
La portabilità di AlloyDB Omni ti consente di eseguirlo in molti ambienti, tra cui:
- Data center
- Laptop
- Istanze VM basate su cloud
Casi d'uso di AlloyDB Omni
AlloyDB Omni è adatto ai seguenti scenari:
- Hai bisogno di una versione scalabile e performante di PostgreSQL, ma non puoi eseguire un database nel cloud a causa di requisiti normativi o di sovranità dei dati.
- Hai bisogno di un database che continui a funzionare anche quando è disconnesso da internet.
- Per ridurre al minimo la latenza, devi posizionare il database il più vicino possibile ai tuoi utenti dal punto di vista geografico.
- Vuoi un modo per eseguire la migrazione da un database legacy, ma senza eseguire una migrazione completa al cloud.
AlloyDB Omni non include le funzionalità di AlloyDB che si basano sul funzionamento in Google Cloud. Se vuoi eseguire l'upgrade del tuo progetto alle funzionalità di scalabilità, sicurezza e disponibilità completamente gestite di AlloyDB, puoi eseguire la migrazione dei dati di AlloyDB Omni in un cluster AlloyDB proprio come faresti con qualsiasi altra importazione iniziale di dati.
Funzionalità principali
- Un server di database compatibile con PostgreSQL.
- Supporto per AlloyDB AI, che ti aiuta a creare applicazioni di AI generativa di livello aziendale utilizzando i tuoi dati operativi.
- Integrazioni con l'ecosistema Google Cloud AI, tra cui Vertex AI Model Garden e strumenti di AI generativa open source.
Supporto delle funzionalità Autopilot di AlloyDB in Google Cloud che consente ad AlloyDB Omni di autogestirsi e autoregolarsi.
Ad esempio, AlloyDB Omni supporta la gestione automatica della memoria e l'autovacuum adattivo dei dati obsoleti.
Uno strumento di suggerimenti sull'indicizzazione che analizza le query eseguite di frequente e consiglia nuovi indici per migliorare le prestazioni delle query.
Il motore colonnare di AlloyDB Omni, che conserva spesso i dati soggetti più spesso a query in un formato colonnare in memoria per prestazioni più veloci su carichi di lavoro per business intelligence, generazione di report ed elaborazione transazionale ibrida e analitica (HTAP).
Nei nostri test delle prestazioni, i carichi di lavoro transazionali in AlloyDB Omni sono oltre due volte più veloci e le query analitiche sono fino a 100 volte più veloci rispetto a PostgreSQL standard.
Come funziona AlloyDB Omni
Puoi installare AlloyDB Omni come server autonomo o come parte di un ambiente Kubernetes.
AlloyDB Omni viene eseguito in un container Docker che installi nel tuo ambiente. Ti consigliamo di eseguire AlloyDB Omni su un sistema Linux con spazio di archiviazione SSD e almeno 8 GB di memoria per CPU.
L'operatore AlloyDB Omni Kubernetes è un'estensione dell'API Kubernetes che ti consente di eseguire AlloyDB Omni nella maggior parte degli ambienti Kubernetes conformi a CNCF. Per ulteriori informazioni, consulta Installare AlloyDB Omni su Kubernetes.
Le tue applicazioni si connettono e comunicano con la tua installazione di AlloyDB Omni, proprio come le applicazioni si connettono e comunicano con un server di database PostgreSQL standard. Anche il controllo dell'accesso degli utenti si basa sugli standard PostgreSQL.
Dalla registrazione alla pulizia all'engine colonnare, puoi configurare il comportamento del database di AlloyDB Omni utilizzando i flag di database.
Vantaggi dell'esecuzione di AlloyDB Omni come container
Google distribuisce AlloyDB Omni come container che puoi eseguire con runtime del container come Docker e Podman. A livello operativo, i container presentano i seguenti vantaggi:
- Gestione trasparente delle dipendenze: tutte le dipendenze necessarie sono raggruppate nel container e testate da Google per garantire la piena compatibilità con AlloyDB Omni.
- Portabilità: puoi aspettarti che AlloyDB Omni funzioni in modo coerente in tutti gli ambienti.
- Isolamento della sicurezza: scegli a cosa ha accesso il container AlloyDB Omni sulla macchina host.
- Gestione delle risorse: puoi definire la quantità di risorse di calcolo che vuoi che il container AlloyDB Omni utilizzi.
- Applicazione di patch e upgrade senza interruzioni: per applicare una patch a un container, devi solo sostituire l'immagine esistente con una nuova.
Backup dati e disaster recovery
AlloyDB Omni è dotato di un sistema di backup e recupero continui che ti consente di creare un nuovo cluster di database in base a qualsiasi momento all'interno di un periodo di conservazione regolabile. In questo modo puoi ripristinare rapidamente i dati in caso di perdita accidentale.
Inoltre, AlloyDB Omni può creare e archiviare backup completi dei dati del cluster di database, on demand o in base a una pianificazione regolare. In qualsiasi momento, puoi eseguire il ripristino da un backup a un cluster di database AlloyDB Omni che contiene tutti i dati del cluster di database originale al momento della creazione del backup.
Per saperne di più, consulta Esegui il backup e il ripristino di AlloyDB Omni.
Come ulteriore metodo di disaster recovery, puoi ottenere la replica tra data center creando cluster di database secondari in data center separati. AlloyDB Omni trasmette in streaming in modo asincrono i dati da un cluster di database primario designato a ciascuno dei suoi cluster secondari. Se necessario, puoi promuovere un cluster di database secondario a cluster di database AlloyDB Omni primario.
Per saperne di più, consulta Informazioni sulla replica tra data center.
Componenti della VM AlloyDB Omni
AlloyDB Omni su VM è costituito da due set di componenti dell'architettura: componenti PostgreSQL con miglioramenti di AlloyDB per PostgreSQL e componenti di AlloyDB per PostgreSQL. Il seguente diagramma illustra entrambi i set di componenti, il livello di infrastruttura in cui si trovano su una VM o un server e le funzionalità correlate che puoi aspettarti per ogni componente.
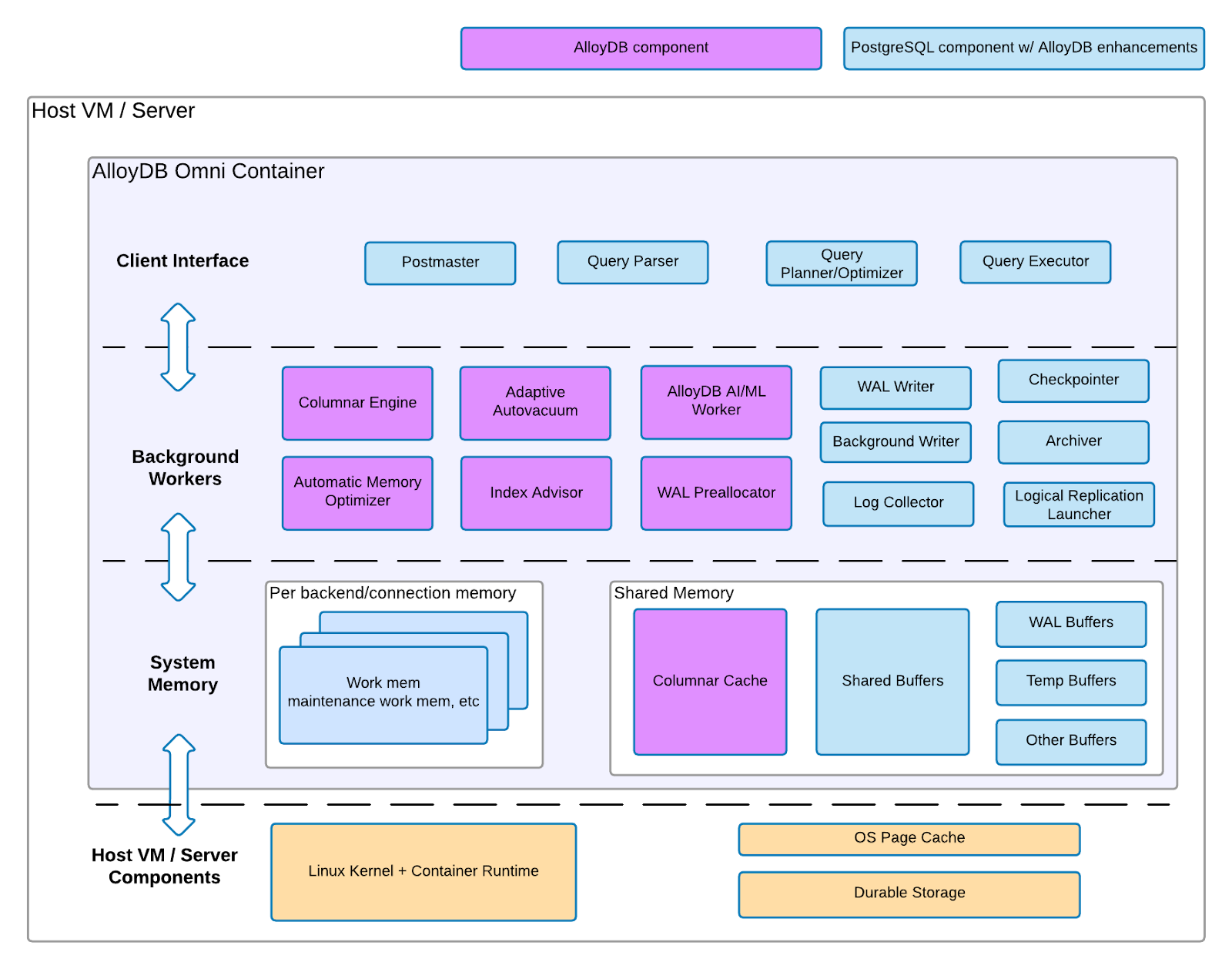
Figura 1. Architettura di AlloyDB Omni
Motore del database
Questo documento descrive l'architettura del database in AlloyDB Omni in un container. Questo documento presuppone che tu abbia familiarità con PostgreSQL.
Un motore di database esegue le seguenti attività:
- Traduce una query di un client in un piano eseguibile
- Trova i dati necessari per soddisfare la query
- Esegue qualsiasi filtro, ordinamento e aggregazione necessari
- Restituisce i risultati al client
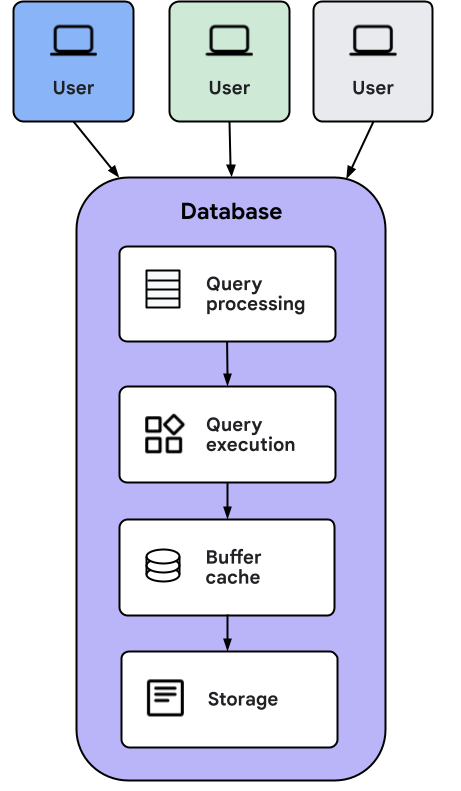
Quando l'applicazione client invia una query ad AlloyDB Omni, si verificano le seguenti azioni:
- Il livello di elaborazione delle query trasforma la query in un piano di esecuzione che viene inviato al livello di esecuzione delle query.
- Il livello di esecuzione delle query esegue le operazioni necessarie per calcolare la risposta alla query.
- Durante l'esecuzione, i dati potrebbero essere caricati dalla cache del buffer o direttamente dallo spazio di archiviazione. Se i dati vengono caricati dallo spazio di archiviazione, i dati vengono memorizzati nella cache per utilizzi futuri.
Le risorse utilizzate durante l'elaborazione della query del client includono CPU, memoria, I/O, rete e primitive di sincronizzazione come i blocchi del database. L'ottimizzazione delle prestazioni mira a ottimizzare l'utilizzo delle risorse durante ogni fase dell'esecuzione della query.
L'obiettivo di un motore del database efficiente è rispondere a una query utilizzando il minor numero di risorse necessarie. Questo obiettivo inizia con un buon modello di dati e una progettazione delle query.
- Come si può rispondere alle query esaminando la quantità minima di dati?
- Quali indici sono necessari per ridurre lo spazio di ricerca e l'I/O?
- L'ordinamento dei dati richiede CPU e, spesso, accesso al disco per set di dati di grandi dimensioni, quindi come si può evitare l'ordinamento dei dati?
Archiviazione dei dati
AlloyDB Omni archivia i dati in pagine di dimensioni fisse archiviate nel file system sottostante. Quando una query deve accedere ai dati, AlloyDB Omni controlla innanzitutto il buffer pool. Se le pagine che contengono i dati richiesti non vengono trovate nel buffer pool, AlloyDB Omni legge le pagine richieste dal file system. L'accesso ai dati dal buffer pool è notevolmente più veloce della lettura dal file system, pertanto massimizzare le dimensioni del buffer pool per la quantità di dati a cui accederà un'applicazione è un fattore importante.
Gestione delle risorse
AlloyDB Omni utilizza la gestione dinamica della memoria per consentire al buffer pool di aumentare e diminuire dinamicamente entro i limiti configurati a seconda delle esigenze di memoria del sistema. Pertanto, non è necessario ottimizzare le dimensioni del buffer pool. Quando diagnostichi problemi di prestazioni, le prime metriche da considerare sono il tasso di hit del buffer pool e il tasso di lettura per verificare se la tua applicazione sta ottenendo il vantaggio del buffer pool. In caso contrario, significa che il set di dati dell'applicazione non rientra nel buffer pool e potresti prendere in considerazione la possibilità di ridimensionarlo su una macchina più grande con più memoria.
Il processo di recupero, filtraggio, aggregazione, ordinamento e proiezione dei dati richiede risorse CPU sul server di database. Per ridurre la quantità di risorse CPU necessarie per questo processo, riduci al minimo la quantità di dati da manipolare. Monitora l'utilizzo della CPU sul server di database per assicurarti che l'utilizzo allo stato stazionario sia intorno al 70%. Questo importo lascia un margine sufficiente sul server per picchi di utilizzo o modifiche ai pattern di accesso nel tempo. L'esecuzione a un utilizzo più vicino al 100% introduce un sovraccarico dovuto alla pianificazione dei processi e al cambio di contesto e potrebbe creare colli di bottiglia in altre parti del sistema. L'utilizzo elevato della CPU è un'altra metrica chiave da utilizzare quando si prendono decisioni sulle specifiche della macchina.
Le operazioni di input/output al secondo (IOPS) sono un fattore importante per le prestazioni delle applicazioni di database: quante operazioni di input o output al secondo può fornire il dispositivo di archiviazione sottostante al database. Per evitare di raggiungere i limiti di IOPS dell'archiviazione del database, riduci al minimo le letture e le scritture nell'archiviazione massimizzando la quantità di dati che possono essere contenuti nel buffer pool.
Motore colonnare
Il motore colonnare accelera l'elaborazione delle query SQL di scansioni, join e aggregazioni fornendo i seguenti componenti:
Archivio colonne in memoria: contiene i dati di tabelle e viste materializzate per le colonne selezionate in un formato orientato alle colonne. Per impostazione predefinita, lo store di colonne utilizza 1 GB di memoria disponibile. Per modificare la quantità di memoria utilizzabile dallo spazio di archiviazione a colonne, imposta il parametro
google_columnar_engine.memory_size_in_mbnel filepostgresql.confutilizzato dall'istanza AlloyDB Omni.Per ulteriori informazioni su come modificare il parametro, consulta Modificare i parametri di configurazione.
Pianificatore di query ed execution engine colonnari: supporta l'utilizzo dello store di colonne nelle query.
Gestione automatica della memoria
Il gestore automatico della memoria monitora e ottimizza continuamente il consumo di memoria
in un'intera istanza AlloyDB Omni. Quando esegui
i tuoi carichi di lavoro, questo modulo regola le dimensioni della cache del buffer condiviso in base alla pressione
della memoria. Per impostazione predefinita, il gestore automatico della memoria imposta il limite superiore all'80%
della memoria di sistema e alloca il 10% della memoria di sistema per la cache del buffer condiviso.
Per modificare il limite superiore per le dimensioni della cache del buffer condiviso, imposta il parametro shared_buffers nel file postgresql.conf utilizzato dall'istanza AlloyDB Omni.
Per saperne di più, consulta Gestione automatica della memoria.
Aspirazione automatica adattiva
L'autovacuum adattivo analizza le operazioni in base al carico di lavoro del database e regola automaticamente la frequenza di pulizia. Questo aggiustamento automatico aiuta il database a funzionare al massimo delle prestazioni, anche quando il carico di lavoro cambia, senza interferenze del processo di vacuum.
L'autovacuum adattivo utilizza i seguenti fattori per determinare la frequenza e l'intensità delle operazioni di vacuuming:
- Dimensioni del database
- Numero di tuple non attive nel database
- Età dei dati nel database
- Numero di transazioni al secondo rispetto alla velocità di vacuum stimata
L'autovacuum adattivo offre i seguenti vantaggi:
- Gestione dinamica delle risorse di vacuum: anziché utilizzare un limite di costo fisso,
AlloyDB Omni utilizza statistiche sulle risorse in tempo reale per regolare i
worker di vacuum. Quando il sistema è occupato, il processo di pulizia e l'utilizzo delle risorse associate vengono limitati. Se è disponibile memoria sufficiente,
viene allocata memoria aggiuntiva per
maintenance_work_memper ridurre il tempo di aspirazione end-to-end. - Limitazione dinamica dell'XID: monitora automaticamente e continuamente
l'avanzamento dell'aspirazione e la velocità di consumo dell'ID transazione. Se viene rilevato un rischio
di wraparound dell'ID transazione, AlloyDB Omni
rallenta le transazioni per limitare il consumo di ID. Inoltre,
AlloyDB Omni alloca più risorse ai worker di vacuum
per elaborare le tabelle che bloccano l'avanzamento e il rilascio dello spazio
ID transazione. Durante questo processo, le transazioni complessive al secondo vengono
ridotte finché gli ID transazione non si trovano in una zona sicura (osservabile come
sessioni in attesa di
AdaptiveVacuumNewXidDelay). Quando l'età dell'ID transazione aumenta, il numero di worker di pulizia viene aumentato in modo dinamico. - Pulizia efficiente per tabelle più grandi: la logica PostgreSQL predefinita
utilizzata per decidere quando eseguire la pulizia di una tabella si basa su statistiche specifiche della tabella
memorizzate in
pg_stat_all_tables, che contiene il rapporto tra le tuple non valide. Questa logica funziona per le tabelle di piccole dimensioni, ma potrebbe non funzionare in modo efficiente per le tabelle più grandi e aggiornate di frequente. AlloyDB Omni fornisce un meccanismo di scansione aggiornato che contribuisce ad attivare autovacuum più spesso. Questo meccanismo di scansione scansiona blocchi di tabelle di grandi dimensioni e rimuove le tuple non valide in modo più efficiente rispetto alla logica PostgreSQL predefinita. - Messaggi di avviso del log: in AlloyDB Omni, i blocchi di vacuum, come le transazioni a esecuzione prolungata o le transazioni preparate o gli slot di replica che hanno perso le destinazioni, vengono rilevati e gli avvisi vengono registrati nei log di PostgreSQL in modo da poter risolvere i problemi in modo tempestivo.
Worker AI/ML
In AlloyDB Omni, il worker in background AI/ML fornisce tutte le funzionalità necessarie per chiamare i modelli Vertex AI direttamente dal database. Il worker AI/ML viene eseguito come processo denominato omni ml worker.
Per saperne di più, consulta Crea applicazioni di AI generativa utilizzando AlloyDB AI.