
Lakehouse for Apache Iceberg ist eine verwaltete Data Lakehouse-Plattform aufGoogle Cloud. Im Kern steht der Lakehouse-Laufzeitkatalog, ein vollständig verwalteter, serverloser Metastore-Dienst, der als zentrale Informationsquelle für Ihre Daten dient. Durch die Zentralisierung dieser Metadaten können mehrere Verarbeitungs-Engines, darunter Apache Spark, Apache Flink, Apache Hive und BigQuery, Tabellen nahtlos gemeinsam nutzen, ohne Dateien zu duplizieren.
Um Ihre Abfrage-Engines mit dem Metastore zu verbinden, konfigurieren Sie einen Client mit einem Endpunkt wie dem Apache Iceberg REST-Katalog. Dies dient als Verwaltungsoberfläche im Lakehouse-Laufzeitkatalog zum Verarbeiten von Tabellenmetadaten, während Cloud Storage zum Speichern der zugrunde liegenden Metadaten und Datendateien verwendet wird.
Hauptfunktionen
Als wichtiger Bestandteil von Lakehouse bietet der Lakehouse-Laufzeitkatalog mehrere Vorteile für die Datenverwaltung und -analyse, darunter eine serverlose Architektur, Engine-Interoperabilität mit offenen APIs, eine einheitliche Benutzeroberfläche und leistungsstarke Analysen, Streaming und KI, wenn Sie ihn mit BigQuery verwenden. Weitere Informationen zu diesen Vorteilen finden Sie unter Was ist ein Lakehouse?
Integration von Lakehouse in Google Cloud
Informationen dazu, wie Ihre Daten in Lakehouse verwaltet werden, finden Sie unter Integration der Lakehouse for Apache Iceberg-Architektur in Google Cloud -Dienste. Bei Apache Iceberg werden Daten nicht in monolithischen Tabellen gespeichert. Stattdessen wird eine mehrschichtige Architektur von Metadatendateien verwendet, um Datendateien in einer zusammenhängenden Tabellenstruktur mit ACID-Transaktionsunterstützung zu organisieren.
Das folgende Diagramm veranschaulicht, wie Compute-Engines wie Managed Service for Apache Spark den Lakehouse-Laufzeitkatalog verwenden, um Tabellenmetadaten zu verwalten, um zugrunde liegende Parquet-Datendateien direkt in Cloud Storage zu lesen und zu schreiben.
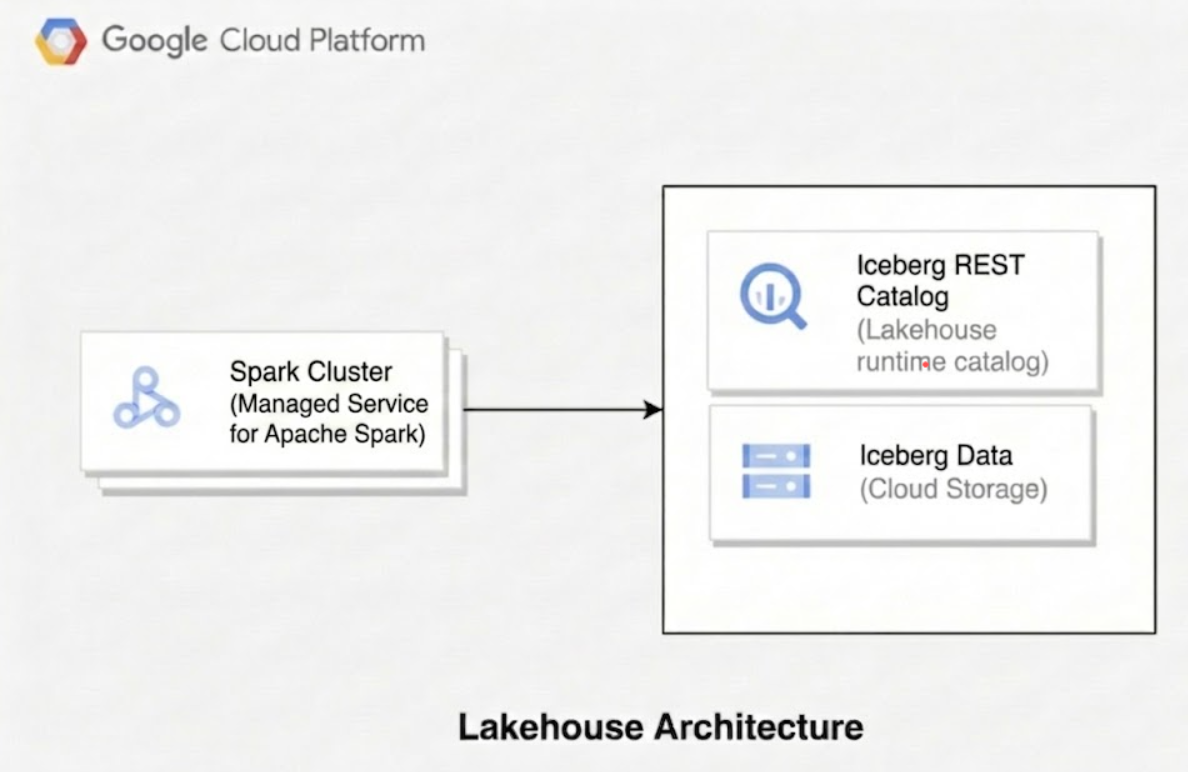
Wenn Sie Lakehouse for Apache Iceberg verwenden, besteht die technische Architektur aus drei verschiedenen Ebenen:
Katalogebene:
- Wichtiges Iceberg-Konzept: Im Katalog wird der aktuelle Status der Tabelle gespeichert, indem ein Zeiger auf die neueste Metadatendatei verwaltet wird. Diese Ebene erleichtert die ACID-Konformität und die Transaktionsisolation, um sicherzustellen, dass sich gleichzeitige Schreibvorgänge nicht gegenseitig stören.
- Lakehouse-Implementierung: Der Lakehouse-Laufzeitkatalog fungiert als regionaler Metastore-Dienst der obersten Ebene. In diesem Dienst erstellen Sie einzelne Kataloge, um Ihre Datenhierarchie zu verwalten. Client-Abfrage-Engines stellen mithilfe bestimmter Endpunktkatalogtypen wie dem Endpunkt Apache Iceberg REST Catalog eine Verbindung zu diesen Katalogen her. Der Metastore verwaltet Transaktions-Commits, Credential Vending für die Delegierung des Speicherzugriffs und die Zeigerverwaltung in Ihren Katalogen.
Metadatenebene:
- Iceberg-Kernkonzept: In dieser Ebene werden die Tabellenstruktur, Snapshots und Dateispeicherorte mithilfe einer Hierarchie von drei Dateitypen erfasst:
- Metadatendateien: Hier werden das Tabellenschema, die Partitionsspezifikation und ein Logbuch mit Snapshot-Zeigern gespeichert.
- Manifestlisten: Sie stellen einen einzelnen Snapshot der Tabelle dar, indem sie eine Sammlung von Manifestdateien gruppieren.
- Manifestdateien: Daten werden auf der Ebene der einzelnen Dateien erfasst. Es werden Dateipfade, Partitionsinformationen und Statistiken auf Spaltenebene gespeichert, z. B. Zeilenanzahl sowie Mindest- und Höchstwerte, die zur Abfrageoptimierung und zum Entfernen von Partitionen verwendet werden.
- Lakehouse-Implementierung: In einem Katalogcontainer organisieren Sie Ihre Daten in logischen Namespaces (ähnlich wie Datasets) und Tabellen. Für jede Tabelle generiert und verwaltet der Lakehouse-Laufzeitkatalog die zugrunde liegende Iceberg-Metadatenhierarchie. Diese beginnt mit einer
metadata.json-Datei auf der Stammebene, die auf die Manifestlisten- und Manifestdateien verweist. Im Lakehouse-Laufzeitkatalog werden diese Dateien direkt in Ihrem angegebenen Warehouse-Speicherort gespeichert.
- Iceberg-Kernkonzept: In dieser Ebene werden die Tabellenstruktur, Snapshots und Dateispeicherorte mithilfe einer Hierarchie von drei Dateitypen erfasst:
Datenschicht:
- Iceberg-Kernkonzept: Diese Komponente ist der zugrunde liegende Speicher, in dem sich die eigentlichen Rohdatensätze befinden, in der Regel in optimierten spalten- oder zeilenbasierten offenen Dateiformaten wie Parquet, ORC oder Avro.
- Lakehouse-Implementierung: Wenn Sie Cloud Storage-Warehouse-Standorte (
bl://odergs://) konfigurieren, werden die physischen Datendateien, auf die in Ihren Tabellen verwiesen wird, sicher in Ihren Buckets gespeichert. Der Lakehouse-Laufzeitkatalog verwaltet den Zugriff über die Delegierung des Speicherzugriffs (Bereitstellung von Anmeldedaten) und stellt kurzlebige Zugriffstokens direkt für Client-Engines bereit. So können Engines Datendateien sicher lesen und schreiben, ohne dass umfassende, direkte IAM-Berechtigungen für die zugrunde liegenden Buckets erforderlich sind.
Implementierung der Apache Iceberg REST-Katalog-API in Lakehouse
Im Lakehouse-Laufzeitkatalog wird die Open-Source-Apache Iceberg REST Catalog API implementiert, um Namespaces und Tabellen zu verwalten. Außerdem bietet sie eine Extensions API speziell für die Katalogverwaltung.
Client-Abfrage-Engines interagieren mit dem Metastore über diese Standard-REST-Katalog-APIs. Weitere Informationen zu Google Cloud-Ressourcen und ‑Endpunkten finden Sie in der Lakehouse REST API-Referenz.
Sie können diese Ressourcen über dieGoogle Cloud Console, die gcloud CLI, die REST API oder Terraform erstellen, konfigurieren und verwalten. Weitere Informationen finden Sie auf den folgenden Seiten:
- Iceberg-REST-Katalogressourcen verwalten
- Tabellen im Lakehouse Iceberg-REST-Katalog verwalten
- Terraform mit Lakehouse verwenden
Kompatibilität und Konfiguration der Abfrage-Engine
Um Daten im Lakehouse-Laufzeitkatalog zu analysieren und zu verwalten, können Sie verschiedene Open-Source- und Enterprise-Abfrage-Engines verbinden. Je nach Ihrer vorhandenen Architektur und den Anforderungen Ihrer Arbeitslasten können Sie aus mehreren unterstützten Engines auswählen und den entsprechenden Katalogendpunkt konfigurieren.
Unterstützte Engines
Der Lakehouse-Laufzeitkatalog ist mit mehreren Abfrage-Engines kompatibel, darunter (aber nicht beschränkt auf) Apache Spark, Apache Flink, Apache Hive und Trino. In der folgenden Tabelle finden Sie Links zur Dokumentation für die einzelnen Engines:
| Engine | Dokumentation |
|---|---|
| Apache Spark | Mit Apache Spark verwenden |
| Apache Hive | Mit Spark und dem Hive-Katalog verwenden |
| Apache Flink | Mit Apache Flink verwenden |
| Trino | Mit Trino verwenden |
Katalogtypen und Endpunktkonfiguration
Wenn Sie Client-Engines für die Verbindung mit dem Metastore des Lakehouse-Laufzeitkatalogs konfigurieren, wählen Sie einen bestimmten Katalog-Endpunkt aus, z. B. den Apache Iceberg-REST-Katalog-Endpunkt oder den Apache Hive-Endpunkt. Die beste Option hängt von Ihrem Anwendungsfall ab, wie in der folgenden Tabelle dargestellt:
| Anwendungsfall | Empfehlung |
|---|---|
| Neue Lakehouse-Laufzeitkatalog-Nutzer, die mit ihrer Open-Source-Engine auf Daten in Cloud Storage zugreifen möchten und Interoperabilität mit anderen Engines benötigen, einschließlich BigQuery und AlloyDB for PostgreSQL. | Verwenden Sie den Apache Iceberg REST-Katalogendpunkt. |
| Nutzer, die Apache Hive- oder Spark-Arbeitslasten ausführen, die von der Hive Metastore-Schnittstelle abhängen, und einen vollständig verwalteten Metastore-Dienst benötigen. | Verwenden Sie den Apache Hive-Katalogendpunkt. |
| Vorhandene Nutzer des Lakehouse-Laufzeitkatalogs, die aktuelle Tabellen mit dem benutzerdefinierten Apache Iceberg-Katalog für den BigQuery-Endpunkt erstellt haben. | Verwenden Sie weiterhin den benutzerdefinierten Apache Iceberg-Katalog für den BigQuery-Endpunkt, aber verwenden Sie den Apache Iceberg-REST-Katalog für neue Arbeitsabläufe. |
Einschränkungen des Lakehouse-Laufzeitkatalogs
Für Tabellen im Lakehouse-Laufzeitkatalog gelten die folgenden allgemeinen Einschränkungen, wenn sie über BigQuery abgefragt werden. Für einzelne Katalogendpunkte (z. B. Apache Iceberg REST oder Apache Hive) gelten möglicherweise zusätzliche endpunktspezifische Einschränkungen.
Tabellenverwaltung
- Apache Iceberg-Tabellen der Version 2 (allgemein verfügbar) und Version 3 (Vorschau) werden unterstützt. Iceberg V1-Tabellen werden nicht unterstützt. Bevor Sie vorhandene V1-Tabellen mit dem Lakehouse-Laufzeitkatalog verwenden können, müssen Sie sie auf eine unterstützte Version aktualisieren. Weitere Informationen finden Sie unter Iceberg-Tabellen von V1 auf V2 aktualisieren.
- Tabellen im Lakehouse-Laufzeitkatalog unterstützen keine Umbenennungsvorgänge oder die Spark SQL-Anweisung
ALTER TABLE ... RENAME TO. - Tabellen im Lakehouse-Laufzeitkatalog unterstützen kein Clustering.
- Tabellen im Lakehouse-Laufzeitkatalog unterstützen keine flexiblen Spaltennamen.
Der Lakehouse-Laufzeitkatalog unterstützt keine Datenbank- oder Metastore-Ansichten.
Der Lakehouse-Laufzeitkatalog unterstützt keine Apache Iceberg-Ansichten.
Abfragen
- Die Abfrageleistung für Tabellen im Lakehouse-Laufzeitkatalog über die BigQuery-Engine ist möglicherweise geringer als bei der Abfrage von Daten in BigQuery-Standardtabellen. Im Allgemeinen sollte die Abfragegeschwindigkeit dem Lesen von Daten aus Cloud Storage entsprechen.
- Ein BigQuery-Probelauf einer Abfrage, die eine Tabelle im Lakehouse-Laufzeitkatalog verwendet, kann eine Untergrenze von 0 Byte an Daten melden, auch wenn Zeilen zurückgegeben werden. Dieses Ergebnis tritt auf, weil die Datenmenge, die aus der Tabelle verarbeitet wird, erst nach Ausführung der vollständigen Abfrage bestimmt werden kann. Für die Ausführung der Abfrage fallen weiterhin Kosten für die Verarbeitung dieser Daten an.
- Sie können in einer Abfrage mit einer Platzhaltertabelle nicht auf eine Tabelle im Lakehouse-Laufzeitkatalog verweisen.
API und Metadaten
- Sie können die
tabledata.list-Methode nicht verwenden, um Daten aus Tabellen im Lakehouse-Laufzeitkatalog abzurufen. Stattdessen können Sie Abfrageergebnisse in einer BigQuery-Tabelle speichern und dann die Methodetabledata.listfür diese Tabelle verwenden. - Die Anzeige von Tabellenspeicherstatistiken für Tabellen im Lakehouse-Laufzeitkatalog wird nicht unterstützt.
Kontingente und Limits
- Für Tabellen im Lakehouse-Laufzeitkatalog in BigQuery gelten dieselben Kontingente und Limits wie für Standardtabellen.
Unterschiede zum klassischen BigLake Metastore
Die wichtigsten Unterschiede zwischen dem Lakehouse-Laufzeitkatalog und dem BigLake-Metastore (klassisch) sind:
- Der Lakehouse-Laufzeitkatalog unterstützt eine direkte Integration mit Open-Source-Engines wie Spark, was dazu beiträgt, Redundanz beim Speichern von Metadaten und Ausführen von Jobs zu reduzieren. Auf Tabellen im Lakehouse-Laufzeitkatalog kann direkt über mehrere Open-Source-Engines und BigQuery zugegriffen werden.
- Der Lakehouse-Laufzeitkatalog unterstützt den Apache Iceberg-REST-Katalogendpunkt, BigLake Metastore (klassisch) jedoch nicht.