
Integração com o Salesforce Marketing Cloud
Esta página descreve as configurações necessárias para trazer dados do Salesforce Marketing Cloud (SFMC) como uma fonte de dados da carga de trabalho de marketing do Cortex Framework Data Foundation.
O SFMC é uma plataforma de automação de marketing digital oferecida pelo Salesforce. Ele oferece às empresas um conjunto abrangente de ferramentas para gerenciar e automatizar várias atividades de marketing em vários canais. O Cortex Framework atua como o mecanismo de análise de dados e IA que ajuda você a entender os resultados, identificar áreas de melhoria e otimizar sua estratégia de marketing para melhores resultados.
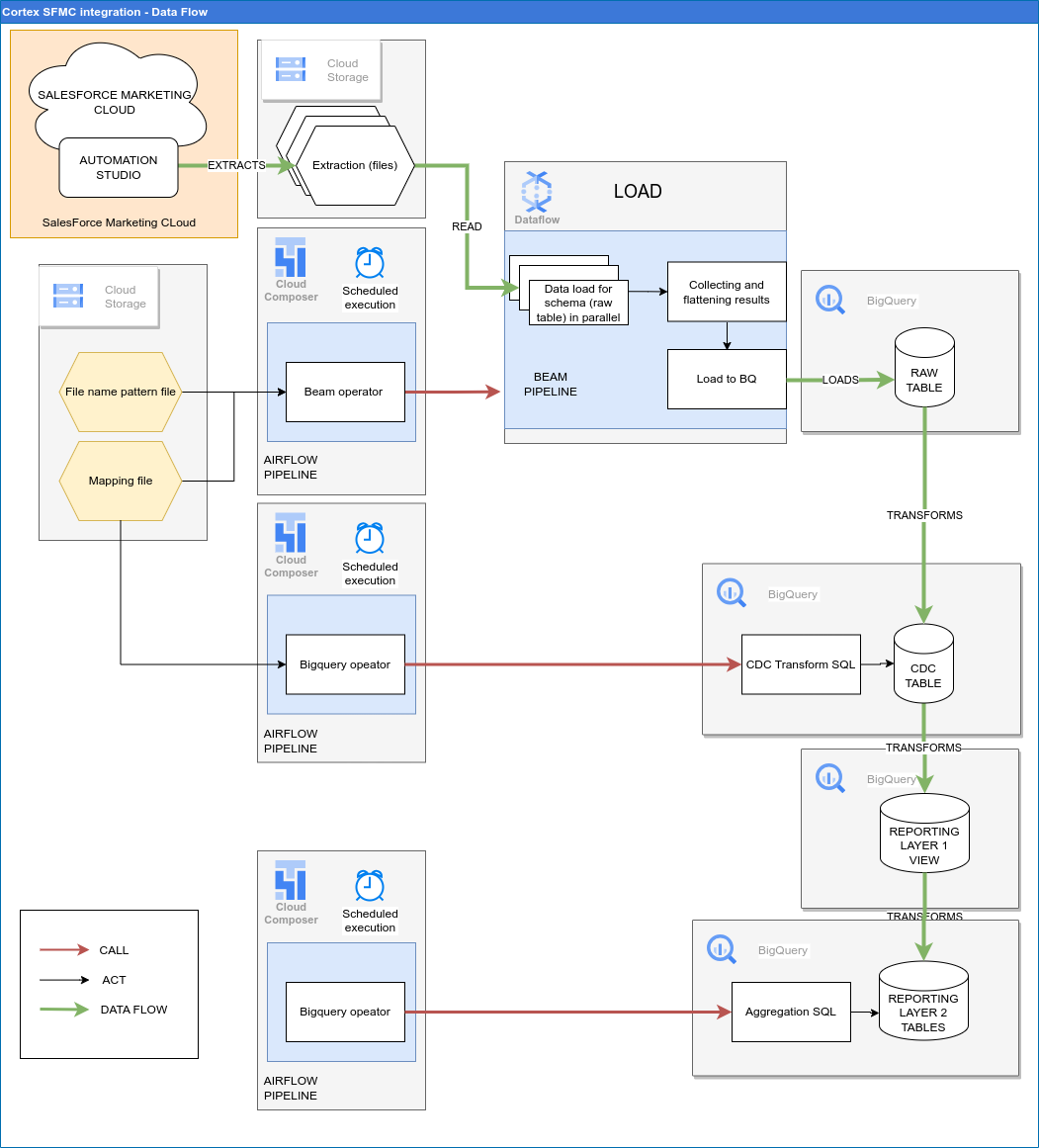
O diagrama a seguir descreve como os dados do SFMC estão disponíveis na carga de trabalho de marketing do Cortex Framework Data Foundation:
Arquivo de configuração
O arquivo config.json configura as definições necessárias para se conectar a fontes de dados para transferir
dados de várias cargas de trabalho. Esse arquivo contém os seguintes parâmetros para o SFMC:
"marketing": {
"deploySFMC": true,
"SFMC": {
"deployCDC": true,
"fileTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFMC"
}
}
}
A tabela a seguir descreve o valor de cada parâmetro de marketing:
| Parâmetro | Significado | Valor padrão | Descrição |
marketing.deploySFMC
|
Implantar o SFMC | true
|
Executar a implantação da fonte de dados do SFMC. |
marketing.SFMC.deployCDC
|
Implantar scripts de CDC para o SFMC | true
|
Gerar scripts de processamento de CDC do Salesforce Marketing Cloud (SFMC) para serem executados como DAGs no Airflow gerenciado. |
marketing.SFMC.fileTransferBucket
|
Bucket com arquivos de extração de dados | - | Bucket em que os arquivos de extração de dados do Automation Studio do Salesforce Marketing Cloud (SFMC) são armazenados. |
marketing.SFMC.datasets.cdc
|
Conjunto de dados de CDC para o SFMC | Conjunto de dados de CDC para o Salesforce Marketing Cloud (SFMC). | |
marketing.SFMC.datasets.raw
|
Conjunto de dados brutos para o SFMC | Conjunto de dados brutos para o Salesforce Marketing Cloud (SFMC). | |
marketing.SFMC.datasets.reporting
|
Conjunto de dados de relatórios para o SFMC | "REPORTING_SFMC"
|
Conjunto de dados de relatórios para o Salesforce Marketing Cloud (SFMC). |
Modelo de dados
Esta seção descreve o modelo de dados do Salesforce Marketing Cloud (SFMC) usando o diagrama de entidade-relacionamento (DER).
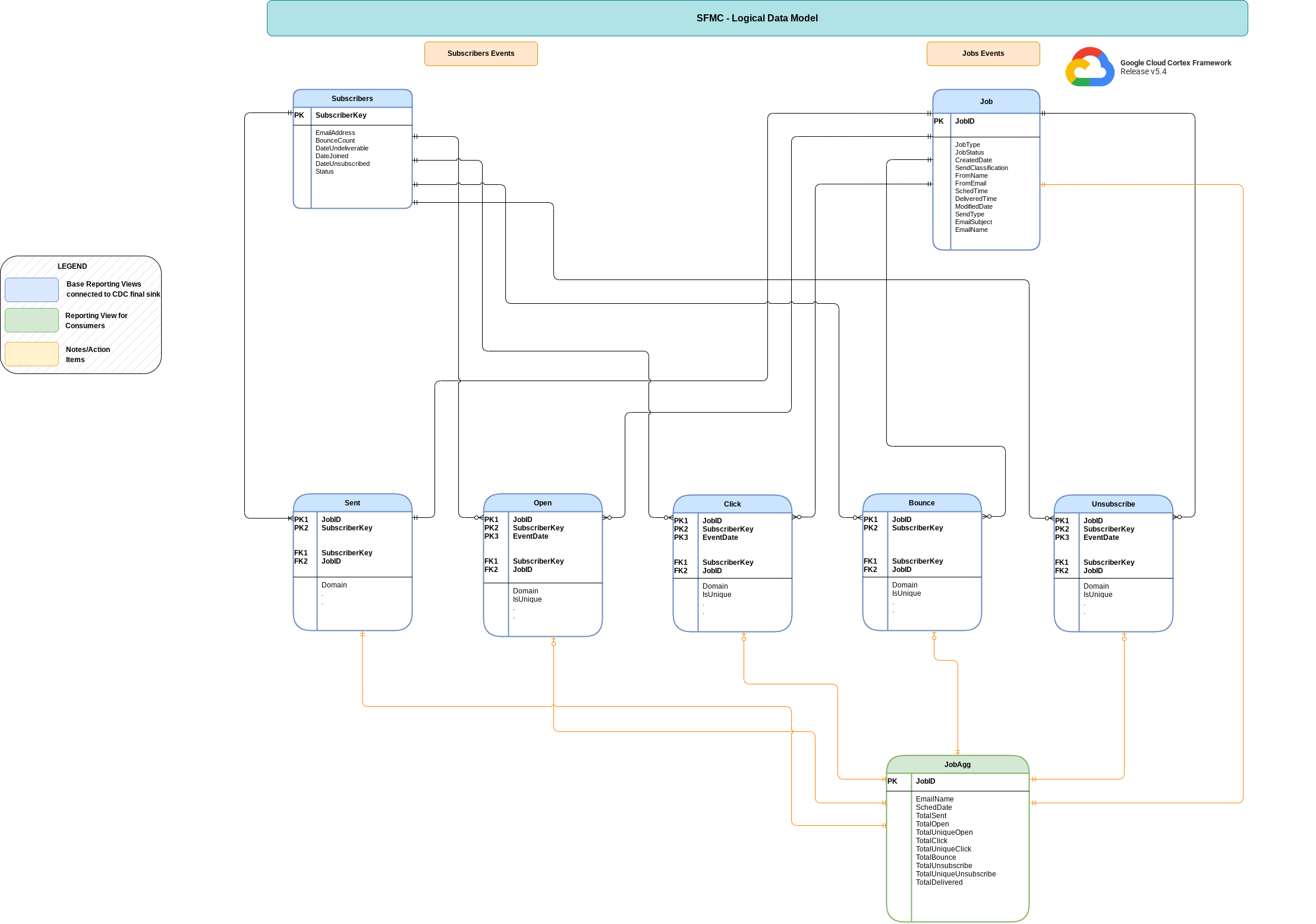
Visualizações básicas
Esses são os objetos azuis no DER e são visualizações em tabelas de CDC sem transformações, exceto alguns aliases de nome de coluna. Consulte os scripts em
src/marketing/src/SFMC/src/reporting/ddls.
Vista de relatórios
Esses são os objetos verdes no DER e são visualizações de relatórios que contêm métricas agregadas. Consulte os scripts em
src/marketing/src/SFMC/src/reporting/ddls.
Extração de dados usando o Automation Studio
O Automation Studio do SFMC permite que os consumidores do SFMC exportem os dados para vários sistemas de armazenamento. O Cortex Framework Data Foundation procura um conjunto de arquivos criados com o Automation Studio em um bucket do Cloud Storage. Você também precisa usar SFMC Email Studio nesse processo.
Para configurar os processos de extração e exportação de dados, siga estas etapas:
- Configure um bucket do Cloud Storage. Esse bucket armazena arquivos exportados do SFMC. Nomeie o bucket
marketing.SFMC.fileTransferBucketparâmetro de configuração. Consulte as instruções na documentação do Salesforce. Crie extensões de dados. Para cada entidade para a qual você quer extrair dados, crie uma extensão de dados no Email Studio. Isso é necessário para identificar as fontes de dados do banco de dados interno do SFMC.
- Liste todos os campos definidos em
src/SFMC/config/table_schemapara a entidade. Se você precisar personalizar isso para extrair mais ou menos campos, verifique se a lista de campos está alinhada nessas etapas e nos arquivos de esquema de tabela. Por exemplo:
Entity: unsubscribe Fields: AccountID OYBAccountID JobID ListID BatchID SubscriberID SubscriberKey EventDate IsUnique Domain- Liste todos os campos definidos em
Crie atividades de consulta SQL. Para cada entidade, crie uma atividade de consulta SQL. Essa atividade está conectada à extensão de dados correspondente criada anteriormente. Consulte a documentação do Salesforce para esta etapa:
- Defina a consulta SQL com todos os campos relevantes. A consulta precisa selecionar todos os campos relevantes para a entidade definida na extensão de dados na etapa anterior.
- Selecione a extensão de dados correta como destino.
- Selecione Substituir como ação de dados.
- Consulte o exemplo de consulta a seguir:
SELECT AccountID, OYBAccountID, JobID, ListID, BatchID, SubscriberID, SubscriberKey, EventDate, IsUnique, Domain FROM _UnsubscribeCrie atividades de extração de dados. Consulte a documentação do Salesforce para criar uma atividade de extração de dados para cada entidade. Essa atividade recebe os dados da extensão de dados do Salesforce e os extrai para um arquivo CSV. Para esta etapa:
- Use o padrão de nomenclatura correto. Ele precisa corresponder ao padrão definido nas
configurações.
Por exemplo, para a entidade
Unsubscribe, o nome do arquivo pode ser algo comounsubscribe_%%Year%%_%%Month%%_%%Day%% %%Hour%%.csv. - Defina Tipo de extração como
Data Extension Extract. - Selecione as opções Tem cabeçalhos de coluna e Texto qualificado.
- Use o padrão de nomenclatura correto. Ele precisa corresponder ao padrão definido nas
configurações.
Por exemplo, para a entidade
Crie atividades de conversão de arquivos para converter o formato de UTF-16 para UTF-8. Por padrão, o Salesforce exporta arquivos CSV em UTF-16. Nesta etapa, você o converte para o formato UTF-8. Para cada entidade, crie outra atividade de extração de dados, para conversão de arquivos. Para esta etapa:
- Use o mesmo padrão de nome de arquivo usado na etapa anterior da atividade de extração de dados.
- Defina Tipo de extração como
File Convert - Selecione
UTF8no menu suspenso emConvert To.
Crie atividades de transferência de arquivos. Crie uma atividade de transferência de arquivos para cada entidade. Essas atividades movem os arquivos CSV extraídos do Salesforce Safehouse para buckets do Cloud Storage. Para esta etapa:
- Use o mesmo padrão de nome de arquivo usado nas etapas anteriores.
- Selecione um bucket do Cloud Storage que foi configurado anteriormente no processo como destino.
Programe a execução. Depois que todas as atividades forem concluídas, configure programações automatizadas para executá-las.
Atualização e atraso de dados
Como regra geral, a atualização de dados para fontes de dados do Cortex Framework é limitada pelo que a conexão upstream permite, bem como pela frequência de execução do DAG. Ajuste a frequência de execução do DAG para se alinhar à frequência upstream, às restrições de recursos e às necessidades de negócios.
Com o Automation Studio do SFMC, o atraso na atualização dos dados depende do atraso de programação quando a exportação de dados é configurada.
Permissões de conexões do Serviço Gerenciado para Apache Airflow
Crie as seguintes conexões no Airflow gerenciado. Consulte mais detalhes na documentação Gerenciar conexões do Airflow.
| Nome da conexão | Purpose |
sfmc_raw_dataflow
|
Para arquivos extraídos do SFMC > conjunto de dados BigQueryRaw. |
sfmc_cdc_bq
|
Para conjunto de dados brutos > transferência de conjunto de dados de CDC. |
sfmc_reporting_bq
|
Para conjunto de dados de CDC > transferência de conjunto de dados de relatórios. |
Permissões da conta de serviço do Airflow gerenciado
A conta de serviço usada no Airflow gerenciado (conforme configurado na conexão sfmc_raw_dataflow) precisa de permissões relacionadas ao Dataflow.
Consulte as instruções na documentação do Dataflow.
Configurações de ingestão
Controle os pipelines de dados Source to Raw e Raw to CDC pelas configurações no arquivo src/SFMC/config/ingestion_settings.yaml .
Esta seção descreve os parâmetros de cada pipeline de dados.
Origem para tabelas brutas
Esta seção tem entradas que controlam como os arquivos extraídos do Automation Studio são usados. Cada entrada corresponde a uma entidade do SFMC. Com base nessa configuração, o Cortex Framework cria DAGs do Airflow que executam pipelines do Dataflow para carregar dados de arquivos exportados em tabelas do BigQuery no conjunto de dados brutos.
O diretório src/SFMC/config/table_schema contém um arquivo de esquema para cada entidade extraída do SFMC. Cada arquivo explica como ler os arquivos CSV extraídos do Automaton Studio para carregá-los com sucesso no conjunto de dados BigQueryraw.
Cada arquivo de esquema contém três colunas:
SourceField: nome do campo do arquivo CSV.TargetField: nome da coluna na tabela bruta para essa entidade.DataType: tipo de dados de cada campo da tabela bruta.
Os parâmetros a seguir controlam as configurações de Source to Raw para cada entrada:
| Parâmetro | Descrição |
base_table
|
Nome da tabela bruta em que os dados extraídos de uma entidade do SFMC são carregados. |
load_frequency
|
Com que frequência um DAG dessa entidade é executado para carregar dados de arquivos extraídos. Para mais informações sobre os valores possíveis, consulte a documentação do Airflow. |
file_pattern
|
Padrão para o arquivo dessa tabela que é exportado do Automation Studio para o bucket do Cloud Storage. Altere isso apenas se você tiver escolhido um nome diferente dos sugeridos para arquivos extraídos. |
partition_details
|
Como a tabela bruta é particionada para considerações de performance. Para mais informações, consulte Partição de tabelas. |
cluster_details
|
Opcional: Se você quiser que a tabela bruta seja agrupada para considerações de performance. Para mais informações, consulte Configurações de cluster. |
Tabelas brutas para CDC
Esta seção descreve quais entradas controlam como os dados são movidos de tabelas brutas para tabelas de CDC. Cada entrada corresponde a uma tabela bruta.
Os parâmetros a seguir controlam as configurações de Raw to CDC para cada entrada:
| Parâmetro | Descrição |
base_table
|
Tabela no conjunto de dados de CDC em que os dados brutos dados após a transformação de CDC são armazenados. |
load_frequency
|
Com que frequência um DAG dessa entidade é executado para preencher a tabela de CDC. Para mais informações sobre os valores possíveis, consulte a documentação do Airflow. |
raw_table
|
Tabela de origem do conjunto de dados brutos. |
row_identifiers
|
Colunas (separadas por vírgula) que formam um registro exclusivo para essa tabela. |
partition_details
|
Como a tabela de CDC é particionada para considerações de performance. Para mais informações, consulte Partição de tabelas. |
cluster_details
|
Opcional: Se você quiser que essa tabela seja agrupada para considerações de performance. Para mais informações, consulte Configurações de cluster. |
Configurações de relatório
É possível configurar e controlar como o Cortex Framework gera dados para a camada de relatórios finais do SFMC usando o arquivo de configurações de relatórios (src/SFMC/config/reporting_settings.yaml). Esse arquivo controla como os objetos do BigQuery da camada de relatórios (tabelas, visualizações,funções ou procedimentos armazenados) são gerados.
Para mais informações, consulte Como personalizar o arquivo de configurações de relatórios.
A seguir
- Para mais informações sobre outras fontes de dados e cargas de trabalho, consulte Fontes de dados e cargas de trabalho.
- Para mais informações sobre as etapas de implantação em ambientes de produção, consulte Pré-requisitos de implantação do Cortex Framework Data Foundation.