
Lakehouse for Apache Iceberg 是Google Cloud上的受管理資料湖倉平台。在這個平台中,Lakehouse 執行階段目錄是全代管的無伺服器 metastore 服務。為資料湖倉提供單一事實來源,讓多個引擎 (包括 Apache Spark、Apache Flink、Apache Hive 和 BigQuery) 共用資料表和中繼資料,不必複製檔案。
如要將查詢引擎連線至 metastore,請使用特定目錄類型 (例如 Apache Iceberg REST 目錄端點) 設定用戶端。這個端點會管理資料表的中繼資料,並使用 Cloud Storage 值區支援的儲存位置資料倉儲,儲存基礎中繼資料和資料檔案。如要進一步瞭解如何選擇目錄類型,請參閱「目錄類型和端點設定」。
Lakehouse 執行階段目錄支援儲存空間存取權委派 (也稱為憑證販售),可移除直接存取 Cloud Storage bucket 的需求,進而提升安全性。此外,還整合了 Knowledge Catalog,提供整合式管理、歷程和資料品質功能。
主要功能
Lakehouse 執行階段目錄是 Lakehouse for Apache Iceberg 的重要元件,可為資料管理和分析提供多項優勢,包括無伺服器架構、透過開放式 API 實現引擎互通性、統一的使用者體驗,以及搭配 BigQuery 使用時的高效能分析、串流和 AI。如要進一步瞭解這些優點,請參閱「什麼是 Lakehouse?」一文。
支援的引擎
Lakehouse 執行階段目錄與多種查詢引擎相容,包括 (但不限於) Apache Spark、Apache Flink、Apache Hive 和 Trino。下表提供各引擎的說明文件連結:
| 引擎 | 說明文件 |
|---|---|
| Apache Spark | 快速入門導覽課程:搭配 Spark 和 Iceberg REST 目錄端點使用 |
| Apache Hive | 搭配 Spark 和 Hive 目錄使用 |
| Apache Flink | 搭配 Apache Flink 使用 |
| Trino | 搭配 Trino 使用 |
目錄類型和端點設定
設定用戶端引擎以連線至 Lakehouse 執行階段目錄 metastore 時,請選取特定目錄端點,例如 Apache Iceberg REST 目錄端點或 Apache Hive 端點。最佳選項取決於您的用途,如下表所示:
| 用途 | 建議 |
|---|---|
| 希望開放原始碼引擎存取 Cloud Storage 中的資料,並需要與其他引擎互通,包括 BigQuery 和 AlloyDB for PostgreSQL 的 Lakehouse 執行階段目錄新使用者。 | 使用 Apache Iceberg REST 目錄端點。 |
| 執行 Apache Hive 或 Spark 工作負載的使用者,這些工作負載依附於 Hive Metastore 介面,且使用者需要全代管的 Metastore 服務。 | 使用 Apache Hive 目錄端點。 |
| 現有的 Lakehouse 執行階段目錄使用者,目前透過 BigQuery 端點的自訂 Apache Iceberg 目錄建立資料表。 | 繼續使用 BigQuery 端點的自訂 Apache Iceberg 目錄,但針對新工作流程,請使用 Apache Iceberg REST 目錄。透過 BigQuery 目錄同盟,使用 Apache Iceberg REST 目錄端點,即可查看透過 BigQuery 端點的自訂 Apache Iceberg 目錄建立的資料表。 |
Lakehouse 架構如何與 Google Cloud 服務整合
如要瞭解 Lakehouse 如何管理資料,請參閱 Google Cloud 服務整合的 Lakehouse for Apache Iceberg 架構。Apache Iceberg 不會將資料儲存在單一資料表中。而是使用中繼資料檔案的階層式架構,將資料檔案整理成具有 ACID 交易支援的連貫資料表結構。
下圖說明 Managed Service for Apache Spark 等運算引擎如何使用 Lakehouse 執行階段目錄管理資料表的中繼資料,直接在 Cloud Storage 中讀取及寫入基礎 Parquet 資料檔案。
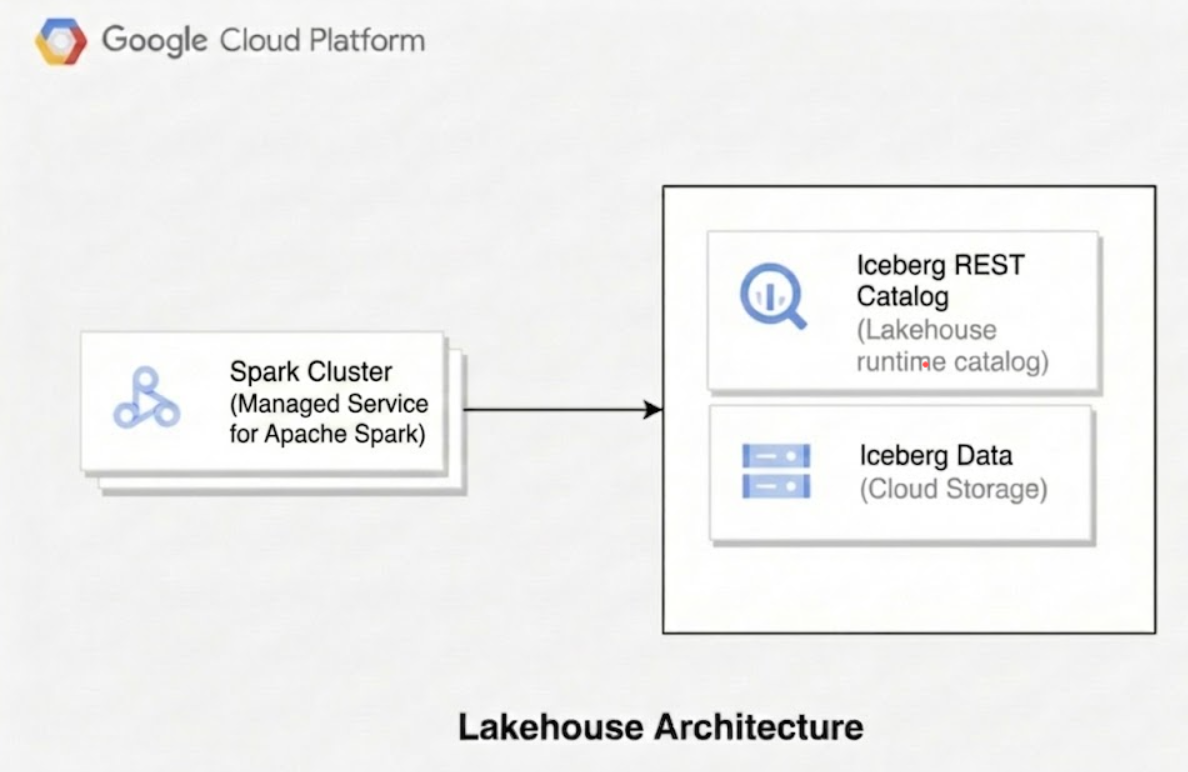
使用 Lakehouse for Apache Iceberg 時,技術架構由三個不同的層組成:
目錄層:
- Iceberg 核心概念:目錄會維護指向最新中繼資料檔案的指標,藉此儲存資料表的目前狀態。這個層可確保符合 ACID 規定並隔離交易,避免並行寫入作業相互干擾。
- Lakehouse 實作:Lakehouse 執行階段目錄是頂層區域中繼資料存放區服務。您可以在這項服務中建立個別目錄,管理資料階層。用戶端查詢引擎會使用特定端點目錄類型 (例如 Apache Iceberg REST 目錄端點),連線至這些目錄。中繼存放區會管理交易提交、儲存空間存取委派的憑證販售,以及目錄中的指標管理。
中繼資料層:
- Iceberg 核心概念:這個層級會使用三種檔案類型的階層,追蹤資料表結構、快照和檔案位置:
- 中繼資料檔案:儲存資料表的結構定義、分割規格和快照指標記錄。
- 資訊清單清單:將一組資訊清單檔案分組,代表資料表的單一快照。
- 資訊清單檔案:追蹤個別檔案層級的資料,儲存檔案路徑、分區資訊和資料欄層級的統計資料 (例如列數、最小值和最大值),用於查詢最佳化和分區修剪。
- Lakehouse 實作:在目錄容器中,將資料整理成邏輯命名空間 (類似於資料集) 和資料表。針對每個資料表,Lakehouse 執行階段目錄會產生並管理基礎 Iceberg 中繼資料階層,從指向資訊清單清單和資訊清單檔案的根
metadata.json檔案開始。Lakehouse 執行階段目錄會直接在您指定的資料倉儲儲存位置保留這些檔案。
- Iceberg 核心概念:這個層級會使用三種檔案類型的階層,追蹤資料表結構、快照和檔案位置:
資料層:
- Iceberg 核心概念:這個元件是基礎儲存空間,實際的原始資料記錄就位於其中,通常採用最佳化單欄式或以資料列為基礎的開放檔案格式,例如 Parquet、ORC 或 Avro。
- Lakehouse 實作:將 Cloud Storage bucket (
gs://) 設定為倉儲儲存位置時,資料表參照的實體資料檔案會安全地儲存在 bucket 中。Lakehouse 執行階段目錄會透過儲存空間存取權委派 (憑證販售) 管理存取權,直接向用戶端引擎販售短期存取權權杖。這樣一來,引擎就能安全地讀取及寫入資料檔案,不必在基礎值區上取得廣泛的直接 IAM 權限。
Lakehouse 執行階段目錄的限制
Lakehouse 執行階段目錄中的資料表有以下限制:
資料表管理
- 您無法使用 BigQuery 資料定義語言 (DDL) 或資料操縱語言 (DML) 陳述式,透過 Apache Iceberg REST 目錄端點建立或修改資料表。您可以使用 BigQuery API (透過 bq 指令列工具或用戶端程式庫) 修改這些資料表,但這麼做可能會導致變更與外部引擎不相容。
- Lakehouse 執行階段目錄中的資料表不支援重新命名作業或
ALTER TABLE ... RENAME TOSpark SQL 陳述式。 - Lakehouse 執行階段目錄中的表格不支援叢集。
- Lakehouse 執行階段目錄中的資料表不支援彈性資料欄名稱。
- Lakehouse 執行階段目錄不支援 Apache Iceberg 檢視區塊。
查詢
- 與查詢標準 BigQuery 資料表中的資料相比,從 BigQuery 引擎查詢 Lakehouse 執行階段目錄中的資料表時,效能可能會較慢。一般來說,查詢速度應與從 Cloud Storage 讀取資料的速度相同。
- 如果查詢使用 Lakehouse 執行階段目錄中的資料表,即使傳回資料列,BigQuery 試算也可能會回報資料下限為 0 位元組。這是因為系統必須執行完整查詢,才能判斷從資料表處理的資料量。執行查詢會產生處理這項資料的費用。
- 您無法在Wildcard 資料表查詢中,參照 Lakehouse 執行階段目錄中的資料表。
API 和中繼資料
- 您無法使用
tabledata.list方法,從 Lakehouse 執行階段目錄中的資料表擷取資料。您可以將查詢結果儲存至 BigQuery 資料表,然後對該資料表使用tabledata.list方法。 - 系統不支援顯示 Lakehouse 執行階段目錄中資料表的資料表儲存空間統計資料。
配額與限制
- BigQuery 中 Lakehouse 執行階段目錄的資料表,與標準資料表適用相同的配額和限制。
與 BigLake metastore (傳統版) 的差異
Lakehouse 執行階段目錄與 BigLake 中繼存放區 (傳統版) 的主要差異包括:
- Lakehouse 執行階段目錄支援與 Spark 等開放原始碼引擎直接整合,有助於減少儲存中繼資料和執行工作時的冗餘。您可以透過多個開放原始碼引擎和 BigQuery,直接存取 Lakehouse 執行階段目錄中的資料表。
- Lakehouse 執行階段目錄支援 Apache Iceberg REST 目錄端點,但 BigLake metastore (傳統版) 不支援。