
Lakehouse for Apache Iceberg 是Google Cloud上的一种托管数据湖仓平台。其核心是 Lakehouse 运行时目录,这是一项全代管式无服务器 metastore 服务,可作为数据的单一可信来源。通过集中管理这些元数据,多个处理引擎(包括 Apache Spark、Apache Flink、Apache Hive 和 BigQuery)可以无缝共享表,而无需复制文件。
如需将查询引擎连接到 metastore,您可以使用 Apache Iceberg REST 目录等目录类型来配置客户端。这会在 Lakehouse 运行时目录中创建一个管理端点来处理表元数据,同时依靠 Cloud Storage 来存储底层元数据和数据文件。
主要功能
作为 Lakehouse for Apache Iceberg 的关键组件,Lakehouse 运行时目录在数据管理和分析方面具有多项优势,包括无服务器架构、通过开放 API 实现引擎互操作性、统一的用户体验,以及与 BigQuery 搭配使用时可实现高性能分析、流式传输和 AI。如需详细了解这些优势,请参阅什么是 Lakehouse?
湖仓一体如何与 Google Cloud集成
如需了解 Lakehouse 如何管理数据,请参阅 Lakehouse for Apache Iceberg 架构如何与 Google Cloud 服务集成。 Apache Iceberg 不会将数据存储在单体表中。相反,它使用元数据文件的分层架构将数据文件整理成具有 ACID 事务支持的统一表结构。
下图展示了托管式 Apache Spark 等计算引擎如何使用 Lakehouse 运行时目录来管理表元数据,以便直接在 Cloud Storage 中读取和写入底层 Parquet 数据文件。
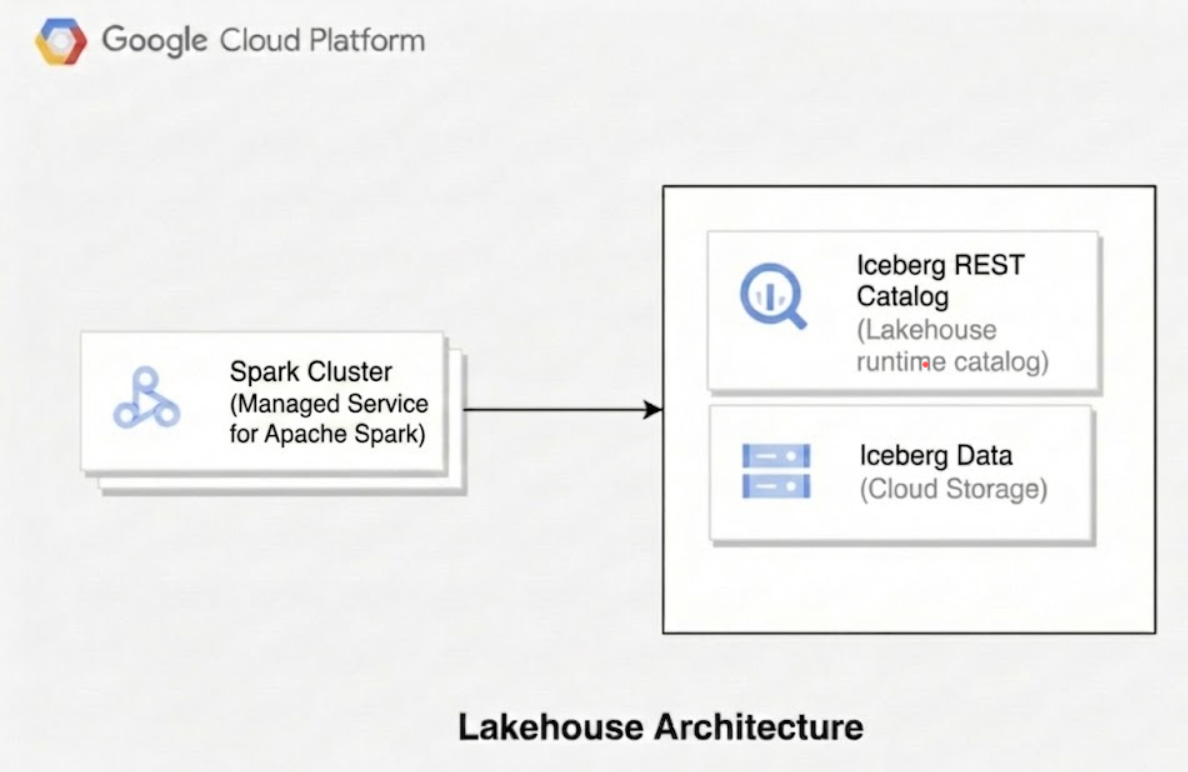
使用 Lakehouse for Apache Iceberg 时,技术架构包含三个不同的层:
目录层:
元数据层:
- 核心 Iceberg 概念:此层使用三种文件类型的层次结构来跟踪表结构、快照和文件位置:
- 元数据文件:存储表的架构、分区规范和快照指针日志。
- 清单列表:通过对一组清单文件进行分组来表示表的单个快照。
- 清单文件:在单个文件级别跟踪数据,存储文件路径、分区信息和列级统计信息(例如行数以及最小值和最大值),这些信息用于查询优化和分区剪除。
- 数据湖仓实现:在目录容器中,您可以将数据整理成逻辑命名空间(类似于数据集)和表。对于每个表,Lakehouse 运行时目录都会生成并管理底层 Iceberg 元数据层次结构,从指向清单列表和清单文件的根
metadata.json文件开始。Lakehouse 运行时目录会将这些文件直接持久化到您指定的仓库存储位置。
- 核心 Iceberg 概念:此层使用三种文件类型的层次结构来跟踪表结构、快照和文件位置:
数据层:
Lakehouse 如何实现 Apache Iceberg REST Catalog API
Lakehouse 运行时目录实现了开源 Apache Iceberg REST Catalog API,用于管理命名空间和表。它还提供专门用于目录管理的扩展 API。
客户端查询引擎使用这些标准 REST 目录 API 与元存储区进行交互。如需详细了解 Google Cloud 资源和端点,请参阅 Lakehouse REST API 参考文档。
您可以使用Google Cloud 控制台、gcloud CLI、REST API 或 Terraform 创建、配置和管理这些资源。 如需了解详情,请参阅以下页面:
查询引擎兼容性和配置
如需在 Lakehouse 运行时目录中分析和管理数据,您可以连接不同的开源和企业查询引擎。您可以根据现有架构和工作负载要求,从多个受支持的引擎中进行选择,并配置相应的目录端点。
支持的引擎
Lakehouse 运行时目录与多种查询引擎兼容,包括但不限于 Apache Spark、Apache Flink、Apache Hive 和 Trino。下表提供了指向每种引擎的文档的链接:
| Engine | 文档 |
|---|---|
| Apache Spark | 快速入门:与 Spark 和 Iceberg REST Catalog 端点搭配使用 |
| Apache Hive | 与 Spark 和 Hive 目录搭配使用 |
| Apache Flink | 与 Apache Flink 搭配使用 |
| Trino | 与 Trino 搭配使用 |
目录类型和端点配置
在配置客户端引擎以连接到 Lakehouse 运行时目录 metastore 时,您需要选择特定的目录端点,例如 Apache Iceberg REST 目录端点或 Apache Hive 端点。最佳选择取决于您的使用情形,如下表所示:
| 用例 | 建议 |
|---|---|
| 希望其开源引擎能够访问 Cloud Storage 中的数据,并且需要与其他引擎(包括 BigQuery 和 AlloyDB for PostgreSQL)实现互操作性的新 Lakehouse 运行时目录用户。 | 使用 Apache Iceberg REST Catalog 端点。 |
| 运行依赖于 Hive Metastore 接口的 Apache Hive 或 Spark 工作负载,并且希望使用全代管式 metastore 服务的用户。 | 使用 Apache Hive Catalog 端点。 |
| 使用自定义 Apache Iceberg 目录为 BigQuery 端点创建了当前表的现有 Lakehouse 运行时目录用户。 | 继续使用 BigQuery 端点的自定义 Apache Iceberg 目录,但对于新工作流,请使用 Apache Iceberg REST 目录。通过 BigQuery 目录联合,使用自定义 Apache Iceberg 目录为 BigQuery 端点创建的表可通过 Apache Iceberg REST 目录端点查看。 |
Lakehouse 运行时目录限制
通过 BigQuery 查询 Lakehouse 运行时目录中的表时,存在以下一般限制。 各个目录端点(例如 Apache Iceberg REST 或 Apache Hive)可能还有其他特定于端点的限制。
表格管理
- 支持 Apache Iceberg V2 表(正式版)和 V3 表(预览版)。不支持 Iceberg V1 表。在将现有 V1 表与 Lakehouse 运行时目录搭配使用之前,您必须将这些表升级到受支持的版本。如需了解详情,请参阅将 Iceberg V1 表升级到 V2。
- 您无法使用 BigQuery 数据定义语言 (DDL) 或数据操纵语言 (DML) 语句通过 Apache Iceberg REST 目录端点创建或修改表。您可以使用 BigQuery API(通过 bq 命令行工具或客户端库)修改这些表,但这样做可能会导致更改与外部引擎不兼容。
- 湖仓一体运行时目录中的表不支持重命名操作或
ALTER TABLE ... RENAME TOSpark SQL 语句。 - Lakehouse 运行时目录中的表不支持聚类。
- Lakehouse 运行时目录中的表不支持使用灵活的列名称。
Lakehouse 运行时目录不支持数据库或 metastore 视图。
Lakehouse 运行时目录不支持 Apache Iceberg 视图。
查询
- 与在标准 BigQuery 表中查询数据相比,BigQuery 引擎中 Lakehouse 运行时目录内表的查询性能可能较慢。一般来说,查询速度应等同于从 Cloud Storage 读取数据的速度。
- 使用 Lakehouse 运行时目录中的表的查询的 BigQuery 试运行可能会报告 0 字节数据的下限,即使在返回了数据行的情况下也是如此。出现这种结果的原因是,在运行完整查询之前,无法确定从表中处理的数据量。运行查询会产生处理此数据的费用。
- 您无法在通配符表查询中引用 Lakehouse 运行时目录中的表。
API 和元数据
- 您无法使用
tabledata.list方法从 Lakehouse 运行时目录中的表检索数据。不过,您可以将查询结果保存到 BigQuery 表中,然后对该表使用tabledata.list方法。 - 不支持显示 Lakehouse 运行时目录中表的表存储空间统计信息。
配额和限制
- BigQuery 中 Lakehouse 运行时目录中的表与标准表具有相同的配额和限制。
与 BigLake metastore(经典版)的差异
Lakehouse 运行时目录与 BigLake metastore(经典版)之间的核心区别包括以下几点:
- Lakehouse 运行时目录支持与 Spark 等开源引擎直接集成,这有助于减少存储元数据和运行作业时的冗余。您可以直接从多个开源引擎和 BigQuery 访问 Lakehouse 运行时目录中的表。
- Lakehouse 运行时目录支持 Apache Iceberg REST 目录端点,而 BigLake metastore(经典版)不支持。