
שילוב עם Salesforce (SFDC)
במאמר הזה מוסבר איך לשלב עומסי עבודה תפעוליים של Salesforce (SFDC) ב-Cortex Framework Data Foundation. Cortex Framework משלב נתונים מ-Salesforce עם צינורות עיבוד נתונים של Dataflow דרך BigQuery, ו-Managed Service for Apache Airflow מתזמן ועוקב אחרי צינורות עיבוד הנתונים האלה כדי להפיק תובנות מהנתונים.
קובץ תצורה
הקובץ config.json
במאגר Cortex Framework Data Foundation
מגדיר את ההגדרות שנדרשות להעברת נתונים מכל מקור נתונים, כולל Salesforce. הקובץ הזה מכיל את הפרמטרים הבאים של עומסי עבודה תפעוליים ב-Salesforce:
"SFDC": {
"deployCDC": true,
"createMappingViews": true,
"createPlaceholders": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFDC"
}
}
בטבלה הבאה מפורט הערך של כל פרמטר תפעולי של SFDC:
| פרמטר | משמעות | ערך ברירת המחדל | תיאור |
SFDC.deployCDC
|
פריסת CDC | true
|
יצירת סקריפטים לעיבוד CDC להפעלה כ-DAG ב-Managed Service for Apache Airflow. אפשר לעיין במסמכי העזרה כדי לקבל מידע על אפשרויות שונות להעברת נתונים מ-Salesforce Sales Cloud. |
SFDC.createMappingViews
|
יצירת תצוגות מיפוי | true
|
ה-DAG שסופק לאחזור רשומות חדשות
מממשקי Salesforce API מעדכן רשומות בדף הנחיתה. אם הערך הזה מוגדר כ-true
נוצרים תצוגות בנתוני ה-CDC שעברו עיבוד, כדי לחשוף טבלאות עם
הגרסה העדכנית ביותר של האמת מנתוני המקור. אם הערך הוא false ו-SFDC.deployCDC הוא true, נוצרים גרפים מכוונים מחזוריים (DAG) עם עיבוד של סימון נתונים שהשתנו (CDC) על סמך SystemModstamp. מידע נוסף על עיבוד CDC ב-Salesforce
|
SFDC.createPlaceholders
|
יצירת פלייס הולדרים | true
|
יוצרים טבלאות placeholder ריקות למקרה שהן לא נוצרות בתהליך ההטמעה, כדי לאפשר לפריסת הדיווח במורד הזרם לפעול ללא כשל. |
SFDC.datasets.raw
|
מערך נתונים גולמי של דפי נחיתה | - | הכלי הזה משמש את תהליך ה-CDC, וכאן כלי השכפול מציב את הנתונים מ-Salesforce. אם משתמשים בנתוני בדיקה, יוצרים מערך נתונים ריק. |
SFDC.datasets.cdc
|
מערך נתונים שעבר עיבוד ב-CDC | - | מערך נתונים שמשמש כמקור לתצוגות הדיווח, וכמטרה לרשומות שמעובדות ב-DAG. אם משתמשים בנתוני בדיקה, צריך ליצור מערך נתונים ריק. |
SFDC.datasets.reporting
|
מערך נתונים לדיווח ב-SFDC | "REPORTING_SFDC"
|
שם מערך הנתונים שמשתמשי הקצה יכולים לגשת אליו כדי ליצור דוחות, ושבו נפרסות תצוגות וטבלאות שמוצגות למשתמשים. |
SFDC.currencies
|
סינון מטבעות | [ "USD" ]
|
אם אתם לא משתמשים בנתוני בדיקה, מזינים מטבע אחד (לדוגמה, [ "USD" ]) או כמה מטבעות (לדוגמה,[ "USD", "CAD" ]) בהתאם לעסק שלכם.
הערכים האלה משמשים להחלפת פלייסהולדרים ב-SQL במודלים של ניתוח נתונים, אם הם זמינים.
|
מודל נתונים
בקטע הזה מתואר מודל הנתונים של Salesforce (SFDC) באמצעות דיאגרמת קשר בין ישויות (ERD).
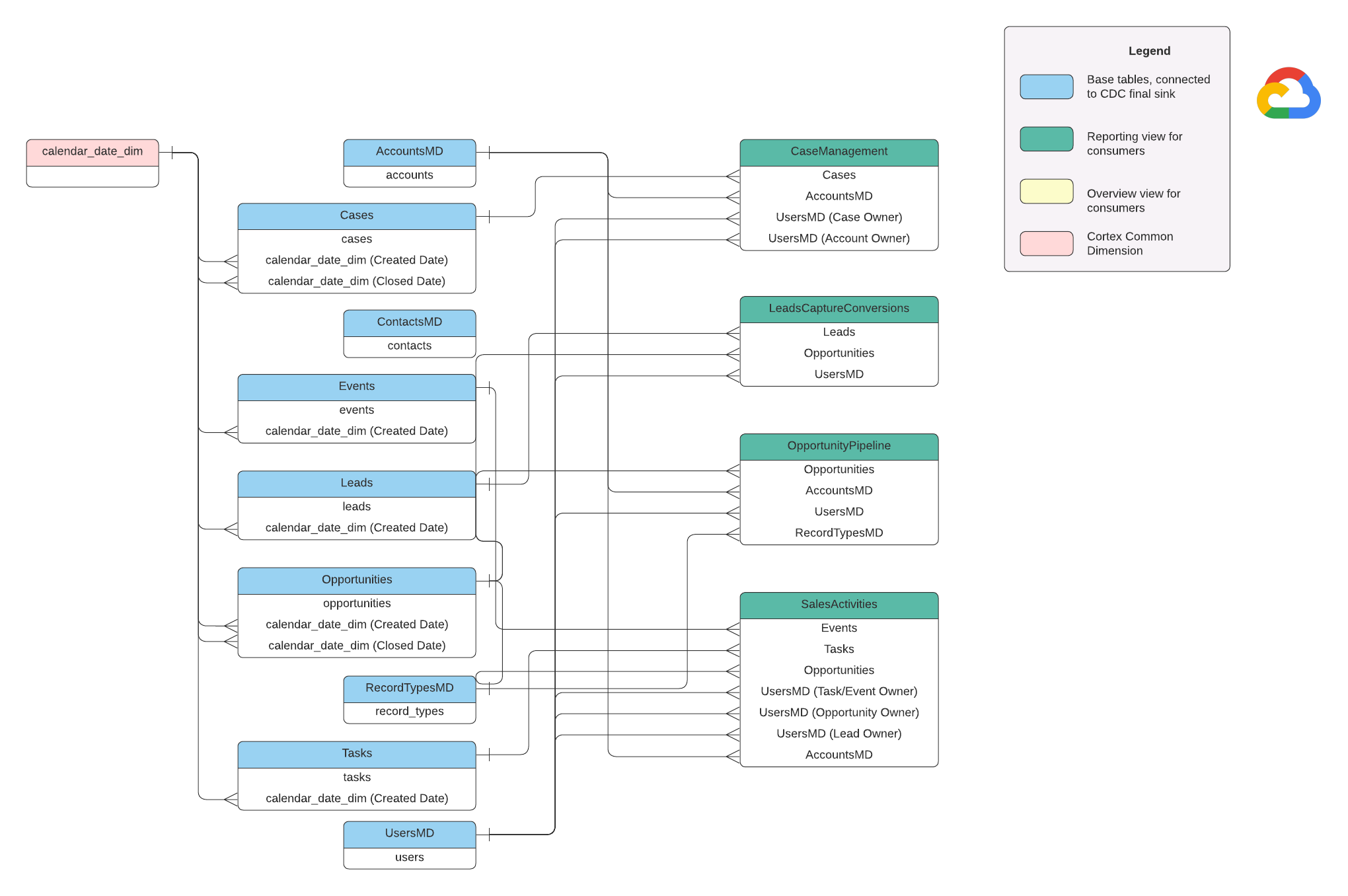
תצוגות בסיסיות
אלה האובייקטים הכחולים ב-ERD, והם תצוגות בטבלאות CDC ללא טרנספורמציות, מלבד כינויים מסוימים של שמות עמודות. אפשר לראות תסריטים ב-src/SFDC/src/reporting/ddls.
תצוגות של דוחות
אלה האובייקטים הירוקים בתרשים ERD, והם מכילים את מאפייני המימד הרלוונטיים שמשמשים את טבלאות הדיווח. אפשר לראות תסריטים ב-src/SFDC/src/reporting/ddls.
הדרישות לגבי נתוני Salesforce
בקטע הזה מפורטות הדרישות לגבי המבנה של נתוני Salesforce כדי שאפשר יהיה להשתמש בהם עם Cortex Framework.
- מבנה הטבלה:
- שמות: שמות הטבלאות הם בצורה
snake_case(מילים באותיות קטנות שמופרדות באמצעות קווים תחתונים) והם ברבים. לדוגמה,some_objects. - סוגי נתונים: העמודות שומרות על אותם סוגי נתונים כמו אלה שמוצגים ב-Salesforce.
- קריאות: יכול להיות ששמות של שדות מסוימים ישתנו קצת כדי שיהיו ברורים יותר בשכבת הדיווח.
- שמות: שמות הטבלאות הם בצורה
- טבלאות ריקות ופריסה: אם חסרות טבלאות נדרשות במערך הנתונים הגולמי, הן נוצרות אוטומטית כטבלאות ריקות במהלך תהליך הפריסה. כך אפשר לוודא שהשלב של פריסת ה-CDC יתבצע בצורה חלקה.
- דרישות ל-CDC: השדות
Idו-SystemModstampחשובים מאוד לסקריפטים של CDC לצורך מעקב אחרי שינויים בנתונים. יכול להיות שהשמות יהיו זהים או שונים. סקריפטים לעיבוד נתונים גולמיים שסופקו לכם מאחזרים את השדות האלה באופן אוטומטי מממשקי ה-API ומעדכנים את טבלת השכפול של היעד.-
Id: משמש כמזהה ייחודי לכל רשומה. -
SystemModstamp: בשדה הזה מאוחסנת חותמת זמן שמציינת את הפעם האחרונה שבה רשומה שונתה.
-
- סקריפטים לעיבוד נתונים גולמיים:הסקריפטים לעיבוד נתונים גולמיים שסופקו לא דורשים עיבוד נוסף (CDC). ההתנהגות הזו מוגדרת במהלך הפריסה כברירת מחדל.
טבלאות המקור להמרת מטבעות
ב-Salesforce אפשר לנהל מטבעות בשתי דרכים:
- בסיסי: זוהי ברירת המחדל, שבה כל הנתונים משתמשים במטבע יחיד.
- מתקדם: המערכת מבצעת המרה בין כמה מטבעות על סמך שערי חליפין (נדרשת הפעלה של ניהול מתקדם של מטבעות).
אם אתם משתמשים בניהול מתקדם של מטבעות, מערכת Salesforce משתמשת בשתי טבלאות מיוחדות:
- CurrencyTypes: בטבלה הזו מאוחסן מידע על המטבעות השונים שבהם אתם משתמשים (לדוגמה, USD, EUR וכו').
- DatedConversionRates: בטבלה הזו מופיעים שערי החליפין בין מטבעות לאורך זמן.
אם משתמשים בניהול מתקדם של מטבעות, מערכת Cortex Framework מצפה שהטבלאות האלה יהיו קיימות. אם אתם לא משתמשים בניהול מתקדם של מטבעות, אתם יכולים להסיר רשומות שקשורות לטבלאות האלה מקובץ הגדרה (src/SFDC/config/ingestion_settings.yaml). השלב הזה מונע ניסיונות מיותרים לחילוץ נתונים מטבלאות שלא קיימות.
טעינת נתונים מ-SFDC ל-BigQuery
Cortex Framework מספק פתרון שכפול שמבוסס על סקריפטים של Python שמתוזמנים ב-Apache Airflow וב-Salesforce Bulk API 2.0. אפשר להתאים את סקריפטי Python האלה ולתזמן אותם בכלי שתבחרו. מידע נוסף זמין במאמר בנושא מודול החילוץ של SFDC.
בנוסף, Cortex Framework מציע שלוש שיטות שונות לשילוב הנתונים, בהתאם למקור הנתונים ולאופן הניהול שלהם:
- קריאות ל-API: האפשרות הזו מתאימה לנתונים שאפשר לגשת אליהם ישירות דרך API. המסגרת של Cortex יכולה לקרוא ל-API, לאחזר את הנתונים ולאחסן אותם במערך נתונים מסוג Raw ב-BigQuery. אם יש רשומות קיימות במערך הנתונים, Cortex Framework יכול לעדכן אותן בנתונים החדשים.
- תצוגות מיפוי מבנה: השיטה הזו שימושית אם כבר טענתם את הנתונים ל-BigQuery באמצעות כלי אחר, אבל מבנה הנתונים לא תואם למה שנדרש ב-Cortex Framework. Cortex Framework משתמש ב'תצוגות' (כמו טבלאות וירטואליות) כדי לתרגם את מבנה הנתונים הקיים לפורמט שנדרש לתכונות הדיווח של Cortex Framework.
סקריפטים לעיבוד נתונים מסוג CDC (Change Data Capture): האפשרות הזו מיועדת במיוחד לנתונים שמשתנים כל הזמן. סקריפטים של CDC עוקבים אחרי השינויים האלה ומעדכנים את הנתונים ב-BigQuery בהתאם. הסקריפטים האלה מסתמכים על שני שדות מיוחדים בנתונים:
-
Id: מזהה ייחודי לכל רשומה. -
SystemModstamp: חותמת זמן שמציינת מתי רשומה השתנתה.
אם הנתונים לא כוללים את השמות האלה בדיוק, אפשר לשנות את הסקריפטים כך שיזהו אותם בשמות אחרים. במהלך התהליך הזה אפשר גם להוסיף שדות מותאמים אישית לסכימת הנתונים. לדוגמה, בטבלת המקור עם נתונים של אובייקט Account צריכים להיות השדות המקוריים
Idו-SystemModstamp. אם השמות של השדות האלה שונים, צריך לעדכן את הקובץsrc/SFDC/src/table_schema/accounts.csvכך ששם השדהIdימופה ל-AccountIdושדה חותמת הזמן של שינוי המערכת ימופה ל-SystemModstamp. מידע נוסף זמין במסמכי התיעוד בנושא SystemModStamp.-
אם כבר טענתם נתונים באמצעות כלי אחר (והם מתעדכנים כל הזמן), Cortex עדיין יכול להשתמש בהם. סקריפטים של CDC מגיעים עם קובצי מיפוי שיכולים לתרגם את מבנה הנתונים הקיים לפורמט שנדרש על ידי Cortex Framework. במהלך התהליך הזה אפשר גם להוסיף שדות מותאמים אישית לנתונים.
הגדרת שילוב API ו-CDC
כדי להעביר את נתוני Salesforce ל-BigQuery, אפשר להשתמש בדרכים הבאות:
- סקריפטים של Cortex לקריאות ל-API: מספק סקריפטים לשכפול של Salesforce או של כלי לשכפול נתונים לפי בחירתכם.חשוב שהנתונים שתייבאו ייראו כאילו הם הגיעו מ-Salesforce APIs.
- כלי שכפול והוספה תמיד : אם אתם משתמשים בכלי לשכפול, זו הדרך להשתמש בכלי שיכול להוסיף רשומות נתונים חדשות (_appendalways_pattern) או לעדכן רשומות קיימות.
- כלי שכפול והוספת רשומות חדשות: אם הכלי לא מעדכן את הרשומות ומשכפל שינויים כרשומות חדשות בטבלת יעד (Raw), Cortex Data Foundation מספק אפשרות ליצור סקריפטים לעיבוד CDC. מידע נוסף זמין במאמר בנושא תהליך ה-CDC.

כדי לוודא שהנתונים שלכם תואמים למה שמצופה מ-Cortex Framework, אתם יכולים לשנות את הגדרות המיפוי כדי למפות את כלי השכפול או את הסכימות הקיימות. הפעולה הזו יוצרת תצוגות מיפוי שתואמות למבנה שצפוי ב-Cortex Framework Data Foundation.
משתמשים בקובץ ingestion_settings.yaml כדי להגדיר את יצירת הסקריפטים לקריאה ל-Salesforce APIs ולשכפול הנתונים לקבוצת הנתונים Raw (בקטע salesforce_to_raw_tables), וגם את יצירת הסקריפטים לעיבוד השינויים שמתקבלים בקבוצת הנתונים Raw ובקבוצת הנתונים CDC processed (בקטע raw_to_cdc_tables).
כברירת מחדל, הסקריפטים שניתנים לקריאה מממשקי API מעדכנים את השינויים במערך הנתונים Raw, כך שלא נדרשים סקריפטים לעיבוד CDC. במקום זאת, נוצרות תצוגות מיפוי כדי להתאים את סכימת המקור לסכימה הצפויה.
יצירת סקריפטים לעיבוד CDC לא מתבצעת אם SFDC.createMappingViews=true בקובץ config.json (התנהגות ברירת המחדל). אם נדרשים סקריפטים של CDC,
מגדירים את SFDC.createMappingViews=false. בשלב השני הזה אפשר גם למפות בין סכימות המקור לסכימות הנדרשות, בהתאם לדרישות של Cortex Framework Data Foundation.
בדוגמה הבאה של קובץ הגדרות setting.yaml אפשר לראות איך נוצרים תצוגות מיפוי כשכלי שכפול מעדכן את הנתונים ישירות במערך הנתונים המשוכפל, כמו שמוצג ב-option 3 (כלומר, לא נדרש CDC, רק מיפוי מחדש של טבלאות ושמות שדות). מכיוון שלא נדרש CDC, האפשרות הזו מופעלת כל עוד הפרמטר SFDC.createMappingViews בקובץ config.json נשאר true.
salesforce_to_raw_tables:
- base_table: accounts
raw_table: Accounts
api_name: Account
load_frequency: "@daily"
- base_table: cases
raw_table: cases2
api_name: Case
load_frequency: "@daily"
בדוגמה הזו, אם מסירים את ההגדרה של טבלת בסיס או של כולן מהקטעים, המערכת מדלגת על יצירת גרפים מכוונים מחזוריים של טבלת הבסיס הזו או של כל הקטע, כמו שמודגם ב-salesforce_to_raw_tables. בתרחיש הזה, הגדרת הפרמטר deployCDC : False תביא לאותה תוצאה, כי לא צריך ליצור סקריפטים לעיבוד CDC.
מיפוי נתונים
צריך למפות את השדות של הנתונים הנכנסים לפורמט שצפוי ב-Cortex Data
Foundation. לדוגמה, שדה בשם unicornId ממערכת נתוני המקור צריך לקבל שם חדש ולהיות מזוהה כ-AccountId (עם סוג נתונים של מחרוזת) ב-Cortex Data Foundation:
- שדה המקור:
unicornId(השם שמשמש במערכת המקור) - שדה Cortex:
AccountId(השם שצפוי על ידי Cortex) - סוג הנתונים:
String(סוג הנתונים שצפוי על ידי Cortex)
מיפוי שדות פולימורפיים
ה-Cortex Framework Data Foundation תומך במיפוי של שדות פולימורפיים, שהם שדות שהשם שלהם יכול להשתנות אבל המבנה שלהם נשאר עקבי. אפשר לשכפל שמות של שדות פולימורפיים (לדוגמה, Who.Type) על ידי הוספת פריט [Field Name]_Type בקובצי ה-CSV של המיפוי המתאימים:
src/SFDC/src/table_schema/tasks.csv. לדוגמה, אם רוצים לשכפל את השדה Who.Type של האובייקט Task, מוסיפים את השורה Who_Type,Who_Type,STRING. הפעולה הזו מגדירה שדה חדש בשם Who.Type
שממופה לעצמו (השם נשאר זהה) וסוג הנתונים שלו הוא מחרוזת.
שינוי תבניות DAG
יכול להיות שתצטרכו לשנות את תבניות ה-DAG ל-CDC או לעיבוד נתונים גולמיים בהתאם לדרישות של המופע של Airflow או Managed Airflow. מידע נוסף זמין במאמר בנושא איסוף הגדרות של Managed Airflow.
אם אתם לא צריכים CDC או יצירה של נתונים גולמיים מקריאות API, צריך להגדיר את deployCDC=false. אפשר גם להסיר את התוכן של הקטעים בingestion_settings.yaml. אם ידוע שמבני הנתונים עקביים עם אלה שצפויים על ידי Cortex Framework Data Foundation, אפשר לדלג על יצירת תצוגות מיפוי על ידי הגדרת SFDC.createMappingViews=false.
הגדרת מודול החילוץ
בקטע הזה מפורטים השלבים לשימוש במודול החילוץ מ-Salesforce ל-BigQuery שמוצע על ידי Data Foundation. הדרישות והתהליך עשויים להשתנות בהתאם למערכת ולהגדרה הקיימת. אפשר גם להשתמש בכלים זמינים אחרים.
הגדרת פרטי כניסה ואפליקציה מקושרת
מתחברים לאינסטנס של Salesforce בתור אדמין כדי לבצע את הפעולות הבאות:
- יוצרים פרופיל ב-Salesforce או מזהים פרופיל שעומד בדרישות הבאות:
Permission for Apex REST Services and API Enabledניתנת במסגרת הרשאות המערכת.- ההרשאה
View Allניתנת לכל האובייקטים שרוצים לשכפל. לדוגמה, Account ו-Cases. כדאי לבדוק אם יש הגבלות או בעיות אצל מנהל האבטחה. - לא ניתנו הרשאות שקשורות לכניסה לממשק משתמש, כמו Salesforce Anywhere ב-Lightning Experience, Salesforce Anywhere בנייד, משתמש ב-Lightning Experience ומשתמש בכניסה ל-Lightning. כדאי לבדוק אם יש הגבלות או בעיות אצל אדמין האבטחה.
- יוצרים משתמש חדש או משתמשים במשתמש קיים ב-Salesforce. צריך לדעת את שם המשתמש, הסיסמה ואסימון האבטחה של המשתמש. כמה נקודות שכדאי לזכור:
- מומלץ להשתמש בחשבון משתמש שמוקדש לביצוע השכפול הזה.
- צריך להקצות את המשתמש לפרופיל שיצרתם או שזיהיתם בשלב 1.
- כאן אפשר לראות את שם המשתמש ולאפס את הסיסמה.
- אם אין לכם את אסימון האבטחה והוא לא נמצא בשימוש בתהליך אחר, אתם יכולים לאפס אותו.
- יוצרים אפליקציה מקושרת. זהו ערוץ התקשורת היחיד ליצירת חיבור ל-Salesforce מהעולם החיצוני בעזרת פרופיל, Salesforce API, פרטי כניסה רגילים של משתמשים ואסימון האבטחה שלהם.
- פועלים לפי ההוראות להפעלת הגדרות OAuth לשילוב API.
- מוודאים שהאפשרויות
Require Secret for Web Server Flowו-Require Secretfor Refresh Token Flowמופעלות בקטע API (Enabled OAuth Settings). - במסמכי התיעוד מוסבר איך מקבלים את טוקן הצרכן (שישמש בהמשך כמזהה הלקוח). כדאי לפנות לאדמין האבטחה כדי לברר אם יש בעיות או הגבלות.
- מקצים את האפליקציה המקושרת לפרופיל שנוצר.
- בפינה השמאלית העליונה במסך הבית של Salesforce, בוחרים באפשרות הגדרה.
- בתיבה חיפוש מהיר, מזינים
profileובוחרים באפשרות פרופיל. מחפשים את הפרופיל שנוצר בשלב 1. - פותחים את הפרופיל.
- לוחצים על הקישור אפליקציות מקושרות שהוקצו.
- לוחצים על Edit.
- מוסיפים את האפליקציה המקושרת החדשה שנוצרה.
- לוחצים על הלחצן שמירה.
הגדרת Secret Manager
מגדירים את Secret Manager לאחסון פרטי החיבור. המודול Salesforce-to-BigQuery מסתמך על Secret Manager כדי לאחסן בצורה מאובטחת את פרטי הכניסה שהוא צריך כדי להתחבר ל-Salesforce ול-BigQuery. הגישה הזו מונעת חשיפה של מידע רגיש כמו סיסמאות ישירות בקוד או בקובצי ההגדרות, וכך משפרת את האבטחה.
יוצרים סוד עם המפרט הבא. הוראות מפורטות זמינות במאמר יצירת סוד.
- שם הסוד:
airflow-connections-salesforce-conn ערך Secret:
http://USERNAME:PASSWORD@https%3A%2F%2FINSTANCE_NAME.lightning.force.com?client_id=CLIENT_ID&security_token=SECRET_TOKEN`מחליפים את מה שכתוב בשדות הבאים:
-
USERNAMEמחליפים בשם המשתמש שלכם. -
PASSWORDמחליפים בסיסמה שלכם. INSTANCE_NAMEבשם המכונה.-
CLIENT_IDמחליפים במזהה הלקוח. -
SECRET_TOKENמחליפים באסימון הסודי שלכם.
-
מידע נוסף מופיע במאמר בנושא איך מאתרים את שם המכונה.
ספריות Managed Airflow לרפליקציה
כדי להריץ את סקריפטים של Python ב-DAG שסופקו על ידי Cortex Framework Data Foundation, צריך להתקין כמה תלויות. ב-Airflow גרסה 1.10, פועלים לפי ההוראות במאמר Install Python dependencies for Managed Service for Apache Airflow 1 כדי להתקין את החבילות הבאות, לפי הסדר:
tableauserverclient==0.17
apache-airflow-backport-providers-salesforce==2021.3.3
אם אתם משתמשים ב-Airflow גרסה 2.x, תוכלו לעיין במסמכי התיעוד בנושא התקנת יחסי תלות של Python ב-Managed Service for Apache Airflow 2 כדי להתקין את apache-airflow-providers-salesforce~=5.2.0.
משתמשים בפקודה הבאה כדי להתקין כל חבילה נדרשת:
gcloud composer environments update ENVIRONMENT_NAME \
--location LOCATION \
--update-pypi-package PACKAGE_NAME EXTRAS_AND_VERSION
מחליפים את מה שכתוב בשדות הבאים:
-
ENVIRONMENT_NAMEבשם הסביבה שהוקצה. LOCATIONעם המיקום.-
PACKAGE_NAMEבשם החבילה שבחרתם. -
EXTRAS_AND_VERSIONעם המפרטים של התוספים והגרסה.
הפקודה הבאה היא דוגמה להתקנה של חבילה נדרשת:
gcloud composer environments update my-composer-instance \
--location us-central1 \
--update-pypi-package apache-airflow-backport-providers-salesforce>=2021.3.3
הפעלת Secret Manager כקצה עורפי
מפעילים את Google Secret Manager כקצה העורפי של האבטחה. בשלב הזה מוסבר איך להפעיל את Secret Manager כמקום האחסון העיקרי למידע רגיש כמו סיסמאות ומפתחות API שמשמשים את סביבת Managed Service for Apache Airflow. השיטה הזו משפרת את האבטחה כי היא מאפשרת לנהל את פרטי הכניסה באופן מרכזי בשירות ייעודי. מידע נוסף זמין במאמר בנושא Secret Manager.
מתן אפשרות לחשבון השירות של Composer לגשת לסודות
השלב הזה מבטיח שלחשבון השירות שמשויך ל-Managed Service for Apache Airflow יש את ההרשאות הנדרשות כדי לגשת לסודות שמאוחסנים ב-Secret Manager.
כברירת מחדל, Managed Service for Apache Airflow משתמש בחשבון השירות של Compute Engine.
ההרשאה הנדרשת היא Secret Manager Secret Accessor.
ההרשאה הזו מאפשרת לחשבון השירות לאחזר סודות שמאוחסנים ב-Secret Manager ולהשתמש בהם.מדריך מקיף להגדרת אמצעי בקרת גישה ב-Secret Manager זמין במסמכי התיעוד בנושא בקרת גישה.
חיבור ל-BigQuery ב-Airflow
חשוב ליצור את החיבור sfdc_cdc_bq בהתאם להוראות שבמאמר איסוף הגדרות של Managed Airflow. סביר להניח שהחיבור הזה משמש את המודול Salesforce-to-BigQuery כדי ליצור תקשורת עם BigQuery.
מה השלב הבא?
- מידע נוסף על מקורות נתונים ועומסי עבודה אחרים זמין במאמר מקורות נתונים ועומסי עבודה.
- מידע נוסף על השלבים לפריסה בסביבות ייצור זמין במאמר דרישות מוקדמות לפריסת Cortex Framework Data Foundation.