
Ce tutoriel explique comment connecter une table ou une vue BigQuery pour lire et écrire des données à partir d'un notebook Databricks. Les étapes décrites utilisent la consoleGoogle Cloud et les espaces de travail Databricks.
Vous pouvez également effectuer ces étapes à l'aide des outils de ligne de commande gcloud et databricks, mais cette façon de procéder n'est pas abordée dans le présent tutoriel.
Databricks sur Google Cloud est un environnement Databricks hébergé sur Google Cloud, qui s'exécute sur Google Kubernetes Engine (GKE) et bénéficie d'une intégration native avec BigQuery et d'autres technologies Google Cloud . Si vous ne connaissez pas encore Databricks, regardez la vidéo Introduction to Databricks Unified Data Platform (Présentation de la plate-forme de données unifiée de Databricks) pour découvrir un aperçu de la plate-forme lakehouse de Databricks.
Objectifs
- Configurez Google Cloud pour vous connecter à Databricks.
- Déployez Databricks sur Google Cloud.
- Interroger BigQuery depuis Databricks.
Coûts
Ce tutoriel utilise des composants facturables de la console Google Cloud , y compris BigQuery et GKE. Les tarifs de BigQuery et les tarifs de GKE s'appliquent. Pour en savoir plus sur les coûts associés à un compte Databricks sur Google Cloud, consultez la section Configurer votre compte et créer un espace de travail dans la documentation Databricks.
Avant de commencer
Avant de connecter Databricks à BigQuery, procédez comme suit :
- Activez l'API BigQuery Storage.
- Créez un compte de service pour Databricks.
- Créez un bucket Cloud Storage pour le stockage temporaire.
Activer l'API BigQuery Storage
L'API BigQuery Storage est activée par défaut pour tous les nouveaux projets sur lesquels BigQuery est utilisé. Pour les projets existants pour lesquels l'API n'est pas activée, procédez comme suit :
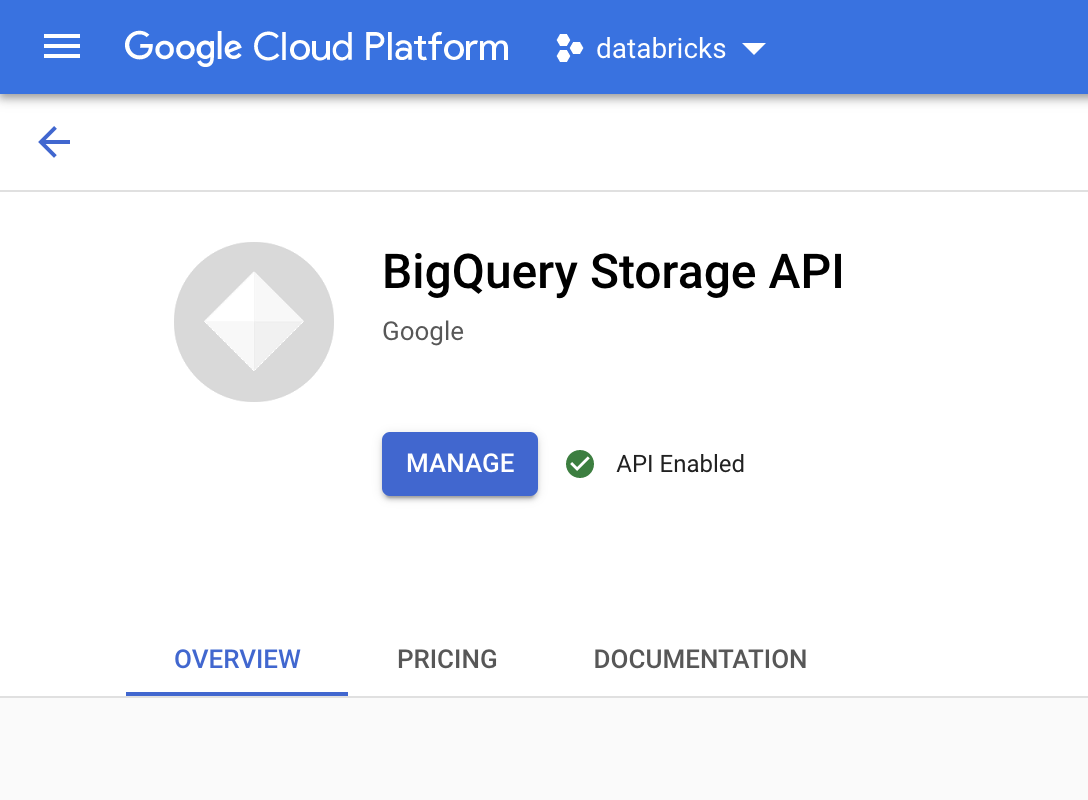
Dans la console Google Cloud , accédez à la page API BigQuery Storage.
Vérifiez que l'API BigQuery Storage est activée.
Créer un compte de service pour Databricks
Créez ensuite un compte de service de gestion de l'authentification et des accès (IAM) pour permettre à un cluster Databricks d'exécuter des requêtes sur BigQuery. Nous vous recommandons de n'accorder à ce compte de service que les privilèges requis pour effectuer ses tâches. Consultez la page Rôles et autorisations BigQuery.
Dans la console Google Cloud , accédez à la page Comptes de service.
Cliquez sur Créer un compte de service, nommez le compte de service
databricks-bigquery, saisissez une brève description commeDatabricks tutorial service account, puis cliquez sur Créer et continuer.Sous Autoriser ce compte de service à accéder au projet, spécifiez les rôles du compte de service. Pour autoriser le compte de service à lire des données de la table BigQuery depuis l'espace de travail Databricks situé dans le même projet, plus spécifiquement sans avoir à référencer une vue matérialisée, attribuez les rôles suivants :
- Utilisateur de sessions de lecture BigQuery
- Lecteur de données BigQuery
Pour accorder l'autorisation d'écrire des données, accordez les rôles suivants :
- Utilisateur de tâche BigQuery
- Éditeur de données BigQuery
Notez l'adresse e-mail de votre nouveau compte de service pour référence dans les prochaines étapes.
Cliquez sur OK.
Créer un bucket Cloud Storage
Pour écrire dans BigQuery, le cluster Databricks doit accéder à un bucket Cloud Storage afin de mettre en mémoire tampon les données écrites.
Dans la console Google Cloud , accédez au navigateur Cloud Storage.
Cliquez sur Créer un bucket pour ouvrir la boîte de dialogue Créer un bucket.
Spécifiez un nom pour le bucket utilisé afin d'écrire les données dans BigQuery. Le nom du bucket doit être un nom unique. Si vous spécifiez un nom de bucket qui existe déjà, Cloud Storage répond avec un message d'erreur. Dans ce cas, spécifiez un nom différent pour votre bucket.
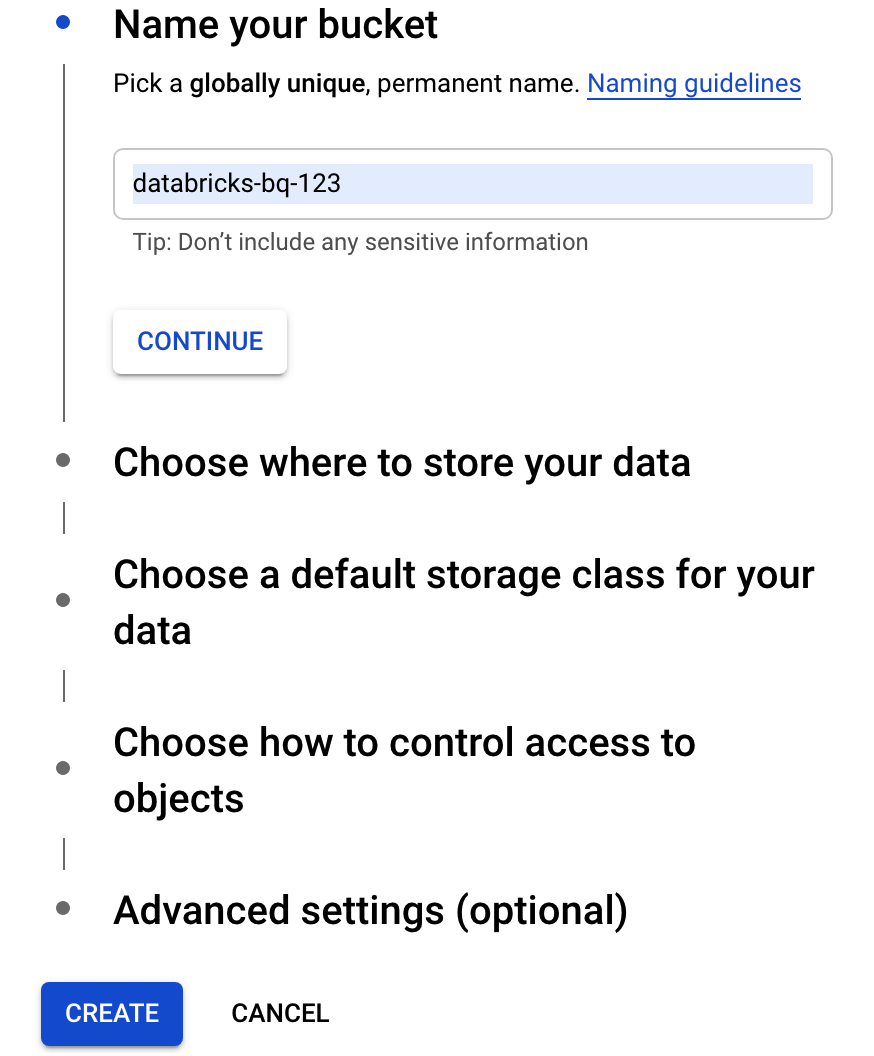
Pour ce tutoriel, utilisez les paramètres par défaut pour l'emplacement de stockage, la classe de stockage, le contrôle des accès et les paramètres avancés.
Cliquez sur Créer pour créer votre bucket Cloud Storage.
Cliquez sur Autorisations, sur Ajouter, puis spécifiez l'adresse e-mail du compte de service que vous avez créé pour l'accès Databricks sur la page Comptes de service.
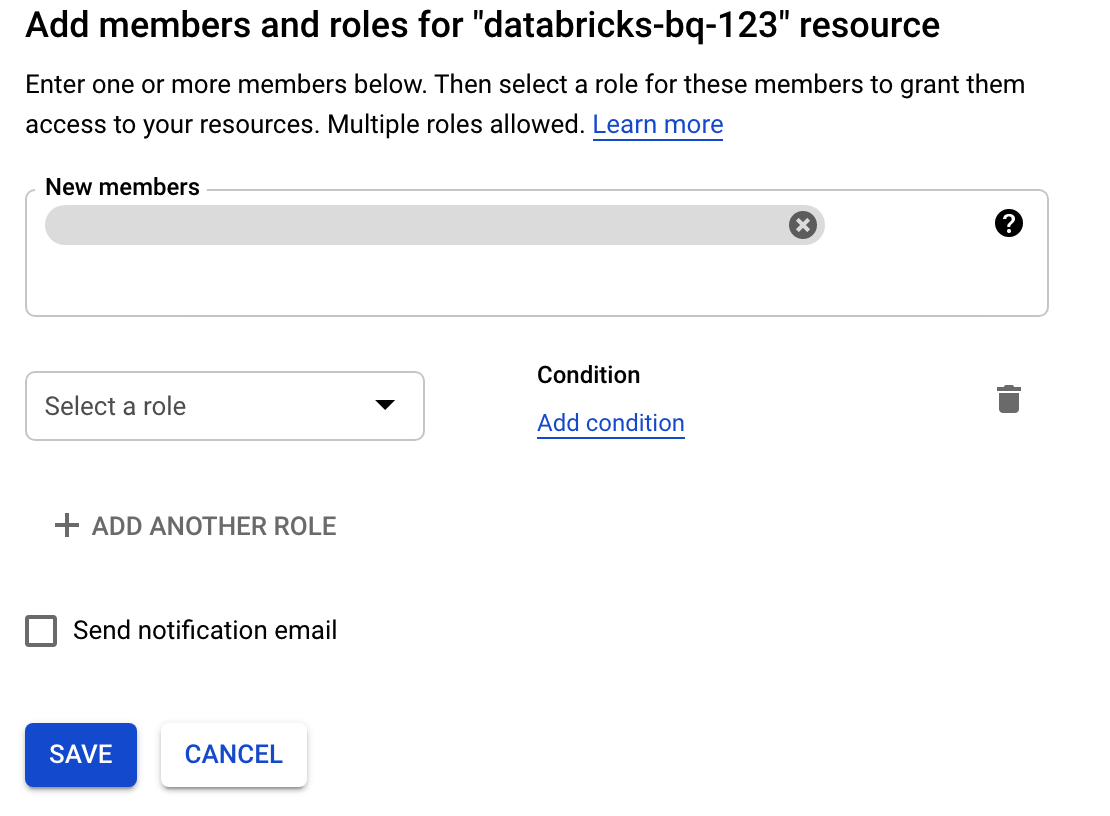
Cliquez sur Sélectionner un rôle, puis ajoutez le rôle Administrateur de l'espace de stockage.
Cliquez sur Enregistrer.
Déployer Databricks sur Google Cloud
Effectuez les étapes suivantes pour préparer le déploiement de Databricks sur Google Cloud.
- Pour configurer votre compte Databricks, suivez les instructions de la documentation Databricks intitulée Configurer votre compte Databricks sur Google Cloud.
- Une fois inscrit, découvrez comment gérer votre compte Databricks.
Créer un espace de travail, un cluster et un notebook Databricks
Les étapes suivantes décrivent comment créer un espace de travail Databricks, un cluster et un notebook Python pour écrire du code permettant d'accéder à BigQuery.
Vérifiez que les prérequis Databrick sont bien satisfaits.
Créez votre premier espace de travail. Dans la console de compte Databricks, cliquez sur Créer un espace de travail.
Spécifiez
gcp-bqcomme nom de l'espace de travail et sélectionnez votre Région.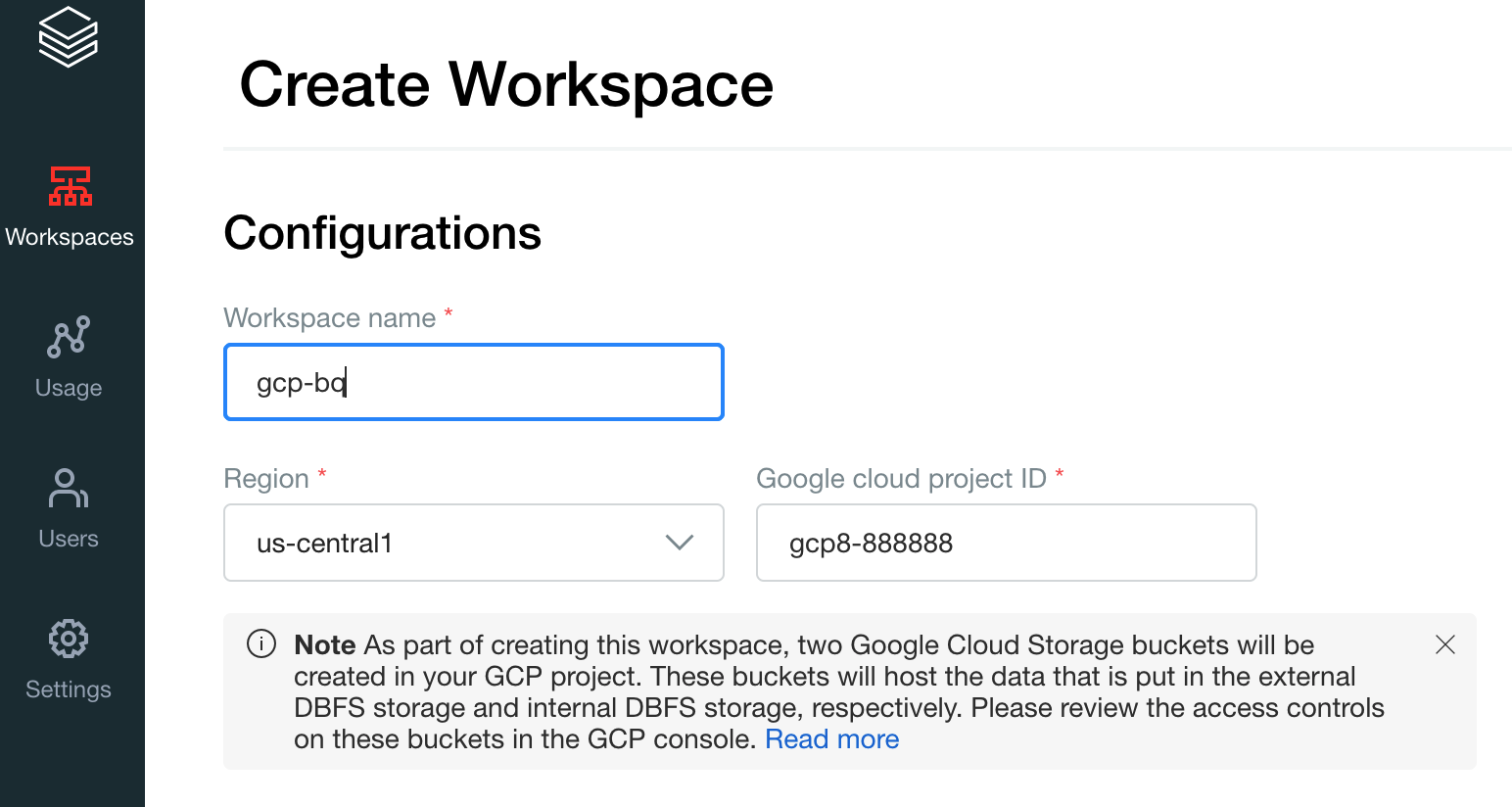
Pour déterminer votre ID de projet Google Cloud , accédez à la console Google Cloud , puis copiez la valeur dans le champ ID de projetGoogle Cloud .
Cliquez sur Enregistrer pour créer votre espace de travail Databricks.
Pour créer un cluster Databricks avec un environnement d'exécution Databricks 7.6 ou version ultérieure, sélectionnez Clusters dans la barre de menu de gauche puis cliquez sur Créer un cluster en haut de page.
Spécifiez le nom de votre cluster et sa taille, puis cliquez sur Options avancées et spécifiez l'adresse e-mail de votre compte de service Google Cloud.
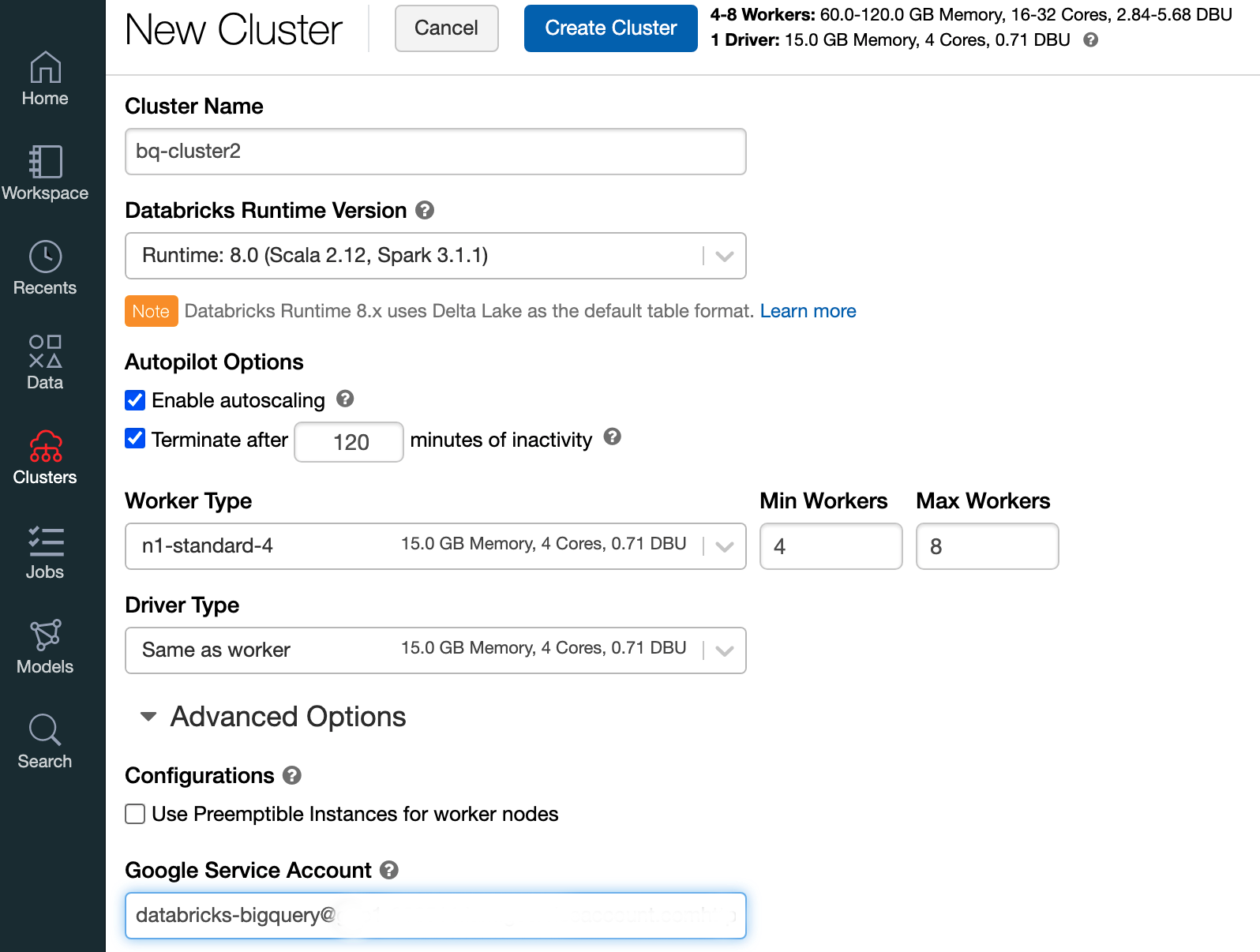
Cliquez sur Create Cluster (Créer le cluster).
Pour créer un notebook Python pour Databricks, suivez les instructions de la section Créer un notebook.
Interroger BigQuery depuis Databricks
Avec la configuration ci-dessus, vous pouvez connecter Databricks à BigQuery de manière sécurisée. Databricks utilise une version modifiée de l'adaptateur Open Source Google Spark pour accéder à BigQuery.
Databricks réduit le transfert de données et accélère les requêtes en envoyant automatiquement certains prédicats de requête, par exemple celui du filtrage sur des colonnes imbriquées, vers BigQuery. En outre, la possibilité supplémentaire d'exécuter d'abord une requête SQL sur BigQuery avec l'API query() réduit la taille de transfert de l'ensemble de données obtenu.
Les étapes suivantes expliquent comment accéder à un ensemble de données sur BigQuery et écrire vos propres données dans BigQuery.
Accéder à un ensemble de données public sur BigQuery
BigQuery fournit une liste des ensembles de données publics disponibles. Pour interroger l'ensemble de données BigQuery Shakespeare, qui fait partie des ensembles de données publics, procédez comme suit :
Pour lire la table BigQuery, utilisez l'extrait de code suivant de votre notebook Databricks.
table = "bigquery-public-data.samples.shakespeare" df = spark.read.format("bigquery").option("table",table).load() df.createOrReplaceTempView("shakespeare")Exécutez le code en appuyant sur
Shift+Return.Vous pouvez maintenant interroger votre table BigQuery en utilisant le DataFrame Spark (
df). Par exemple, utilisez la commande suivante pour afficher les trois premières lignes du dataframe :df.show(3)Pour interroger une autre table, mettez à jour la variable
table.L'une des principales caractéristiques des blocs-notes Databricks est que vous pouvez combiner les cellules de différents langages comme Scala, Python et SQL dans un seul notebook.
La requête SQL suivante vous permet de visualiser le nombre de mots dans Shakespeare après l'exécution de la cellule précédente qui crée la vue temporaire.
%sql SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word ORDER BY word_count DESC LIMIT 12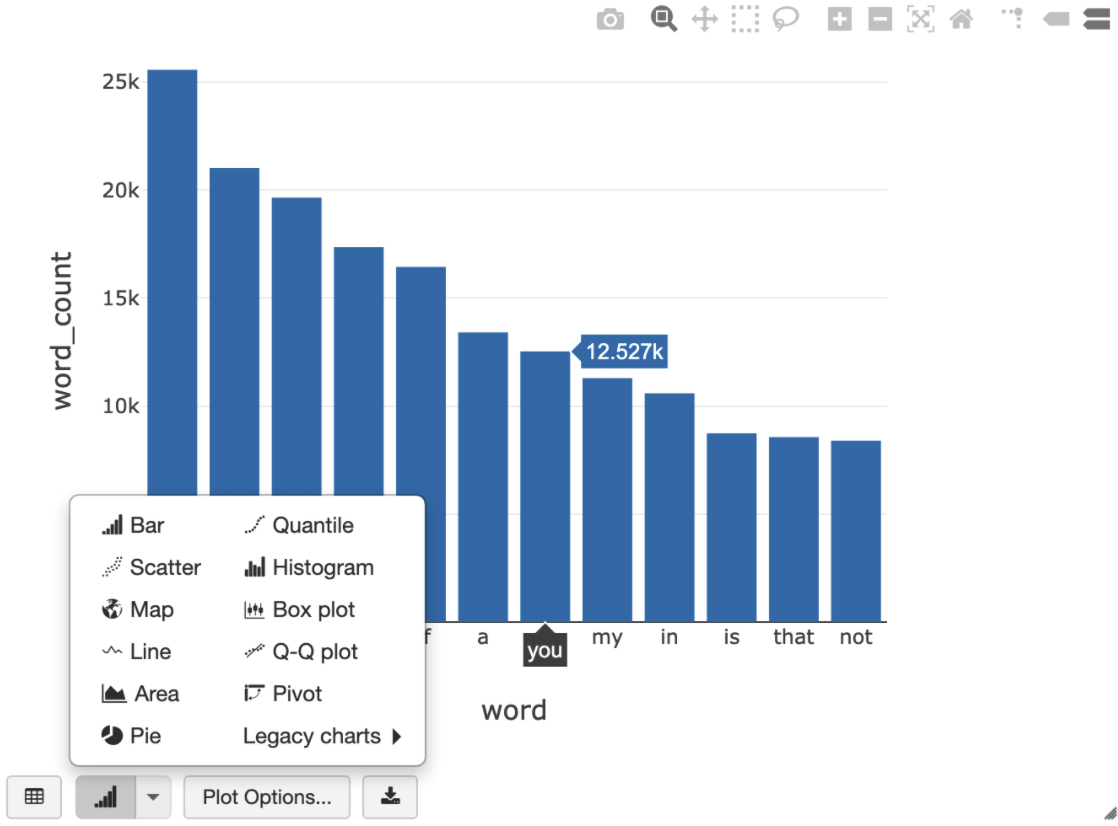
La cellule ci-dessus exécute une requête Spark SQL sur le dataframe de votre cluster Databricks, et non dans BigQuery. L'avantage de cette approche est que l'analyse des données s'effectue au niveau de Spark. Aucun autre appel d'API BigQuery n'est émis, et aucuns frais supplémentaires ne vous sont facturés.
Vous pouvez également déléguer l'exécution d'une requête SQL à BigQuery à l'aide de l'API
query(), ce qui permet d'optimiser la taille de transfert du DataFrame obtenu. Avec cette approche et contrairement à l'exemple ci-dessus où le traitement a été effectué dans Spark, la facturation et les optimisations de requêtes s'appliquent pour l'exécution de la requête dans BigQuery.L'exemple ci-dessous utilise Scala, l'API
query()et l'ensemble de données public Shakespeare sur BigQuery pour calculer les cinq mots les plus courants dans les œuvres de Shakespeare. Avant d'exécuter le code, vous devez d'abord créer dans BigQuery un ensemble de données vide appelémdatasetet auquel le code peut faire référence. Pour en savoir plus, consultez la section Écrire des données dans BigQuery.%scala // public dataset val table = "bigquery-public-data.samples.shakespeare" // existing dataset where the Google Cloud user has table creation permission val tempLocation = "mdataset" // query string val q = s"""SELECT word, SUM(word_count) AS word_count FROM ${table} GROUP BY word ORDER BY word_count DESC LIMIT 10 """ // read the result of a GoogleSQL query into a DataFrame val df2 = spark.read.format("bigquery") .option("query", q) .option("materializationDataset", tempLocation) .load() // show the top 5 common words in Shakespeare df2.show(5)Pour plus d'exemples de code, consultez l'exemple de notebook BigQuery de Databricks.
Écrire des données dans BigQuery
Les tables BigQuery existent dans les ensembles de données. Avant de pouvoir écrire des données dans une table BigQuery, vous devez créer un ensemble de données dans BigQuery. Pour créer un ensemble de données pour un notebook Databricks Python, procédez comme suit :
Accédez à la page BigQuery de la console Google Cloud .
Développez l'option Actions, cliquez sur Créer un ensemble de données, puis nommez-le
together.Dans le notebook Databricks Python, créez un DataFrame simple à partir d'une liste Python avec trois entrées de chaîne à l'aide de l'extrait de code suivant :
from pyspark.sql.types import StringType mylist = ["Google", "Databricks", "better together"] df = spark.createDataFrame(mylist, StringType())Ajoutez une autre cellule à votre notebook qui écrit le dataframe Spark de l'étape précédente dans la table BigQuery
myTablede l'ensemble de donnéestogether. La table est soit créée, soit écrasée. Utilisez le nom de bucket que vous avez spécifié précédemment.bucket = YOUR_BUCKET_NAME table = "together.myTable" df.write .format("bigquery") .option("temporaryGcsBucket", bucket) .option("table", table) .mode("overwrite").save()Pour vérifier que vous avez bien écrit les données, interrogez et affichez votre table BigQuery via le DataFrame Spark (
df) :display(spark.read.format("bigquery").option("table", table).load)
Nettoyer
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Avant de supprimer Databricks, sauvegardez toujours vos données et vos notebooks. Pour nettoyer et supprimer complètement Databricks, résiliez votre abonnement Databricks dans la consoleGoogle Cloud et supprimez toutes les ressources associées que vous avez créées dans la consoleGoogle Cloud .
Si vous supprimez un espace de travail Databricks, les deux buckets Cloud Storage créés par Databricks et portant les noms databricks-WORKSPACE_ID et databricks-WORKSPACE_ID-system ne seront pas supprimés s'ils ne sont pas vides. Après la suppression de l'espace de travail, vous pouvez supprimer ces objets manuellement dans la consoleGoogle Cloud pour votre projet.
Étape suivante
Cette section fournit une liste de documents et tutoriels supplémentaires :
- Découvrez les détails de l'essai sans frais de Databricks.
- En savoir plus sur Databricks sur Google Cloud
- Découvrez Databricks BigQuery.
- Consultez l'annonce de blog sur la compatibilité de BigQuery avec Databricks.
- Découvrez des exemples de notebooks BigQuery.
- Découvrez le fournisseur Terraform pour Databricks sur Google Cloud.
- Lisez le blog Databricks, qui contient davantage d'informations sur des sujets liés à la data science et les ensembles de données.