
O Lakehouse para Apache Iceberg é uma plataforma de data lakehouse gerenciada no Google Cloud. Nessa plataforma, o catálogo de ambientes de execução do Lakehouse funciona como o serviço de metastore totalmente gerenciado e sem servidor. Ele fornece uma única fonte de verdade para o data lakehouse, o que permite que vários mecanismos, incluindo Apache Spark, Apache Flink, Apache Hive e BigQuery, compartilhem tabelas e metadados sem copiar arquivos.
Para conectar mecanismos de consulta ao metastore, configure um cliente usando um tipo de catálogo específico, como o endpoint do catálogo REST do Apache Iceberg. Esse endpoint gerencia os metadados da tabela e usa um data warehouse de local de armazenamento com suporte de um bucket do Cloud Storage para armazenar os metadados e arquivos de dados subjacentes. Para mais informações sobre como escolher um tipo de catálogo, consulte Tipos de catálogo e configuração de endpoint.
O catálogo de ambientes de execução do Lakehouse oferece suporte à delegação de acesso ao armazenamento, também conhecida como venda de credenciais, que melhora a segurança ao remover a necessidade de acesso direto ao bucket do Cloud Storage. Ele também se integra ao Knowledge Catalog para governança unificada, linhagem e qualidade de dados. Quando as tabelas são registradas no catálogo de ambientes de execução do Lakehouse, as entradas correspondentes são registradas automaticamente no catálogo de metadados comerciais (Knowledge Catalog), garantindo a descoberta e a governança de dados consistentes sem mover ou copiar arquivos.
Principais recursos
Como um componente essencial do Lakehouse para Apache Iceberg, o catálogo de ambientes de execução do Lakehouse oferece várias vantagens para gerenciamento e análise de dados, incluindo uma arquitetura sem servidor, interoperabilidade de mecanismos com APIs abertas, uma experiência unificada do usuário e análises, streaming e IA de alta performance ao usar com o BigQuery. Para mais informações sobre esses benefícios, consulte O que é o Lakehouse?
Como a arquitetura do Lakehouse se integra aos Google Cloud serviços
Para entender como o Lakehouse gerencia seus dados, consulte Como a arquitetura do Lakehouse para Apache Iceberg se integra aos Google Cloud serviços. O Apache Iceberg não armazena dados em tabelas monolíticas. Em vez disso, ele usa uma arquitetura em camadas de arquivos de metadados para organizar arquivos de dados em uma estrutura de tabela coesa com suporte a transações ACID.
O diagrama a seguir ilustra como mecanismos de computação, como o Serviço Gerenciado para Apache Spark, usam o catálogo de ambientes de execução do Lakehouse para gerenciar metadados de tabelas para ler e gravar arquivos de dados Parquet subjacentes diretamente no Cloud Storage.
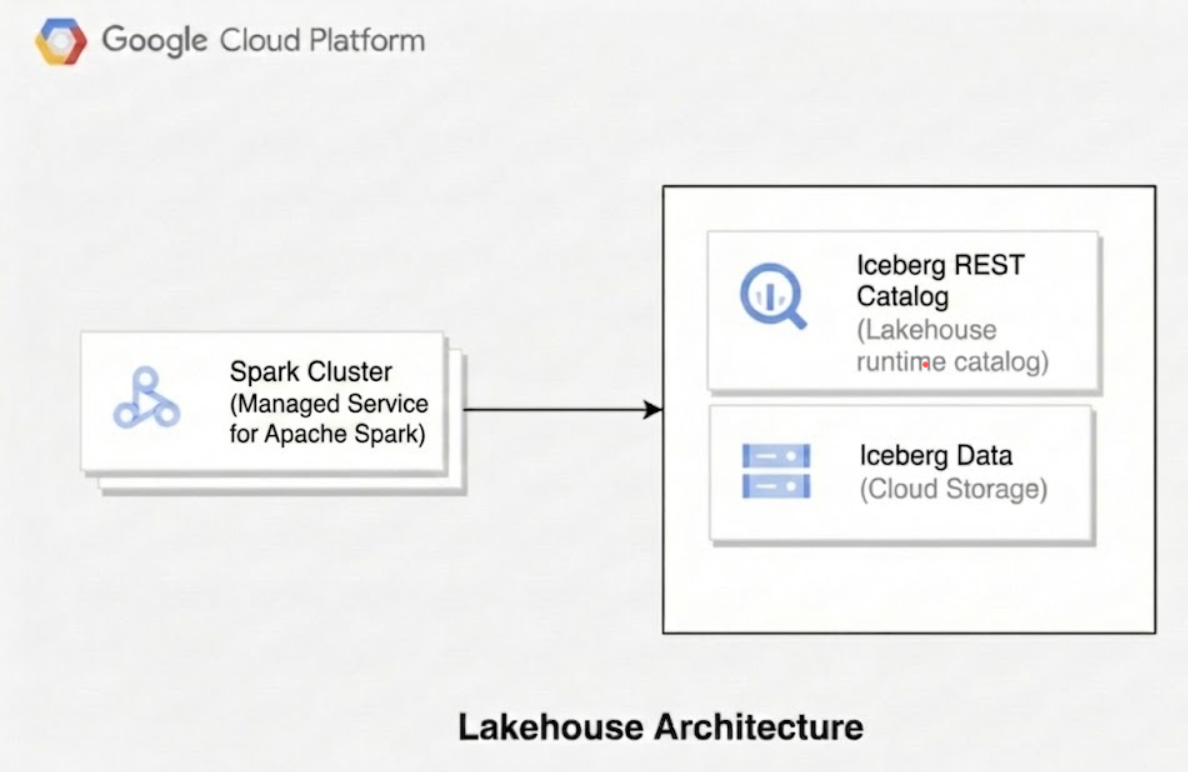
Ao usar o Lakehouse para Apache Iceberg, a arquitetura técnica consiste em três camadas distintas:
Camada de catálogo:
- Conceito principal do Iceberg: o catálogo armazena o estado atual da tabela, mantendo um ponteiro para o arquivo de metadados mais recente. Essa camada facilita a conformidade com ACID e o isolamento da transação para garantir que gravações simultâneas não interfiram umas nas outras.
- Implementação do Lakehouse: o catálogo de ambientes de execução do Lakehouse atua como o serviço de metastore regional de nível superior. Nesse serviço, você cria catálogos individuais para gerenciar sua hierarquia de dados. Os mecanismos de consulta do cliente se conectam a esses catálogos usando tipos de catálogo de endpoint específicos, como o endpoint do catálogo REST do Apache Iceberg. O metastore gerencia confirmações de transações, venda de credenciais para delegação de acesso ao armazenamento e gerenciamento de ponteiros em todos os catálogos.
Camada de metadados:
- Conceito principal do Iceberg: essa camada rastreia a estrutura da tabela,
snapshots e locais de arquivos usando uma hierarquia de três tipos de arquivo:
- Arquivos de metadados: armazenam o esquema da tabela, a especificação de partição, e um registro de ponteiros de snapshot.
- Listas de manifestos: representam um único snapshot da tabela agrupando uma coleção de arquivos de manifesto.
- Arquivos de manifesto: rastreiam dados no nível de arquivo individual, armazenando caminhos de arquivo, informações de partição e estatísticas no nível da coluna, por exemplo, contagens de linhas e valores mínimos e máximos, que são usados para otimização de consultas e remoção de partições.
- Implementação do Lakehouse: em um contêiner de catálogo,
você organiza seus dados em namespaces lógicos (semelhantes a conjuntos de dados)
e tabelas. Para cada tabela, o catálogo de ambientes de execução do Lakehouse gera e gerencia a hierarquia de metadados do Iceberg subjacente, começando com um arquivo
metadata.jsonraiz que aponta para as listas de manifestos e arquivos de manifesto. O catálogo de ambientes de execução do Lakehouse mantém esses arquivos diretamente no local de armazenamento do data warehouse designado.
- Conceito principal do Iceberg: essa camada rastreia a estrutura da tabela,
snapshots e locais de arquivos usando uma hierarquia de três tipos de arquivo:
Camada de dados:
- Conceito principal do Iceberg: esse componente é o armazenamento subjacente em que os registros de dados brutos reais residem, normalmente em formatos de arquivo aberto colunar ou baseado em linhas otimizado, como Parquet, ORC ou Avro.
- Implementação do Lakehouse: ao configurar um
bucket do Cloud Storage (
gs://) como local de armazenamento do data warehouse, os arquivos de dados físicos referenciados pelas tabelas são armazenados com segurança no bucket. O catálogo de ambientes de execução do Lakehouse gerencia o acesso por meio da delegação de acesso ao armazenamento (venda de credenciais), vendendo tokens de acesso de curta duração diretamente para mecanismos de cliente. Isso permite que os mecanismos leiam e gravem arquivos de dados com segurança sem exigir permissões IAM amplas e diretas no bucket subjacente.
Compatibilidade e configuração do mecanismo de consulta
Para analisar e gerenciar dados no catálogo de ambientes de execução do Lakehouse, é possível conectar diferentes mecanismos de consulta de código aberto e corporativos. Dependendo da arquitetura atual e dos requisitos de carga de trabalho, é possível escolher entre vários mecanismos compatíveis e configurar o endpoint de catálogo apropriado.
Mecanismos compatíveis
O catálogo de ambientes de execução do Lakehouse é compatível com vários mecanismos de consulta, incluindo (mas não se limitando a) Apache Spark, Apache Flink, Apache Hive e Trino. A tabela a seguir fornece links para a documentação de cada mecanismo:
| Mecanismo | Documentação |
|---|---|
| Apache Spark | Início rápido: usar com o Spark e o endpoint do catálogo REST do Iceberg |
| Apache Hive | Usar com o Spark e o catálogo do Hive |
| Apache Flink | Usar com o Apache Flink |
| Trino | Usar com o Trino |
Tipos de catálogo e configuração de endpoint
Ao configurar mecanismos de cliente para se conectar ao metastore do catálogo de ambientes de execução do Lakehouse, selecione um endpoint de catálogo específico, como o endpoint do catálogo REST do Apache Iceberg ou o endpoint do Apache Hive. A melhor opção depende do seu caso de uso, conforme mostrado na tabela a seguir:
| Caso de uso | Recomendação |
|---|---|
| Novos usuários do catálogo de ambientes de execução do Lakehouse que querem que o mecanismo de código aberto acesse dados no Cloud Storage e precisam de interoperabilidade com outros mecanismos, incluindo BigQuery e AlloyDB para PostgreSQL. | Use o endpoint do catálogo REST do Apache Iceberg. |
| Usuários que executam cargas de trabalho do Apache Hive ou Spark que dependem da interface do Hive Metastore e querem um serviço de metastore totalmente gerenciado. | Use o endpoint do catálogo do Apache Hive. |
| Usuários atuais do catálogo de ambientes de execução do Lakehouse que têm tabelas criadas com o catálogo personalizado do Apache Iceberg para o endpoint do BigQuery. | Continue usando o catálogo personalizado do Apache Iceberg para o endpoint do BigQuery, mas use o catálogo REST do Apache Iceberg para novos fluxos de trabalho. As tabelas criadas com o catálogo personalizado do Apache Iceberg para o endpoint do BigQuery ficam visíveis com o endpoint do catálogo REST do Apache Iceberg pela federação de catálogos do BigQuery. |
Limitações do catálogo de ambientes de execução do Lakehouse
As seguintes limitações se aplicam a tabelas no catálogo de ambientes de execução do Lakehouse:
Gerenciamento de tabelas
- Não é possível criar ou modificar tabelas com o endpoint do catálogo REST do Apache Iceberg usando instruções de linguagem de definição de dados (DDL) ou linguagem de manipulação de dados (DML) do BigQuery. É possível modificar essas tabelas usando a API BigQuery (com a ferramenta de linha de comando bq ou bibliotecas de cliente), mas isso corre o risco de fazer alterações incompatíveis com o mecanismo externo.
- As tabelas no catálogo de ambientes de execução do Lakehouse não oferecem suporte a
operações de renomeação ou à instrução SQL
ALTER TABLE ... RENAME TOdo Spark. - As tabelas no catálogo de ambientes de execução do Lakehouse não oferecem suporte a clustering.
- As tabelas no catálogo de ambientes de execução do Lakehouse não oferecem suporte a nomes de colunas flexíveis.
- O catálogo de ambientes de execução do Lakehouse não oferece suporte a visualizações do Apache Iceberg.
Consulta
- O desempenho da consulta para tabelas no catálogo de ambientes de execução do Lakehouse do mecanismo do BigQuery pode ser lento em comparação com a consulta de dados em tabelas padrão do BigQuery. Em geral, a velocidade da consulta precisa ser equivalente à leitura de dados do Cloud Storage.
- Uma simulação do BigQuery de uma consulta que usa uma tabela no catálogo de ambientes de execução do Lakehouse pode relatar um limite inferior de 0 bytes de dados, mesmo que as linhas sejam retornadas. Esse resultado ocorre porque a quantidade de dados processados da tabela não pode ser determinada até que a consulta completa seja executada. A execução da consulta gera um custo para o processamento desses dados.
- Não é possível referenciar uma tabela no catálogo de ambientes de execução do Lakehouse em uma consulta de tabela curinga.
API e metadados
- Não é possível usar o
tabledata.listmétodo para recuperar dados de tabelas no catálogo de ambientes de execução do Lakehouse. Em vez disso, é possível salvar os resultados da consulta em uma tabela do BigQuery e usar o métodotabledata.listnessa tabela. - A exibição de estatísticas de armazenamento de tabelas no catálogo de ambientes de execução do Lakehouse não é compatível.
Cotas e limites
- As tabelas no catálogo de ambientes de execução do Lakehouse no BigQuery estão sujeitas às mesmas cotas e limites que as tabelas padrão.
Diferenças com o metastore do BigLake (clássico)
As principais diferenças entre o catálogo de ambientes de execução do Lakehouse e o metastore do BigLake (clássico) incluem o seguinte:
- O catálogo de ambientes de execução do Lakehouse oferece suporte a uma integração direta com mecanismos de código aberto, como o Spark, o que ajuda a reduzir a redundância ao armazenar metadados e executar jobs. As tabelas no catálogo de ambientes de execução do Lakehouse podem ser acessadas diretamente de vários mecanismos de código aberto e do BigQuery.
- O catálogo de ambientes de execução do Lakehouse oferece suporte ao endpoint do catálogo REST do Apache Iceberg, enquanto o metastore do BigLake (clássico) não.
A seguir
- Entenda o endpoint do catálogo REST do Apache Iceberg.