
Casos de uso
Essa arquitetura de referência de disponibilidade é adequada para os seguintes casos de uso:
- Aplicativos essenciais para os negócios que exigem RTO e RPO mais baixos.
- Você quer implantar uma réplica em outra zona ou nó que ofereça alta disponibilidade para seus bancos de dados e proteja contra falhas de instância, servidor e zona.
- Você quer proteção contra erros do usuário e corrupção de dados (usando backups).
Como funciona a arquitetura de referência
A disponibilidade avançada é adicionada à disponibilidade padrão, incluindo instâncias de réplica de leitura na região para ativar a alta disponibilidade (HA) que reduz o objetivo de tempo de recuperação (RTO). Essa abordagem também reduz o objetivo de ponto de recuperação (RPO) , permitindo a transmissão de mudanças transacionais para a réplica.
A alta disponibilidade no AlloyDB Omni usa pelo menos duas instâncias de banco de dados. Uma instância funciona como o banco de dados principal, oferecendo suporte a operações de leitura e gravação. As instâncias restantes servem como réplicas de leitura, operando no modo somente leitura.
Confira a seguir alguns conceitos importantes de alta disponibilidade:
- Failover é o procedimento durante uma interrupção não planejada em que a instância principal falha ou fica indisponível, e a réplica de espera é ativada para assumir o modo principal (leitura/gravação). Esse processo é chamado de promoção. Normalmente, nesses cenários, quando o servidor ou banco de dados principal volta a ficar on-line, o banco de dados precisa ser recriado e, em seguida, precisa atuar como um banco de dados de espera. Para oferecer alta disponibilidade, há mecanismos para tornar os failovers automáticos.
- Uma alternância, também conhecida como reversão de papel, é um procedimento usado para alternar os modos entre o banco de dados principal e um dos bancos de dados de espera, de modo que o principal se torne o de espera e o de espera se torne o principal. As alternâncias normalmente acontecem de maneira controlada e elegante, e podem ser iniciadas por vários motivos, por exemplo, para permitir o tempo de inatividade e a aplicação de patches no banco de dados principal anterior. As alternâncias elegantes precisam permitir uma troca futura sem a necessidade de reinstanciar o novo banco de dados de espera ou outros aspectos da configuração de replicação.
Opções de alta disponibilidade
Em implantações não Kubernetes, use o Patroni e o HAProxy. Para mais informações, consulte Arquitetura de alta disponibilidade do AlloyDB Omni para PostgreSQL.
| Observação: o Patroni e o HAProxy são ferramentas de terceiros não comerciais e são compatíveis com o AlloyDB Omni. |
|---|
Recomendamos que você tenha pelo menos dois bancos de dados de espera para que a perda de um banco de dados não afete a alta disponibilidade do cluster. Nesse modo, você tem pelo menos um par de alta disponibilidade em caso de failover ou durante qualquer manutenção planejada de um nó.
Para planejar o tamanho e o formato da implantação do AlloyDB Omni, consulte Planejar a instalação do AlloyDB Omni em uma VM.
Balanceadores de carga
Outro mecanismo importante que ajuda a suavizar os procedimentos de alternância e failover é a presença de um balanceador de carga.
Para implantações não Kubernetes, o software HAProxy oferece balanceamento de carga. O HAProxy oferece balanceamento de carga distribuindo o tráfego de rede entre vários servidores. O HAProxy também mantém o estado de integridade dos servidores de back-end a que se conecta, realizando verificações de integridade. Se um servidor falhar em uma verificação de integridade, o HAProxy vai parar de enviar tráfego para ele até que ele passe nas verificações de integridade novamente.
Alta disponibilidade
Os bancos de dados de réplica de leitura implantados em uma região oferecem alta disponibilidade se o banco de dados principal falhar. Quando ocorre uma falha no banco de dados principal, o banco de dados de espera é promovido para substituir o principal, e o aplicativo continua com pouca ou nenhuma interrupção.
Geralmente, é recomendável realizar verificações anuais ou semestrais regulares na forma de alternâncias para garantir que todos os aplicativos que dependem desses bancos de dados ainda possam se conectar e responder em um período adequado.
A proteção no nível da zona pode ser alcançada usando qualquer tipo de implantação, colocando uma das réplicas de leitura de espera em uma zona de disponibilidade diferente do banco de dados principal.
Um benefício adicional de ter réplicas de leitura é a capacidade de descarregar operações somente leitura para os bancos de dados de espera, que podem atuar como bancos de dados de relatórios usando dados atualizados. Essa abordagem reduz a carga e a sobrecarga no principal de leitura/gravação.
Configuração de backups e alta disponibilidade
As réplicas de leitura podem ser configuradas em várias zonas que oferecem alta disponibilidade. Embora ofereçam RTO e RPO baixos, elas não protegem contra determinadas interrupções, como corrupção de dados lógicos, como exclusões acidentais de tabelas ou atualizações de dados incorretas. Portanto, backups regulares precisam ser feitos além da configuração de alta disponibilidade. Consulte a documentação da arquitetura de disponibilidade padrão para mais detalhes.
A Figura 1 mostra uma configuração de alta disponibilidade recomendada com dois bancos de dados de espera de réplica de leitura em duas zonas de disponibilidade diferentes.
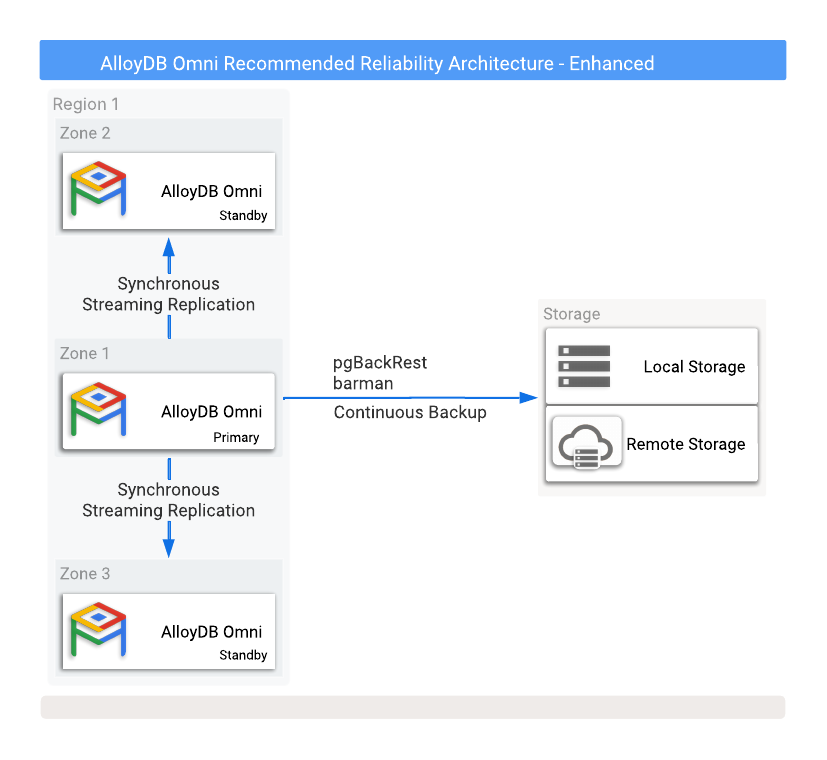
Figura 1. AlloyDB Omni com opções de backups e alta disponibilidade.
Para proteger contra perda de dados se a instância principal falhar, é necessário configurar a replicação no modo síncrono. Embora esse método ofereça proteção de dados forte, ele pode afetar o desempenho do banco de dados principal, porque todos os commits precisam ser gravados no principal e em todos os bancos de dados de espera sincronizados. Uma conexão de rede de baixa latência entre essas instâncias de banco de dados é essencial para essa configuração.
Implantações de alta disponibilidade não Kubernetes
A implantação independente não Kubernetes é uma configuração manual que exige ferramentas de terceiros, o que é mais complexo de configurar e manter do que a implantação do Kubernetes.
Ao usar uma implantação não Kubernetes, há alguns parâmetros que afetam como um failover é detectado e com que rapidez ele ocorre depois que o principal fica indisponível. Confira a seguir um breve resumo desses parâmetros:
Ttl: o tempo máximo necessário para adquirir um bloqueio para o banco de dados principal antes de iniciar um failover. O padrão é 30 segundos.Loop_wait: o tempo de espera antes de verificar novamente. O padrão é 10 segundos.Retry_timeout: o tempo limite antes de rebaixar a instância principal devido a falha de rede. O padrão é 10 segundos.
Para mais informações, consulte Arquitetura de alta disponibilidade do AlloyDB Omni para PostgreSQL.
Implementação
Ao escolher uma arquitetura de referência de disponibilidade, considere as vantagens, as limitações e as alternativas a seguir.
Benefícios
- Proteção contra falhas de instância.
- Proteção contra falhas de servidor.
- Proteção contra falhas de zona.
- O RTO foi reduzido drasticamente em relação à disponibilidade padrão.
Limitações
- Nenhuma proteção extra para desastres regionais.
- Possível impacto no desempenho do principal devido à replicação síncrona.
- A configuração da transmissão do WAL do PostgreSQL no modo síncrono não causa perda de dados (
RPO=0) durante a operação normal ou failovers típicos. No entanto, essa abordagem não protege contra perda de dados em situações específicas de falha dupla, como quando todas as instâncias de espera são perdidas ou ficam inacessíveis da primária, e isso é imediatamente seguido por uma reinicialização da primária.
Alternativas
- A Arquitetura de Disponibilidade Padrão para opções de backup e recuperação.
- A Arquitetura de Disponibilidade Premium para recuperação de desastres no nível da região , réplicas de leitura adicionais e alcance de recuperação de desastres expandido.
A seguir
- Visão geral da arquitetura de referência de disponibilidade do AlloyDB Omni.
- Disponibilidade Padrão do AlloyDB Omni.
- Disponibilidade Premium do AlloyDB Omni.
- Planejar a instalação do AlloyDB Omni em uma VM.
- Arquitetura de alta disponibilidade do AlloyDB Omni para PostgreSQL.