
Lakehouse pour Apache Iceberg est une plate-forme de data lakehouse gérée sur Google Cloud. Elle repose sur le catalogue d'environnements d'exécution Lakehouse, un service de metastore sans serveur entièrement géré qui constitue la source unique de vérité pour vos données. En centralisant ces métadonnées, plusieurs moteurs de traitement, y compris Apache Spark, Apache Flink, Apache Hive et BigQuery, peuvent partager des tables de manière transparente sans dupliquer les fichiers.
Pour connecter vos moteurs de requête au metastore, vous configurez un client à l'aide d'un point de terminaison tel que le catalogue REST Apache Iceberg. Il sert d'interface de gestion dans le catalogue d'environnements d'exécution Lakehouse pour gérer les métadonnées de table, tout en s'appuyant sur Cloud Storage pour stocker les métadonnées et les fichiers de données sous-jacents.
Capacités clés
En tant que composant clé de Lakehouse, le catalogue d'environnements d'exécution Lakehouse offre plusieurs avantages pour la gestion et l'analyse des données, y compris une architecture sans serveur, l'interopérabilité des moteurs avec des API ouvertes, une expérience utilisateur unifiée, ainsi que des analyses, des flux de données et une IA hautes performances lorsque vous l'utilisez avec BigQuery. Pour en savoir plus sur ces avantages, consultez Qu'est-ce que Lakehouse ?
Intégration de Lakehouse à Google Cloud
Pour comprendre comment Lakehouse gère vos données, découvrez comment l' architecture Lakehouse pour Apache Iceberg s'intègre aux Google Cloud services. Apache Iceberg ne stocke pas les données dans des tables monolithiques. Au lieu de cela, il utilise une architecture en couches de fichiers de métadonnées pour organiser les fichiers de données dans une structure de table cohérente avec la prise en charge des transactions ACID.
Le schéma suivant illustre comment les moteurs de calcul tels que Managed Service pour Apache Spark utilisent le catalogue d'environnements d'exécution Lakehouse pour gérer les métadonnées de table afin de lire et d'écrire directement les fichiers de données Parquet sous-jacents dans Cloud Storage.
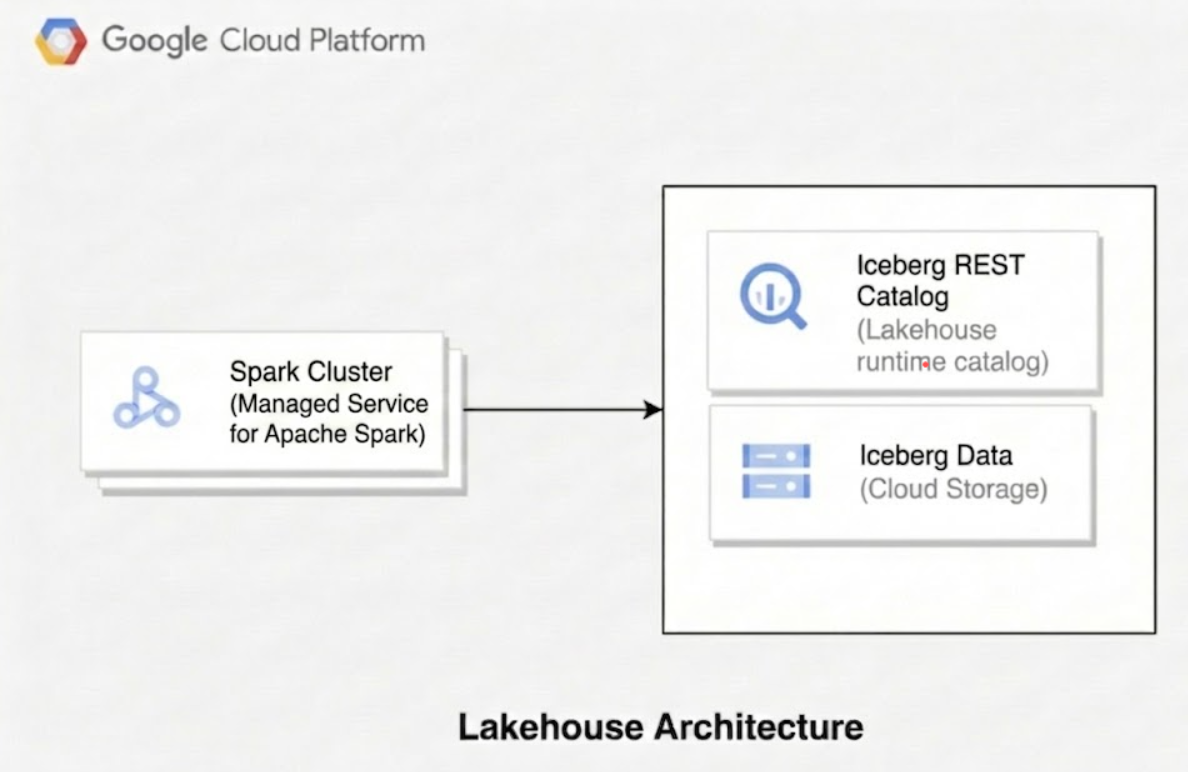
Lorsque vous utilisez Lakehouse pour Apache Iceberg, l'architecture technique se compose de trois couches distinctes :
Couche de catalogue :
- Concept Iceberg de base : le catalogue stocke l'état actuel de la table en conservant un pointeur vers le dernier fichier de métadonnées. Cette couche facilite la conformité ACID et l'isolation des transactions pour s'assurer que les écritures simultanées n'interfèrent pas les unes avec les autres.
- Implémentation Lakehouse : le catalogue d'environnements d'exécution Lakehouse sert de service de metastore régional de premier niveau. Dans ce service, vous créez des catalogues individuels pour gérer votre hiérarchie de données. Les moteurs de requête client se connectent à ces catalogues à l'aide de types de catalogues de points de terminaison spécifiques, tels que le point de terminaison catalogue REST Apache Iceberg. Le metastore gère les validations de transactions, la distribution d'identifiants pour la délégation d'accès au stockage et la gestion des pointeurs dans vos catalogues.
Couche de métadonnées :
- Concept Iceberg de base : cette couche suit la structure de la table,
les instantanés et les emplacements des fichiers à l'aide d'une hiérarchie de trois types de fichiers :
- Fichiers de métadonnées : stockent le schéma de la table, les spécifications de partitionnement et un journal des pointeurs d'instantanés.
- Listes de fichiers manifestes : représentent un seul instantané de la table en regroupant une collection de fichiers manifestes.
- Fichiers manifestes : suivent les données au niveau du fichier individuel, en stockant les chemins d'accès aux fichiers, les informations de partitionnement et les statistiques au niveau des colonnes, par exemple, le nombre de lignes et les valeurs minimales et maximales, qui sont utilisées pour l'optimisation des requêtes et l'élagage des partitions.
- Implémentation Lakehouse : dans un conteneur de catalogue,
vous organisez vos données en espaces de noms logiques (semblables à des
ensembles de données) et en tables. Pour chaque table, le catalogue d'environnements d'exécution Lakehouse génère et gère la hiérarchie de métadonnées Iceberg sous-jacente, en commençant par un fichier
metadata.jsonracine qui pointe vers les listes de fichiers manifestes et les fichiers manifestes. Le catalogue d'environnements d'exécution Lakehouse conserve ces fichiers directement dans l'emplacement de stockage de l'entrepôt que vous avez désigné.
- Concept Iceberg de base : cette couche suit la structure de la table,
les instantanés et les emplacements des fichiers à l'aide d'une hiérarchie de trois types de fichiers :
Couche de données :
- Concept Iceberg de base : ce composant est le stockage sous-jacent où résident les enregistrements de données brutes, généralement dans des formats de fichiers ouverts en colonnes ou basés sur des lignes optimisés, tels que Parquet, ORC ou Avro.
- Implémentation Lakehouse : lorsque vous configurez des emplacements d'entrepôt Cloud
Storage (
bl://ougs://), les fichiers de données physiques référencés par vos tables sont stockés de manière sécurisée dans vos buckets. Le catalogue d'environnements d'exécution Lakehouse gère l'accès via la délégation d'accès au stockage (distribution d'identifiants), en distribuant des jetons d'accès de courte durée directement aux moteurs clients. Cela permet aux moteurs de lire et d'écrire des fichiers de données de manière sécurisée sans nécessiter d'autorisations IAM directes et étendues sur les buckets sous-jacents.
Implémentation par Lakehouse de l'API de catalogue REST Apache Iceberg
Le catalogue d'environnements d'exécution Lakehouse implémente l'Open Source API de catalogue REST Apache Iceberg pour gérer les espaces de noms et les tables. Il fournit également une API d'extensions spécifiquement pour la gestion des catalogues.
Les moteurs de requête client interagissent avec le metastore à l'aide de ces API de catalogue REST standards. Pour en savoir plus sur les ressources et les points de terminaison Google Cloud, consultez la documentation de référence de l'API REST Lakehouse.
Vous pouvez créer, configurer et gérer ces ressources à l'aide de la Google Cloud console, de gcloud CLI, de l'API REST ou de Terraform. Pour en savoir plus, consultez les pages suivantes :
- Gérer les ressources du catalogue REST Iceberg
- Gérer les tables du catalogue REST Iceberg Lakehouse
- Utiliser Terraform avec Lakehouse
Compatibilité et configuration des moteurs de requête
Pour analyser et gérer les données dans le catalogue d'environnements d'exécution Lakehouse, vous pouvez connecter différents moteurs de requête Open Source et d'entreprise. En fonction de votre architecture existante et des exigences de votre charge de travail, vous pouvez choisir parmi plusieurs moteurs compatibles et configurer le point de terminaison de catalogue approprié.
Moteurs compatibles
Le catalogue d'environnements d'exécution Lakehouse est compatible avec plusieurs moteurs de requête, y compris (mais sans s'y limiter) Apache Spark, Apache Flink, Apache Hive et Trino. Le tableau suivant fournit des liens vers la documentation de chaque moteur :
| Moteur | Documentation |
|---|---|
| Apache Spark | Utiliser avec Apache Spark |
| Apache Hive | Utiliser avec Spark et le catalogue Hive |
| Apache Flink | Utiliser avec Apache Flink |
| Trino | Utiliser avec Trino |
Types de catalogues et configuration des points de terminaison
Lorsque vous configurez des moteurs clients pour qu'ils se connectent au metastore du catalogue d'environnements d'exécution Lakehouse, vous sélectionnez un point de terminaison de catalogue spécifique, tel que le point de terminaison catalogue REST Apache Iceberg ou le point de terminaison Apache Hive. La meilleure option dépend de votre cas d'utilisation, comme indiqué dans le tableau suivant :
| Cas d'utilisation | Recommandation |
|---|---|
| Nouveaux utilisateurs du catalogue d'environnements d'exécution Lakehouse qui souhaitent que leur moteur open source accède aux données dans Cloud Storage et qui ont besoin d'une interopérabilité avec d'autres moteurs, y compris BigQuery et AlloyDB pour PostgreSQL. | Utilisez le point de terminaison du catalogue REST Apache Iceberg. |
| Utilisateurs exécutant des charges de travail Apache Hive ou Spark qui dépendent de l'interface Hive Metastore et qui souhaitent un service de metastore entièrement géré. | Utilisez le point de terminaison du catalogue Apache Hive. |
| Utilisateurs existants du catalogue d'environnements d'exécution Lakehouse qui disposent de tables actuelles créées avec le catalogue Apache Iceberg personnalisé pour le point de terminaison BigQuery. | Continuez à utiliser le catalogue Apache Iceberg personnalisé pour le point de terminaison BigQuery, mais utilisez le catalogue REST Apache Iceberg pour les nouveaux workflows. Les tables créées avec le catalogue Apache Iceberg personnalisé pour le point de terminaison BigQuery sont visibles avec le point de terminaison du catalogue REST Apache Iceberg via la fédération de catalogues BigQuery. |
Limites du catalogue d'environnements d'exécution Lakehouse
Les limites générales suivantes s'appliquent aux tables du catalogue d'environnements d'exécution Lakehouse lorsque vous les interrogez via BigQuery. Les points de terminaison de catalogue individuels (tels qu'Apache Iceberg REST ou Apache Hive) peuvent avoir des limites supplémentaires spécifiques aux points de terminaison.
Gestion des tables
- Les tables Apache Iceberg V2 (disponibilité générale) et V3 (aperçu) sont compatibles. Les tables Iceberg V1 ne sont pas compatibles. Avant d'utiliser des tables V1 existantes avec le catalogue d'environnements d'exécution Lakehouse, vous devez les mettre à niveau vers une version compatible. Pour en savoir plus, consultez Mettre à niveau les tables Iceberg V1 vers la version V2.
- Vous ne pouvez pas créer ni modifier de tables avec le point de terminaison du catalogue REST Apache Iceberg à l'aide d'instructions de langage de définition de données (LDD) ou de langage de manipulation de données (LMD) BigQuery. Vous pouvez modifier ces tables à l'aide de l'API BigQuery (avec l'outil de ligne de commande bq ou les bibliothèques clientes), mais vous risquez d'apporter des modifications incompatibles avec le moteur externe.
- Les tables du catalogue d'environnements d'exécution Lakehouse ne sont pas compatibles avec
les opérations de renommage ni avec l'
ALTER TABLE ... RENAME TOinstruction Spark SQL. - Les tables du catalogue d'environnements d'exécution Lakehouse ne sont pas compatibles avec le clustering.
- Les tables du catalogue d'environnements d'exécution Lakehouse ne sont pas compatibles avec les noms de colonnes flexibles.
Le catalogue d'environnements d'exécution Lakehouse n'est pas compatible avec les vues de base de données ni de metastore.
Le catalogue d'environnements d'exécution Lakehouse n'est pas compatible avec les vues Apache Iceberg.
Requête
- Les performances des requêtes pour les tables du catalogue d'environnements d'exécution Lakehouse à partir du moteur BigQuery peuvent être lentes par rapport aux requêtes sur des données dans des tables BigQuery standards. En général, la vitesse des requêtes doit être équivalente à la lecture des données à partir de Cloud Storage.
- Une simulation BigQuery d'une requête qui utilise une table dans le catalogue d'environnements d'exécution Lakehouse peut indiquer une limite inférieure de 0 octet de données, même si des lignes sont renvoyées. Ce résultat se produit, car la quantité de données traitées à partir de la table ne peut pas être déterminée tant que la requête complète n'est pas exécutée. L'exécution de la requête entraîne des frais pour le traitement de ces données.
- Vous ne pouvez pas référencer de table dans le catalogue d'environnements d'exécution Lakehouse dans une requête de table générique.
API et métadonnées
- Vous ne pouvez pas utiliser la
tabledata.listméthode pour récupérer des données à partir de tables dans le catalogue d’environnements d’exécution Lakehouse. Vous pouvez enregistrer les résultats de la requête dans une table BigQuery, puis utiliser la méthodetabledata.listsur cette table. - L'affichage des statistiques de stockage de tables pour les tables du catalogue d'environnements d'exécution Lakehouse n'est pas compatible.
Quotas et limites
- Les tables du catalogue d'environnements d'exécution Lakehouse dans BigQuery sont soumises aux mêmes quotas et limites que les tables standards.
Différences avec BigLake Metastore (classique)
Les principales différences entre le catalogue d'environnements d'exécution Lakehouse et BigLake Metastore (classique) sont les suivantes :
- Le catalogue d'environnements d'exécution Lakehouse est compatible avec une intégration directe aux moteurs Open Source tels que Spark, ce qui permet de réduire la redondance lorsque vous stockez des métadonnées et exécutez des jobs. Les tables du catalogue d'environnements d'exécution Lakehouse sont directement accessibles à partir de plusieurs moteurs Open Source et de BigQuery.
- Le catalogue d'environnements d'exécution Lakehouse est compatible avec le point de terminaison du catalogue REST Apache Iceberg, contrairement à BigLake Metastore (classique).
Étape suivante
- Comprendre le point de terminaison du catalogue REST Apache Iceberg.