
Garantire l'affidabilità e la qualità della configurazione Patroni ad alta disponibilità è fondamentale per mantenere le operazioni continue del database AlloyDB Omni e ridurre al minimo i tempi di inattività. Questa pagina fornisce una guida completa per testare il cluster Patroni, che copre vari scenari di errore, la coerenza della replica e i meccanismi di failover.
Testare la configurazione Patroni
Connettiti a una delle istanze Patroni (
alloydb-patroni1,alloydb-patroni2oalloydb-patroni3) e vai alla cartella Patroni di AlloyDB Omni.cd /alloydb/
Esamina i log di Patroni.
docker compose logs alloydbomni-patroni
Le ultime voci devono riflettere le informazioni sul nodo Patroni. Dovresti vedere un output simile al seguente.
alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lock
Connettiti a un'istanza che esegue Linux con connettività di rete all'istanza Patroni principale,
alloydb-patroni1, e ottieni informazioni sull'istanza. Potresti dover installare lojqstrumento eseguendosudo apt-get install jq -y.curl -s http://alloydb-patroni1:8008/patroni | jq .
Dovresti vedere un output simile al seguente.
{ "state": "running", "postmaster_start_time": "2024-05-16 14:12:30.031673+00:00", "role": "master", "server_version": 150005, "xlog": { "location": 83886408 }, "timeline": 1, "replication": [ { "usename": "alloydbreplica", "application_name": "patroni2", "client_addr": "10.172.0.40", "state": "streaming", "sync_state": "async", "sync_priority": 0 }, { "usename": "alloydbreplica", "application_name": "patroni3", "client_addr": "10.172.0.41", "state": "streaming", "sync_state": "async", "sync_priority": 0 } ], "dcs_last_seen": 1715870011, "database_system_identifier": "7369600155531440151", "patroni": { "version": "3.3.0", "scope": "my-patroni-cluster", "name": "patroni1" } }
La chiamata all'endpoint API HTTP di Patroni su un nodo Patroni espone vari dettagli sullo stato e sulla configurazione di quella particolare istanza PostgreSQL gestita da Patroni, tra cui informazioni sullo stato del cluster, timeline, informazioni WAL e controlli di integrità che indicano se i nodi e il cluster sono attivi e funzionano correttamente.
Testare la configurazione HAProxy
Su una macchina con un browser e connettività di rete al nodo HAProxy, vai al seguente indirizzo:
http://haproxy:7000. In alternativa, puoi utilizzare l'indirizzo IP esterno dell'istanza HAProxy anziché il relativo nome host.Dovresti vedere uno screenshot simile al seguente.
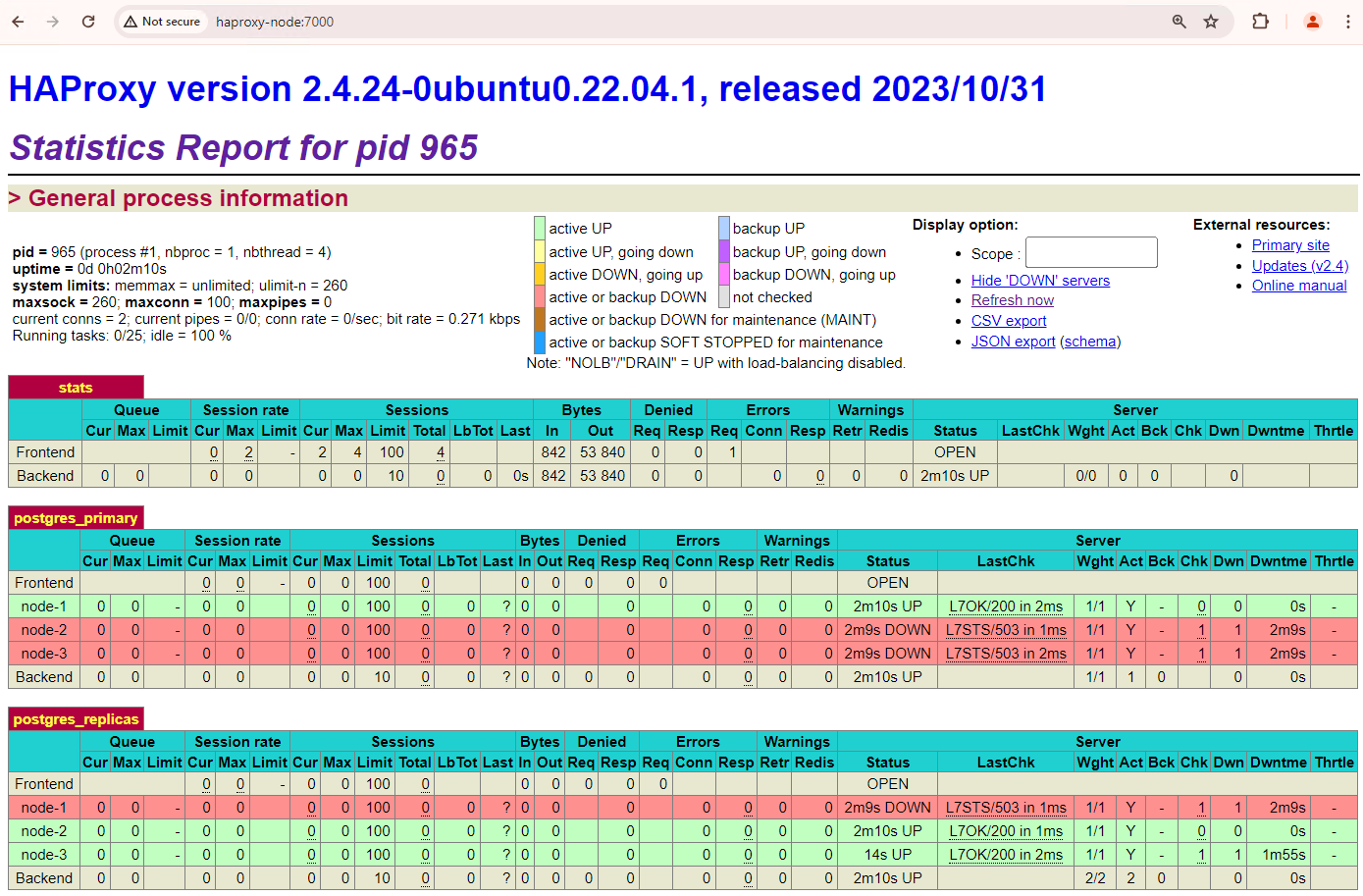
Figura 1. Pagina di stato di HAProxy che mostra lo stato di integrità e la latenza dei nodi Patroni.
Nella dashboard di HAProxy puoi visualizzare lo stato di integrità e la latenza del nodo Patroni principale,
patroni1, e delle due repliche,patroni2epatroni3.Puoi eseguire query per controllare le statistiche di replica nel cluster. Da un client come pgAdmin, connettiti al server del database principale tramite HAProxy ed esegui la seguente query.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Dovresti vedere un diagramma simile al seguente, che mostra che
patroni2epatroni3eseguono lo streaming dapatroni1.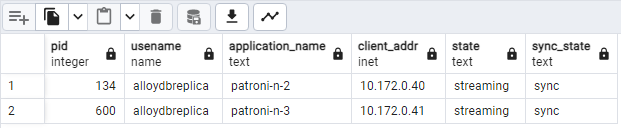
Figura 2. Output di pg_stat_replication che mostra lo stato di replica dei nodi Patroni.
Testare il failover automatico
In questa sezione, nel cluster a tre nodi, simuleremo un'interruzione sul nodo principale interrompendo il container Patroni in esecuzione collegato. Puoi interrompere il servizio Patroni sul nodo principale per simulare un'interruzione o applicare alcune regole firewall per interrompere la comunicazione con quel nodo.
Nell'istanza Patroni principale, vai alla cartella Patroni di AlloyDB Omni.
cd /alloydb/
Arresta il container.
docker compose down
Dovresti vedere un output simile al seguente. Questo dovrebbe convalidare che il container e la rete sono stati arrestati.
[+] Running 2/2 ✔ Container alloydb-patroni Removed ✔ Network alloydbomni-patroni_default Removed
Aggiorna la dashboard di HAProxy e osserva come avviene il failover.
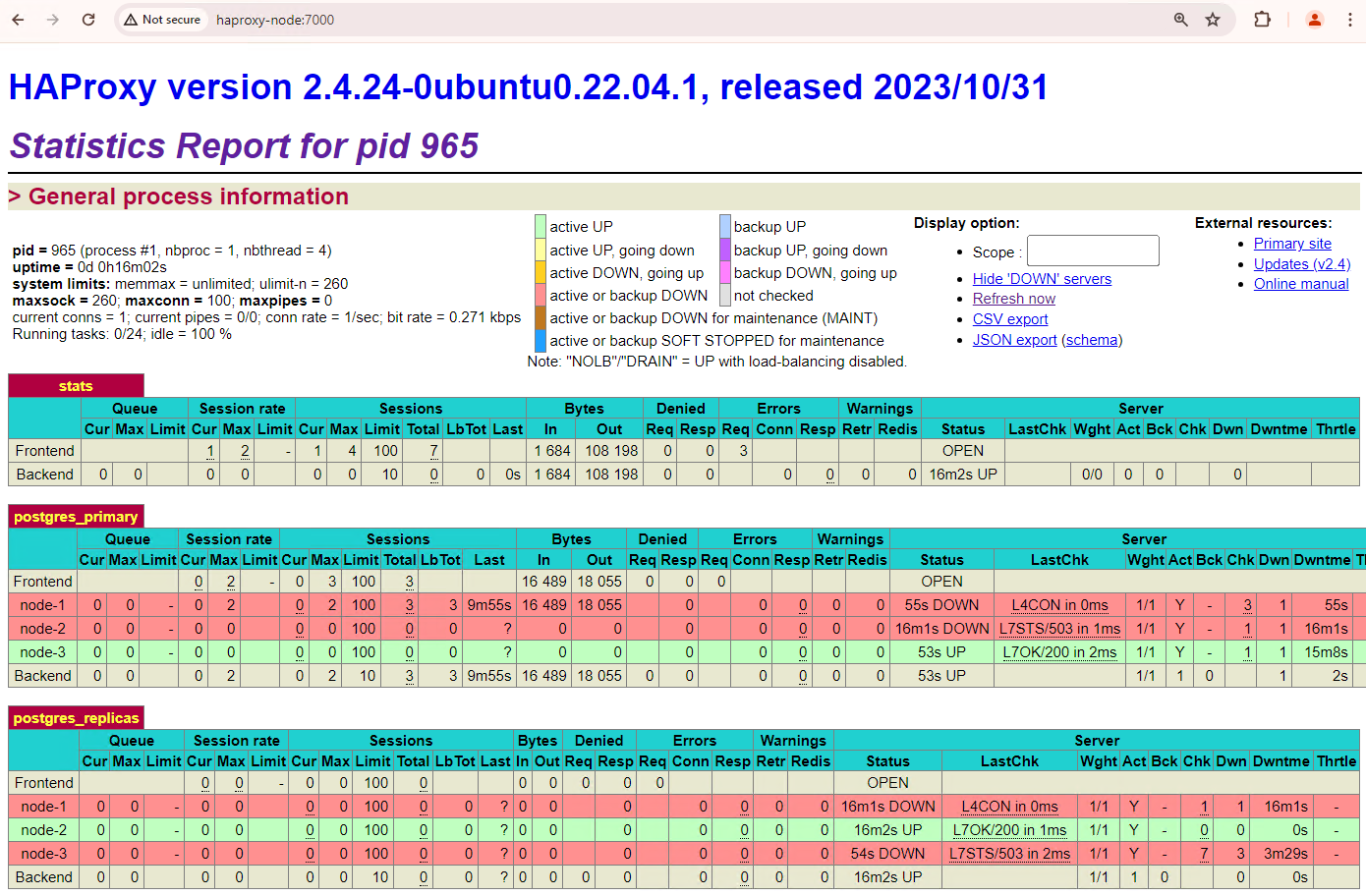
Figura 3. Dashboard di HAProxy che mostra il failover dal nodo principale al nodo in standby.
L'istanza
patroni3è diventata la nuova istanza principale epatroni2è l'unica replica rimanente. L'istanza principale precedente,patroni1, è inattiva e i controlli di integrità non vanno a buon fine.Patroni esegue e gestisce il failover tramite una combinazione di monitoraggio, consenso e orchestrazione automatica. Non appena il nodo principale non riesce a rinnovare il lease entro un timeout specificato o se segnala un errore, gli altri nodi del cluster riconoscono questa condizione tramite il sistema di consenso. I nodi rimanenti si coordinano per selezionare la replica più adatta da promuovere come nuova istanza principale. Una volta selezionata una replica candidata, Patroni promuove questo nodo a principale applicando le modifiche necessarie, come l'aggiornamento della configurazione di PostgreSQL e la riproduzione di eventuali record WAL in sospeso. Poi, il nuovo nodo principale aggiorna il sistema di consenso con il suo stato e le altre repliche si riconfigurano per seguire la nuova istanza principale, inclusa la modifica della sorgente di replica e, potenzialmente, il recupero di eventuali nuove transazioni. HAProxy rileva la nuova istanza principale e reindirizza le connessioni client di conseguenza, garantendo un'interruzione minima.
Da un client come pgAdmin, connettiti al server del database tramite HAProxy e controlla le statistiche di replica nel cluster dopo il failover.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Dovresti vedere un diagramma simile al seguente, che mostra che ora solo
patroni2esegue lo streaming.
Figura 4. Output di pg_stat_replication che mostra lo stato di replica dei nodi Patroni dopo il failover.
Il cluster a tre nodi può sopravvivere a un'altra interruzione. Se arresti il nodo principale attuale,
patroni3, si verifica un altro failover.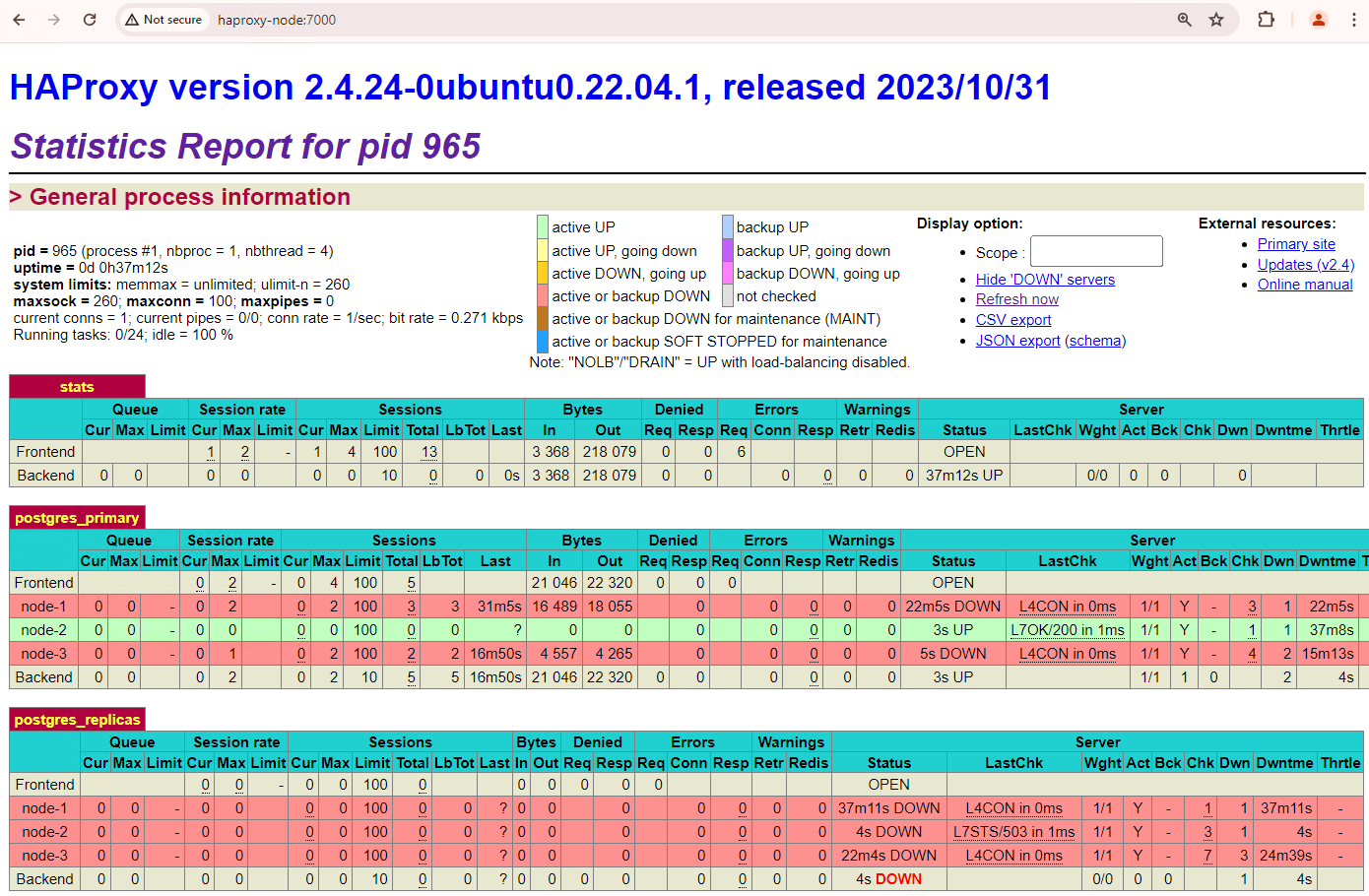
Figura 5. Dashboard di HAProxy che mostra il failover dal nodo principale,
patroni3, al nodo in standby,patroni2.
Considerazioni sul fallback
Il fallback è la procedura per ripristinare il nodo di origine precedente dopo che si è verificato un failover. In genere, il fallback automatico non è consigliato in un cluster di database ad alta disponibilità a causa di diverse problematiche critiche, come il recupero incompleto, il rischio di scenari di split-brain e il ritardo di replica.
Nel cluster Patroni, se attivi i due nodi con cui hai simulato un'interruzione, questi si uniranno di nuovo al cluster come repliche in standby.
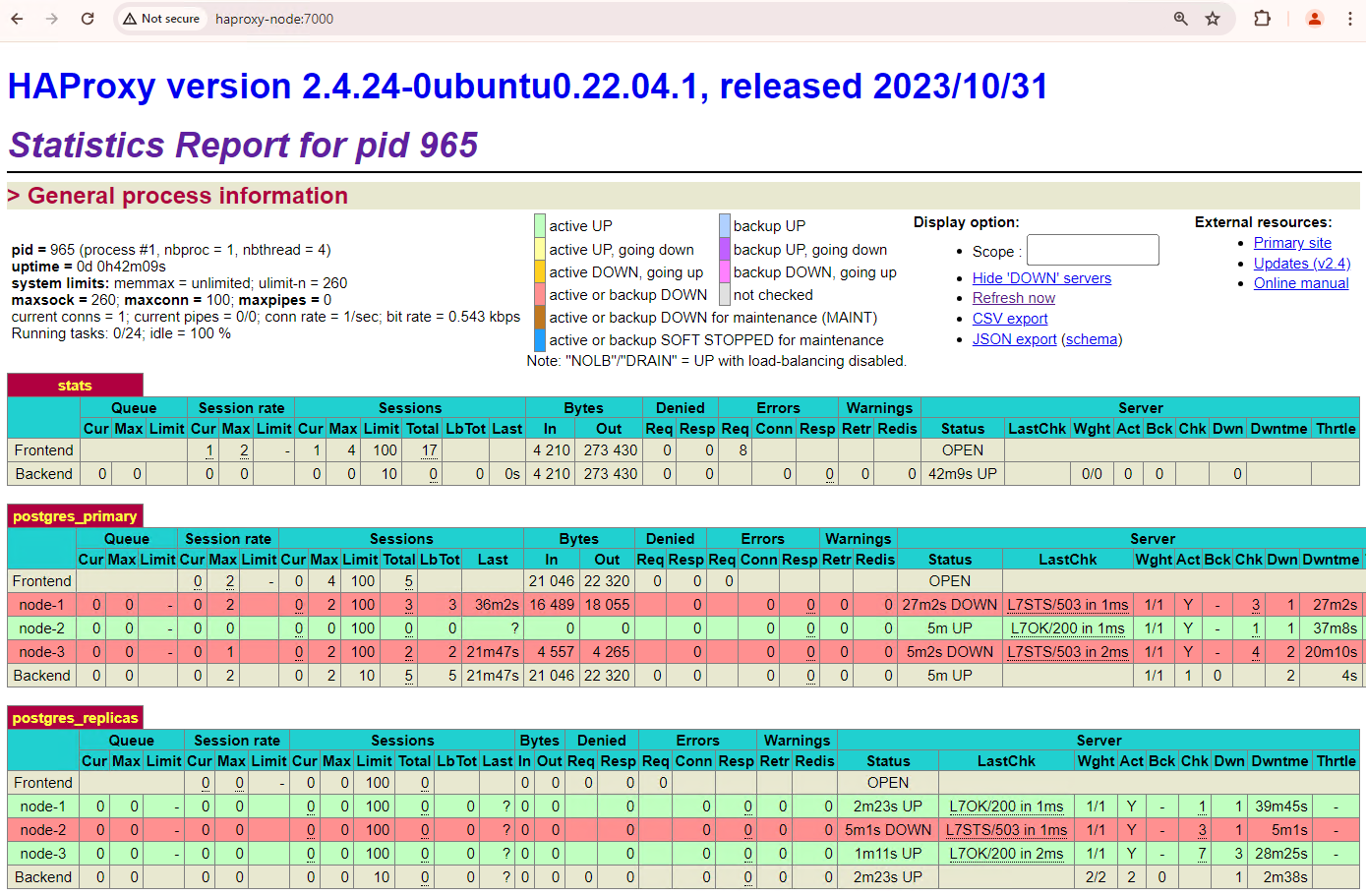
Figura 6. Dashboard di HAProxy che mostra il ripristino di patroni1 e patroni3 come nodi in standby.
Ora patroni1 e patroni3 eseguono la replica dall'istanza principale attuale patroni2.

Figura 7. Output di pg_stat_replication che mostra lo stato di replica dei nodi Patroni dopo il fallback.
Se vuoi eseguire manualmente il fallback all'istanza principale iniziale, puoi farlo utilizzando l'interfaccia a riga di comando patronictl. Se scegli il fallback manuale, puoi garantire una procedura di recupero più affidabile, coerente e accuratamente verificata, mantenendo l'integrità e la disponibilità dei sistemi di database.