
Managed Airflow (terza generazione) | Managed Airflow (seconda generazione) | Managed Airflow (prima generazione legacy)
Questa pagina descrive come eseguire test di failover di database e cluster per ambienti a elevata resilienza.
I test di failover per il tuo ambiente simulano un'interruzione completa di una zona in un data center. In questo scenario, un'interruzione zonale di un cluster e un'interruzione zonale di un database potrebbero verificarsi contemporaneamente. Eseguendo i due test di failover, puoi monitorare il modo in cui il tuo ambiente a elevata resilienza esegue un failover e verificare in che modo influisce sui DAG e sulle attività.
Prima di iniziare
Per eseguire i test di failover, il tuo Account Google deve disporre dei seguenti ruoli e autorizzazioni:
Autorizzazione
composer.environments.update. Per un elenco dei ruoli con questa autorizzazione, consulta Controllo dell'accesso con IAM.Ruolo Amministratore cluster Kubernetes Engine (
roles/container.clusterAdmin) per eseguire i comandikubectlsul cluster dell'ambiente. In alternativa, puoi eseguire il provisioning dei ruoli RBAC di Kubernetes direttamente in GKE.
Se utilizzi le reti autorizzate, devi eseguire i
kubectlcomandi da una macchina che può accedere all'endpoint del piano di controllo del cluster GKE. A seconda di come configuri l'accesso all'endpoint del piano di controllo dell'ambiente, puoi utilizzare diverse opzioni. Per saperne di più, consulta Eseguire comandi in un ambiente IP privato.
Controllare che l'ambiente sia integro
Assicurati di eseguire i test di failover solo su ambienti integri. Per verificare che l'ambiente sia integro:
Nella Google Cloud console, vai alla pagina Ambienti.
Nell'elenco degli ambienti, fai clic sul nome del tuo ambiente. Si apre la pagina Dettagli ambiente.
Vai alla scheda Monitoraggio.
Assicurati che tutte le metriche di integrità siano verdi.
Eseguire un test di failover del database
Puoi eseguire un test di failover del database, che simula un'interruzione zonale, attivandolo con un comando Google Cloud CLI. Ad esempio, potresti volerlo fare per misurare la quantità di tempo necessaria al database del tuo ambiente per passare a un'altra zona.
Per eseguire un test di failover del database per il tuo ambiente:
Assicurati che l'ambiente sia integro.
Recupera la zona principale del database del tuo ambiente:
gcloud composer environments fetch-database-properties \ ENVIRONMENT_NAME \ --location LOCATIONSostituisci quanto segue:
ENVIRONMENT_NAME: il nome del tuo ambiente Cloud Composer.LOCATION: la regione in cui si trova l'ambiente.
Esempio:
gcloud composer environments fetch-database-properties \ example-environment \ --location us-central1Avvia il test di failover del database:
gcloud composer environments database-failover \ ENVIRONMENT_NAME \ --location LOCATIONSostituisci quanto segue:
ENVIRONMENT_NAME: il nome del tuo ambiente Cloud Composer.LOCATION: la regione in cui si trova l'ambiente.
Esempio:
gcloud composer environments database-failover \ example-environment \ --location us-central1Attendi il completamento del test di failover del database. La procedura può richiedere fino a 3 minuti.
Verifica che la zona principale del database del tuo ambiente sia stata modificata:
gcloud composer environments fetch-database-properties \ ENVIRONMENT_NAME \ --location LOCATIONControlla le metriche di integrità dell'ambiente per assicurarti che l'ambiente sia integro.
Il database dell'ambiente diventa pronto per un altro failover quando la metrica dell'ambiente Database disponibile per il failover (
composer.googleapis.com/environment/database/available_for_failover) diventaTrue. Per saperne di più sulla visualizzazione delle metriche dell'ambiente in Cloud Monitoring, consulta Monitorare gli ambienti.
Eseguire il test di failover del cluster dell'ambiente
Puoi eseguire un test di failover per il cluster del tuo ambiente, che simula un'interruzione zonale. Ad esempio, potresti volerlo fare per misurare la quantità di tempo necessaria al tuo ambiente per passare a un'altra zona.
Controllare che l'ambiente sia integro
Prima di iniziare il test, assicurati che l'ambiente sia integro.
Configurare le credenziali per il cluster dell'ambiente
Per ottenere le credenziali del cluster:
Nella Google Cloud console, vai alla pagina Ambienti.
Nell'elenco degli ambienti, fai clic sul nome del tuo ambiente. Si apre la pagina Dettagli ambiente.
Vai alla scheda Configurazione ambiente.
Fai clic su Visualizza dettagli cluster.
Fai clic su Connetti.
Copia ed esegui il comando Google Cloud CLI visualizzato.
Ad esempio:
gcloud container clusters get-credentials \ us-central1-exam-db23ee12-gke \ --region us-central1 \ --project example-project
Controllare il cluster dell'ambiente
Controlla le zone e i nodi in cui vengono eseguiti i carichi di lavoro nel cluster dell'ambiente. Utilizzerai queste informazioni in un secondo momento per simulare un'interruzione zonale. Puoi anche eseguire di nuovo questi comandi durante l'esecuzione del test di failover per vedere come il cluster dell'ambiente esegue il failover.
Controlla nodi e zone:
kubectl get nodes \ -o=custom-columns=NAME:.metadata.name,NODE:.metadata.labels.topology\\.gke\\.io/zoneControlla i pod:
kubectl get pods --all-namespaces \ -o=custom-columns=NAME:.metadata.name,STATUS:.status.phase,NODE:.spec.nodeName \ --field-selector metadata.namespace!=kube-systemVisualizza informazioni più dettagliate sui pod:
kubectl get pods --all-namespaces -o wide \ --field-selector metadata.namespace!=kube-system
Svuotare i nodi
Scegli una zona in cui vuoi simulare un'interruzione. Se esegui il test di failover del cluster
insieme al test di failover del database,
potresti scegliere la zona principale dell'ambiente
della tua istanza Cloud SQL a elevata disponibilità.
Ad esempio, se l'istanza Cloud SQL principale viene eseguita in us-central1-a, puoi simulare un'interruzione nell'intera zona us-central1-a eseguendo prima il test di failover del database e poi il test di failover del cluster in us-central1-a.
Il seguente comando simula la mancata disponibilità di un insieme di nodi in una zona specifica. Forza la rimozione dei pod dai nodi nella zona specificata e impedisce la ripianificazione dei pod su questi nodi. Poiché non è possibile pianificare nuovi pod, vengono aggiunti nuovi nodi al cluster.
Questo comando non influisce sui carichi di lavoro eseguiti nello spazio dei nomi composer-system. Nell'output del comando potresti visualizzare messaggi di errore correlati. Questo non influisce sul test di failover. I nodi esistenti nella zona selezionata sono ancora contrassegnati come non pianificabili.
Per simulare un errore della zona del cluster nella zona selezionata:
kubectl get nodes -o name -l "topology.gke.io/zone=ZONE" | \
xargs kubectl drain \
--ignore-daemonsets --delete-emptydir-data --force --disable-eviction
Sostituisci quanto segue:
ZONE: la zona in cui vuoi simulare un errore della zona del cluster.
Controllare le metriche dell'ambiente
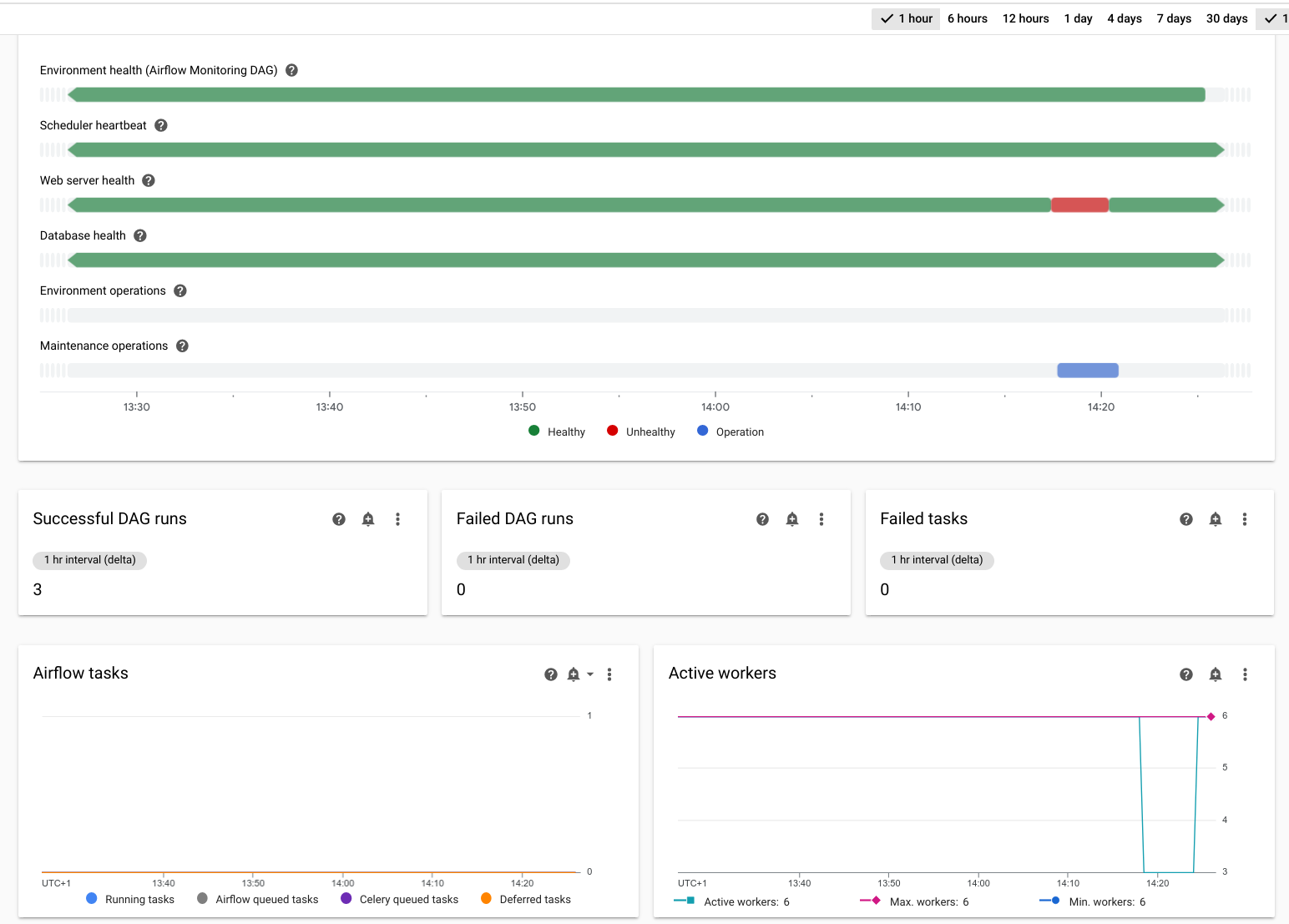
Nella Google Cloud console, vai alla pagina Ambienti.
Nell'elenco degli ambienti, fai clic sul nome del tuo ambiente. Si apre la pagina Dettagli ambiente.
Vai alla scheda Monitoraggio.
Verifica che le seguenti metriche siano "verdi" durante l'operazione di failover o che rimangano nello stato "rosso" per al massimo alcuni minuti.
- Integrità dell'ambiente
- Heartbeat dello scheduler
- Integrità del server web
- Integrità del database
- Worker attivi
- Scheduler attivi
- Server web attivi
- Trigger attivi
Tieni presente che l'interruzione simulata è contrassegnata come "Operazione di manutenzione del cluster".
Non è necessario eseguire ulteriori azioni per riportare il cluster dell'ambiente alla preparazione per il failover dopo il test. Durante il test, il cluster dell'ambiente aggiunge automaticamente nuovi nodi che sostituiscono quelli interessati dall'interruzione simulata.