
Managed Airflow (Gen 3) | Managed Airflow (Gen 2) | Managed Airflow (Legacy Gen 1)
Diese Seite enthält Schritte zur Fehlerbehebung und Informationen zu häufigen Workflow-Problemen.
Viele Probleme bei der DAG-Ausführung werden durch eine nicht optimale Leistung der Umgebung verursacht. Sie können Ihre Umgebung optimieren, indem Sie dem Leitfaden zum Optimieren von Umgebungsleistung und ‑kosten folgen.
Einige Probleme bei der DAG-Ausführung können dadurch verursacht werden, dass der Airflow-Scheduler nicht richtig oder optimal funktioniert. Folgen Sie der Anleitung zur Fehlerbehebung für den Scheduler, um diese Probleme zu beheben.
Fehlerbehebung beim Workflow
So beginnen Sie mit der Fehlerbehebung:
Prüfen Sie die Airflow-Logs.
Sie können die Logging-Ebene von Airflow erhöhen, indem Sie die folgende Airflow-Konfigurationsoption überschreiben.
Bereich Schlüssel Wert logginglogging_levelDer Standardwert ist INFO. Wenn SieDEBUGfestlegen, werden in Logmeldungen mehr Details angezeigt.Sehen Sie sich das Monitoring-Dashboard an.
Suchen Sie in der Google Cloud Console nach Fehlern auf den Seiten für die Komponenten Ihrer Umgebung.
Prüfen Sie in der Airflow-Weboberfläche in der Grafikansicht des DAG, ob Aufgabeninstanzen fehlgeschlagen sind.
Bereich Schlüssel Wert webserverdag_orientationLR,TB,RLoderBT
Airflow-Aufgabenfehler mit Gemini Cloud Assist untersuchen
Gemini Cloud Assist investigations sind ein Ursachenanalysetool (RCA) zur Fehlerbehebung für Ihre Infrastruktur und Anwendungen in komplexen und verteilten Cloud-Umgebungen. Mithilfe von Prüfungen lassen sich Probleme in Google Cloudleichter nachvollziehen, diagnostizieren und beheben. Sie können damit die Incident Response optimieren, indem Sie die Zeit bis zur Lösung verkürzen und die Gesamtverfügbarkeit verbessern – und das alles mit weniger Aufwand.
In Managed Airflow können Sie Gemini Cloud Assist-Untersuchungen für fehlgeschlagene Airflow-Aufgaben über die DAG-UI starten. In Managed Airflow werden Details wie die Problembeschreibung und der Zeitraum automatisch ausgefüllt und Ihre Umgebung wird als relevante Ressource angegeben.
Prüfungen starten und ansehen
So starten Sie eine neue Gemini Cloud Assist-Prüfung für einen fehlgeschlagenen Airflow-Task oder rufen eine vorhandene Prüfung auf:
Rufen Sie in der Google Cloud Console die Seite Umgebungen auf.
Wählen Sie eine Umgebung aus, um die zugehörigen Details anzuzeigen.
Wechseln Sie auf der Seite Umgebungsdetails zum Tab DAGs.
Klicken Sie auf den Namen eines DAG.
Rufen Sie auf der Seite DAG-Details den Tab Ausführungsverlauf auf und klicken Sie auf einen DAG-Laufvorgang mit fehlgeschlagenen Aufgaben.
Klicken Sie in der Spalte Status der fehlgeschlagenen Airflow-Aufgabe auf Untersuchen:
- Klicken Sie bei einer neu untersuchten Aufgabe auf Untersuchen.
- Wenn für eine Aufgabe bereits eine Untersuchung vorhanden ist, klicken Sie auf Untersuchung ansehen, um die vorhandene Untersuchung zu prüfen. Alternativ können Sie eine weitere Prüfung starten, indem Sie auf Neue Prüfung klicken.
Erstellen, Ausführen und Überprüfen der Untersuchung mit Gemini Cloud Assist
Beispiel für eine Untersuchung
In diesem Beispiel wird der Prozess der Untersuchung einer fehlgeschlagenen Aufgabe gezeigt.
Beobachten Sie im Dashboard Monitoring > DAG Statistics (Monitoring > DAG-Statistiken) fehlgeschlagene DAG-Ausführungen:
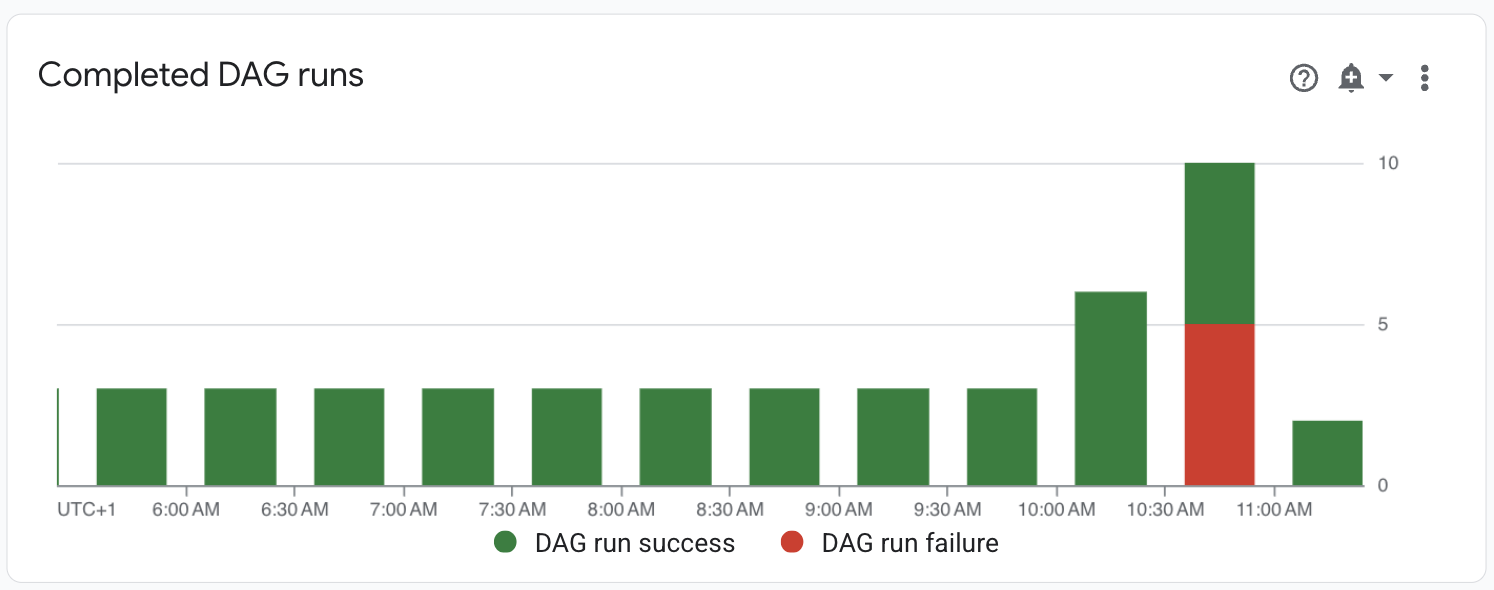
Abbildung 1. Diagramm der abgeschlossenen DAG-Ausführungen (zum Vergrößern klicken) Rufen Sie DAGs auf. In der Spalte Nicht erfolgreiche Ausführungen (1 Stunde) sehen Sie, dass die DAG
create_large_txt_file_print_logsin der letzten Stunde mehrere nicht erfolgreiche Ausführungen hatte. Klicken Sie auf den Namen des DAG.
Abbildung 2. Liste der DAGs mit Statistiken zu DAG-Ausführungen (zum Vergrößern klicken) Klicken Sie auf einen der fehlgeschlagenen DAG-Ausführungen und dann neben dem fehlgeschlagenen Airflow-Aufgabeneintrag auf Untersuchen, um die Untersuchung zu starten.
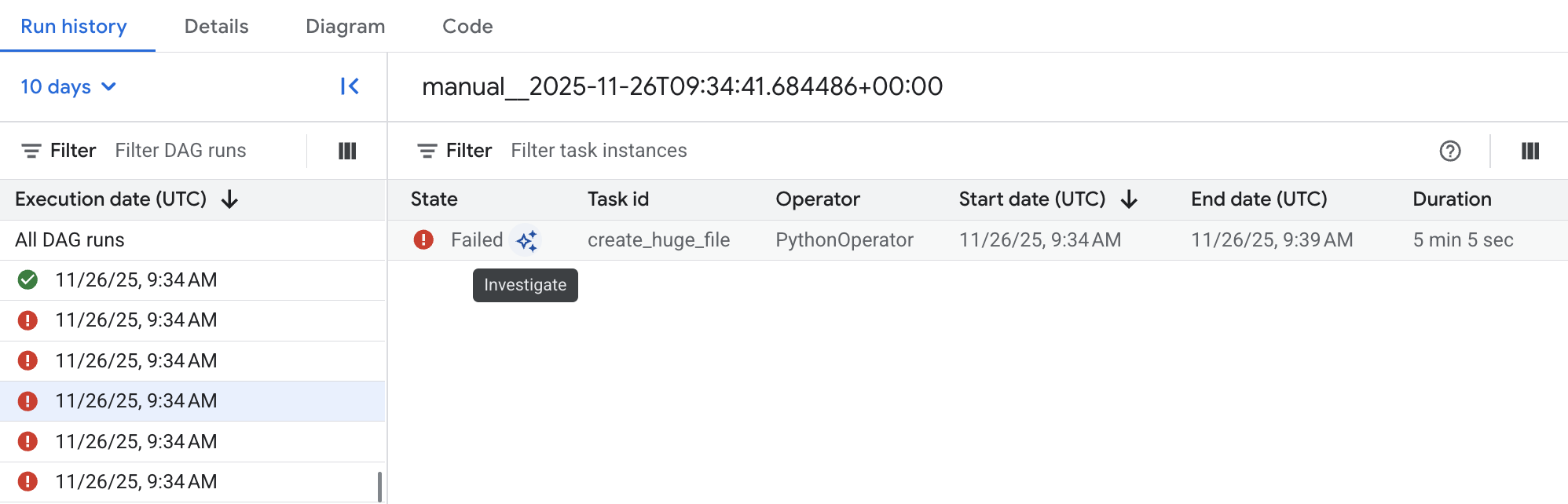
Abbildung 3. Liste der Aufgaben in den fehlerhaften DAGs (zum Vergrößern klicken) Warten Sie, bis die Untersuchung abgeschlossen ist.
In der Liste Relevante Beobachtungen wird der Prüfprozess beschrieben. In diesem Beispiel ist die Aufgabe fehlgeschlagen, ohne dass Logs generiert wurden. Gemini Cloud Assist konnte die Ursache des Fehlers jedoch in den Airflow-Scheduler-Logs finden. Dort wurde die Aufgabe als Zombie beendet.
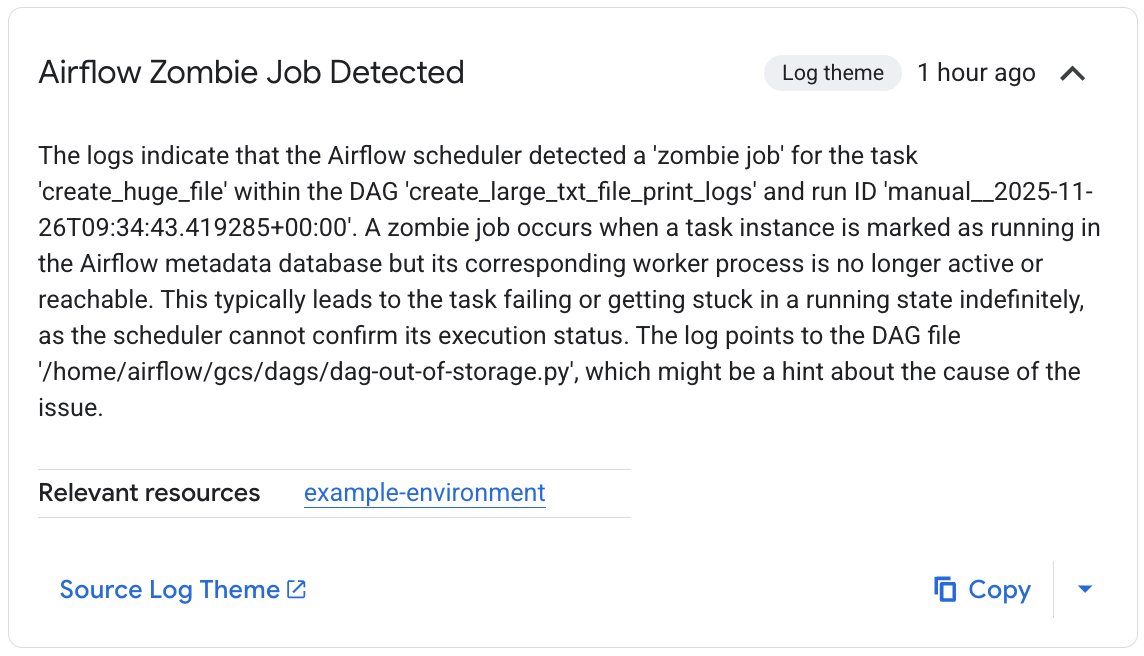
Abbildung 4: Beobachtung „Zombie-Job erkannt“ (zum Vergrößern klicken) Schließlich fasst Gemini Cloud Assist die Ergebnisse zusammen und liefert eine Hypothese sowie Empfehlungen zur Behebung des Problems. In diesem Beispiel ist die Aufgabe fehlgeschlagen, weil ein Airflow-Worker nicht genügend Ressourcen für die Verarbeitung hatte. Dies wird durch Beobachtungen des Worker-Pods unterstützt, der mehrmals mit einem OOM-Fehler neu gestartet wurde und dessen Aufgabe anschließend vom Planer als Zombie-Aufgabe beendet wurde.

Abbildung 5. Hypothese zur Erschöpfung von Airflow-Worker-Pod-Ressourcen (zum Vergrößern klicken)
Fehlerbehebung bei Operatorfehlern
So beheben Sie Operatorfehler:
- Suchen Sie nach aufgabenspezifischen Fehlern.
- Prüfen Sie die Airflow-Logs.
- Cloud Monitoring
- Prüfen Sie die operatorspezifischen Logs.
- Beheben Sie die Fehler.
- Laden Sie den DAG in den Ordner
/dagshoch. - Löschen Sie die vergangenen Status für den DAG in der Airflow-Weboberfläche.
- Setzen Sie den DAG fort oder führen Sie ihn aus.
Fehlerbehebung bei der Aufgabenausführung
Airflow ist ein verteiltes System mit vielen Einheiten wie Scheduler, Executor und Workern, die über eine Aufgabenwarteschlange und die Airflow-Datenbank miteinander kommunizieren und Signale (z. B. SIGTERM) senden. Das folgende Diagramm zeigt eine Übersicht über die Verbindungen zwischen Airflow-Komponenten.

In einem verteilten System wie Airflow kann es zu Problemen mit der Netzwerkverbindung kommen oder die zugrunde liegende Infrastruktur kann zeitweise Probleme haben. Dies kann dazu führen, dass Aufgaben fehlschlagen und zur Ausführung neu geplant werden oder dass Aufgaben nicht erfolgreich abgeschlossen werden (z. B. Zombie-Aufgaben oder Aufgaben, die bei der Ausführung hängen geblieben sind). Airflow verfügt über Mechanismen, um solche Situationen zu bewältigen und den normalen Betrieb automatisch wieder aufzunehmen. In den folgenden Abschnitten werden häufige Probleme beschrieben, die während der Ausführung von Aufgaben durch Airflow auftreten.
Aufgaben schlagen fehl, ohne Logs auszugeben
Eine Aufgabeninstanz kann aus verschiedenen Gründen fehlschlagen, ohne dass Protokolle ausgegeben werden. Das kann beispielsweise aufgrund von DAG-Parsing-Fehlern, Verzögerungen bei der DAG-Synchronisierung oder aufgrund eines Airflow-Worker-Pods, der während der Ausführung einer Aufgabe entfernt wird, passieren (siehe Aufgabe schlägt aufgrund von Pod-Entfernung fehl).
Zeitüberschreitungen oder Fehler beim Parsen von DAGs
Wenn eine DAG-Datei Programmierfehler enthält oder das Parsen einer DAG-Datei zu lange dauert, kann es passieren, dass der Airflow-Planer Aufgaben planen kann, Airflow-Worker sie aber nicht ausführen können. In diesem Fall kann eine Aufgabe als Failed markiert werden, ohne dass es einen Log von der Ausführung gibt.
Symptome
Airflow-Worker-Logs in Cloud Logging enthalten Nachrichten wie:
airflow.exceptions.AirflowException: Dag "example-dag" could not be found; either it does not exist or it failed to parse.airflow.exceptions.AirflowTaskTimeout: Timeout, PID: 12345(diese Meldung enthält möglicherweise nicht den DAG-Namen oder den Dateipfad).ERROR - Failed to import: /home/airflow/gcs/dags/example-dag.py(ohne detaillierte Tracebacks).
Wenn es DAG-Importfehler gibt, werden sie möglicherweise in der Airflow-UI oder als
Broken DAG-Meldungen auf der Seite Umgebungsdetails in derGoogle Cloud -Konsole angezeigt.
Lösung
Prüfen Sie die Airflow-Worker-Logs auf Fehler im Zusammenhang mit dem DAG-Parsing. Wenn
AirflowTaskTimeout-Fehler angezeigt werden, kann es sein, dass das DAG-Parsing ein Zeitlimit überschreitet. Das Parsing-Zeitlimit für Airflow-Worker wird durchdagbag_import_timeoutgesteuert.Wenn die DAG-Parsing-Zeiten lang sind, prüfen Sie, ob es in Ihrem Cluster zu CPU-Konflikten kommt. Wenn Worker nicht genügend CPU haben: Erhöhen Sie die CPU für Airflow-Worker. Alternativ können Sie „worker_concurrency“ reduzieren, wie unter Umgebung optimieren beschrieben.
Wenn die CPU-Auslastung niedrig ist, optimieren Sie die DAG-Definition, um die Parsing-Zeit zu verkürzen, z. B. indem Sie Code auf oberster Ebene vermeiden.
Wenn Sie
Failed to import-Fehler oder Fehler in der Airflow-UI oder derGoogle Cloud -Konsole sehen, prüfen Sie die DAG-Prozessor-Logs auf detaillierte Tracebacks, wie unter Probleme mit dem DAG-Prozessor beheben beschrieben. Alternativ können Sie DAG-Importfehler mit dem folgenden gcloud CLI-Befehl aufrufen:gcloud composer environments run ENVIRONMENT_NAME \ --location LOCATION \ dags list-import-errorsWenn in Ihrem DAG während des Parsens externe Dienste aufgerufen werden, sollten Sie
try...except-Blöcke um diese Aufrufe herum hinzufügen, um vorübergehende Fehler zu beheben.Wenn die Optimierung des DAG-Parsings nicht möglich ist, erhöhen Sie
dagbag_import_timeout. Überschreiben Sie diese Airflow-Konfigurationsoption mit einem höheren Wert als dem Standardwert von 30 Sekunden, z. B. 120 Sekunden.
Verzögerungen bei der Synchronisierung von DAG-Dateien
Wenn Sie DAG-Dateien in den Bucket Ihrer Umgebung hochladen oder aktualisieren, dauert es einige Zeit, bis diese Dateien mit Airflow-Workern und -Planern synchronisiert werden.
Diese Synchronisierung erfolgt unabhängig auf allen Planern und Workern. Wenn Sie einen DAG-Lauf kurz nach dem Hochladen oder Aktualisieren einer DAG-Datei auslösen und die DAG-Datei noch nicht mit einem Worker synchronisiert wurde, der eine Aufgabe übernimmt, schlägt die Aufgabe ohne Logs fehl. In den Worker-Logs wird möglicherweise airflow.exceptions.AirflowException: Dag "example-dag" could not be
found... angezeigt.
Diese Synchronisierung dauert in der Regel 1 bis 2 Minuten, kann aber länger dauern, wenn sich viele oder große Dateien in den Ordnern dags/ oder plugins/ im Bucket befinden.
Lösung
Warten Sie nach dem Hochladen oder Aktualisieren von DAGs oder Plug-ins mindestens 2 Minuten, bevor Sie DAGs auslösen oder aktivieren.
Aufgaben bleiben im Status „In der Warteschlange“
In Airflow-Versionen vor 2.6.3 können Aufgaben manchmal dauerhaft im Status queued hängen bleiben. Das kann passieren, wenn eine Aufgabe in der Airflow-Datenbank als in der Warteschlange stehend markiert ist, aber in Celery nicht vorhanden ist.
In diesem Fall können Airflow-Worker bei Aktivitätsprüfungen fehlschlagen und neu gestartet werden. Dies kann wiederum dazu führen, dass Aufgaben mit Fehlern vom Typ „Log file is not found“ (Logdatei nicht gefunden) fehlschlagen.
Dieses Problem wurde in Airflow 2.6.3 und höher behoben. Wenn Sie eine frühere Airflow-Version verwenden, können Sie Ihre Umgebung auf eine Image-Version aktualisieren, die Airflow 2.6.3 oder höher verwendet.
Als Workaround können Sie Aufgaben, die im Status „In der Warteschlange“ hängen geblieben sind, manuell löschen. Rufen Sie in der Airflow-UI Browse > Task Instances auf, suchen Sie nach Aufgabeninstanzen, die im Status queued hängen geblieben sind, und legen Sie ihren Status auf failed fest.
Aufgaben werden abrupt unterbrochen
Während der Ausführung von Aufgaben können Airflow-Worker aufgrund von Problemen, die nicht speziell mit der Aufgabe selbst zusammenhängen, abrupt beendet werden. Eine Liste solcher Szenarien und möglicher Lösungen finden Sie unter Häufige Ursachen. In den folgenden Abschnitten werden einige zusätzliche Symptome behandelt, die auf diese Ursachen zurückzuführen sein könnten:
Zombie-Aufgaben
Airflow erkennt zwei Arten von Abweichungen zwischen einer Aufgabe und einem Prozess, der die Aufgabe ausführt:
Zombie-Aufgaben sind Aufgaben, die ausgeführt werden sollten, aber nicht ausgeführt werden. Dies kann passieren, wenn der Prozess der Aufgabe beendet wurde oder nicht reagiert, wenn der Airflow-Worker den Aufgabenstatus nicht rechtzeitig gemeldet hat, weil er überlastet ist, oder wenn die VM, auf der die Aufgabe ausgeführt wird, heruntergefahren wurde. Airflow findet solche Aufgaben regelmäßig und führt sie entweder fehl oder versucht es noch einmal, je nach den Einstellungen der Aufgabe.
Zombie-Aufgaben erkennen
resource.type="cloud_composer_environment" resource.labels.environment_name="ENVIRONMENT_NAME" log_id("airflow-scheduler") textPayload:"Detected zombie job"Zombie-Aufgaben sind Aufgaben, die eigentlich nicht ausgeführt werden sollten. Airflow sucht regelmäßig nach solchen Tasks und beendet sie.
Weitere Informationen zur Fehlerbehebung bei Zombie-Aufgaben finden Sie unter Häufige Ursachen.
SIGTERM-Signale
SIGTERM-Signale werden von Linux, Kubernetes, dem Airflow-Scheduler und Celery verwendet, um Prozesse zu beenden, die für die Ausführung von Airflow-Workern oder Airflow-Tasks verantwortlich sind.
Es kann mehrere Gründe geben, warum SIGTERM-Signale in einer Umgebung gesendet werden:
Eine Aufgabe ist zu einer Zombie-Aufgabe geworden und muss beendet werden.
Der Scheduler hat ein Duplikat einer Aufgabe erkannt und sendet die Signale „Terminating instance“ (Instanz wird beendet) und SIGTERM an die Aufgabe, um sie zu beenden.
Beim horizontalen Pod-Autoscaling sendet die GKE-Steuerungsebene SIGTERM-Signale, um nicht mehr benötigte Pods zu entfernen.
Der Planer kann SIGTERM-Signale an den DagFileProcessorManager-Prozess senden. Solche SIGTERM-Signale werden vom Scheduler verwendet, um den Lebenszyklus des DagFileProcessorManager-Prozesses zu verwalten, und können gefahrlos ignoriert werden.
Beispiel:
Launched DagFileProcessorManager with pid: 353002 Sending Signals.SIGTERM to group 353002. PIDs of all processes in the group: [] Sending the signal Signals.SIGTERM to group 353002 Sending the signal Signals.SIGTERM to process 353002 as process group is missing.Race-Bedingung zwischen dem Heartbeat-Callback und den Exit-Callbacks im local_task_job, der die Ausführung der Task überwacht. Wenn der Heartbeat erkennt, dass eine Aufgabe als erfolgreich markiert wurde, kann er nicht unterscheiden, ob die Aufgabe selbst erfolgreich war oder ob Airflow angewiesen wurde, die Aufgabe als erfolgreich zu betrachten. Trotzdem wird ein Task-Runner beendet, ohne auf das Beenden zu warten.
Solche SIGTERM-Signale können ignoriert werden. Die Aufgabe befindet sich bereits im Status „Erfolgreich“ und die Ausführung des DAG-Laufs als Ganzes ist davon nicht betroffen.
Der Logeintrag
Received SIGTERM.ist der einzige Unterschied zwischen dem regulären Beenden und dem Beenden der Aufgabe im Status „Erfolgreich“.
Abbildung 7. Race-Bedingung zwischen den Heartbeat- und Exit-Callbacks (zum Vergrößern klicken) Eine Airflow-Komponente verwendet mehr Ressourcen (CPU, Arbeitsspeicher) als vom Clusterknoten zulässig.
Der GKE-Dienst führt Wartungsvorgänge aus und sendet SIGTERM-Signale an Pods, die auf einem Knoten ausgeführt werden, der aktualisiert werden soll.
Wenn eine Aufgabeninstanz mit SIGTERM beendet wird, können Sie die folgenden Logeinträge in den Logs eines Airflow-Workers sehen, der die Aufgabe ausgeführt hat:
{local_task_job.py:211} WARNING - State of this instance has been externally set to queued. Terminating instance. {taskinstance.py:1411} ERROR - Received SIGTERM. Terminating subprocesses. {taskinstance.py:1703} ERROR - Task failed with exception
Mögliche Lösungen:
Dieses Problem tritt auf, wenn auf einer VM, auf der die Aufgabe ausgeführt wird, nicht genügend Arbeitsspeicher vorhanden ist. Dies hängt nicht mit Airflow-Konfigurationen, sondern mit der Menge an Arbeitsspeicher zusammen, die für die VM verfügbar ist.
In Managed Airflow (Gen 2) können Sie Airflow-Workern mehr CPU- und Arbeitsspeicherressourcen zuweisen.
Sie können den Wert der Airflow-Konfigurationsoption
[celery]worker_concurrencyconcurrency senken. Diese Option legt fest, wie viele Aufgaben von einem bestimmten Airflow-Worker gleichzeitig ausgeführt werden.
Weitere Informationen zum Optimieren Ihrer Umgebung finden Sie unter Umgebungsleistung und -kosten optimieren.
Airflow-Task wurde von Negsignal.SIGKILL unterbrochen
Manchmal verwendet Ihre Aufgabe möglicherweise mehr Arbeitsspeicher, als dem Airflow-Worker zugewiesen ist.
In diesem Fall wird die Wiedergabe möglicherweise durch Negsignal.SIGKILL unterbrochen. Das System sendet dieses Signal, um weiteren Speicherverbrauch zu vermeiden, der sich auf die Ausführung anderer Airflow-Aufgaben auswirken könnte. Im Log des Airflow-Workers wird möglicherweise der folgende Logeintrag angezeigt:
{local_task_job.py:102} INFO - Task exited with return code Negsignal.SIGKILL
Negsignal.SIGKILL kann auch als Code -9 angezeigt werden.
Mögliche Lösungen:
Niedrigerer
worker_concurrencyvon Airflow-Workern.Erhöhen Sie den für Airflow-Worker verfügbaren Arbeitsspeicher.
Ressourcenintensive Aufgaben in Managed Airflow können Sie mit KubernetesPodOperator oder GKEStartPodOperator verwalten, um Tasks zu isolieren und Ressourcen individuell zuzuweisen.
Optimieren Sie Ihre Aufgaben, damit sie weniger Arbeitsspeicher verwenden.
Aufgabe schlägt aufgrund von Ressourcenknappheit fehl
Symptom: Während der Ausführung einer Aufgabe wird der für die Ausführung der Airflow-Aufgabe verantwortliche Unterprozess des Airflow-Workers abrupt unterbrochen. Der im Log des Airflow-Workers sichtbare Fehler sieht möglicherweise so aus:
...
File "/opt/python3.8/lib/python3.8/site-packages/celery/app/trace.py", line 412, in trace_task R = retval = fun(*args, **kwargs) File "/opt/python3.8/lib/python3.8/site-packages/celery/app/trace.py", line 704, in __protected_call__ return self.run(*args, **kwargs) File "/opt/python3.8/lib/python3.8/site-packages/airflow/executors/celery_executor.py", line 88, in execute_command _execute_in_fork(command_to_exec) File "/opt/python3.8/lib/python3.8/site-packages/airflow/executors/celery_executor.py", line 99, in _execute_in_fork
raise AirflowException('Celery command failed on host: ' + get_hostname())airflow.exceptions.AirflowException: Celery command failed on host: airflow-worker-9qg9x
...
Lösung:
Erhöhen Sie in Managed Airflow (Gen 2) die Arbeitsspeicherlimits für Airflow-Worker.
Wenn in Ihrer Umgebung auch Zombie-Aufgaben generiert werden, lesen Sie den Abschnitt Fehlerbehebung bei Zombie-Aufgaben.
Eine Anleitung zum Debuggen von Problemen mit unzureichendem Arbeitsspeicher finden Sie unter DAG-Probleme mit unzureichendem Arbeitsspeicher und Speicherplatz beheben.
Task schlägt aufgrund von Pod-Entfernung fehl
Google Kubernetes Engine-Pods unterliegen dem Kubernetes-Pod-Lebenszyklus und der Pod-Bereinigung. Aufgabenspitzen sind die häufigste Ursache für die Pod-Bereinigung in Managed Airflow.
Eine Pod-Bereinigung kann auftreten, wenn ein bestimmter Pod Ressourcen eines Knotens relativ zu den konfigurierten Erwartungen in Sachen Ressourcenverbrauch für den Knoten übernutzt. Eine Bereinigung kann beispielsweise auftreten, wenn mehrere speicherintensive Aufgaben in einem Pod ausgeführt werden und ihre kombinierte Last dazu führt, dass der Knoten, auf dem dieser Pod ausgeführt wird, das Limit für den Arbeitsspeicherverbrauch überschreitet.
Wenn ein Airflow-Worker-Pod bereinigt wird, werden alle auf diesem Pod ausgeführten Aufgabeninstanzen unterbrochen und später von Airflow als fehlgeschlagen markiert.
Logs werden zwischengespeichert. Wenn ein Worker-Pod entfernt wird, bevor der Zwischenspeicher geleert wurde, werden keine Logs ausgegeben. Ein Aufgabenfehler ohne Logs ist ein Hinweis darauf, dass die Airflow-Worker aufgrund von zu wenig Arbeitsspeicher neu gestartet werden. In Cloud Logging sind möglicherweise einige Logs vorhanden, obwohl die Airflow-Logs nicht ausgegeben wurden.
So können die Logs angezeigt werden:
Rufen Sie in der Google Cloud Console die Seite Umgebungen auf.
Klicken Sie in der Liste der Umgebungen auf den Namen Ihrer Umgebung. Die Seite Umgebungsdetails wird geöffnet.
Rufen Sie den Tab Logs auf.
Sie können die Logs einzelner Airflow-Worker unter Alle Logs > Airflow-Logs > Worker ansehen.
Symptom:
Rufen Sie in der Google Cloud Console die Seite Arbeitslasten auf.
Wenn
airflow-worker-Pods vorhanden sind, dieEvictedanzeigen, klicken Sie auf die einzelnen bereinigten Pods und suchen Sie oben im Fenster nach folgender Meldung:The node was low on resource: memory.
Lösung:
Erhöhen Sie die Arbeitsspeicherlimits für Airflow-Worker.
Prüfen Sie die Logs von
airflow-worker-Pods auf mögliche Ursachen für die Bereinigung. Weitere Informationen zum Abrufen von Logs aus einzelnen Pods finden Sie unter Probleme mit bereitgestellten Arbeitslasten beheben.Achten Sie darauf, dass die Aufgaben im DAG idempotent und abrufbar sind.
Vermeiden Sie das Herunterladen unnötiger Dateien in das lokale Dateisystem von Airflow-Workern.
Airflow-Worker haben eine begrenzte Kapazität für das lokale Dateisystem. Ein Airflow-Worker kann 1 GB bis 10 GB Speicherplatz haben. Wenn der Speicherplatz knapp wird, wird der Airflow-Worker-Pod von der GKE-Steuerungsebene entfernt. Dadurch schlagen alle Aufgaben fehl, die der entfernte Worker ausgeführt hat.
Beispiele für problematische Vorgänge:
- Dateien oder Objekte herunterladen und lokal in einem Airflow-Worker speichern. Speichern Sie diese Objekte stattdessen direkt in einem geeigneten Dienst wie einem Cloud Storage-Bucket.
- Auf große Objekte im Ordner
/dataüber einen Airflow-Worker zugreifen Der Airflow-Worker lädt das Objekt in sein lokales Dateisystem herunter. Implementieren Sie Ihre DAGs stattdessen so, dass große Dateien außerhalb des Airflow-Worker-Pods verarbeitet werden.
Häufige Ursachen
Airflow-Worker hat nicht mehr genügend Arbeitsspeicher
Jeder Airflow-Worker kann bis zu [celery]worker_concurrency Aufgabeninstanzen gleichzeitig ausführen. Wenn der kumulative Arbeitsspeicherverbrauch dieser Aufgabeninstanzen das Arbeitsspeicherlimit für einen Airflow-Worker überschreitet, wird ein zufälliger Prozess darauf beendet, um Ressourcen freizugeben.
Ereignisse zu Airflow-Workern mit zu wenig Arbeitsspeicher erkennen
resource.type="k8s_node"
resource.labels.cluster_name="GKE_CLUSTER_NAME"
log_id("events")
jsonPayload.message:"Killed process"
jsonPayload.message:("airflow task" OR "celeryd")Manchmal kann der Arbeitsspeichermangel auf einem Airflow-Worker dazu führen, dass während einer SQLAlchemy-Sitzung fehlerhafte Pakete an die Datenbank, an einen DNS-Server oder an einen anderen Dienst gesendet werden, der von einem DAG aufgerufen wird. In diesem Fall lehnt das andere Ende der Verbindung möglicherweise Verbindungen vom Airflow-Worker ab oder trennt sie. Beispiel:
"UNKNOWN:Error received from peer
{created_time:"2024-11-31T10:09:52.217738071+00:00", grpc_status:14,
grpc_message:"failed to connect to all addresses; last error: UNKNOWN:
ipv4:<ip address>:443: handshaker shutdown"}"
Lösungen:
Optimieren Sie Aufgaben, damit sie weniger Speicherplatz benötigen, z. B. indem Sie Code auf oberster Ebene vermeiden.
Verringern
[celery]worker_concurrencyErhöhen Sie den Arbeitsspeicher für Airflow-Worker, um
[celery]worker_concurrency-Änderungen zu berücksichtigen.Aktualisieren Sie in Managed Airflow-Versionen (Gen 2) vor 2.6.0
[celery]worker_concurrencymit der aktuellen Formel, wenn dieser Wert niedriger ist.
Airflow-Worker wurde bereinigt
Pod-Bereinigungen sind ein normaler Teil der Ausführung von Arbeitslasten in Kubernetes. GKE entfernt Pods, wenn der Speicherplatz nicht mehr ausreicht oder um Ressourcen für Arbeitslasten mit höherer Priorität freizugeben.
Bereinigte Airflow-Worker
resource.type="k8s_pod"
resource.labels.cluster_name="GKE_CLUSTER_NAME"
resource.labels.pod_name:"airflow-worker"
log_id("events")
jsonPayload.reason="Evicted"Lösungen:
- Wenn ein Ausschluss durch Speichermangel verursacht wird, können Sie die Speichernutzung reduzieren oder temporäre Dateien entfernen, sobald sie nicht mehr benötigt werden.
Alternativ können Sie den verfügbaren Speicherplatz erhöhen oder Arbeitslasten in einem dedizierten Pod mit
KubernetesPodOperatorausführen.
Airflow-Worker wurde beendet
Airflow-Worker können extern entfernt werden. Wenn aktuell ausgeführte Aufgaben während eines ordnungsgemäßen Beendigungszeitraums nicht abgeschlossen werden, werden sie unterbrochen und möglicherweise als Zombieprozesse erkannt.
Beendigung von Airflow-Worker-Pods erkennen
resource.type="k8s_cluster" resource.labels.cluster_name="GKE_CLUSTER_NAME" protoPayload.methodName:"pods.delete" protoPayload.response.metadata.name:"airflow-worker"
Mögliche Szenarien und Lösungen:
Airflow-Worker werden bei Umgebungsänderungen wie Upgrades oder Paketinstallationen neu gestartet:
Änderungen an Composer-Umgebungen erkennen
resource.type="cloud_composer_environment" resource.labels.environment_name="ENVIRONMENT_NAME" log_id("cloudaudit.googleapis.com%2Factivity")Sie können solche Vorgänge ausführen, wenn keine kritischen Aufgaben ausgeführt werden, oder Wiederholungsversuche für Aufgaben aktivieren.
Während der Wartungsarbeiten sind verschiedene Komponenten möglicherweise vorübergehend nicht verfügbar.
GKE-Wartungsvorgänge
resource.type="gke_nodepool" resource.labels.cluster_name="GKE_CLUSTER_NAME" protoPayload.metadata.operationType="UPGRADE_NODES"
Sie können Wartungsfenster angeben, um
überschneidet sich mit der Ausführung kritischer Aufgaben.
In Managed Airflow-Versionen (Gen 2) vor 2.4.5 ignoriert ein beendeter Airflow-Worker möglicherweise das SIGTERM-Signal und führt weiterhin Aufgaben aus:
Herunterskalieren durch Composer-Autoscaling
resource.type="cloud_composer_environment" resource.labels.environment_name="ENVIRONMENT_NAME" log_id("airflow-worker-set") textPayload:"Workers deleted"Sie können ein Upgrade auf eine neuere Managed Airflow-Version durchführen, in der dieses Problem behoben ist.
Airflow-Worker war stark ausgelastet
Die Menge an CPU- und Arbeitsspeicherressourcen, die einem Airflow-Worker zur Verfügung stehen, wird durch die Konfiguration der Umgebung begrenzt. Wenn die Ressourcennutzung sich den Limits nähert, kann dies zu Ressourcenkonflikten und unnötigen Verzögerungen bei der Ausführung von Aufgaben führen. In extremen Situationen, in denen Ressourcen über längere Zeiträume fehlen, kann dies zu Zombie-Aufgaben führen.
Lösungen:
- Worker-CPU- und -Arbeitsspeichernutzung überwachen und anpassen, damit sie nicht über 80 % liegt.
Cloud Logging-Abfragen, um die Gründe für Pod-Neustarts oder ‑Entfernungen zu ermitteln
In den Umgebungen von Managed Airflow werden GKE-Cluster als Recheninfrastrukturebene verwendet. In diesem Abschnitt finden Sie nützliche Abfragen, mit denen Sie die Gründe für Neustarts oder Entfernungen von Airflow-Workern oder Airflow-Planern ermitteln können.
Die folgenden Abfragen können so angepasst werden:
Sie können den gewünschten Zeitraum in Cloud Logging angeben. Sie können beispielsweise die letzten 6 Stunden oder 3 Tage auswählen oder einen benutzerdefinierten Zeitraum definieren.
Sie müssen den Namen des Clusters Ihrer Umgebung in CLUSTER_NAME angeben.
Sie können die Suche auf einen bestimmten Pod beschränken, indem Sie POD_NAME hinzufügen.
Neu gestartete Container ansehen
resource.type="k8s_node"
log_id("kubelet")
jsonPayload.MESSAGE:"will be restarted"
resource.labels.cluster_name="CLUSTER_NAME"
Alternative Abfrage, um die Ergebnisse auf einen bestimmten Pod zu beschränken:
resource.type="k8s_node"
log_id("kubelet")
jsonPayload.MESSAGE:"will be restarted"
resource.labels.cluster_name="CLUSTER_NAME"
"POD_NAME"
Container finden, die aufgrund eines Ereignisses mit unzureichendem Arbeitsspeicher beendet wurden
resource.type="k8s_node"
log_id("events")
(jsonPayload.reason:("OOMKilling" OR "SystemOOM")
OR jsonPayload.message:("OOM encountered" OR "out of memory"))
severity=WARNING
resource.labels.cluster_name="CLUSTER_NAME"
Alternative Abfrage, um die Ergebnisse auf einen bestimmten Pod zu beschränken:
resource.type="k8s_node"
log_id("events")
(jsonPayload.reason:("OOMKilling" OR "SystemOOM")
OR jsonPayload.message:("OOM encountered" OR "out of memory"))
severity=WARNING
resource.labels.cluster_name="CLUSTER_NAME"
"POD_NAME"
Container finden, die nicht mehr ausgeführt werden
resource.type="k8s_node"
log_id("kubelet")
jsonPayload.MESSAGE:"ContainerDied"
severity=DEFAULT
resource.labels.cluster_name="CLUSTER_NAME"
Alternative Abfrage, um die Ergebnisse auf einen bestimmten Pod zu beschränken:
resource.type="k8s_node"
log_id("kubelet")
jsonPayload.MESSAGE:"ContainerDied"
severity=DEFAULT
resource.labels.cluster_name="CLUSTER_NAME"
"POD_NAME"
Airflow-Datenbank war stark ausgelastet
Eine Datenbank wird von verschiedenen Airflow-Komponenten verwendet, um miteinander zu kommunizieren und insbesondere Heartbeats von Aufgabeninstanzen zu speichern. Ressourcenmangel in der Datenbank führt zu längeren Abfragezeiten und kann sich auf die Ausführung von Aufgaben auswirken.
Manchmal sind in den Logs eines Airflow-Workers die folgenden Fehler vorhanden:
(psycopg2.OperationalError) connection to server at <IP address>,
port 3306 failed: server closed the connection unexpectedly
This probably means the server terminated abnormally before or while
processing the request.
Lösungen:
- Vermeiden Sie die Verwendung vieler
Variables.get-Anweisungen in Ihrem DAG-Code auf oberster Ebene. Verwenden Sie stattdessen Jinja-Vorlagen, um Werte von Airflow-Variablen abzurufen. Vermeiden Sie die Verwendung von CloudLoggingHandler für die Verarbeitung von Logging. Dieser Logging-Handler führt zu einer Überlastung der Datenbank der Umgebung und zu nachfolgenden DAG-Fehlern mit den Fehlermeldungen „server closed the connection unexpectedly“ (Server hat die Verbindung unerwartet geschlossen).
Optimieren (reduzieren) Sie die Verwendung von xcom_push- und xcom_pull-Anweisungen in Jinja-Vorlagen im DAG-Code der obersten Ebene.
Erwägen Sie ein Upgrade auf eine größere Umgebungsgröße (Mittel oder Groß).
Die Airflow-Datenbank war vorübergehend nicht verfügbar
Es kann einige Zeit dauern, bis ein Airflow-Worker vorübergehende Fehler wie vorübergehende Verbindungsprobleme erkennt und ordnungsgemäß behandelt. Möglicherweise wird der Standardgrenzwert für die Zombie-Erkennung überschritten.
Airflow-Heartbeat-Zeitüberschreitungen
resource.type="cloud_composer_environment"
resource.labels.environment_name="ENVIRONMENT_NAME"
log_id("airflow-worker")
textPayload:"Heartbeat time limit exceeded"Lösungen:
Erhöhen Sie das Zeitlimit für Zombie-Aufgaben und überschreiben Sie den Wert der Airflow-Konfigurationsoption
[scheduler]scheduler_zombie_task_threshold:Bereich Schlüssel Wert Hinweise schedulerscheduler_zombie_task_thresholdNeues Zeitlimit (in Sekunden) Der Standardwert ist 300.
Aufgaben schlagen fehl, weil bei der Ausführung ein Fehler aufgetreten ist
Instanz wird beendet
Airflow verwendet den Mechanismus Instanz beenden, um Airflow-Aufgaben herunterzufahren. Dieser Mechanismus wird in den folgenden Situationen verwendet:
- Wenn ein Scheduler eine Aufgabe beendet, die nicht rechtzeitig abgeschlossen wurde.
- Wenn für eine Aufgabe das Zeitlimit überschritten wird oder sie zu lange ausgeführt wird.
Wenn Airflow Aufgabeninstanzen beendet, werden in den Logs eines Airflow-Workers, der die Aufgabe ausgeführt hat, die folgenden Logeinträge angezeigt:
INFO - Subtask ... WARNING - State of this instance has been externally set
to success. Terminating instance.
INFO - Subtask ... INFO - Sending Signals.SIGTERM to GPID <X>
INFO - Subtask ... ERROR - Received SIGTERM. Terminating subprocesses.
Mögliche Lösungen:
Prüfen Sie den Aufgabencode auf Fehler, die dazu führen könnten, dass die Ausführung zu lange dauert.
Erhöhen Sie die CPU und den Arbeitsspeicher für Airflow-Worker, damit Aufgaben schneller ausgeführt werden.
Erhöhen Sie den Wert der Airflow-Konfigurationsoption
[celery_broker_transport_options]visibility_timeout.Daher wartet der Scheduler länger, bis eine Aufgabe abgeschlossen ist, bevor er sie als Zombie-Aufgabe betrachtet. Diese Option ist besonders nützlich für zeitaufwendige Aufgaben, die viele Stunden dauern. Wenn der Wert zu niedrig ist (z. B. 3 Stunden), betrachtet der Scheduler Aufgaben, die 5 oder 6 Stunden lang ausgeführt werden, als „aufgehängt“ (Zombie-Aufgaben).
Erhöhen Sie den Wert der Airflow-Konfigurationsoption
[core]killed_task_cleanup_time.Ein längerer Wert gibt Airflow-Workern mehr Zeit, ihre Aufgaben ordnungsgemäß zu beenden. Wenn der Wert zu niedrig ist, werden Airflow-Aufgaben möglicherweise abrupt unterbrochen, ohne dass genügend Zeit bleibt, ihre Arbeit ordnungsgemäß zu beenden.
DAG-Ausführung wird nicht innerhalb des erwarteten Zeitrahmens beendet
Symptom:
Manchmal wird eine DAG-Ausführung nicht beendet, weil Airflow-Aufgaben hängen bleiben und die DAG-Ausführung länger als erwartet dauert. Unter normalen Umständen bleiben Airflow-Aufgaben nicht unbegrenzt im Status „Warteschlange“ oder „Wird ausgeführt“, da Airflow Zeitüberschreitungs- und Bereinigungsverfahren hat, die helfen, diese Situation zu vermeiden.
Lösung:
Verwenden Sie den Parameter
dagrun_timeoutfür die DAGs. Beispiel:dagrun_timeout=timedelta(minutes=120). Daher muss jede DAG-Ausführung innerhalb des DAG-Ausführungstimeouts abgeschlossen werden. Weitere Informationen zu Airflow-Aufgabenstatus finden Sie in der Apache Airflow-Dokumentation.Mit dem Parameter Zeitlimit für die Ausführung von Aufgaben können Sie ein Standardzeitlimit für Aufgaben definieren, die auf Apache Airflow-Operatoren basieren.
Die Verbindung zum Postgres-Server wird während der Abfrage unterbrochen. Ausnahme wird während der Aufgabenausführung oder unmittelbar danach ausgelöst.
Lost connection to Postgres server during query-Ausnahmen treten häufig auf, wenn die folgenden Bedingungen erfüllt sind:
- Ihr DAG verwendet
PythonOperatoroder einen benutzerdefinierten Operator. - Ihr DAG stellt Abfragen an die Airflow-Datenbank.
Wenn mehrere Abfragen von einer aufrufbaren Funktion gesendet werden, verweisen Tracebacks möglicherweise fälschlicherweise auf die Zeile self.refresh_from_db(lock_for_update=True) im Airflow-Code. Sie ist die erste Datenbankabfrage nach der Aufgabenausführung. Die tatsächliche Ursache der Ausnahme tritt davor auf, wenn eine SQLAlchemy-Sitzung nicht ordnungsgemäß geschlossen wird.
SQLAlchemy-Sitzungen sind auf einen Thread beschränkt und werden in einer aufrufbaren Funktionssitzung erstellt, die später innerhalb des Airflow-Codes fortgesetzt werden kann. Wenn es innerhalb einer Sitzung zu erheblichen Verzögerungen zwischen Abfragen kommt, wurde die Verbindung möglicherweise bereits vom Postgres-Server geschlossen. Das Zeitlimit für die Verbindung in Managed Airflow-Umgebungen ist auf etwa zehn Minuten festgelegt.
Lösung:
- Verwenden Sie den Decorator
airflow.utils.db.provide_session. Dieser Decorator stellt eine gültige Sitzung für die Airflow-Datenbank imsession-Parameter bereit und schließt die Sitzung am Ende der Funktion ordnungsgemäß. - Verwenden Sie keine einzelne Funktion mit langer Ausführungszeit. Verschieben Sie stattdessen alle Datenbankabfragen in separate Funktionen, sodass es mehrere Funktionen mit dem Decorator
airflow.utils.db.provide_sessiongibt. In diesem Fall werden Sitzungen nach dem Abrufen von Abfrageergebnissen automatisch geschlossen.
Vorübergehende Unterbrechungen beim Herstellen einer Verbindung zur Airflow-Metadatenbank
Managed Airflow wird auf einer verteilten Infrastruktur ausgeführt. Das bedeutet, dass gelegentlich vorübergehende Probleme auftreten können, die die Ausführung Ihrer Airflow-Aufgaben unterbrechen.
In solchen Fällen werden möglicherweise die folgenden Fehlermeldungen in den Logs der Airflow-Worker angezeigt:
"Can't connect to Postgres server on 'airflow-sqlproxy-service.default.svc.cluster.local' (111)"
oder
"Can't connect to Postgres server on 'airflow-sqlproxy-service.default.svc.cluster.local' (104)"
Solche zeitweiligen Probleme können auch durch Wartungsvorgänge für Ihre Managed Airflow-Umgebungen verursacht werden.
Normalerweise treten solche Fehler nur zeitweise auf. Wenn Ihre Airflow-Aufgaben idempotent sind und Sie Wiederholungsversuche konfiguriert haben, wirken sich diese Fehler nicht auf Sie aus. Sie können auch Wartungsfenster definieren.
Ein weiterer Grund für solche Fehler könnte ein Mangel an Ressourcen im Cluster Ihrer Umgebung sein. In solchen Fällen können Sie Ihre Umgebung wie in den Anleitungen Umgebungen skalieren oder Umgebung optimieren beschrieben hochskalieren oder optimieren.
Eine DAG-Ausführung wird als erfolgreich markiert, enthält aber keine ausgeführten Aufgaben
Wenn ein DAG-Lauf execution_date vor dem start_date des DAG liegt, werden möglicherweise DAG-Läufe ohne Task-Läufe angezeigt, die aber trotzdem als erfolgreich markiert sind.

Ursache
Das kann in folgenden Fällen passieren:
Die Abweichung wird durch den Zeitzonenunterschied zwischen
execution_dateundstart_dateder DAG verursacht. Das kann beispielsweise passieren, wenn Siependulum.parse(...)verwenden, umstart_datefestzulegen.Der
start_datedes DAG ist auf einen dynamischen Wert festgelegt, z. B.airflow.utils.dates.days_ago(1).
Lösung
Achten Sie darauf, dass in
execution_dateundstart_datedieselbe Zeitzone verwendet wird.Geben Sie ein statisches
start_datean und kombinieren Sie es mitcatchup=False, um zu vermeiden, dass DAGs mit vergangenen Startdaten ausgeführt werden.
Best Practices
Auswirkungen von Update- oder Upgradevorgängen auf die Ausführung von Airflow-Aufgaben
Aktualisierungs- oder Upgradevorgänge unterbrechen aktuell ausgeführte Airflow-Aufgaben, es sei denn, eine Aufgabe wird im deferrable mode (aufschiebbaren Modus) ausgeführt.
Wir empfehlen, diese Vorgänge auszuführen, wenn Sie mit minimalen Auswirkungen auf die Ausführung von Airflow-Aufgaben rechnen, und entsprechende Wiederholungsmechanismen in Ihren DAGs und Aufgaben einzurichten.
Programmatisch generierte DAGs nicht gleichzeitig planen
Das programmatische Generieren von DAG-Objekten aus einer DAG-Datei ist eine effiziente Methode, um viele ähnliche DAGs zu erstellen, die sich nur geringfügig unterscheiden.
Es ist wichtig, nicht alle diese DAGs sofort für die Ausführung zu planen. Es besteht eine hohe Wahrscheinlichkeit, dass Airflow-Worker nicht genügend CPU- und Arbeitsspeicherressourcen haben, um alle gleichzeitig geplanten Aufgaben auszuführen.
So vermeiden Sie Probleme bei der Planung programmatischer DAGs:
- Erhöhen Sie die Nebenläufigkeit der Worker und skalieren Sie Ihre Umgebung, damit mehr Aufgaben gleichzeitig ausgeführt werden können.
- Generieren Sie DAGs so, dass ihre Zeitpläne gleichmäßig über die Zeit verteilt werden, um zu vermeiden, dass Hunderte von Aufgaben gleichzeitig geplant werden. So haben Airflow-Worker Zeit, alle geplanten Aufgaben auszuführen.
Ausführungszeit von DAGs, Aufgaben und parallelen Ausführungen desselben DAG steuern
Wenn Sie steuern möchten, wie lange die Ausführung einer einzelnen DAG für eine bestimmte DAG dauert, können Sie den DAG-Parameter dagrun_timeout verwenden. Wenn Sie beispielsweise erwarten, dass ein einzelner DAG-Lauf (unabhängig davon, ob die Ausführung erfolgreich oder fehlgeschlagen ist) nicht länger als eine Stunde dauern darf, legen Sie diesen Parameter auf 3.600 Sekunden fest.
Sie können auch festlegen, wie lange eine einzelne Airflow-Aufgabe dauern darf. Dazu können Sie execution_timeout verwenden.
Wenn Sie steuern möchten, wie viele aktive DAG-Ausführungen für einen bestimmten DAG ausgeführt werden sollen, können Sie dazu die [core]max-active-runs-per-dag
Airflow-Konfigurationsoption verwenden.
Wenn Sie möchten, dass zu einem bestimmten Zeitpunkt nur eine Instanz eines DAG ausgeführt wird, legen Sie den Parameter max-active-runs-per-dag auf 1 fest.
Erhöhten Netzwerkverkehr zur und von der Airflow-Datenbank vermeiden
Die Menge des Netzwerk-Traffics zwischen dem GKE-Cluster Ihrer Umgebung und der Airflow-Datenbank hängt von der Anzahl der DAGs, der Anzahl der Aufgaben in DAGs und der Art des Zugriffs der DAGs auf Daten in der Airflow-Datenbank ab. Folgende Faktoren können sich auf die Netzwerknutzung auswirken:
Abfragen an die Airflow-Datenbank Wenn Ihre DAGs viele Abfragen ausführen, generieren sie große Mengen an Traffic. Beispiele: Status prüfen, bevor andere Aufgaben ausgeführt werden, XCom-Tabelle abfragen und Inhalt der Airflow-Datenbank auslesen.
Große Anzahl von Aufgaben Je mehr Aufgaben geplant sind, desto mehr Netzwerktraffic wird generiert. Dieser Aspekt gilt sowohl für die Gesamtzahl der Aufgaben in Ihren DAGs als auch für die Planungshäufigkeit. Wenn der Airflow-Planer DAG-Ausführungen plant, sendet er Abfragen an die Airflow-Datenbank und generiert Traffic.
Die Airflow-Weboberfläche generiert Netzwerkverkehr, da sie Abfragen an die Airflow-Datenbank sendet. Die intensive Verwendung von Seiten mit Grafiken, Aufgaben und Diagrammen kann große Mengen an Netzwerkverkehr generieren.
Nächste Schritte
- Fehlerbehebung bei der Installation von PyPI-Paketen
- Fehlerbehebung bei Umgebungsupdates und -upgrades