
Lakehouse for Apache Iceberg は、 Google Cloud上のマネージド データ レイクハウス プラットフォームです。その中核となるのは、Lakehouse ランタイム カタログです。これは、データの信頼できる唯一の情報源となるフルマネージドのサーバーレス メタストア サービスです。このメタデータを一元化することで、Apache Spark、Apache Flink、Apache Hive、BigQuery などの複数の処理エンジンが、ファイルを重複させることなくテーブルをシームレスに共有できます。
クエリエンジンをメタストアに接続するには、Apache Iceberg REST カタログなどのカタログタイプを使用してクライアントを構成します。これにより、Lakehouse ランタイム カタログ内にテーブル メタデータを処理するための管理エンドポイントが作成されます。基盤となるメタデータとデータファイルは Cloud Storage に保存されます。
主な機能
Lakehouse ランタイム カタログは、Lakehouse for Apache Iceberg の主要コンポーネントとして、データ 管理と分析にいくつかのメリットをもたらします。たとえば、サーバーレス アーキテクチャ、オープン API を使用したエンジン間の相互運用性、統合されたユーザー エクスペリエンス、BigQuery との併用による高性能な分析、ストリーミング、AI などです。これらのメリットの詳細については、Lakehouse とは をご覧ください。
Lakehouse と の統合方法 Google Cloud
Lakehouse がデータを管理する方法については、 Lakehouse for Apache Iceberg アーキテクチャと Google Cloud サービスの統合方法をご覧ください。 Apache Iceberg は、モノリシック テーブルにデータを保存しません。代わりに、メタデータ ファイルの階層化されたアーキテクチャを使用して、データファイルを ACID トランザクションをサポートするまとまりのあるテーブル構造に整理します。
次の図は、Managed Service for Apache Spark などのコンピューティング エンジンが Lakehouse ランタイム カタログを使用してテーブル メタデータを管理し、Cloud Storage 内の基盤となる Parquet データファイルを直接読み書きする方法を示しています。
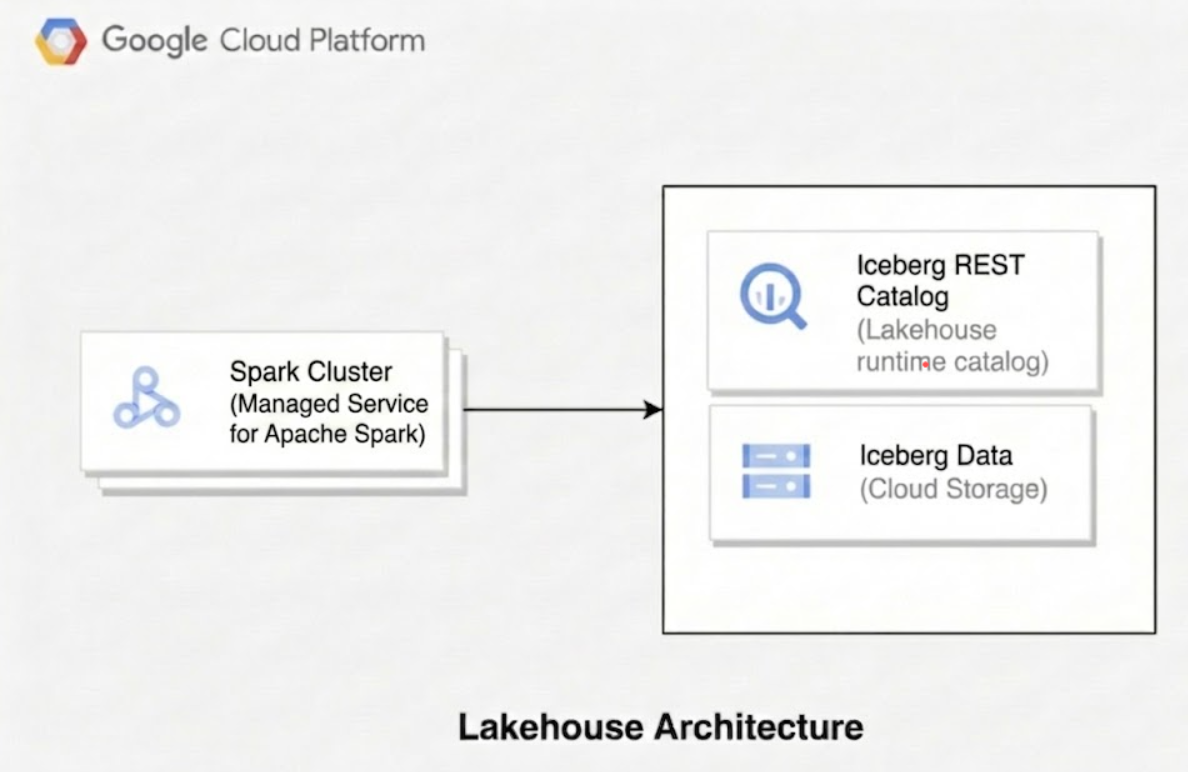
Lakehouse for Apache Iceberg を使用する場合、技術アーキテクチャは次の 3 つの異なるレイヤで構成されます。
カタログレイヤ:
- Iceberg のコアコンセプト: カタログは、最新のメタデータ ファイルへのポインタを保持することで、 テーブルの現在の状態を保存します。このレイヤは、ACID 準拠とトランザクション分離を容易にし、同時書き込みが相互に干渉しないようにします。
- Lakehouse の実装: Lakehouse ランタイム カタログ は、最上位の リージョン メタストア サービスとして機能します。このサービス内で、個々の カタログを作成してデータ階層を管理します。クライアント クエリエンジンは、特定のエンドポイント カタログタイプを使用して、これらのカタログに接続します。たとえば、Apache Iceberg REST カタログ エンドポイントなどです。メタストアは、 トランザクションのコミット、ストレージ アクセス 委任の認証情報ベンダー、カタログ間のポインタ管理を管理します。
メタデータ レイヤ:
- Iceberg のコアコンセプト: このレイヤは、次の 3 種類のファイルタイプの階層を使用して、テーブル構造、
スナップショット、ファイルの場所を追跡します:
- メタデータ ファイル: テーブルのスキーマ、パーティション 仕様、スナップショット ポインタのログを保存します。
- マニフェスト リスト: マニフェスト ファイルのコレクションを グループ化して、テーブルの単一のスナップショットを表します。
- マニフェスト ファイル: 個々のファイルレベルでデータを追跡し、 ファイルパス、パーティション情報、列レベルの 統計情報(行数、最小値、最大値 など)を保存します。これらは、クエリの最適化とパーティション プルーニングに使用されます。
- Lakehouse の実装: カタログ コンテナ内で、
データを論理的な 名前空間 (
データセットと同様)と テーブルに整理します。各テーブルについて、Lakehouse ランタイム カタログは、マニフェスト リストとマニフェスト ファイルを指すルート
metadata.jsonファイルから始まる、基盤となる Iceberg メタデータ階層を生成して管理します。Lakehouse ランタイム カタログは、これらのファイルを指定されたウェアハウス ストレージの場所に直接保存します。
- Iceberg のコアコンセプト: このレイヤは、次の 3 種類のファイルタイプの階層を使用して、テーブル構造、
スナップショット、ファイルの場所を追跡します:
データレイヤ:
- Iceberg のコアコンセプト: このコンポーネントは、 実際の未加工データ レコードが存在する基盤となるストレージです。通常は、最適化された列ベースまたは 行ベースのオープン ファイル形式 (Parquet、ORC、Avro など) です。
- Lakehouse の実装: Cloud Storage ウェアハウスの場所(
bl://またはgs://)を構成すると、テーブルで参照される物理データファイルがバケット内に安全に保存されます。Lakehouse ランタイム カタログは、 ストレージ アクセス委任(認証情報ベンダー)を介してアクセスを管理し、 有効期間の短いアクセス トークンをクライアント エンジンに直接提供します。これにより、エンジンは基盤となるバケットに対する広範な直接 IAM 権限を必要とせずに、データファイルを安全に読み書きできます。
Lakehouse で Apache Iceberg REST カタログ API を実装する方法
Lakehouse ランタイム カタログは、オープンソースの Apache Iceberg REST カタログ API を実装して、名前空間とテーブルを管理します。また、カタログ管理専用の拡張 API も提供します。
クライアント クエリエンジンは、これらの標準 REST カタログ API を使用してメタストアとやり取りします。Google Cloud リソースとエンドポイントの詳細については、 Lakehouse REST API リファレンスをご覧ください。
これらのリソースは、 Google Cloud コンソール、gcloud CLI、REST API、または Terraform を使用して作成、構成、管理できます。 詳しくは次のページをご覧ください。
クエリエンジンの互換性と構成
Lakehouse ランタイム カタログでデータを分析して管理するには、さまざまなオープンソース エンジンとエンタープライズ クエリエンジンを接続できます。既存のアーキテクチャとワークロードの要件に応じて、サポートされている複数のエンジンから選択し、適切なカタログ エンドポイントを構成できます。
サポートされているエンジン
Lakehouse ランタイム カタログは、Apache Spark、Apache Flink、Apache Hive、Trino などの複数のクエリエンジンと互換性があります。次の表に、各エンジンのドキュメントへのリンクを示します。
| エンジン | ドキュメント |
|---|---|
| Apache Spark | クイックスタート: Spark と Iceberg REST カタログ エンドポイントで使用する |
| Apache Hive | Spark と Hive カタログで使用する |
| Apache Flink | Apache Flink で使用する |
| Trino | Trino で使用する |
カタログタイプとエンドポイント構成
Lakehouse ランタイム カタログ メタストアに接続するようにクライアント エンジンを構成する場合は、 Apache Iceberg REST カタログ エンドポイントや Apache Hive エンドポイントなど、特定の カタログ エンドポイントを選択します。最適なオプションはユースケースによって異なります。次の表をご覧ください。
| ユースケース | 推奨事項 |
|---|---|
| オープンソース エンジンで Cloud Storage のデータにアクセスし、BigQuery や AlloyDB for PostgreSQL などの他のエンジンとの相互運用が必要な Lakehouse ランタイム カタログの新規ユーザー。 | Apache Iceberg REST カタログ エンドポイントを使用します。 |
| Hive Metastore インターフェースに依存する Apache Hive または Spark ワークロードを実行していて、フルマネージドのメタストア サービスを必要とするユーザー。 | Apache Hive カタログ エンドポイントを使用します。 |
| BigQuery エンドポイント用のカスタム Apache Iceberg カタログで作成された現在の テーブルがある、既存の Lakehouse ランタイム カタログ ユーザー。 | BigQuery エンドポイント用の カスタム Apache Iceberg カタログを引き続き使用しますが、新しいワークフローには Apache Iceberg REST カタログを使用します。BigQuery カタログ連携により、BigQuery エンドポイント用のカスタム Apache Iceberg カタログで作成されたテーブルは、Apache Iceberg REST カタログ エンドポイントで表示されます。 |
Lakehouse ランタイム カタログの制限事項
BigQuery を介してクエリを実行する場合、Lakehouse ランタイム カタログのテーブルには次の一般的な制限が適用されます。 個々のカタログ エンドポイント(Apache Iceberg REST や Apache Hive など)には、エンドポイント固有の追加の制限がある場合があります。
テーブル管理
- Apache Iceberg V2 テーブル(一般提供)と V3 テーブル(プレビュー)がサポートされています。Iceberg V1 テーブルはサポートされていません。Lakehouse ランタイム カタログで既存の V1 テーブルを使用する前に、サポートされているバージョンにアップグレードする必要があります。詳細については、Iceberg V1 テーブルを V2 にアップグレードするをご覧ください。
- BigQuery データ定義言語(DDL)またはデータ操作言語(DML)ステートメントを使用して、Apache Iceberg REST カタログ エンドポイントでテーブルを作成または変更することはできません。BigQuery API(bq コマンドライン ツールまたはクライアント ライブラリを使用)を使用してこれらのテーブルを変更することはできますが、外部エンジンと互換性のない変更が行われる可能性があります。
- Lakehouse ランタイム カタログのテーブルは、
名前変更オペレーションや
ALTER TABLE ... RENAME TOSpark SQL ステートメントをサポートしていません。 - Lakehouse ランタイム カタログのテーブルは クラスタリングをサポートしていません。
- Lakehouse ランタイム カタログのテーブルは、 柔軟な列名をサポートしていません。
Lakehouse ランタイム カタログは、データベース ビューまたはメタストア ビューをサポートしていません。
Lakehouse ランタイム カタログは、Apache Iceberg ビューをサポートしていません。
クエリ
- BigQuery エンジンの Lakehouse ランタイム カタログのテーブルに対するクエリのパフォーマンスは、標準的な BigQuery テーブルのデータに対するクエリよりも低速になる可能性があります。一般的に、クエリ速度は Cloud Storage からのデータの読み取りと同等になります。
- Lakehouse ランタイム カタログのテーブルを使用するクエリの BigQuery ドライランで、行が返されても、下限 0 バイトと報告される場合があります。これは、クエリ全体が実行されるまで、テーブルから処理されるデータの量を決定できないためです。クエリを実行すると、このデータの処理に費用がかかります。
- ワイルドカード テーブル クエリで Lakehouse ランタイム カタログのテーブルを参照することはできません。 ワイルドカード テーブル クエリ。
API とメタデータ
tabledata.listメソッド を使用して、Lakehouse ランタイム カタログのテーブルからデータを取得することはできません。代わりに、クエリ結果を BigQuery テーブルに保存し、そのテーブルでtabledata.listメソッドを使用できます。- Lakehouse ランタイム カタログのテーブルのテーブル ストレージ統計情報の表示はサポートされていません。
割り当てと上限
- BigQuery の Lakehouse ランタイム カタログのテーブルには、標準的なテーブルと同じ 割り当てと 上限が適用されます。
BigLake metastore(クラシック)との違い
Lakehouse ランタイム カタログと BigLake metastore(クラシック)の主な違いは次のとおりです。
- Lakehouse ランタイム カタログは、Spark などのオープンソース エンジンとの直接統合をサポートしているため、メタデータの保存とジョブの実行時の冗長性を軽減できます。Lakehouse ランタイム カタログのテーブルには、複数のオープンソース エンジンと BigQuery から直接アクセスできます。
- Lakehouse ランタイム カタログは Apache Iceberg REST カタログ エンドポイントをサポートしていますが、BigLake metastore(クラシック)はサポートしていません。
次のステップ
- Apache Iceberg REST カタログ エンドポイントについて理解する。