
Lakehouse para Apache Iceberg es una plataforma de data lakehouse administrada enGoogle Cloud. En su núcleo, se encuentra el catálogo de entornos de ejecución de Lakehouse, un servicio de metastore sin servidores y completamente administrado que funciona como la única fuente de información para tus datos. Al centralizar estos metadatos, varios motores de procesamiento, incluidos Apache Spark, Apache Flink, Apache Hive y BigQuery, pueden compartir tablas sin problemas y sin duplicar archivos.
Para conectar tus motores de consultas al metastore, configura un cliente con un extremo, como el catálogo REST de Apache Iceberg. Actúa como una interfaz de administración dentro del catálogo del entorno de ejecución de Lakehouse para controlar los metadatos de la tabla, mientras que se basa en Cloud Storage para almacenar los metadatos y los archivos de datos subyacentes.
Funciones clave
Como componente clave de Lakehouse, el catálogo del entorno de ejecución de Lakehouse proporciona varias ventajas para la administración y el análisis de datos, como una arquitectura sin servidores, interoperabilidad del motor con APIs abiertas, una experiencia de usuario unificada y estadísticas, transmisión y análisis de alto rendimiento cuando lo usas con BigQuery. Para obtener más información sobre estos beneficios, consulta ¿Qué es Lakehouse?
Cómo se integra Lakehouse con Google Cloud
Para comprender cómo Lakehouse administra tus datos, consulta cómo la arquitectura de Lakehouse para Apache Iceberg se integra con los servicios de Google Cloud . Apache Iceberg no almacena datos en tablas monolíticas. En cambio, usa una arquitectura en capas de archivos de metadatos para organizar los archivos de datos en una estructura de tabla coherente con compatibilidad para transacciones ACID.
En el siguiente diagrama, se ilustra cómo los motores de procesamiento, como Managed Service para Apache Spark, usan el catálogo del entorno de ejecución de Lakehouse para administrar los metadatos de la tabla y leer y escribir los archivos de datos de Parquet subyacentes directamente en Cloud Storage.
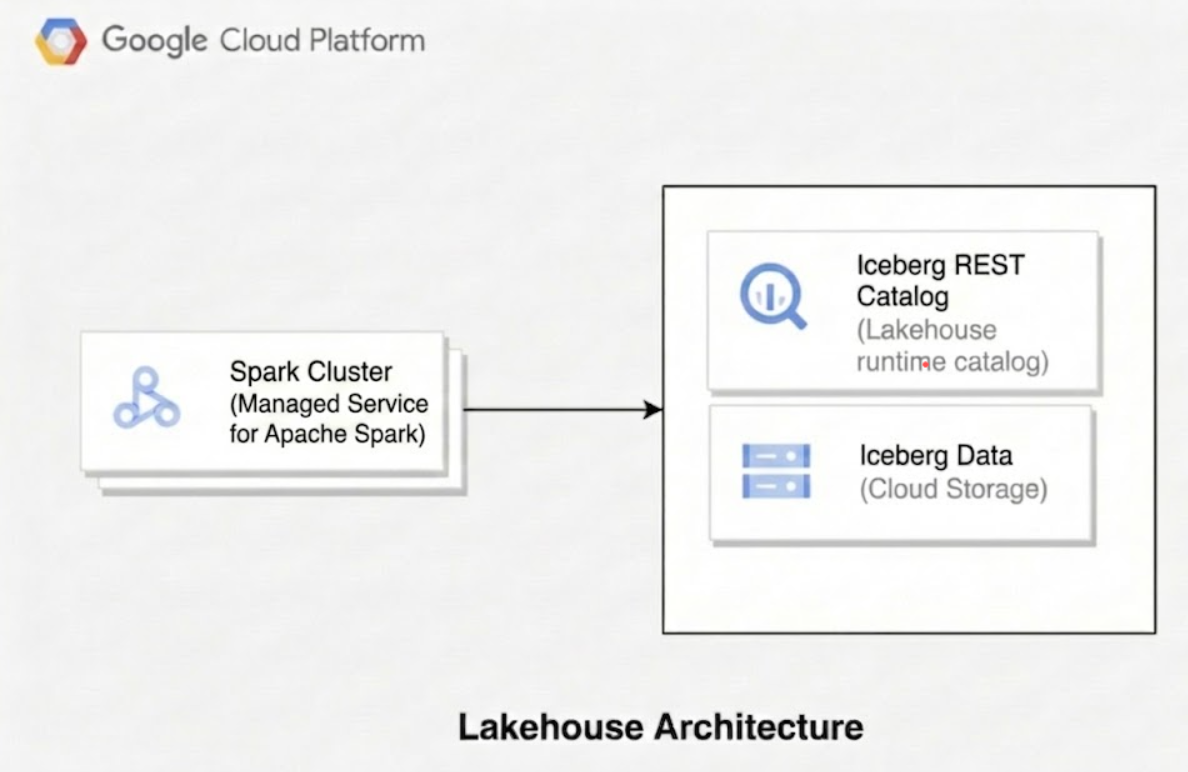
Cuando usas Lakehouse para Apache Iceberg, la arquitectura técnica consta de tres capas distintas:
Capa de catálogo:
- Concepto principal de Iceberg: El catálogo almacena el estado actual de la tabla manteniendo un puntero al archivo de metadatos más reciente. Esta capa facilita el cumplimiento de ACID y el aislamiento de transacciones para garantizar que las escrituras simultáneas no interfieran entre sí.
- Implementación de Lakehouse: El catálogo de entorno de ejecución de Lakehouse actúa como el servicio de metastore regional de nivel superior. Dentro de este servicio, crearás catálogos individuales para administrar tu jerarquía de datos. Los motores de consultas del cliente se conectan a estos catálogos con tipos de catálogos de extremos específicos, como el extremo del catálogo REST de Apache Iceberg. El metastore administra las confirmaciones de transacciones, la venta de credenciales para la delegación del acceso al almacenamiento y la administración de punteros en todos tus catálogos.
Capa de metadatos:
- Concepto principal de Iceberg: Esta capa hace un seguimiento de la estructura de la tabla, las instantáneas y las ubicaciones de los archivos con una jerarquía de tres tipos de archivos:
- Archivos de metadatos: Almacenan el esquema de la tabla, la especificación de partición y un registro de punteros de instantáneas.
- Listas de manifiestos: Representan una sola instantánea de la tabla agrupando una colección de archivos de manifiesto.
- Archivos de manifiesto: Realizan un seguimiento de los datos a nivel de archivo individual y almacenan rutas de acceso a archivos, información de partición y estadísticas a nivel de columna, por ejemplo, recuentos de filas y valores mínimos y máximos, que se utilizan para la optimización de consultas y la eliminación de particiones.
- Implementación de Lakehouse: Dentro de un contenedor de catálogo, organizas tus datos en espacios de nombres lógicos (similares a los conjuntos de datos) y tablas. Para cada tabla, el catálogo del entorno de ejecución de Lakehouse genera y administra la jerarquía de metadatos subyacente de Iceberg, comenzando con un archivo
metadata.jsonraíz que apunta a las listas de manifiestos y los archivos de manifiestos. El catálogo de entornos de ejecución de Lakehouse conserva estos archivos directamente en la ubicación de almacenamiento del almacén designada.
- Concepto principal de Iceberg: Esta capa hace un seguimiento de la estructura de la tabla, las instantáneas y las ubicaciones de los archivos con una jerarquía de tres tipos de archivos:
Capa de datos:
- Concepto principal de Iceberg: Este componente es el almacenamiento subyacente en el que residen los registros de datos sin procesar reales, por lo general, en formatos de archivo abiertos optimizados basados en columnas o filas, como Parquet, ORC o Avro.
- Implementación de Lakehouse: Cuando configuras ubicaciones de almacén de Cloud Storage (
bl://ogs://), los archivos de datos físicos a los que hacen referencia tus tablas se almacenan de forma segura en tus buckets. El catálogo de entornos de ejecución de Lakehouse administra el acceso a través de la delegación de acceso al almacenamiento (venta de credenciales), que vende tokens de acceso de corta duración directamente a los motores cliente. Esto permite que los motores lean y escriban archivos de datos de forma segura sin necesidad de amplios y directos permisos de IAM en los buckets subyacentes.
Cómo Lakehouse implementa la API del catálogo de REST de Apache Iceberg
El catálogo del entorno de ejecución de Lakehouse implementa la API del catálogo de REST de Apache Iceberg de código abierto para administrar los espacios de nombres y las tablas. También proporciona una API de extensiones específicamente para la administración del catálogo.
Los motores de consultas del cliente interactúan con el metastore a través de estas APIs de catálogo de REST estándar. Para obtener detalles sobre los recursos y extremos de Google Cloud, consulta la referencia de la API de REST de Lakehouse.
Puedes crear, configurar y administrar estos recursos con laGoogle Cloud console, la gcloud CLI, la API de REST o Terraform. Si deseas obtener más información, consulta las siguientes páginas:
- Administra recursos del catálogo de REST de Iceberg
- Administra tablas del catálogo de REST de Lakehouse para Iceberg
- Usa Terraform con Lakehouse
Compatibilidad y configuración del motor de consultas
Para analizar y administrar datos en el catálogo del entorno de ejecución de Lakehouse, puedes conectar diferentes motores de consultas de código abierto y empresariales. Según tu arquitectura existente y los requisitos de carga de trabajo, puedes elegir entre varios motores compatibles y configurar el extremo de catálogo adecuado.
Motores compatibles
El catálogo del entorno de ejecución de Lakehouse es compatible con varios motores de consultas, incluidos (sin limitaciones) Apache Spark, Apache Flink, Apache Hive y Trino. En la siguiente tabla, se proporcionan vínculos a la documentación de cada motor:
| Motor | Documentación |
|---|---|
| Apache Spark | Uso con Apache Spark |
| Apache Hive | Uso con Spark y el catálogo de Hive |
| Apache Flink | Uso con Apache Flink |
| Trino | Uso con Trino |
Tipos de catálogos y configuración de extremos
Cuando configuras motores cliente para conectarse al metastore del catálogo del entorno de ejecución de Lakehouse, seleccionas un extremo de catálogo específico, como el extremo del catálogo de REST de Apache Iceberg o el extremo de Apache Hive. La mejor opción depende de tu caso de uso, como se muestra en la siguiente tabla:
| Caso práctico | Recomendación |
|---|---|
| Nuevos usuarios del catálogo de tiempo de ejecución de Lakehouse que desean que su motor de código abierto acceda a los datos en Cloud Storage y necesitan interoperabilidad con otros motores, incluidos BigQuery y AlloyDB para PostgreSQL. | Usa el extremo del catálogo de REST de Apache Iceberg. |
| Usuarios que ejecutan cargas de trabajo de Apache Hive o Spark que dependen de la interfaz de Hive Metastore y desean un servicio de metastore completamente administrado | Usa el extremo del catálogo de Apache Hive. |
| Usuarios existentes del catálogo de entorno de ejecución de Lakehouse que tienen tablas actuales creadas con el catálogo personalizado de Apache Iceberg para el extremo de BigQuery | Sigue usando el extremo del catálogo personalizado de Apache Iceberg para BigQuery, pero usa el catálogo REST de Apache Iceberg para los flujos de trabajo nuevos. |
Limitaciones del catálogo de entorno de ejecución de Lakehouse
Se aplican las siguientes limitaciones generales a las tablas del catálogo del entorno de ejecución de Lakehouse cuando se consultan a través de BigQuery. Los extremos de catálogo individuales (como Apache Iceberg REST o Apache Hive) pueden tener limitaciones adicionales específicas del extremo.
Administración de tablas
- Se admiten las tablas de Apache Iceberg V2 (GA) y V3 (versión preliminar). No se admiten las tablas de Iceberg V1. Antes de usar tablas existentes de la versión 1 con el catálogo del entorno de ejecución de Lakehouse, debes actualizarlas a una versión compatible. Para obtener más información, consulta Actualiza las tablas de Iceberg V1 a V2.
- Las tablas del catálogo del entorno de ejecución de Lakehouse no admiten operaciones de cambio de nombre ni la instrucción
ALTER TABLE ... RENAME TOde Spark SQL. - Las tablas del catálogo de entorno de ejecución de Lakehouse no admiten el agrupamiento en clústeres.
- Las tablas del catálogo de entorno de ejecución de Lakehouse no admiten nombres de columnas flexibles.
El catálogo de entornos de ejecución de Lakehouse no admite vistas de bases de datos ni de metastore.
El catálogo de entorno de ejecución de Lakehouse no admite vistas de Apache Iceberg.
Realiza consultas
- El rendimiento de las consultas de las tablas en el catálogo del entorno de ejecución de Lakehouse desde el motor de BigQuery puede ser lento en comparación con la consulta de datos en tablas estándar de BigQuery. En general, la velocidad de las consultas debe ser equivalente a la lectura de datos de Cloud Storage.
- Una ejecución de prueba de BigQuery de una consulta que usa una tabla en el catálogo del entorno de ejecución de Lakehouse puede informar un límite inferior de 0 bytes de datos, incluso si se muestran filas. Este resultado se produce porque la cantidad de datos que se procesan desde la tabla no se puede determinar hasta que se ejecuta la consulta completa. La ejecución de la consulta genera un costo por procesar estos datos.
- No puedes hacer referencia a una tabla en el catálogo de entorno de ejecución de Lakehouse en una consulta de tabla comodín.
API y metadatos
- No puedes usar el método
tabledata.listpara recuperar datos de tablas en el catálogo del tiempo de ejecución de Lakehouse. En su lugar, puedes guardar los resultados de la consulta en una tabla de BigQuery y, luego, usar el métodotabledata.listen esa tabla. - No se admite la visualización de estadísticas de almacenamiento de tablas en el catálogo del entorno de ejecución de Lakehouse.
Cuotas y límites
- Las tablas del catálogo del entorno de ejecución de Lakehouse en BigQuery están sujetas a las mismas cuotas y límites que las tablas estándar.
Diferencias con BigLake Metastore (clásico)
Las principales diferencias entre el catálogo del entorno de ejecución de Lakehouse y el metastore de BigLake (clásico) incluyen las siguientes:
- El catálogo de entorno de ejecución de Lakehouse admite una integración directa con motores de código abierto, como Spark, lo que ayuda a reducir la redundancia cuando almacenas metadatos y ejecutas trabajos. Se puede acceder directamente a las tablas del catálogo de entorno de ejecución de Lakehouse desde varios motores de código abierto y BigQuery.
- El catálogo de entorno de ejecución de Lakehouse admite el extremo del catálogo de REST de Apache Iceberg, mientras que BigLake Metastore (clásico) no lo hace.
¿Qué sigue?
- Comprende el extremo del catálogo de REST de Apache Iceberg.