
Integração com a Meta
Esta página descreve as configurações necessárias para trazer dados da Meta (Facebook e Instagram Ads) como uma fonte de dados da carga de trabalho de marketing do Cortex Framework Data Foundation.
A Meta é uma empresa de tecnologia proprietária de várias plataformas on-line populares. O Cortex Framework integra dados de anúncios do Instagram e do Facebook para analisar e combinar com outras fontes de dados, além de usar a IA para gerar insights mais detalhados e otimizar sua estratégia de marketing.
O diagrama a seguir descreve como os dados de marketing da Meta ficam disponíveis na carga de trabalho de marketing do Cortex Framework Data Foundation:
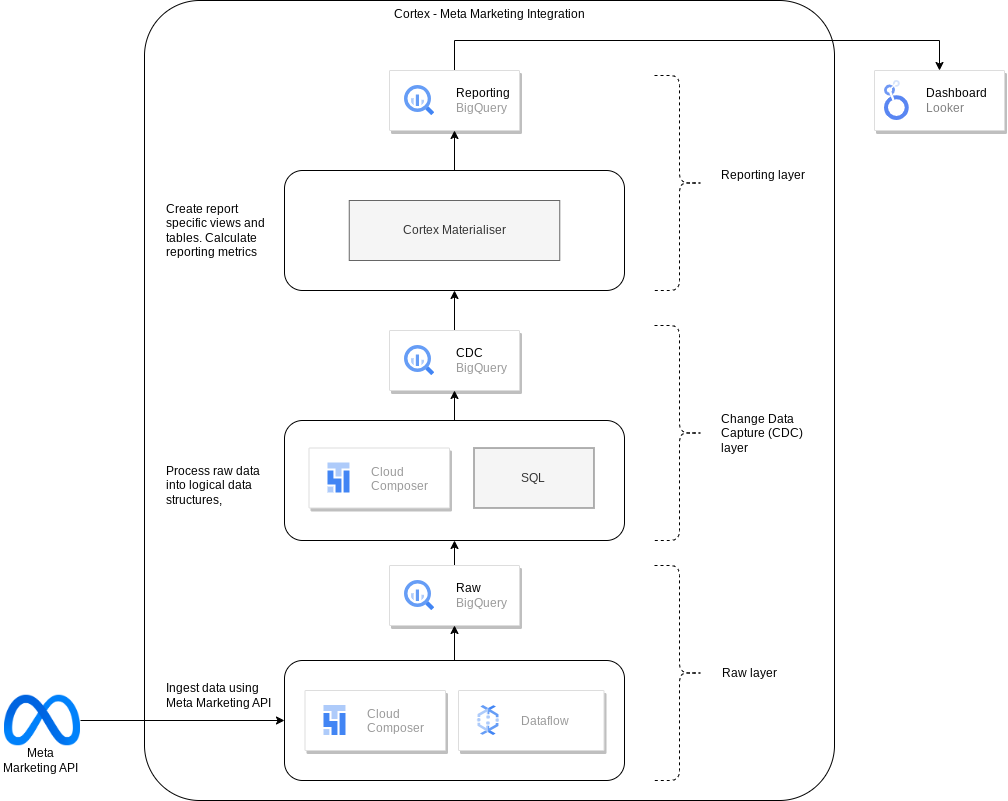
Arquivo de configuração
O arquivo config.json configura as definições necessárias para se conectar a fontes de dados para transferir
dados de várias cargas de trabalho. Esse arquivo contém os seguintes parâmetros para a Meta:
"marketing": {
"deployMeta": true,
"Meta": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_Meta"
}
}
}
A tabela a seguir descreve o valor de cada parâmetro de marketing:
| Parâmetro | Significado | Valor padrão | Descrição |
marketing.deployMeta
|
Implantar Meta | true
|
Executa a implantação da fonte de dados da Meta. |
marketing.Meta.deployCDC
|
Implantar scripts de CDC para a Meta | true
|
Gera scripts de processamento de CDC da Meta para serem executados como DAGs no Airflow gerenciado. |
marketing.Meta.datasets.cdc
|
Conjunto de dados de CDC para a Meta | Conjunto de dados de CDC para a Meta. | |
marketing.Meta.datasets.raw
|
Conjunto de dados brutos para a Meta | Conjunto de dados brutos para a Meta. | |
marketing.Meta.datasets.reporting
|
Conjunto de dados de relatórios para a Meta | "REPORTING_Meta"
|
Conjunto de dados de relatórios para a Meta. |
Modelo de dados
Esta seção descreve o modelo de dados da Meta usando o diagrama de relacionamento de entidades (ERD, na sigla em inglês).
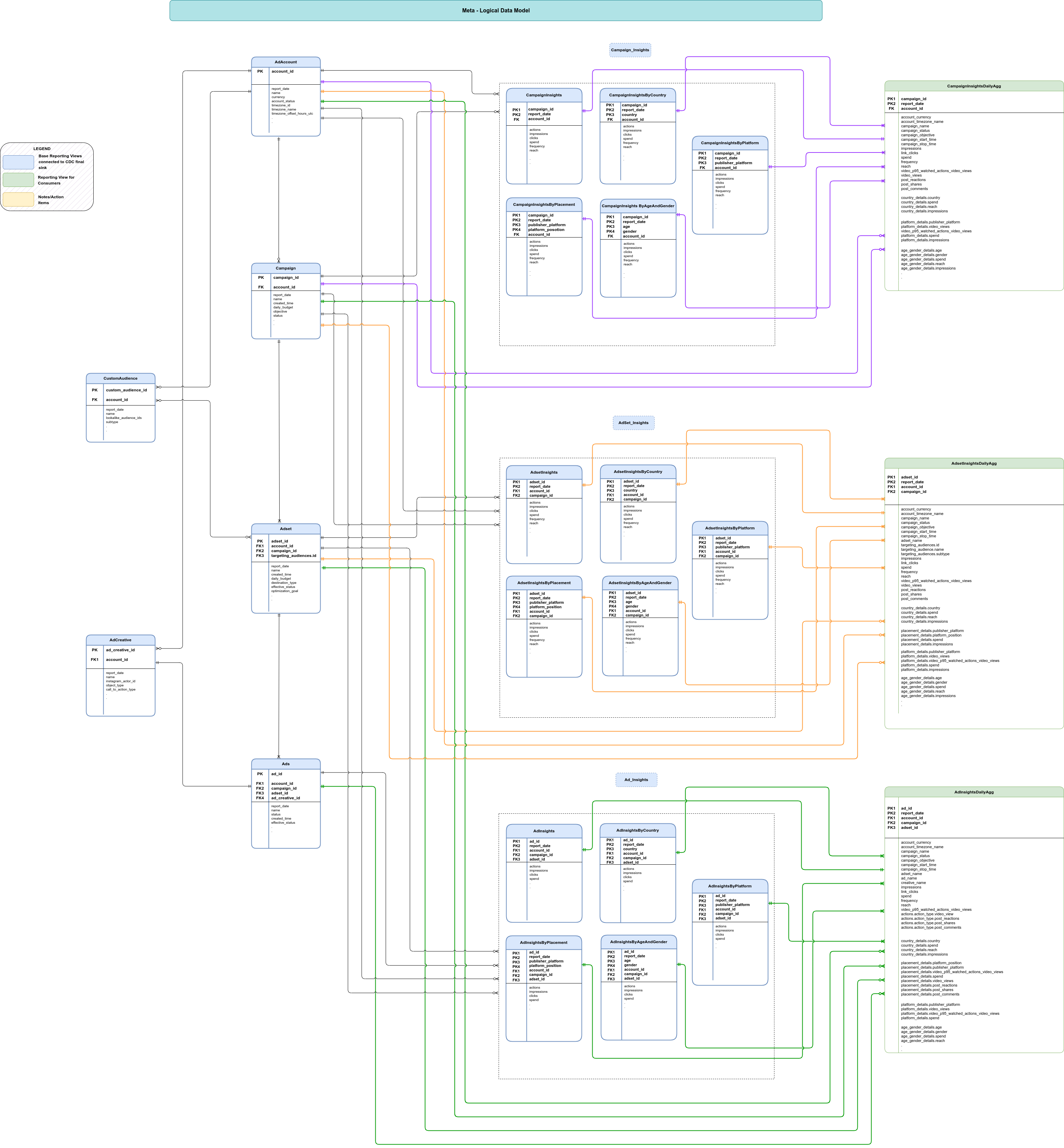
Visualizações básicas
São os objetos azuis no ERD e são visualizações em tabelas de CDC com transformações mínimas para descompactar estruturas de dados complexas. Consulte os scripts em
src/marketing/src/Meta/src/reporting/ddls.
Visualizações de relatórios
São os objetos verdes no ERD e são visualizações de relatórios que contêm métricas agregadas. Consulte os scripts em
src/marketing/src/Meta/src/reporting/ddls.
Conexão de API
Os modelos de ingestão no Cortex Framework para a Meta usam a API Marketing da Meta para recuperar atributos e métricas de relatórios. Os modelos atuais usam a versão v25.0.
A Meta impõe um limite de taxa dinâmico ao consultar a API Marketing. Quando o limite de taxa é atingido, os DAGs de ingestão de origem para bruto podem não ser concluídos. Nesses casos, você pode conferir mensagens de erro relevantes no registro, e a próxima execução dos DAGs vai carregar retroativamente todos os dados ausentes.
A API Marketing da Meta tem dois níveis de acesso: básico e padrão. O nível padrão oferece um limite muito maior e é recomendado se você planeja usar a ingestão de origem para bruto de forma extensiva. Para mais detalhes sobre esses limites e como alcançar um nível de acesso mais alto, consulte a documentação da Meta.
Se você tiver acesso ao nível padrão, poderá diminuir o valor da configuração next_request_delay_sec em src/Meta/src/raw/pipelines/config.ini para tempos de carregamento mais rápidos.
Acesso à API e token de acesso
As etapas a seguir são necessárias no Gerenciador de empresas da Meta e no Console para desenvolvedores para trazer dados da Meta para o Cortex Framework.
- Identifique um app para usar. Você pode criar um novo app
conectado à conta empresarial. Verifique se o app é do tipo
Business. - Configure as permissões do app. Você precisa ser atribuído ao app como administrador antes de poder criar tokens com ele. Consulte a documentação de papéis do app. Atribua os recursos relevantes (contas) ao seu app.
Crie um token de acesso. Os tokens de acesso são necessários para acessar a API Marketing da Meta e estão sempre associados a um app e a um usuário. Você pode criar o token com um usuário do sistema ou com seu próprio login.
- Crie um usuário do sistema administrador.
- Gere um token. Anote o token assim que ele for gerado, porque não será possível recuperá-lo depois que você sair da página.
- Conceda as permissões
ads_readebusiness_managementao seu token para acessar os objetos compatíveis.
Siga a documentação do Airflow gerenciado para ativar o Secret Manager no Airflow gerenciado. Em seguida, crie um Secret chamado
cortex_meta_access_tokene armazene o token gerado na etapa anterior como conteúdo.
Atualização e atraso de dados
Como regra geral, a atualização de dados para fontes de dados do Cortex Framework é limitada pelo que a conexão upstream permite, bem como pela frequência de execução do DAG. Ajuste a frequência de execução do DAG para se alinhar à frequência upstream, às restrições de recursos e às necessidades da sua empresa.
Com a API Marketing da Meta, a maioria dos dados (exceto conversões) fica disponível quase em tempo real, embora possa ser ajustada até 28 dias após o evento.
Permissões de conexões do Serviço gerenciado para Apache Airflow
Crie as seguintes conexões no Airflow gerenciado. Confira mais detalhes na documentação Gerenciar conexões do Airflow.
| Nome da conexão | Purpose |
meta_raw_dataflow
|
Para a API Marketing da Meta > conjunto de dados brutos do BigQuery |
meta_cdc_bq
|
Para transferência de conjunto de dados brutos > conjunto de dados de CDC |
meta_reporting_bq
|
Para transferência de conjunto de dados de CDC > conjunto de dados de relatórios |
Permissões da conta de serviço do Airflow gerenciado
Conceda permissões do Dataflow à conta de serviço usada no Airflow Gerenciado (conforme configurado na conexão meta_raw_dataflow).
Consulte as instruções na documentação do Dataflow. A conta de serviço também precisa da permissão Secret Manager Secret Accessor. Confira detalhes
na documentação de controle de acesso.
Parâmetros de solicitação
O diretório src/Meta/config/request_parameters contém um arquivo de especificação de solicitação de API para cada entidade extraída da API Marketing da Meta. Cada arquivo de solicitação contém uma lista de campos a serem buscados na API Marketing da Meta, um campo por linha. Confira mais informações na referência da API Marketing da Meta.
Configurações de ingestão
Controle os pipelines de dados Source to Raw e Raw to CDC pelas configurações no arquivo src/Meta/config/ingestion_settings.yaml.
Esta seção descreve os parâmetros de cada pipeline de dados.
Tabelas de origem para bruto
Esta seção tem entradas que controlam quais entidades são buscadas pelas APIs e como. Cada entrada corresponde a uma entidade da API Marketing da Meta. Com base nessa configuração, o Cortex Framework cria DAGs do Airflow que executam pipelines do Dataflow para buscar dados usando as APIs Marketing da Meta.
O arquivo src/Meta/src/raw/pipelines/config.ini controla alguns comportamentos do DAG do Airflow gerenciado e como as APIs Marketing da Meta são consumidas.
Encontre descrições para cada parâmetro no arquivo.
Os parâmetros a seguir controlam as configurações de Source to Raw para cada entrada:
| Parâmetro | Descrição |
base_table
|
Tabela no conjunto de dados brutos em que os dados buscados
são armazenados (por exemplo, customer).
|
load_frequency
|
Com que frequência um DAG é executado para buscar dados da Meta. Para mais informações sobre os valores possíveis, consulte a documentação do Airflow. |
object_endpoint
|
Caminho do endpoint de API (por exemplo,
campaigns para o endpoint /{account_id}/campaigns).
|
entity_type
|
Tipo de tabela (deve ser um de
fact, dimension ou addaccount).
|
object_id_column
|
Colunas (separadas por vírgula) que
formam um registro exclusivo para essa tabela. Necessário apenas
quando entity_type é fact.
|
breakdowns
|
Opcional: colunas de detalhamento
(separadas por vírgula) para endpoints de insights. Aplicável apenas
quando entity_type é fact.
|
action_breakdowns
|
Opcional: colunas de detalhamento de ação
(separadas por vírgula) para endpoints de insights. Aplicável apenas
quando entity_type é fact.
|
partition_details
|
Opcional: Se você quiser que essa tabela seja particionada para considerações de performance. Para mais informações, consulte Particionamento de tabelas. |
cluster_details
|
Opcional: Se você quiser que essa tabela seja agrupada para considerações de performance. Para mais informações, consulte Configurações de cluster. |
Tabelas brutas para CDC
Esta seção descreve as entradas que controlam como os dados são movidos de tabelas brutas para tabelas de CDC. Cada entrada corresponde a uma tabela bruta (que, por sua vez, corresponde à entidade da API da Meta, conforme mencionado).
Os parâmetros a seguir controlam as configurações de Raw to CDC para cada entrada:
| Parâmetro | Descrição |
base_table
|
Tabela em que os dados brutos foram
replicados. Uma tabela com o mesmo nome no conjunto de dados de CDC armazena
os dados brutos após a transformação de CDC (por exemplo, campaign_insights).
|
row_identifiers
|
Colunas (separadas por vírgula) que formam um registro exclusivo para essa tabela. |
load_frequency
|
Com que frequência um DAG para esta entidade é executado para preencher a tabela de CDC. Para mais informações sobre os valores possíveis, consulte a documentação do Airflow. |
partition_details
|
Opcional: Se você quiser que essa tabela seja particionada para considerações de performance. Para mais informações, consulte Particionamento de tabelas. |
cluster_details
|
Opcional: Se você quiser que essa tabela seja agrupada para considerações de performance. Para mais informações, consulte Configurações de cluster. |
Esquema da tabela de CDC
Para a Meta, todos os campos são armazenados no formato de string na camada bruta. Na camada de CDC, os tipos primitivos são convertidos em tipos de dados da empresa relevantes, e todos os tipos complexos são armazenados no formato JSON do BigQuery.
Para ativar essa conversão, o diretório src/Meta/config/table_schema contém um arquivo de esquema para cada entidade especificada na seção raw_to_cdc_tables que explica como traduzir corretamente cada tabela bruta do BigQuery para a tabela de CDC.
Cada arquivo de esquema contém três colunas:
SourceField: nome do campo da tabela bruta para essa entidade.TargetField: nome da coluna na tabela de CDC para essa entidade.DataType: tipo de dados de cada campo da tabela de CDC.
Configurações de relatório
É possível configurar e controlar como o Cortex gera dados para a camada de relatórios finais da Meta usando o arquivo de configurações de relatórios (src/Meta/config/reporting_settings.yaml). Esse arquivo controla como os objetos do BigQuery da camada de relatórios (tabelas, visualizações, funções ou procedimentos armazenados) são gerados.
Para mais informações, consulte Como personalizar o arquivo de configurações de relatórios.
A seguir
- Para mais informações sobre outras fontes de dados e cargas de trabalho, consulte Fontes de dados e cargas de trabalho.
- Para mais informações sobre as etapas de implantação em ambientes de produção, consulte Pré-requisitos de implantação do Cortex Framework Data Foundation.