
Informationen zur Verwendung der gefilterten Vektorsuche zum Verfeinern von Ähnlichkeitssuchen finden Sie unter Gefilterte Vektorsuche in AlloyDB Omni.
Informationen zum Ausführen einer Vektorsuche mit Vertex AI-Einbettungen finden Sie unter Erste Schritte mit Vektoreinbettungen in AlloyDB Omni AI.
Ziele
- Erstellen Sie einen AlloyDB Omni-Cluster und eine primäre Instanz.
- Stellen Sie eine Verbindung zu Ihrer Datenbank her und installieren Sie die erforderlichen Erweiterungen.
- Erstellen Sie eine
product- und eineproduct inventory-Tabelle. - Fügen Sie Daten in die Tabellen
productundproduct inventoryein und führen Sie eine einfache Vektorsuche durch. - Erstellen Sie einen ScaNN-Index für die Tabelle „products“.
- Führen Sie eine einfache Vektorsuche durch.
- Eine komplexe Vektorsuche mit einem Filter und einem Join durchführen
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung Ihrer voraussichtlichen Nutzung vornehmen.
Neuen Nutzern von Google Cloud steht möglicherweise ein kostenloser Testzeitraum zur Verfügung.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter „Bereinigen“.
Vorbereitung
Erfüllen Sie die folgenden Voraussetzungen, bevor Sie eine Vektorsuche durchführen:
- AlloyDB AI in AlloyDB Omni installieren
-
AlloyDB Omni als Nutzer
postgresausführen und eine Verbindung herstellen -
Installieren Sie die Erweiterungen
vector,alloydb_scannundgoogle_ml_integration.CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
Produkt- und Produktinventardaten einfügen und eine einfache Vektorsuche durchführen
Führen Sie die folgende Anweisung aus, um eine Tabelle
productzu erstellen, die Folgendes ausführt:- Hier werden grundlegende Produktinformationen gespeichert.
- Enthält eine
embedding-Vektorspalte, in der ein Einbettungsvektor für eine Produktbeschreibung jedes Produkts berechnet und gespeichert wird.
CREATE TABLE product ( id INT PRIMARY KEY, name VARCHAR(255) NOT NULL, description TEXT, category VARCHAR(255), color VARCHAR(255), embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005', description)) STORED );Bei Bedarf können Sie sich die Logs ansehen und Fehler beheben.
Führen Sie die folgende Abfrage aus, um eine
product_inventory-Tabelle zu erstellen, in der Informationen zu verfügbarem Inventar und den entsprechenden Preisen gespeichert werden. Die Tabellenproduct_inventoryundproductwerden in dieser Anleitung verwendet, um komplexe Vektorsuchanfragen auszuführen.CREATE TABLE product_inventory ( id INT PRIMARY KEY, product_id INT REFERENCES product(id), inventory INT, price DECIMAL(10,2) );Führen Sie die folgende Abfrage aus, um Produktdaten in die Tabelle
producteinzufügen:INSERT INTO product (id, name, description,category, color) VALUES (1, 'Stuffed Elephant', 'Soft plush elephant with floppy ears.', 'Plush Toys', 'Gray'), (2, 'Remote Control Airplane', 'Easy-to-fly remote control airplane.', 'Vehicles', 'Red'), (3, 'Wooden Train Set', 'Classic wooden train set with tracks and trains.', 'Vehicles', 'Multicolor'), (4, 'Kids Tool Set', 'Toy tool set with realistic tools.', 'Pretend Play', 'Multicolor'), (5, 'Play Food Set', 'Set of realistic play food items.', 'Pretend Play', 'Multicolor'), (6, 'Magnetic Tiles', 'Set of colorful magnetic tiles for building.', 'Construction Toys', 'Multicolor'), (7, 'Kids Microscope', 'Microscope for kids with different magnification levels.', 'Educational Toys', 'White'), (8, 'Telescope for Kids', 'Telescope designed for kids to explore the night sky.', 'Educational Toys', 'Blue'), (9, 'Coding Robot', 'Robot that teaches kids basic coding concepts.', 'Educational Toys', 'White'), (10, 'Kids Camera', 'Durable camera for kids to take pictures and videos.', 'Electronics', 'Pink'), (11, 'Walkie Talkies', 'Set of walkie talkies for kids to communicate.', 'Electronics', 'Blue'), (12, 'Karaoke Machine', 'Karaoke machine with built-in microphone and speaker.', 'Electronics', 'Black'), (13, 'Kids Drum Set', 'Drum set designed for kids with adjustable height.', 'Musical Instruments', 'Blue'), (14, 'Kids Guitar', 'Acoustic guitar for kids with nylon strings.', 'Musical Instruments', 'Brown'), (15, 'Kids Keyboard', 'Electronic keyboard with different instrument sounds.', 'Musical Instruments', 'Black'), (16, 'Art Easel', 'Double-sided art easel with chalkboard and whiteboard.', 'Arts & Crafts', 'White'), (17, 'Finger Paints', 'Set of non-toxic finger paints for kids.', 'Arts & Crafts', 'Multicolor'), (18, 'Modeling Clay', 'Set of colorful modeling clay.', 'Arts & Crafts', 'Multicolor'), (19, 'Watercolor Paint Set', 'Watercolor paint set with brushes and palette.', 'Arts & Crafts', 'Multicolor'), (20, 'Beading Kit', 'Kit for making bracelets and necklaces with beads.', 'Arts & Crafts', 'Multicolor'), (21, '3D Puzzle', '3D puzzle of a famous landmark.', 'Puzzles', 'Multicolor'), (22, 'Race Car Track Set', 'Race car track set with cars and accessories.', 'Vehicles', 'Multicolor'), (23, 'RC Monster Truck', 'Remote control monster truck with oversized tires.', 'Vehicles', 'Green'), (24, 'Train Track Expansion Set', 'Expansion set for wooden train tracks.', 'Vehicles', 'Multicolor');Optional: Führen Sie die folgende Abfrage aus, um zu prüfen, ob die Daten in die Tabelle
producteingefügt wurden:SELECT * FROM product;Führen Sie die folgende Abfrage aus, um Inventardaten in die Tabelle
product_inventoryeinzufügen:INSERT INTO product_inventory (id, product_id, inventory, price) VALUES (1, 1, 9, 13.09), (2, 2, 40, 79.82), (3, 3, 34, 52.49), (4, 4, 9, 12.03), (5, 5, 36, 71.29), (6, 6, 10, 51.49), (7, 7, 7, 37.35), (8, 8, 6, 10.87), (9, 9, 7, 42.47), (10, 10, 3, 24.35), (11, 11, 4, 10.20), (12, 12, 47, 74.57), (13, 13, 5, 28.54), (14, 14, 11, 25.58), (15, 15, 21, 69.84), (16, 16, 6, 47.73), (17, 17, 26, 81.00), (18, 18, 11, 91.60), (19, 19, 8, 78.53), (20, 20, 43, 84.33), (21, 21, 46, 90.01), (22, 22, 6, 49.82), (23, 23, 37, 50.20), (24, 24, 27, 99.27);Führen Sie die folgende Vektorsuchanfrage aus, um Produkte zu finden, die dem Wort
musicähneln. Das bedeutet, dass in den Ergebnissen Produkte angezeigt werden, die für die Anfrage relevant sind, auch wenn das Wortmusicnicht explizit in der Produktbeschreibung erwähnt wird:SELECT * FROM product ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector LIMIT 3;Das Ergebnis der Abfrage sieht so aus:
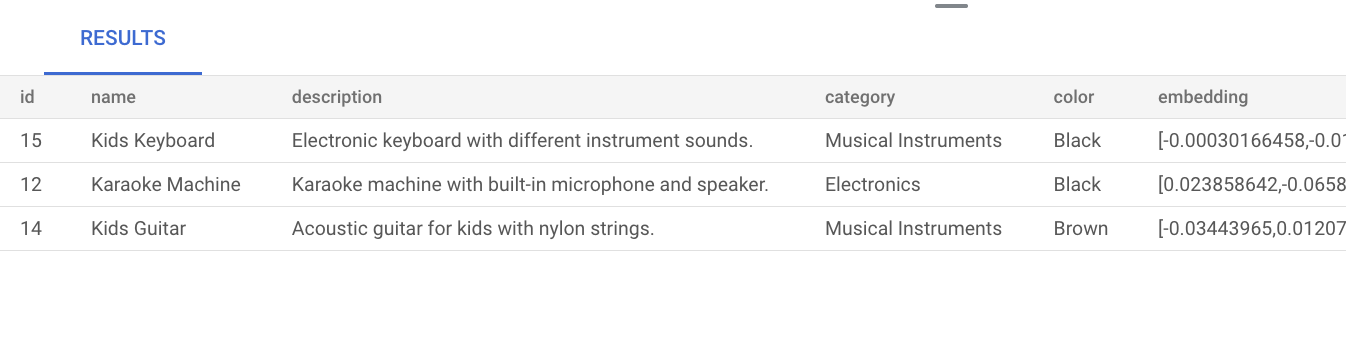
Wenn Sie eine einfache Vektorsuche ohne Indexerstellung durchführen, wird die exakte Suche nach dem nächsten Nachbarn (KNN) verwendet, die einen effizienten Recall bietet. Bei großem Umfang kann die Verwendung von KNN die Leistung beeinträchtigen. Für eine bessere Abfrageleistung empfehlen wir, den ScaNN-Index für die ungefähre Suche nach dem nächsten Nachbarn (ANN) zu verwenden, die einen hohen Recall bei niedrigen Latenzen bietet.
Ohne Indexerstellung verwendet AlloyDB Omni standardmäßig die exakte Suche nach dem nächsten Nachbarn (KNN).
Weitere Informationen zur Verwendung von ScaNN im großen Maßstab finden Sie unter Erste Schritte mit Vektoreinbettungen in AlloyDB AI.
Manuell optimierten ScaNN-Index für die Produkttabelle erstellen
Führen Sie die folgende Abfrage aus, um einen product_index-ScaNN-Index für die Tabelle product zu erstellen:
CREATE INDEX product_index ON product
USING scann (embedding cosine)
WITH (mode='MANUAL', num_leaves=4);
Weitere Informationen zum Erstellen eines ScaNN-Index finden Sie unter ScaNN-Index erstellen.
Vektorsuche ausführen
Führen Sie die folgende Vektorsuchanfrage aus, um Produkte zu finden, die der Anfrage in natürlicher Sprache music ähneln. Auch wenn das Wort music nicht in der Produktbeschreibung enthalten ist, werden im Ergebnis Produkte angezeigt, die für die Anfrage relevant sind:
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
Die Abfrageergebnisse sehen so aus:

Der Abfrageparameter scann.num_leaves_to_search steuert die Anzahl der Blattknoten, die bei einer Ähnlichkeitssuche durchsucht werden. Die Parameterwerte num_leaves und scann.num_leaves_to_search tragen dazu bei, ein ausgewogenes Verhältnis zwischen Leistung und Recall zu erzielen.
Vektorsuche mit Filter und Join durchführen
Sie können gefilterte Vektorsuche-Abfragen auch dann effizient ausführen, wenn Sie den ScaNN-Index verwenden. Führen Sie die folgende komplexe Vektorsuche-Abfrage aus, die relevante Ergebnisse zurückgibt, die die Abfragebedingungen erfüllen, auch mit Filtern:
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product p
JOIN product_inventory pi ON p.id = pi.product_id
WHERE pi.price < 80.00
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
Gefilterte Vektorsuche beschleunigen
Sie können den spaltenbasierten Engine-Speicher verwenden, um die Leistung von Vektorähnlichkeitssuchen zu verbessern, insbesondere von KNN-Suchen (K-Nearest Neighbor), wenn sie mit einer hochselektiven Prädikatfilterung kombiniert werden, z. B. mit LIKE in Datenbanken. In diesem Abschnitt verwenden Sie die Erweiterung vector und die AlloyDB Omni-Erweiterung google_columnar_engine. Weitere Informationen zur Funktionsweise der spaltenbasierten Engine finden Sie unter Übersicht über die spaltenbasierte Engine.
Leistungssteigerungen ergeben sich aus der integrierten Effizienz der spaltenbasierten Engine beim Scannen großer Datasets und Anwenden von Filtern wie LIKE-Prädikaten in Verbindung mit der Möglichkeit, mithilfe der Vektorunterstützung Zeilen vorzufiltern. Diese Funktion reduziert die Anzahl der für nachfolgende KNN-Vektorberechnungen erforderlichen Datenuntergruppen und trägt zur Optimierung komplexer Analyseabfragen bei, die Standardfilterung und Vektorsuche umfassen.
Der spaltenorientierte Speicher bietet zwei Optionen zum Verwalten seiner Inhalte:
- Spaltenspeicherinhalte automatisch verwalten: Neue AlloyDB Omni-Instanzen verwenden standardmäßig die automatische Spaltenformatierung. Alternativ können Sie die automatische Spaltenaufteilung auch manuell ausführen.
- Spaltenspeicherinhalte manuell verwalten: Wenn Sie die Spalten im Spaltenspeicher für Ihren Arbeitslast manuell verwalten müssen, können Sie die automatische Spaltenformatierung deaktivieren.
So vergleichen Sie die Ausführungszeit einer KNN-Vektorsuche, die nach einem LIKE-Prädikat gefiltert wird, vor und nach der Aktivierung der spaltenbasierten Engine:
-
Aktivieren Sie die
vector-Erweiterung, um Vektordatentypen und ‑vorgänge zu unterstützen. Führen Sie die folgenden Anweisungen aus, um eine Beispielstabelle (items) mit einer ID, einer Textbeschreibung und einer Spalte mit 512-dimensionalen Vektoreinbettungen zu erstellen.CREATE EXTENSION IF NOT EXISTS vector; CREATE TABLE items ( id SERIAL PRIMARY KEY, description TEXT, embedding VECTOR(512) );
-
Füllen Sie die Daten, indem Sie die folgenden Anweisungen ausführen, um 1 Million Zeilen in die Beispielstabelle
itemseinzufügen.-- Simplified example of inserting matching (~0.1%) and non-matching data INSERT INTO items (description, embedding) SELECT CASE WHEN g % 1000 = 0 THEN 'product_' || md5(random()::text) || '_common' -- ~0.1% match ELSE 'generic_item_' || g || '_' || md5(random()::text) -- ~99.9% don't match END, (SELECT array_agg(random()) FROM generate_series(1, 512))::vector FROM generate_series(1, 999999) g;
-
Messen Sie die Referenzleistung der Suche nach Vektorähnlichkeiten ohne die spaltenbasierte Engine.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;
-
Aktivieren Sie die spaltenbasierte Engine und die Vektorunterstützung.
-
Aktivieren Sie die Datenbank-Flags
google_columnar_engine.enabledundgoogle_columnar_engine.enable_vector_support.ALTER SYSTEM SET google_columnar_engine.enabled = 'on'; ALTER SYSTEM SET google_columnar_engine.enable_vector_support = 'on';
-
AlloyDB Omni neu starten
Docker
docker restart CONTAINER_NAMEDocker
docker restart CONTAINER_NAMEPodman
podman restart CONTAINER_NAMEPodman
podman restart CONTAINER_NAMEErsetzen Sie
CONTAINER_NAMEdurch den Namen des Containers, den Sie unter AlloyDB Omni in Containern installieren erstellt haben.
-
-
Fügen Sie der spaltenbasierten Engine die Tabelle
itemshinzu:SELECT google_columnar_engine_add('items');
-
Messen Sie die Leistung der Suche nach Vektorähnlichkeiten mit der spaltenbasierten Engine. Sie führen die Abfrage noch einmal aus, mit der Sie zuvor die Referenzleistung gemessen haben.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;
-
Führen Sie den folgenden Befehl aus, um zu prüfen, ob die Abfrage mit der spaltenorientierten Engine ausgeführt wurde:
explain (analyze) SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;
Bereinigen
Informationen zum Deinstallieren von AlloyDB Omni finden Sie unter AlloyDB Omni verwalten und überwachen.