
AI 영역은 인공지능 및 머신러닝 (AI 및 ML) 학습 및 추론 워크로드에 사용되는 전문 영역입니다. 이러한 인스턴스는 상당한 ML 가속기 (GPU 및 TPU) 용량을 제공합니다.
리전 내에서 AI 영역은 표준(비 AI) 영역과 지리적으로 떨어져 있습니다. 다음 그림은 us-central1 리전의 표준 영역에 비해 더 멀리 있는 AI 영역(us-central1-ai1a)의 예를 보여줍니다.
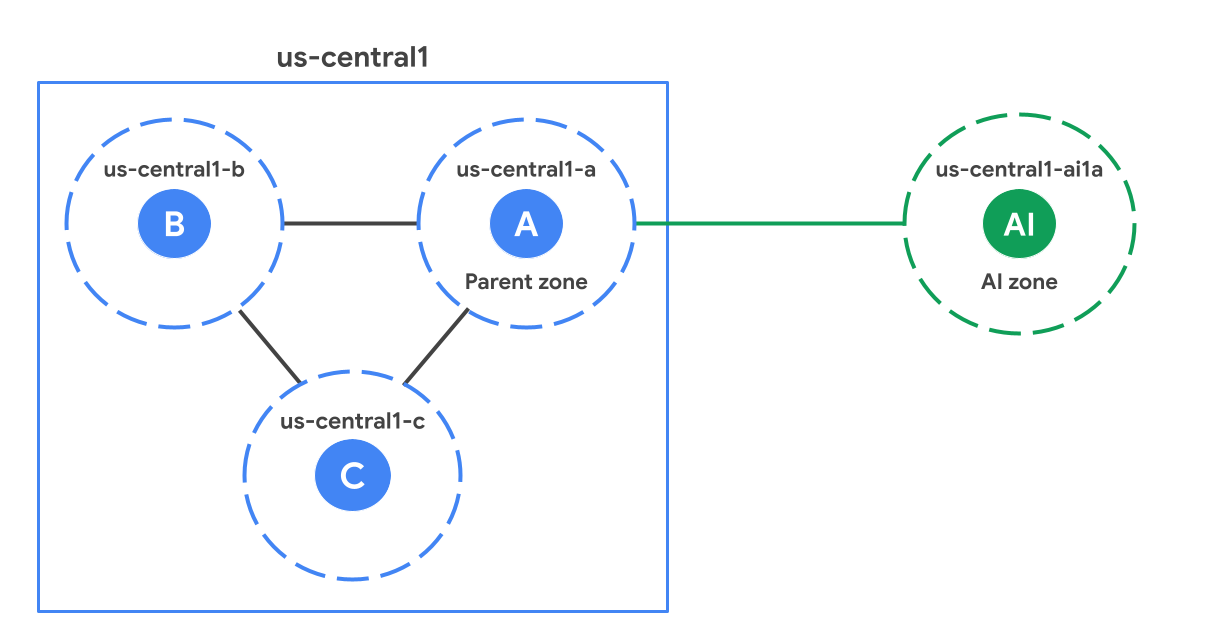
부모 영역
각 AI 영역은 리전의 표준 영역과 연결되며 이를 상위 영역이라고 합니다. 상위 영역은 AI 영역과 동일한 접미사가 있는 표준 영역입니다. 예를 들어 다이어그램에서 us-central1-a는 us-central1-ai1a의 상위 영역입니다. 소프트웨어 업데이트 일정을 공유하고 인프라를 공유하는 경우도 있습니다. 즉, 상위 영역에 영향을 미치는 소프트웨어 또는 인프라 문제도 AI 영역에 영향을 미칠 수 있습니다. 고가용성 솔루션을 설계할 때는 고가용성 (HA) 고려사항을 검토하여 상위 영역에 대한 종속성을 고려하세요.
AI 영역을 사용해야 하는 경우
AI 영역은 AI 및 ML 워크로드에 최적화되어 있습니다. 다음 안내에 따라 AI 영역에 가장 적합한 워크로드와 표준 영역에 더 적합한 워크로드를 결정하세요.
추천 대상:
대규모 학습: 다수의 액셀러레이터를 사용할 수 있으므로 대규모 언어 모델 (LLM) 및 파운데이션 모델 학습과 같은 대규모 학습 워크로드에 적합합니다.
소규모 학습, 파인 튜닝, 대량 추론, 재학습: AI 영역은 상당한 액셀러레이터 용량이 필요한 워크로드에 적합합니다.
실시간 ML 추론: AI 영역은 실시간 추론 워크로드를 지원합니다. 특히 워크로드에 상위 리전으로의 왕복 요청이 필요한 경우 성능은 애플리케이션 설계 및 모델 지연 시간 요구사항에 따라 달라집니다.
다음의 경우 권장하지 않음:
- 비 ML 워크로드: AI 영역은 모든 Google Cloud 서비스를 로컬로 제공하지 않으므로 비 ML 워크로드는 표준 영역에서 실행하는 것이 좋습니다.
AI 영역에서 서비스 액세스
AI 영역에서 Google Cloud 리전의 모든 Google Cloud 제품에 액세스할 수 있습니다. 하지만 AI 영역은 리전의 표준 영역 위치와 물리적으로 분리되어 있으므로 AI 영역에서 Google Cloud 리전의 서비스에 액세스하면 네트워크 지연 시간이 추가될 수 있습니다.
특정 제품은 AI 영역에서 영역 리소스를 로컬로 만들거나 액세스하는 것을 지원합니다. 이러한 서비스에 대한 자세한 내용은 다음 표를 참고하세요.
| 제품 | 설명 |
|---|---|
| Google Kubernetes Engine(GKE) | ComputeClass, 노드 자동 프로비저닝, GKE Standard 노드 풀을 사용한 구성을 비롯하여 GKE 클러스터에서 AI 영역을 사용하기 위한 설정 GKE에서 AI 영역 사용 |
| Cloud Storage | 활성 작업 중 성능을 극대화하는 영역 스토리지와 데이터 세트 및 모델 체크포인트를 위한 영구 스토리지를 비롯한 AI 영역의 워크로드용 객체 스토리지 구성 Cloud Storage에서 AI 영역 사용 |
| Compute Engine | 명명 규칙, 액셀러레이터 유형 또는 머신 유형별로 필터링하는 방법을 비롯하여 콘솔, Google Cloud CLI, REST API를 사용하여 사용 가능한 AI 영역을 식별하는 방법 사용 가능한 AI 영역 찾기 |
위치
AI 영역은 다음 위치에서 사용할 수 있습니다.
| AI 영역 | AI 영역 위치 | Google Cloud 리전 | Google Cloud 리전 위치 | 상위 영역 |
|---|---|---|---|---|
us-south1-ai1b |
북미 텍사스 오스틴 | us-south1 |
북미 텍사스 댈러스 | us-south1-b |
us-central1-ai1a |
북미 네브래스카 링컨 | us-central1 |
북미 아이오와 카운슬블러프즈 | us-central1-a |
AI 영역 사용
AI 영역은 Google Cloud 콘솔, Google Cloud CLI 또는 REST를 통해 액세스할 수 있습니다. 하지만Google Cloud 콘솔을 사용하여 VM을 만드는 경우 AI 영역을 수동으로 선택해야 합니다. 표준 영역과 달리 자동으로 선택되지 않습니다. 다음 기능과 함께 AI 영역을 사용하려면 이러한 리소스를 설정할 때 AI 영역을 명시적으로 선택해야 합니다.
특정 Compute Engine 및 GKE 기능: 특정 Compute Engine 및 GKE 리전 기능 (예: 리전 관리형 인스턴스 그룹, 리전 GKE 클러스터)에서는 AI 영역이 자동으로 선택되지 않습니다. GKE에 관한 자세한 내용은 GKE 문서를 참고하세요.
비가속기 워크로드 제한사항: AI 영역에서 CPU 전용 VM을 실행할 때는 Compute Engine에서 적용하는 제한사항에 유의하세요. 여기에는 GPU:CPU 비율 및 예약 요구사항이 포함될 수 있습니다.
Vertex AI: GKE 기반 Vertex AI 리전 제품은 리전 클러스터에 AI 영역을 포함하도록 GKE를 구성해야 합니다. Vertex AI를 선택할 필요는 없습니다. Vertex AI가 이 구성을 관리합니다.
Google Cloud 서비스 메타데이터 위치 API: locations.list API를 사용할 때
--extraLocationTypes플래그를 사용 설정해야 AI 영역이 이를 사용하려는 사용자에게만 표시됩니다.
GKE에서 AI 영역 사용
기본적으로 GKE는 AI 영역에 워크로드를 배포하지 않습니다. AI 영역을 사용하려면 다음 옵션 중 하나를 구성합니다.
ComputeClasses: AI 영역에서 주문형 TPU를 요청하도록 가장 높은 우선순위를 설정합니다. ComputeClass를 사용하면 워크로드의 하드웨어 구성에 우선순위를 지정할 수 있습니다. 예시는 ComputeClass 정보를 참고하세요.
노드 자동 프로비저닝: 포드 사양에서
nodeSelector또는nodeAffinity를 사용하여 AI 영역에 노드 풀을 만들도록 노드 자동 프로비저닝에 지시합니다. 워크로드에서 AI 영역을 명시적으로 타겟팅하지 않으면 노드 자동 프로비저닝은 새 노드 풀을 만들 때 표준 영역만 고려합니다. 이 구성을 사용하면 AI/ML 모델을 실행하지 않는 워크로드가 명시적으로 다르게 구성하지 않는 한 표준 영역에 유지됩니다.nodeSelector를 사용하는 매니페스트의 예는 자동 생성 노드의 기본 영역 설정을 참고하세요.GKE Standard: 노드 풀을 직접 관리하는 경우 노드 풀을 만들 때
--node-locations플래그에서 AI 영역을 사용합니다. 예를 보려면 GKE Standard에 TPU 워크로드 배포를 참고하세요.
제한사항
AI 영역에서는 다음을 사용할 수 없습니다.
AI 영역 설계 고려사항
AI 영역을 사용하도록 애플리케이션을 설계할 때는 다음 사항을 고려하세요.
고가용성 (HA) 고려사항
AI 영역은 소프트웨어 출시 및 인프라를 상위 영역과 공유합니다. 워크로드의 고가용성을 보장하려면 영역을 선택할 때(자동 또는 수동) 다음 배포 패턴을 피하세요.
AI 영역과 상위 영역에 HA 워크로드를 배포하지 마세요.
동일한 상위 영역을 공유하는 두 AI 영역에 HA 워크로드를 배포하지 마세요.
스토리지 권장사항
비용, 내구성, 성능의 균형을 맞추려면 계층화된 스토리지 아키텍처를 사용하는 것이 좋습니다.
- 콜드 스토리지 레이어: 학습 데이터 세트와 모델 체크포인트를 지속적이고 내구성이 뛰어난 스토리지에 저장하려면 표준 영역의 리전 Cloud Storage 버킷을 사용하세요.
성능 레이어: 특수 영역 스토리지 서비스를 사용하여 고속 캐시 또는 임시 스크래치 공간으로 작동합니다. 이 접근 방식은 활성 작업 중에 영역 간 지연 시간을 없애고 goodput을 극대화합니다.
GPU와 TPU가 완전히 포화 상태를 유지하여 유효 처리량을 최대화하려면 컴퓨팅 리소스와 동일한 AI 영역에 성능 레이어를 프로비저닝하세요.
AI 영역으로 AI 및 ML 시스템 성능을 최적화하려면 다음 스토리지 솔루션을 사용하는 것이 좋습니다.
| 스토리지 서비스 | 설명 | 사용 사례 |
|---|---|---|
| Cloud Storage의 Anywhere Cache 기능 | 버킷에서 자주 읽는 데이터를 AI 영역으로 가져오는 완전 관리형 SSD 지원 영역별 읽기 캐시입니다. | 추천 대상:
|