
Kasus penggunaan
Arsitektur referensi ini mendukung skenario berikut:
- Anda memiliki database yang dapat mentoleransi beberapa periode nonaktif dan kehilangan data sejak pencadangan terakhir.
- Anda ingin melindungi database AlloyDB Omni dari kesalahan pengguna, kerusakan, atau kegagalan fisik di tingkat database (bukan snapshot server atau image VM).
- Anda ingin dapat memulihkan database di tempat atau dari jarak jauh, mungkin hingga titik waktu tertentu.
Cara kerja arsitektur referensi
Arsitektur referensi Ketersediaan Standar mencakup pencadangan dan pemulihan database AlloyDB Omni Anda, baik yang berjalan sebagai instance mandiri di server host, sebagai virtual machine (Menginstal AlloyDB Omni), atau di cluster Kubernetes (Menginstal AlloyDB Omni di Kubernetes).
Meskipun Ketersediaan Standar adalah penerapan dasar dan meminimalkan hardware atau layanan tambahan yang diperlukan, Batas Waktu Pemulihan (RTO) meningkat seiring dengan bertambah besarnya database. Makin banyak data yang dicadangkan, makin lama waktu yang dibutuhkan untuk memulihkan dan memulihkan database. Kehilangan data bergantung pada jenis cadangan. Jika hanya file data yang dicadangkan secara berkala, maka saat Anda memulihkan, Anda akan mengalami kehilangan data sejak pencadangan terakhir.
Mengurangi RPO
Fitur pengarsipan berkelanjutan PostgreSQL memungkinkan Anda mencapai Toleransi Jumlah Data yang Hilang (RPO) yang rendah dan mengaktifkan pemulihan point-in-time melalui pencadangan. Proses ini melibatkan pengarsipan file Write-Ahead Logging (WAL) dan streaming data WAL, yang berpotensi ke lokasi penyimpanan jarak jauh.
Jika file WAL diarsipkan hanya saat penuh atau pada interval tertentu, kehilangan database lengkap (termasuk file WAL saat ini) membatasi pemulihan ke file WAL yang terakhir diarsipkan, yang berarti bahwa Toleransi Durasi Kehilangan Data (RPO) harus mempertimbangkan potensi kehilangan data. Sebaliknya, transfer data WAL berkelanjutan memaksimalkan nol kehilangan data.
Saat melakukan pencadangan berkelanjutan, Anda dapat melakukan pemulihan ke titik waktu tertentu. Pemulihan point-in-time memungkinkan pemulihan ke status sebelum terjadi error, seperti penghapusan tabel yang tidak disengaja atau update batch yang salah. Namun, metode pemulihan ini memengaruhi Toleransi Jumlah Data yang Hilang (RPO) kecuali jika database tambahan sementara digunakan.
Strategi pencadangan
Anda dapat mengonfigurasi pencadangan tingkat Postgres AlloyDB Omni agar disimpan di penyimpanan lokal atau jarak jauh. Meskipun penyimpanan lokal mungkin lebih cepat untuk dicadangkan dan dipulihkan, penyimpanan jarak jauh biasanya lebih andal untuk menangani kegagalan saat seluruh host atau VM gagal.
Pencadangan di non-Kubernetes
Untuk deployment non-Kubernetes, Anda dapat menjadwalkan pencadangan menggunakan alat PostgreSQL berikut:
- pgBackRest. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan pgBackRest untuk AlloyDB Omni.
- Barman. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan Barman untuk AlloyDB Omni.
Atau, untuk database kecil, Anda dapat memilih untuk melakukan pencadangan logis database (menggunakan pg_dump untuk satu database atau pg_dumpall untuk seluruh cluster). Anda dapat melakukan pemulihan menggunakan pg_restore.
Pencadangan di Kubernetes menggunakan operator AlloyDB Omni
Untuk AlloyDB Omni yang di-deploy di cluster Kubernetes, Anda dapat mengonfigurasi pencadangan berkelanjutan menggunakan rencana pencadangan untuk setiap cluster database. Untuk mengetahui informasi selengkapnya, lihat Mencadangkan dan memulihkan di Kubernetes.
Anda dapat menyimpan cadangan AlloyDB Omni secara lokal atau dari jarak jauh di Cloud Storage, termasuk opsi yang disediakan oleh vendor cloud mana pun. Untuk mengetahui informasi selengkapnya, lihat Gambar 1, yang menunjukkan potensi tujuan pencadangan.
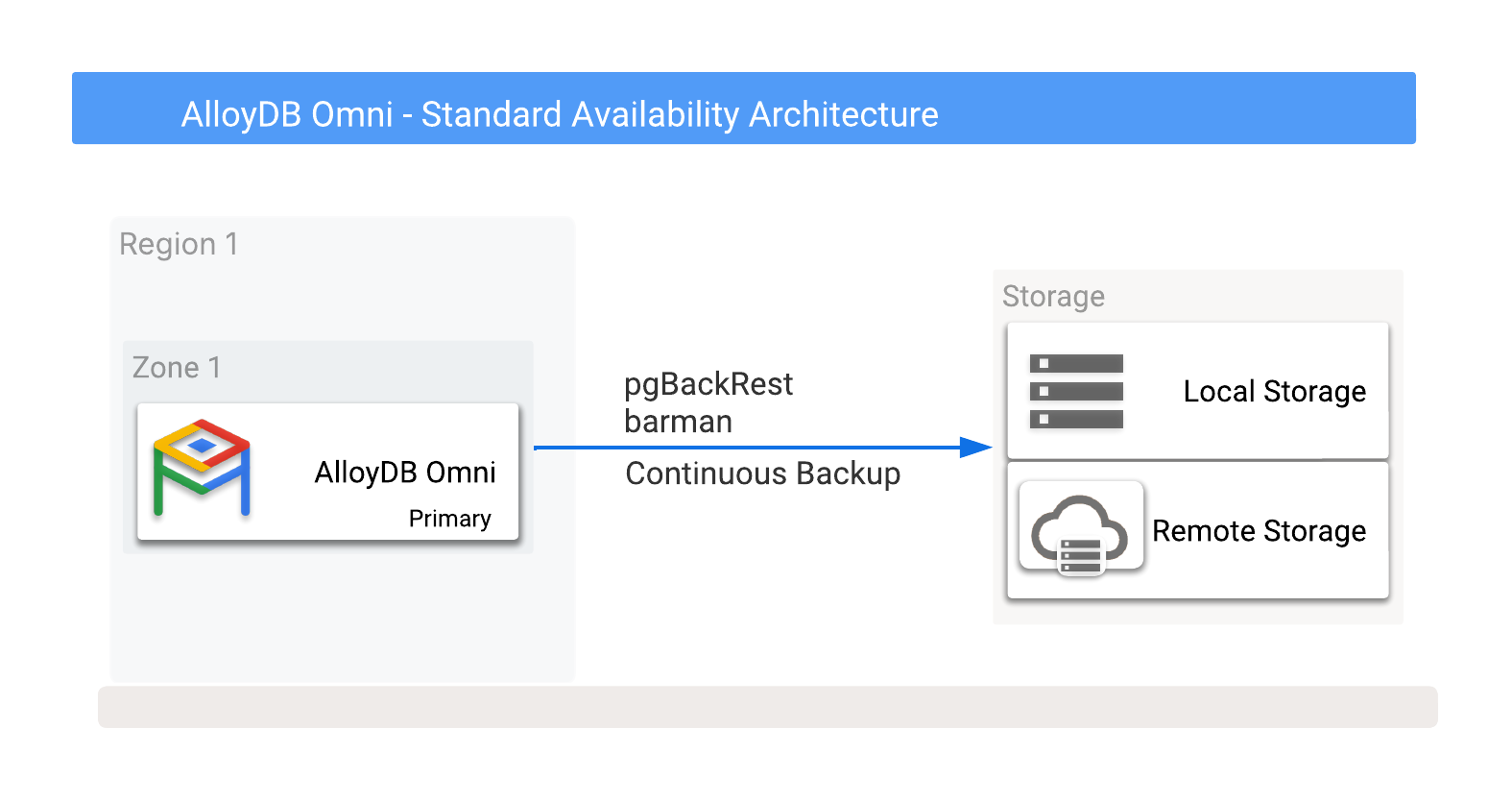
Gambar 1. AlloyDB Omni dengan opsi pencadangan.
Cadangan dapat disimpan ke opsi penyimpanan lokal atau jarak jauh. Pencadangan lokal cenderung lebih cepat karena hanya mengandalkan throughput I/O, sedangkan pencadangan jarak jauh biasanya memiliki latensi yang lebih tinggi dan bandwidth jaringan yang lebih rendah. Namun, cadangan jarak jauh memberikan perlindungan yang optimal, termasuk kegagalan zona.
Anda juga dapat memisahkan cadangan lokal ke penyimpanan lokal atau bersama. Meskipun opsi penyimpanan lokal terpengaruh oleh kurangnya opsi pemulihan bencana saat host database gagal, penyimpanan bersama memungkinkan penyimpanan tersebut dipindahkan ke server lain dan kemudian digunakan untuk pemulihan. Artinya, penyimpanan bersama berpotensi menawarkan RTO yang lebih cepat.
Untuk deployment penyimpanan lokal dan bersama, jenis pencadangan berikut dapat dijadwalkan atau dilakukan secara manual sesuai permintaan:
- Pencadangan penuh: pencadangan lengkap semua file database yang diperlukan untuk pemulihan data.
- Cadangan diferensial: cadangan hanya perubahan file sejak cadangan penuh terakhir.
- Pencadangan inkremental: pencadangan hanya perubahan file sejak pencadangan terakhir dalam bentuk apa pun.
Pemulihan point-in-time
Pencadangan berkelanjutan file Write-Ahead Logging (WAL) PostgreSQL mendukung pemulihan point-in-time. Jika, setelah peristiwa kegagalan, file WAL tetap utuh dan dapat digunakan, Anda dapat menggunakan file ini untuk melakukan pemulihan tanpa kehilangan data.
Untuk mengontrol penulisan file WAL, Anda dapat mengonfigurasi parameter berikut:
| Parameter | Deskripsi |
|---|---|
|
Menentukan seberapa sering penulis WAL membersihkan WAL ke disk, kecuali jika penulisan diaktifkan lebih awal oleh transaksi yang di-commit secara asinkron. Nilai defaultnya adalah 200 md. Meningkatkan nilai ini akan mengurangi frekuensi penulisan, tetapi dapat meningkatkan jumlah data yang hilang jika server mengalami error. |
|
Menentukan seberapa banyak data WAL dapat terakumulasi sebelum penulis WAL memaksa flush ke disk. Nilai defaultnya adalah 1 MB. Jika disetel ke nol, data WAL akan selalu di-flush ke disk secara langsung. |
|
Menentukan apakah commit menampilkan respons kepada pengguna sebelum
data WAL di-flush ke disk. Setelan defaultnya adalah
on, yang memastikan bahwa transaksi bersifat tahan lama. Dengan
kata lain, commit telah ditulis ke disk sebelum menampilkan kode
berhasil kepada pengguna. Jika ditetapkan ke off, maka ada
hingga tiga kali wal_writer_delay sebelum
transaksi ditulis ke disk. |
Pemantauan penggunaan WAL
Anda dapat menggunakan metode berikut untuk mengamati penggunaan WAL:
| Metode pengamatan | Deskripsi |
|---|---|
|
Tampilan standar ini memiliki kolom wal_write
dan wal_sync, yang menyimpan
jumlah penulisan WAL dan sinkronisasi WAL. Jika parameter konfigurasi track_wal_io_timing diaktifkan, wal_write_time dan wal_sync_time juga akan disimpan. Snapshot reguler dari tampilan ini dapat membantu menampilkan aktivitas penulisan dan sinkronisasi WAL dari waktu ke waktu. |
pg_current_wal_lsn() |
Fungsi ini menampilkan posisi nomor urut log (lsn) saat ini
yang, jika dikaitkan dengan stempel waktu dan dikumpulkan sebagai snapshot
dari waktu ke waktu, dapat memberikan byte/detik WAL yang dihasilkan menggunakan
fungsi pg_wal_lsn_diff(lsn1, lsn2).
Fungsi ini adalah metrik yang berguna untuk memahami rasio transaksi dan performa file WAL. |
Streaming data WAL ke lokasi jarak jauh
Saat Anda menggunakan Barman, data WAL juga dapat disiapkan untuk melakukan streaming secara real-time ke lokasi jarak jauh untuk memastikan hanya ada sedikit atau tidak ada kehilangan data saat pemulihan. Meskipun streaming dilakukan secara real time, ada sedikit kemungkinan kehilangan transaksi yang di-commit karena penulisan streaming ke server barman jarak jauh bersifat asinkron secara default. Namun, Anda dapat menyiapkan streaming WAL menggunakan mode sinkron yang menyimpan WAL dan mengirim respons status kembali ke database sumber. Perlu diingat bahwa pendekatan ini dapat memperlambat transaksi jika harus menunggu penulisan ini selesai sebelum melanjutkan.
Jadwal pencadangan
Di sebagian besar lingkungan, pencadangan biasanya dijadwalkan setiap minggu. Berikut adalah jadwal pencadangan mingguan yang umum:
- Minggu: pencadangan penuh
- Senin, Selasa: pencadangan
- Rabu: pencadangan diferensial
- Kamis, Jumat: pencadangan inkremental
- Sabtu: pencadangan diferensial
Dengan jadwal umum ini, jendela pemulihan bergulir selama satu minggu memerlukan ruang penyimpanan hingga tiga cadangan penuh ditambah cadangan inkremental atau diferensial yang diperlukan. Pendekatan ini mendukung pemulihan untuk kegagalan yang terjadi selama pencadangan penuh pada hari Minggu, dan pemulihan database diperlukan untuk diperpanjang hingga hari Minggu sebelumnya sebelum pencadangan dimulai.
Untuk meminimalkan RTO dengan potensi RPO yang lebih tinggi, database tambahan dapat beroperasi dalam mode pemulihan berkelanjutan. Proses ini melibatkan pemutaran ulang cadangan dan pembaruan berkelanjutan lingkungan sekunder dengan mengarsipkan dan memutar ulang file WAL baru. RPO sebenarnya, yang mencerminkan potensi kehilangan data, bergantung pada frekuensi transaksi, ukuran file WAL, dan penggunaan streaming WAL.
Memulihkan di non-Kubernetes
Untuk deployment non-Kubernetes, memulihkan database AlloyDB Omni melibatkan penghentian penampung Docker, lalu memulihkan data, atau memulihkan data ke lokasi lain dan meluncurkan instance Docker baru menggunakan data yang dipulihkan tersebut. Setelah penampung dimulai ulang, database dapat diakses dengan data yang dipulihkan.
Untuk mengetahui informasi selengkapnya tentang opsi pemulihan, lihat Memulihkan cluster AlloyDB Omni menggunakan pgBackRest dan Memulihkan cluster AlloyDB Omni menggunakan Barman.
Memulihkan di Kubernetes menggunakan Operator
Untuk memulihkan database di Kubernetes, operator menawarkan pemulihan ke cluster dan namespace Kubernetes yang sama, dari cadangan bernama atau clone dari Point In Time (PIT). Untuk meng-clone database ke cluster Kubernetes yang berbeda, gunakan pgBackRest. Untuk mengetahui informasi selengkapnya, lihat Mencadangkan dan memulihkan di Kubernetes dan Ringkasan meng-clone cluster database dari cadangan Kubernetes.
Penerapan
Saat memilih arsitektur referensi ketersediaan, perhatikan manfaat, batasan, dan alternatif berikut.
Manfaat
- Mudah digunakan dan dikelola, serta cocok untuk database non-kritis dengan RTO/RPO yang fleksibel.
- Hardware tambahan minimal yang diperlukan
- Pencadangan selalu diperlukan untuk rencana pemulihan dari bencana yang lengkap
- Pemulihan ke titik waktu mana pun dalam periode pemulihan dapat dilakukan
Batasan
- Persyaratan penyimpanan yang mungkin lebih besar daripada database itu sendiri, bergantung pada persyaratan retensi.
- Pemulihan bisa lambat dan dapat menghasilkan RTO yang lebih tinggi.
- Dapat mengakibatkan hilangnya beberapa data, bergantung pada ketersediaan data WAL saat ini setelah kegagalan database, yang dapat memengaruhi RPO secara negatif.
Alternatif
- Pertimbangkan Arsitektur Ketersediaan Tingkat Lanjut atau Premium untuk opsi ketersediaan dan pemulihan dari bencana yang lebih baik.
Langkah berikutnya
- Ringkasan arsitektur referensi ketersediaan AlloyDB Omni.
- Ketersediaan yang Ditingkatkan untuk AlloyDB Omni.
- Ketersediaan Premium AlloyDB Omni.
- Instal AlloyDB Omni di Kubernetes.
- Menyiapkan pgBackRest untuk AlloyDB Omni.
- Menyiapkan Barman untuk AlloyDB Omni.
- Mencadangkan dan memulihkan di Kubernetes.
- Memulihkan cluster AlloyDB Omni menggunakan pgBackRest.
- Memulihkan cluster AlloyDB Omni menggunakan Barman.
- Mencadangkan dan memulihkan di Kubernetes.
- Meng-clone cluster database dari ringkasan pencadangan Kubernetes.