
בדף הזה מוסבר איך להשתמש בלוח הבקרה של תובנות לגבי שאילתות כדי לזהות ולנתח בעיות בביצועים. במאמר סקירה כללית על תובנות לגבי שאילתות יש סקירה כללית של התכונה.
אתם יכולים להשתמש ב-Gemini Cloud Assist כדי לעקוב אחרי משאבי AlloyDB ולפתור בעיות שקשורות אליהם. מידע נוסף זמין במאמר בנושא מעקב ופתרון בעיות בעזרת Gemini.
לפני שמתחילים
אם אתם או משתמשים אחרים צריכים להציג את תוכנית השאילתה או לבצע מעקב מקצה לקצה, אתם צריכים הרשאות ספציפיות של ניהול זהויות והרשאות גישה (IAM). אתם יכולים ליצור תפקיד בהתאמה אישית ולהוסיף לו את הרשאות ה-IAM הנדרשות. אחר כך תוכלו להוסיף את התפקיד הזה לכל חשבון משתמש שמשתמש בתובנות לגבי שאילתות כדי לפתור בעיה. רוצים לדעת איך יוצרים תפקיד בהתאמה אישית?
לתפקיד בהתאמה אישית צריכה להיות הרשאת ה-IAM הבאה: cloudtrace.traces.get.
פתיחת מרכז הבקרה של תובנות לגבי שאילתות
כדי לפתוח את מרכז הבקרה של תובנות לגבי שאילתות:
- ברשימת האשכולות והמכונות, לוחצים על מכונה.
- אפשר ללחוץ על Go to Query insights for more in-depth info on queries and performance (מעבר לתובנות לגבי שאילתות לקבלת מידע מעמיק יותר על שאילתות וביצועים) מתחת לתרשים המדדים בדף Overview (סקירה כללית) של האשכול, או לבחור בכרטיסייה Query insights (תובנות לגבי שאילתות) בחלונית הניווט הימנית.
בדף הבא, אפשר להשתמש באפשרויות הבאות כדי לסנן את התוצאות:
- בורר המופעים. מאפשר לבחור את המופע הראשי או את המופעים של מאגר הקריאה באשכול. כברירת מחדל, המופע הראשי נבחר. הפרטים שמוצגים הם נתונים מצטברים של כל המופעים של מאגר הקריאה המחובר והצמתים שלהם.
- מסד נתונים. מסננים את עומס השאילתות במסד נתונים ספציפי או בכל מסדי הנתונים.
- משתמש. מסננים את עומס השאילתות מחשבונות משתמשים ספציפיים.
- כתובת הלקוח: סינון עומס השאילתות מכתובת IP ספציפית.
- טווח זמן.מסנן את טעינת השאילתה לפי טווחי זמן, כמו שעה, יום, שבוע או טווח מותאם אישית.
עריכת ההגדרות של תובנות לגבי שאילתות
תובנות לגבי שאילתות מופעלות כברירת מחדל במופעי AlloyDB. אתם יכולים לערוך את הגדרות ברירת המחדל של התובנות לגבי שאילתות.
כדי לערוך את ההגדרה של תובנות לגבי שאילתות במופע AlloyDB, פועלים לפי השלבים הבאים:
המסוף
נכנסים לדף Clusters במסוף Google Cloud .
לוחצים על אשכול בעמודה שם המשאב.
בחלונית הניווט הימנית, לוחצים על תובנות לגבי שאילתות.
בוחרים באפשרות Primary או Read pool מהרשימה Query insights ולוחצים על Edit.
עורכים את השדות תובנות לגבי שאילתות:
כדי לשנות את מגבלת ברירת המחדל של 1,024 בייט על אורכי שאילתות לניתוח ב-AlloyDB, בשדה Query lengths (אורכי שאילתות), מזינים מספר בין 256 ל-4,500.
המכונה מופעלת מחדש אחרי שאתם עורכים את השדה הזה.
הערה: כדי להגדיל את המגבלה על אורך השאילתה צריך יותר זיכרון.
כדי להתאים אישית את קבוצות התכונות של התובנות לגבי שאילתות, משנים את האפשרויות הבאות:
דגימת תוכנית שאילתה: מסמנים את תיבת הסימון הזו כדי להציג את הפעולות שנעשה בהן שימוש להשלמת דגימה של שאילתה. קצב הדגימה קובע את המספר המקסימלי של שאילתות ש-AlloyDB יכול לדגום לדקה עבור המופע לכל צומת.
בשדה שיעור הדגימה המקסימלי, מזינים מספר בין 1 ל-20. כברירת מחדל, קצב הדגימה מוגדר כ-5. כדי להשבית את הדגימה, מבטלים את הסימון בתיבת הסימון Query plan sampling.
שמירת כתובות ה-IP של הלקוחות: מסמנים את התיבה הזו כדי לדעת מאיפה מגיעות השאילתות שלכם, וכדי לקבץ את המידע הזה להפעלת מדדים.
תגי אפליקציות של חנות: מסמנים את התיבה הזו כדי לדעת אילו אפליקציות עם תגים שולחות בקשות, וכדי לקבץ את המידע הזה להפעלת מדדים. מידע נוסף על תגי אפליקציות זמין במפרט.
לוחצים על עדכון המופע.
gcloud
כדי להפעיל את התכונה 'תובנות לגבי שאילתות' במכונת AlloyDB באמצעות פקודות של Google Cloud CLI, מבצעים את הפעולות הבאות:
- התקינו את ה-CLI של Google Cloud.
- כדי לאתחל את ה-CLI של gcloud, הריצו את הפקודה הבאה:
gcloud init
אם אתם משתמשים במעטפת מקומית, אתם צריכים ליצור פרטי כניסה לאימות מקומי עבור חשבון המשתמש:
gcloud auth application-default login
אם אתם משתמשים ב-Cloud Shell, אין צורך לבצע את הפעולה הזו.
מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
הנה דוגמה:
gcloud alloydb instances update INSTANCE \
--cluster=CLUSTER \
--project=PROJECT \
--region=REGION \
--insights-config-query-string-length=QUERY_LENGTH \
--insights-config-query-plans-per-minute=QUERY_PLANS \
--insights-config-record-application-tags \
--insights-config-record-client-addressמחליפים את מה שכתוב בשדות הבאים:
-
INSTANCE: המזהה של המכונה שרוצים לעדכן -
CLUSTER: המזהה של האשכול של המופע -
PROJECT: מזהה הפרויקט של האשכול -
REGION: האזור של האשכול – לדוגמה,us-central1 -
QUERY_LENGTH: אורך השאילתה, בין 256 ל-4,500 -
QUERY_PLANS: מספר תוכניות השאילתות שיוגדרו לדקה.
אפשר גם להשתמש באחד או יותר מהדגלים האופציונליים הבאים:
-
--insights-config-query-string-length: מגדיר את מגבלת אורך השאילתה כברירת מחדל לערך שצוין בין 256 ל-4,500 בייט. אורך השאילתה כברירת מחדל הוא 1,024 בייט. אורך שאילתה גדול יותר שימושי יותר לשאילתות אנליטיות, אבל הוא גם דורש יותר זיכרון. כדי לשנות את אורך השאילתה צריך להפעיל מחדש את המכונה. עדיין אפשר להוסיף תגים לשאילתות שחורגות ממגבלת האורך. -
--insights-config-query-plans-per-minute: כברירת מחדל, נשמרות עד חמש דגימות של תוכניות שאילתות שהופעלו בכל דקה בכל מסדי הנתונים במופע. צריך לשנות את הערך הזה למספר בין 1 ל-20. כדי להשבית את הדגימה, מזינים 0. הגדלת קצב הדגימה כנראה תספק לכם יותר נקודות נתונים, אבל יכול להיות שתתווסף תקורה של ביצועים. -
--insights-config-record-client-address: מאחסן את כתובות ה-IP של הלקוחות שמהן מגיעות השאילתות, ועוזר לקבץ את הנתונים האלה כדי להריץ עליהם מדדים. השאילתות מגיעות מיותר ממארח אחד. בדיקת הגרפים של שאילתות מכתובות IP של לקוחות יכולה לעזור לזהות את מקור הבעיה. אם לא רוצים לאחסן כתובות IP של לקוחות, צריך להשתמש ב---no-insights-config-record-client-address. -
--insights-config-record-application-tags: מאחסן תגי אפליקציה שעוזרים לכם לקבוע את נתיבי ה-API ואת נתיבי בקר התצוגה של המודל (MVC) שמבצעים בקשות, ומקבץ את הנתונים כדי להריץ מדדים על בסיסם. כדי להשתמש באפשרות הזו, צריך להוסיף הערות לשאילתות עם קבוצה ספציפית של תגים. אם אתם לא רוצים לאחסן תגי אפליקציה, אתם יכולים להשתמש באפשרות--no-insights-config-record-application-tags.
Terraform
כדי להשתמש ב-Terraform להגדרת התובנות לגבי שאילתות, משתמשים במשאב google_alloydb_instance.
הנה דוגמה:
query_insights_config {
query_string_length = QUERY_STRING_LENGTH_VALUE
record_application_tags = RECORD_APPLICATION_TAG_VALUE
record_client_address = RECORD_CLIENT_ADDRESS_VALUE
query_plans_per_minute = QUERY_PLANS_PER_MINUTE_VALUE5
}
מחליפים את מה שכתוב בשדות הבאים:
-
QUERY_STRING_LENGTH_VALUE: אורך מחרוזת השאילתה. ערך ברירת המחדל הוא1024. כל מספר שלם בין 256 ל-4,500 הוא ערך תקין. -
RECORD_APPLICATION_TAG_VALUE: הקלטת תג אפליקציה עבור מכונה. ערך ברירת המחדל הואtrue. -
RECORD_CLIENT_ADDRESS_VALUE: תיעוד של כתובת הלקוח עבור מופע. ערך ברירת המחדל הואtrue.
QUERY_PLANS_PER_MINUTE_VALUE: מספר תוכניות ההפעלה של השאילתות שנאספו על ידי התובנות בכל דקה לכל השאילתות יחד. ערך ברירת המחדל הוא5. כל מספר שלם בין 0 ל-20 הוא ערך תקין.כדי ללמוד איך להחיל הגדרות ב-Terraform או להסיר אותן, ראו פקודות בסיסיות ב-Terraform.
הגדרת המופע לדוגמה עם הגדרת התובנות לגבי שאילתות שנוספה אמורה להופיע באופן הבא:
resource "google_alloydb_instance" "instance_name" { provider = "google-beta" cluster = google_alloydb_cluster.default.name instance_id = "instance_id" instance_type = "PRIMARY" machine_config { cpu_count = 8 } query_insights_config { query_string_length = 1024 record_application_tags = false record_client_address = false query_plans_per_minute = 5 } depends_on = [google_alloydb_instance.default] }
REST v1
בדוגמה הזו מוגדרות הגדרות של יכולת תצפית במופע AlloyDB. לרשימה מלאה של הפרמטרים של הקריאה הזו, אפשר לעיין במאמר בנושא Method: projects.locations.clusters.instances.patch.
כדי להגדיר את ההגדרות של התכונה 'תובנות לגבי שאילתות', משנים את השדות האופציונליים לפי הצורך. רשימה מלאה של השדות של הקריאה הזו מופיעה במאמר QueryInsightsInstanceConfig.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
-
CLUSTER_ID: המזהה של האשכול שיוצרים. הוא צריך להתחיל באות קטנה באנגלית, ויכול לכלול אותיות קטנות, מספרים ומקפים. -
PROJECT_ID: מזהה הפרויקט שבו רוצים למקם את האשכול. -
LOCATION_ID: המזהה של האזור של האשכול. -
INSTANCE_ID: השם של המכונה הראשית שרוצים ליצור.
כדי לשנות את הגדרות המכונה, משתמשים בבקשת PATCH הבאה:
PATCH https://alloydb.googleapis.com/v1beta/{instance.name=projects/PROJECT_ID/locations/LOCATION_ID/clusters/CLUSTER_ID/instances/INSTANCE_ID?updateMask=observabilityConfig.enabled}
תוכן בקשת JSON שקובע את ההגדרות של כל שדות הניטור נראה כך:
{
"queryStringLength": integer,
"recordApplicationTags": boolean,
"recordClientAddress": boolean,
"queryPlansPerMinute": integer
}
שיפור הביצועים של שאילתות
התכונה 'תובנות לגבי שאילתות' עוזרת לפתור בעיות בשאילתות של AlloyDB כדי למצוא בעיות בביצועים. בלוח הבקרה של תובנות לגבי שאילתות מוצג עומס השאילתות על סמך גורמים שאתם בוחרים. עומס השאילתות הוא מדד של העבודה הכוללת של כל השאילתות במופע בטווח הזמן שנבחר.
תובנות לגבי שאילתות עוזרות לכם לזהות ולנתח בעיות בביצועים של שאילתות. כדי לפתור בעיות בשאילתות באמצעות תובנות לגבי שאילתות, פועלים לפי השלבים הבאים:
- צפייה בעומס על מסד הנתונים עבור כל השאילתות.
- מזהים שאילתה או תג בעייתיים.
- בודקים את השאילתה או התג כדי לזהות בעיות.
- בדיקת מעקב שנוצר על ידי שאילתה לדוגמה
הצגת העומס על מסד הנתונים לכל השאילתות
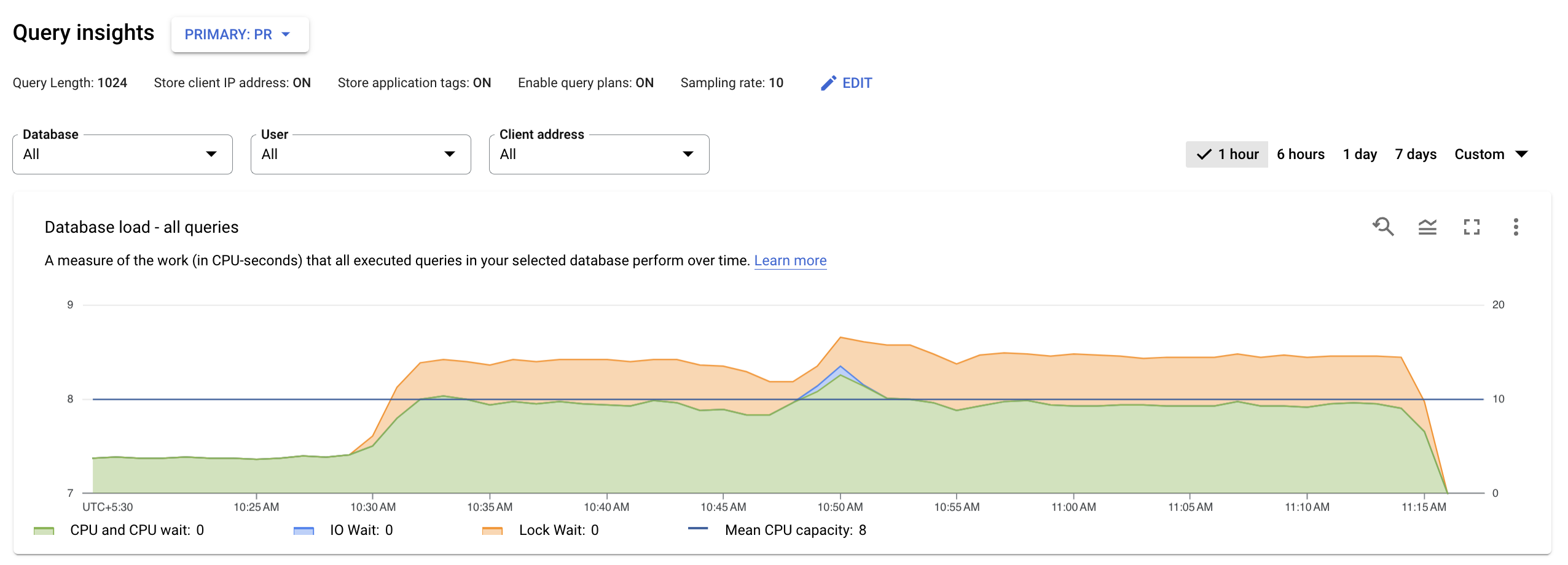
במרכז הבקרה של תובנות לגבי שאילתות ברמה העליונה מוצג הגרף עומס על מסד הנתונים – כל השאילתות המובילות באמצעות נתונים מסוננים. עומס שאילתות במסד נתונים הוא מדד של העבודה (בשניות מעבד) שמתבצעת על ידי השאילתות שהופעלו במסד הנתונים שנבחר לאורך זמן. כל שאילתה שמופעלת משתמשת במשאבי CPU, במשאבי קלט/פלט או במשאבי נעילה, או ממתינה להם. עומס שאילתות במסד הנתונים הוא היחס בין משך הזמן שנדרש לכל השאילתות שהושלמו בחלון זמן נתון לבין הזמן שחלף בפועל.
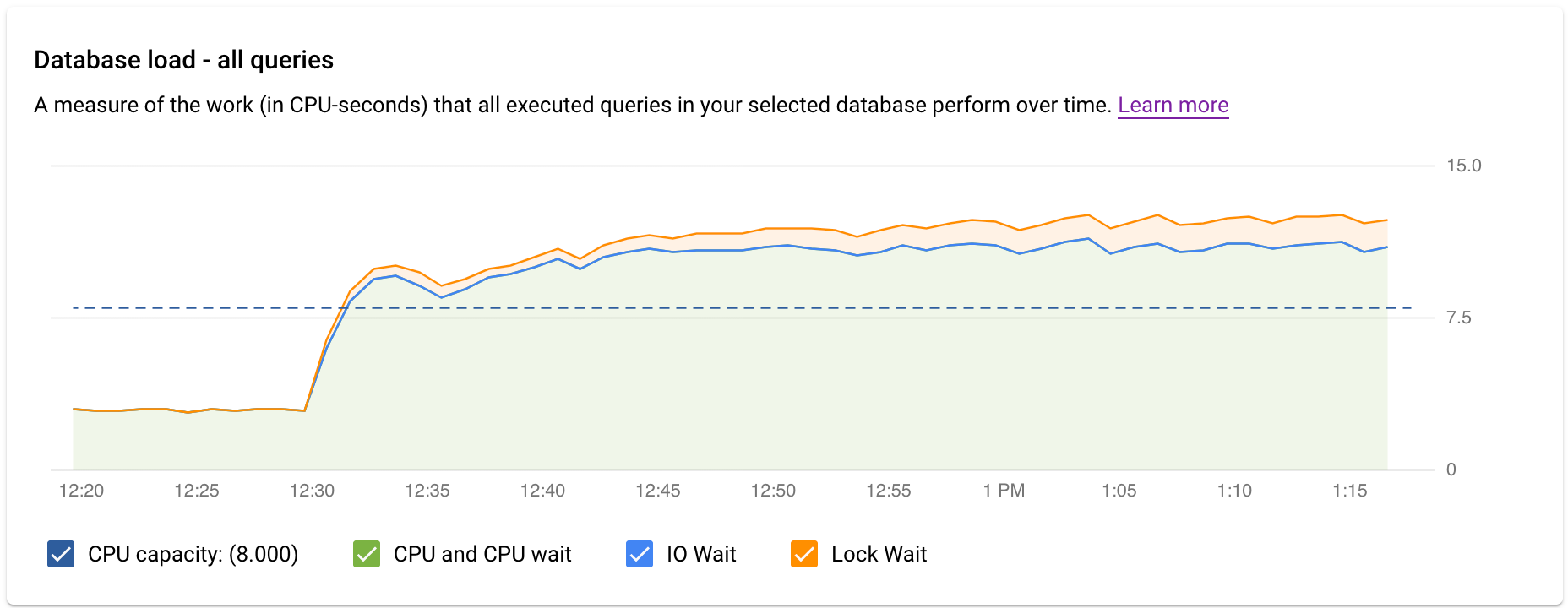
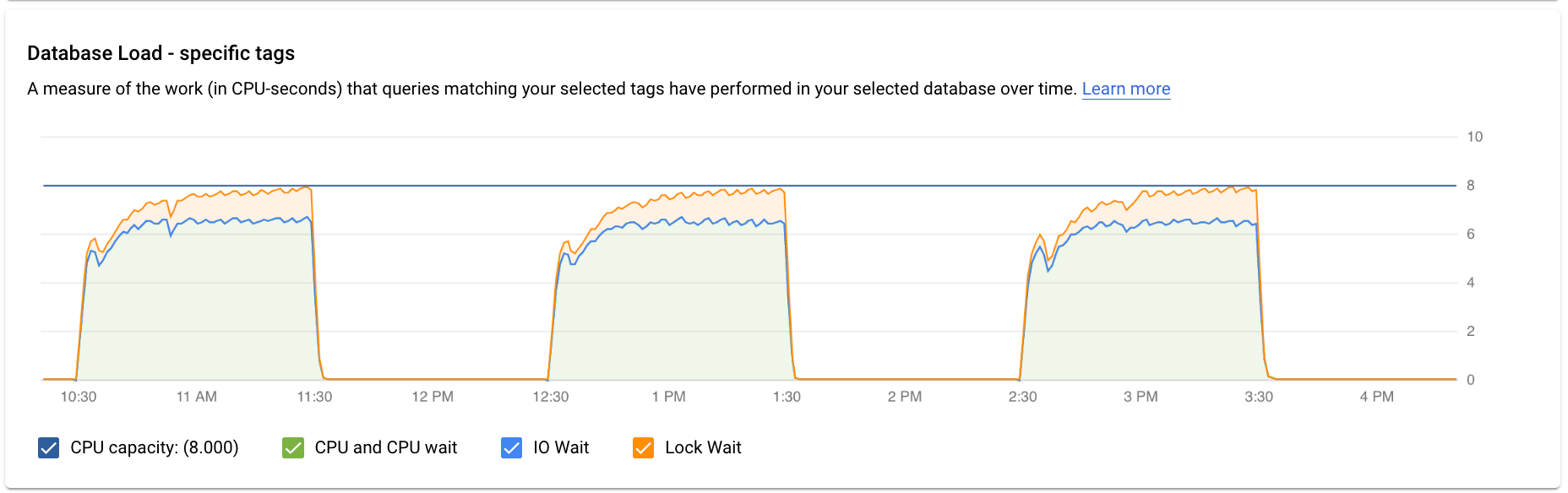
הקווים הצבעוניים בתרשים מציגים את עומס השאילתות, שמחולק לארבע קטגוריות:
- קיבולת המעבד: מספר המעבדים שזמינים במופע.
מעבד (CPU) והמתנה למעבד: היחס בין הזמן שלוקח לשאילתות במצב פעיל לבין הזמן שחלף בפועל. המתנות של קלט/פלט ונעילה לא חוסמות שאילתות שנמצאות במצב פעיל. יכול להיות שהמדד הזה מצביע על כך שהשאילתה משתמשת במעבד או ממתינה לתזמון של Linux כדי לתזמן את תהליך השרת שמריץ את השאילתה, בזמן שתהליכים אחרים משתמשים במעבד.
הערה: עומס המעבד כולל גם את זמן הריצה וגם את הזמן שבו המערכת ממתינה לתזמון של תהליך השרת שפועל על ידי מתזמן Linux. כתוצאה מכך, עומס המעבד יכול לחרוג מהקו המקסימלי של הליבה.
המתנה לקלט/פלט: היחס בין הזמן שלוקח לשאילתות שממתינות לקלט/פלט לבין הזמן שחלף בפועל. ההגדרה 'המתנה ל-IO' כוללת את ההגדרה 'המתנה לקריאת IO' ואת ההגדרה 'המתנה לכתיבת IO'. אפשר לעיין בטבלת האירועים של PostgreSQL. אם רוצים לראות פירוט של מידע על זמני המתנה של קלט/פלט, אפשר לראות אותו ב-Cloud Monitoring. מידע נוסף זמין במאמר בנושא תרשימי מדדים.
המתנה לנעילה: היחס בין הזמן שלוקח לשאילתות להמתין לנעילות לבין הזמן שחלף בפועל. הוא כולל את Lock Waits, LwLock Waits ו-Buffer pin Lock waits. אם רוצים לראות פירוט של מידע על זמן ההמתנה לנעילה, אפשר לראות אותו ב-Cloud Monitoring. מידע נוסף זמין במאמר בנושא תרשימי מדדים.
לאחר מכן, בודקים את הגרף ומשתמשים באפשרויות הסינון כדי לענות על השאלות הבאות:
- האם עומס השאילתות גבוה? האם יש קפיצות או עלייה בגרף לאורך זמן? אם לא מופיע עומס גבוה, הבעיה לא קשורה לשאילתות.
- כמה זמן העומס גבוה? האם המחיר גבוה רק עכשיו? או שהיא גבוהה כבר הרבה זמן? אפשר להשתמש בבחירת הטווח כדי לבחור תקופות זמן שונות ולבדוק כמה זמן הבעיה נמשכת. אפשר גם להתקרב כדי לראות חלון זמן שבו נצפו עליות חדות בעומס השאילתות. אפשר להקטין את התצוגה כדי לראות ציר זמן של עד שבוע.
- מה גורם לעומס הגבוה? אתם יכולים לבחור אפשרויות כדי לראות את קיבולת המעבד, את המעבד ואת זמן ההמתנה של המעבד, את זמן ההמתנה של הנעילה או את זמן ההמתנה של קלט/פלט. התרשים של כל אחת מהאפשרויות האלה מוצג בצבע אחר, כדי שתוכלו לראות לאיזו מהן יש את העומס הכי גבוה. הקו הכחול הכהה בתרשים מראה את קיבולת המעבד המקסימלית של המערכת. אפשר להשוות את עומס השאילתות לקיבולת המקסימלית של מערכת ה-CPU. ההשוואה הזו עוזרת לכם לדעת אם נגמרים המשאבים של יחידת העיבוד המרכזית (CPU) במופע.
- באיזה מסד נתונים העומס גבוה? בוחרים מסדי נתונים שונים מהתפריט הנפתח Databases כדי למצוא את מסדי הנתונים עם העומסים הכי גבוהים.
- האם משתמשים ספציפיים או כתובות IP ספציפיות גורמים לעומסים גבוהים יותר? בוחרים משתמשים וכתובות שונים מהתפריטים הנפתחים כדי להשוות בין העומסים הגבוהים יותר.
סינון של טעינת מסד הנתונים
בקטעים Queries and tags (שאילתות ותגים) אפשר לסנן או למיין את עומס השאילתות לפי שאילתה נבחרת או תג שאילתת SQL.
סינון לפי שאילתות
בטבלה QUERIES מוצגת סקירה כללית של השאילתות שגורמות לעומס השאילתות הגבוה ביותר. בטבלה מוצגות כל השאילתות הנורמליות עבור חלון הזמן והאפשרויות שנבחרו בלוח הבקרה של תובנות לגבי שאילתות.
כברירת מחדל, השאילתות בטבלה ממוינות לפי זמן הביצוע הכולל בחלון הזמן שבחרתם.
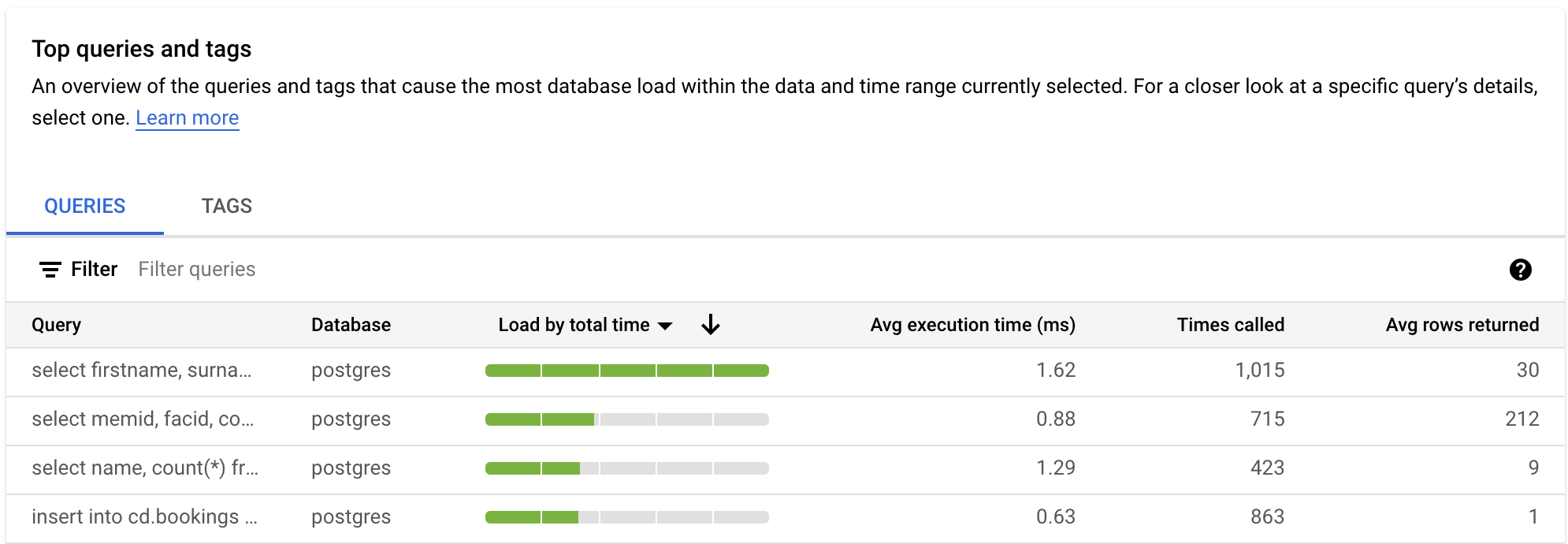
כדי לסנן את הטבלה, בוחרים מאפיין מתוך Filter queries. כדי למיין את הטבלה, בוחרים כותרת של עמודה. הטבלה מציגה את המאפיינים הבאים:
מחרוזת שאילתה. מחרוזת השאילתה שעברה נורמליזציה. כברירת מחדל, בתובנות לגבי שאילתות מוצגים רק 1,024 תווים במחרוזת השאילתה.
שאילתות שמסומנות בתווית
UTILITY COMMANDכוללות בדרך כלל פקודותBEGIN,COMMITו-EXPLAINאו פקודות wrapper.מסד נתונים.מסד הנתונים שהשאילתה הופעלה מולו.
עומס לפי זמן כולל / עומס לפי CPU / עומס לפי זמן המתנה של קלט/פלט / עומס לפי זמן המתנה של נעילה. האפשרויות האלה מאפשרות לסנן שאילתות ספציפיות כדי למצוא את העומס הגדול ביותר לכל אפשרות.
זמן הביצוע הממוצע (באלפיות השנייה). הזמן הכולל שלוקח לכל משימות המשנה בכל העובדים המקבילים להשלים את השאילתה. מידע נוסף זמין במאמר בנושא זמן ביצוע ממוצע ומשך זמן.
מספר הפעמים שהתקשרו. מספר הפעמים שהאפליקציה קראה לשאילתה.
מספר השורות הממוצע שאוחזרו. המספר הממוצע של שורות שאוחזרו עבור השאילתה.
בתובנות לגבי שאילתות מוצגות שאילתות שעברו נרמול, כלומר, הערכים הקבועים המילוליים מוחלפים בערכים $1, $2 וכן הלאה. לדוגמה:
UPDATE
"demo_customer"
SET
"customer_id" = $1::uuid,
"name" = $2,
"address" = $3,
"rating" = $4,
"balance" = $5,
"current_city" = $6,
"current_location" = $7
WHERE
"demo_customer"."id" = $8
הערך של הקבוע מוזנח כדי שתוכלו לראות תובנות לגבי שאילתות, שבהן שאילתות דומות מקובצות ופרטים אישיים מזהים (PII) שמוצגים בקבוע מוסרים.
סינון לפי תגי שאילתות
כדי לפתור בעיות באפליקציה, קודם צריך להוסיף תגים לשאילתות ה-SQL.
התובנות לגבי שאילתות מספקות מעקב ממוקד באפליקציה כדי לאבחן בעיות בביצועים של אפליקציות שנבנו באמצעות ORM.
אם אתם אחראים על כל מחסנית האפליקציות, התובנות לגבי שאילתות מספקות מעקב אחר שאילתות מנקודת מבט של אפליקציה. תיוג שאילתות עוזר לכם למצוא בעיות במבנים ברמה גבוהה יותר, כמו שימוש בלוגיקה עסקית, במיקרו-שירות או במבנה אחר. אתם יכולים לתייג שאילתות לפי הלוגיקה העסקית, למשל, באמצעות התגים payment, inventory, business analytics או shipping. לאחר מכן תוכלו למצוא את עומס השאילתות שנוצר על ידי הסוגים השונים של הלוגיקה העסקית. לדוגמה, תוכלו למצוא אירועים לא צפויים, כמו עליות פתאומיות בתג business analytics בשעה 13:00. לחלופין, תוכלו לראות צמיחה לא צפויה בשירות תשלומים במהלך השבוע הקודם.
תגי עומס של שאילתות מספקים פירוט של עומס השאילתות של התג שנבחר לאורך זמן.
כדי לחשב את עומס מסד הנתונים של התג, התכונה 'תובנות לגבי שאילתות' משתמשת בכמות הזמן שלוקח לכל שאילתה שמשתמשת בתג שבחרתם. התכונה 'תובנות לגבי שאילתות' מחשבת את זמן הסיום בגבול הדקה באמצעות זמן שעון קיר.
במרכז הבקרה של תובנות לגבי שאילתות, לוחצים על תגים כדי לראות את טבלת התגים. בטבלה TAGS התגים ממוינים לפי העומס הכולל שלהם לפי הזמן הכולל.

כדי למיין את הטבלה, בוחרים מאפיין מתוך Filter queries או לוחצים על כותרת של עמודה. הטבלה מציגה את המאפיינים הבאים:
- Action, Controller, Framework, Route, Application, DB Driver. כל נכס שהוספתם לשאילתות מוצג כעמודה. אם רוצים לסנן לפי תגים, צריך להוסיף לפחות אחד מהמאפיינים האלה.
- עומס לפי זמן כולל / עומס לפי CPU / עומס לפי זמן המתנה של קלט/פלט / עומס לפי זמן המתנה של נעילה. האפשרויות האלה מאפשרות לסנן שאילתות ספציפיות כדי למצוא את העומס הגדול ביותר לכל אפשרות.
- זמן הביצוע הממוצע (באלפיות השנייה). הזמן הכולל שלוקח לכל משימות המשנה בכל העובדים המקבילים להשלים את השאילתה. מידע נוסף זמין במאמר בנושא זמן ביצוע ממוצע ומשך זמן.
- מספר הפעמים שהתקשרו. מספר הפעמים שהשאילתה נקראה על ידי האפליקציה.
- מספר השורות הממוצע שאוחזרו. המספר הממוצע של שורות שאוחזרו עבור השאילתה.
- מסד נתונים.מסד הנתונים שהשאילתה הופעלה מולו.
בדיקת שאילתה או תג ספציפיים
כדי לבדוק אם שאילתה או תג הם שורש הבעיה, מבצעים את הפעולות הבאות בכרטיסייה Queries או בכרטיסייה Tags, בהתאם:
- לוחצים על הכותרת טעינה לפי זמן כולל כדי למיין את הרשימה בסדר יורד.
- לוחצים על השאילתה או על התג שנראה שיש לו את העומס הכי גבוה ושזמן הביצוע שלו ארוך יותר משל האחרים.
ייפתח לוח בקרה עם הפרטים של השאילתה או התג שנבחרו.
אם בחרתם שאילתה, מוצג סיכום של השאילתה שנבחרה:

אם בחרתם תג, יוצג לכם סיכום של התג שנבחר.
בדיקת העומס של שאילתה או תג ספציפיים
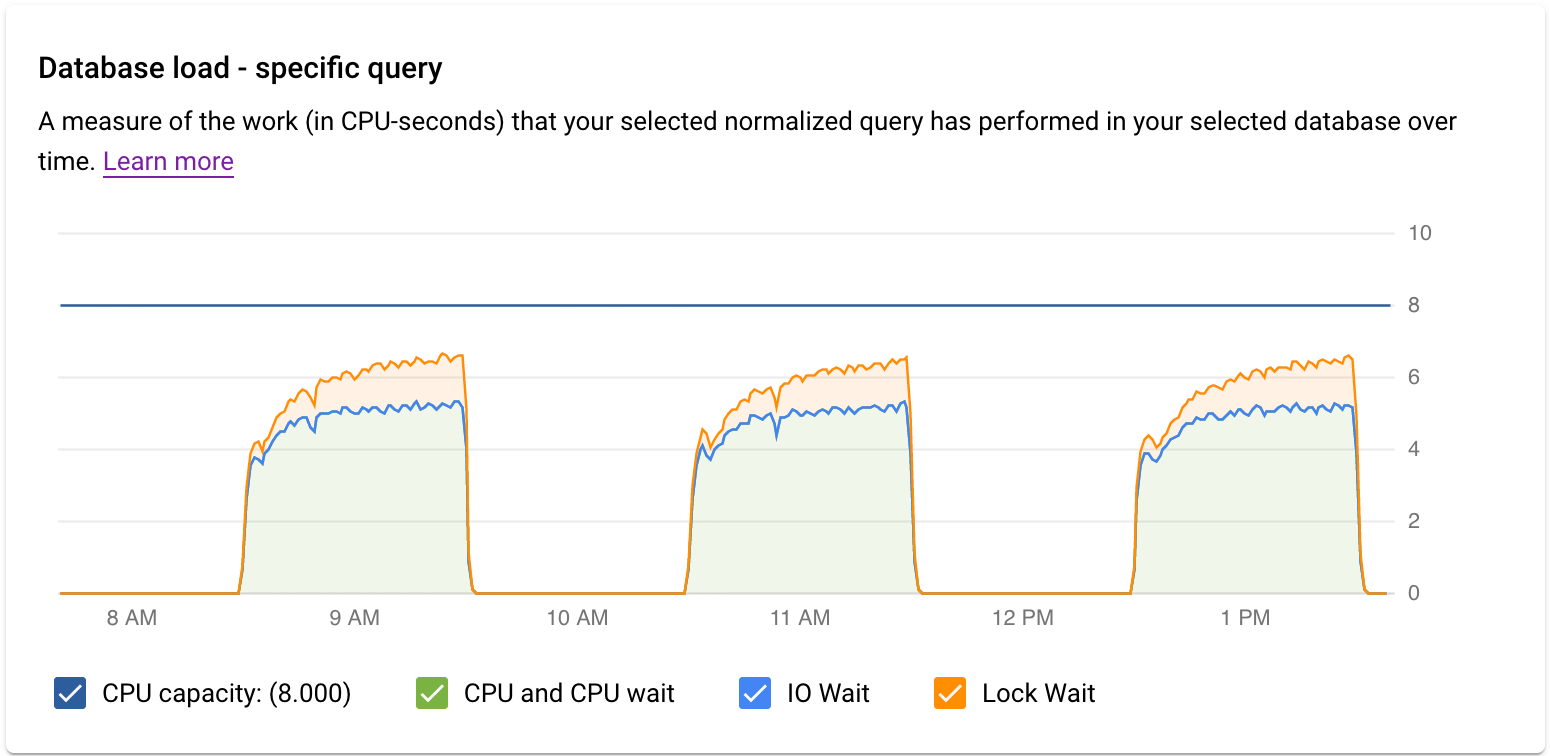
בתרשים Database load — specific query מוצג מדד של העבודה (בשניות CPU) שבוצעה על ידי השאילתה הנורמלית שנבחרה בשאילתה שנבחרה לאורך זמן. כדי לחשב את העומס, המערכת משתמשת בכמות הזמן שלקח לשאילתות הנורמליות שהושלמו בגבול הדקה עד לשעון הקיר. בחלק העליון של הטבלה מוצגים 1,024 התווים הראשונים של השאילתה הנורמלית (שבה הוסרו ליטרלים לצורך צבירה ומטעמי PII). כמו בתרשים של סך השאילתות, אפשר לסנן את העומס של שאילתה ספציפית לפי Database, User ו-Client Address. עומס השאילתה מחולק ל-CPU capacity, CPU and CPU Wait, IO Wait ו-Lock Wait.
בתרשים Database load — specific tags מוצגת מדידה של העבודה (בשניות CPU) שבוצעה במסד הנתונים שנבחר על ידי שאילתות שתואמות לתגים שנבחרו, לאורך זמן. כמו בגרף של סך השאילתות, אפשר לסנן את העומס של תג מסוים לפי מסד נתונים, משתמש וכתובת לקוח.
בדיקת זמן האחזור
משתמשים בתרשים זמן האחזור כדי לבדוק את זמן האחזור של השאילתה או התג. זמן האחזור הוא הזמן שנדרש להשלמת השאילתה הנורמלית, לפי שעון קיר. בלוח הבקרה של זמן האחזור מוצגים זמני האחזור באחוזון ה-50, ה-95 וה-99, כדי לזהות התנהגויות חריגות.
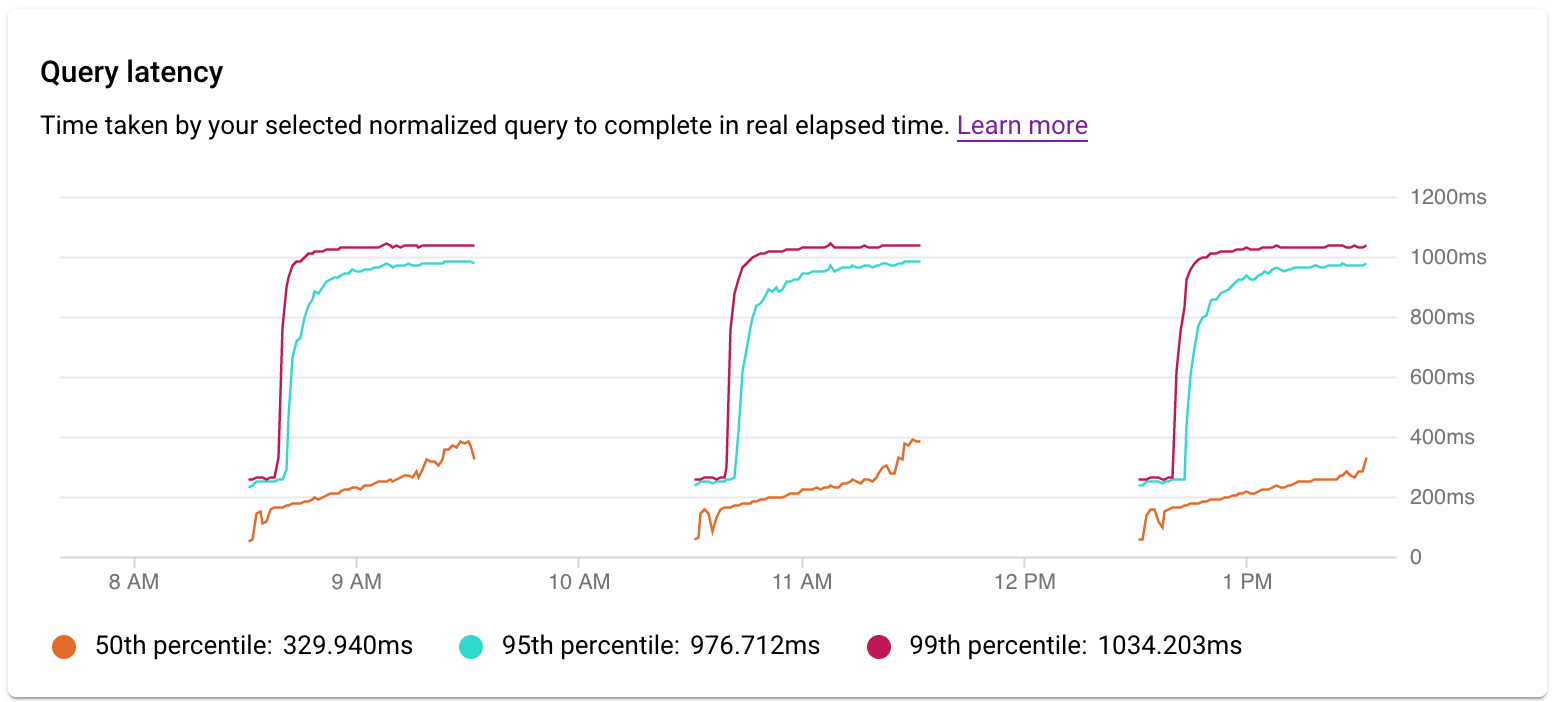
החביון של שאילתות מקבילות נמדד בזמן שעובר בפועל, למרות שעומס השאילתה יכול להיות גבוה יותר כי נעשה שימוש בכמה ליבות כדי להריץ חלק מהשאילתה.
כדי לצמצם את הבעיה, כדאי לבדוק את הדברים הבאים:
- מה גורם לעומס הגבוה? בוחרים אפשרויות כדי לבדוק את קיבולת המעבד, את המעבד ואת זמן ההמתנה של המעבד, את זמן ההמתנה של הנעילה או את זמן ההמתנה של קלט/פלט.
- כמה זמן העומס גבוה? האם המחיר גבוה רק עכשיו? או שהיא גבוהה כבר הרבה זמן? משנים את טווחי הזמן כדי למצוא את התאריך והשעה שבהם הביצועים של העומס התחילו להיות נמוכים.
- היו עליות פתאומיות בזמן האחזור? אפשר לשנות את חלון הזמן כדי לבדוק את זמן האחזור ההיסטורי של השאילתה הנורמלית.
אחרי שמאתרים את האזורים והשעות שבהם העומס הכי גבוה, אפשר להעמיק עוד יותר.
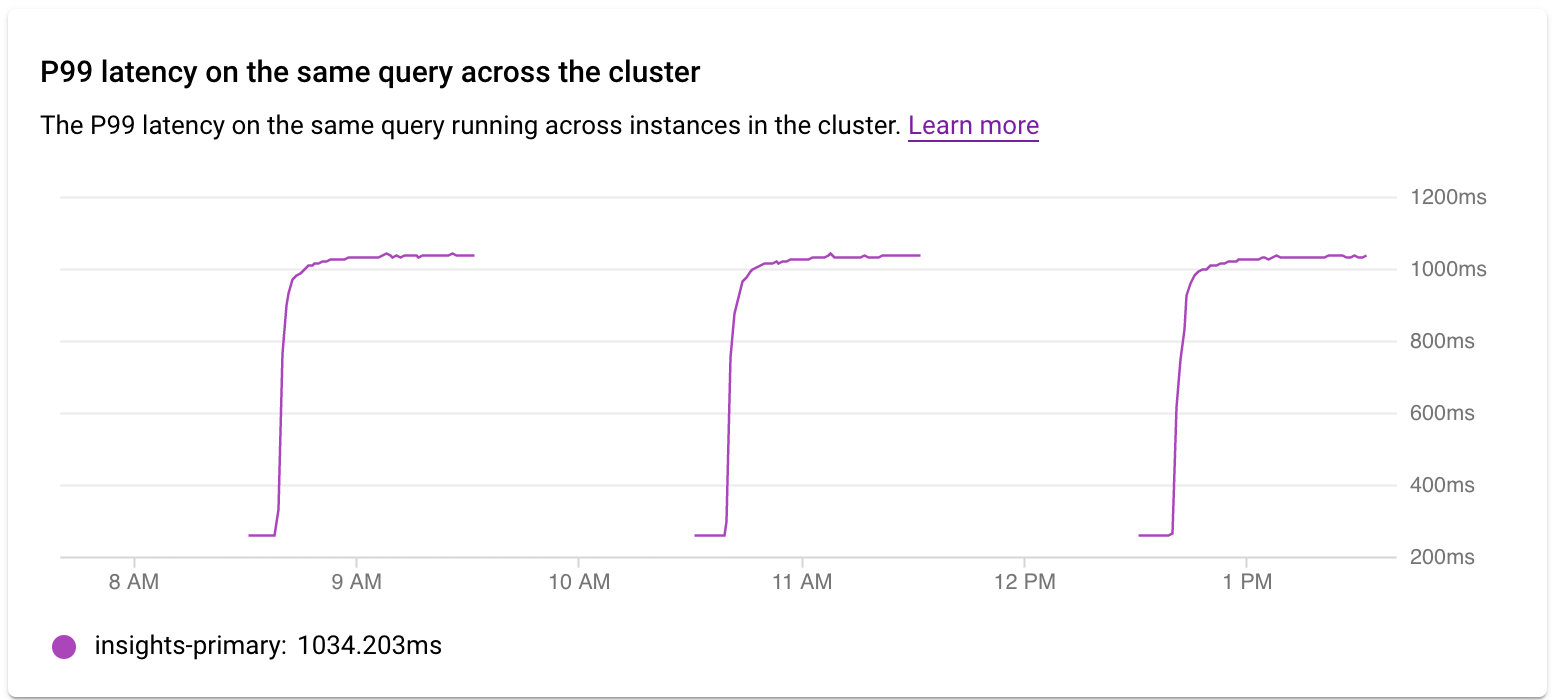
בדיקת זמן האחזור באשכול
אפשר להשתמש בתרשים P99 latency on the same query across the cluster כדי לבדוק את חביון P99 בשאילתה או בתג בכל המופעים באשכול.
בדיקת פעולות בתוכנית שאילתה שנדגמה
תוכנית שאילתה לוקחת מדגם של השאילתה ומפרקת אותה לפעולות נפרדות. הוא מסביר ומנתח כל פעולה בשאילתה. בתרשים Query plan samples מוצגות כל תוכניות השאילתות שפועלות בזמנים מסוימים, ומשך הזמן שלקח לכל תוכנית לפעול.
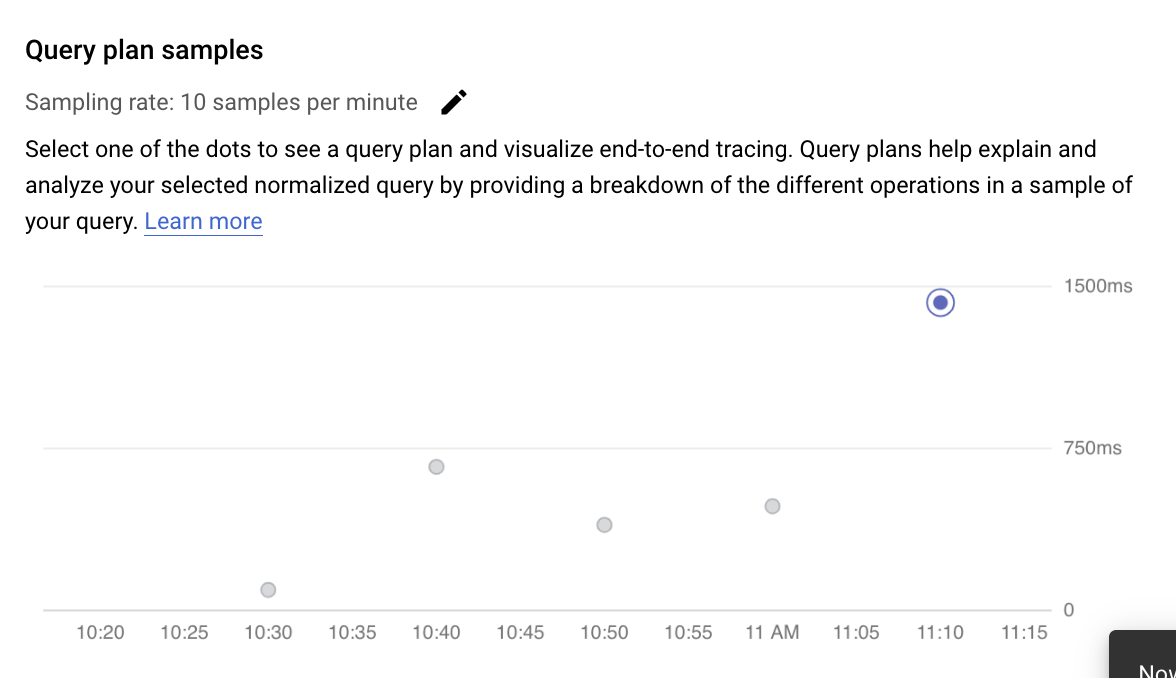
כדי לראות פרטים על תוכנית השאילתות לדוגמה, לוחצים על הנקודות בתרשים Sample query plans. יש תצוגה של תוכניות שאילתות לדוגמה שהופעלו עבור רוב השאילתות, אבל לא עבור כולן. שימו לב ש-AlloyDB ל-PostgreSQL דוגם שאילתות באופן אוטומטי. ככל ששאילתה מופעלת יותר פעמים, כך גדל הסיכוי שהיא תידגם. אם אתם צריכים לראות עוד תוכניות שאילתות לדוגמה, פועלים לפי ההוראות במאמר בנושא עריכת ההגדרה של תובנות לגבי שאילתות כדי להגדיל את קצב הדגימה המקסימלי.
כשמציגים את הפרטים המורחבים של תוכנית שאילתה, רואים מודל של כל הפעולות בתוכנית. בכל פעולה מוצגים זמן האחזור, השורות שהוחזרו והעלות של הפעולה. כשבוחרים פעולה, אפשר לראות פרטים נוספים, כמו בלוקים משותפים של פגיעות, סוג הסכימה, הלולאות בפועל, שורות התוכנית ועוד.
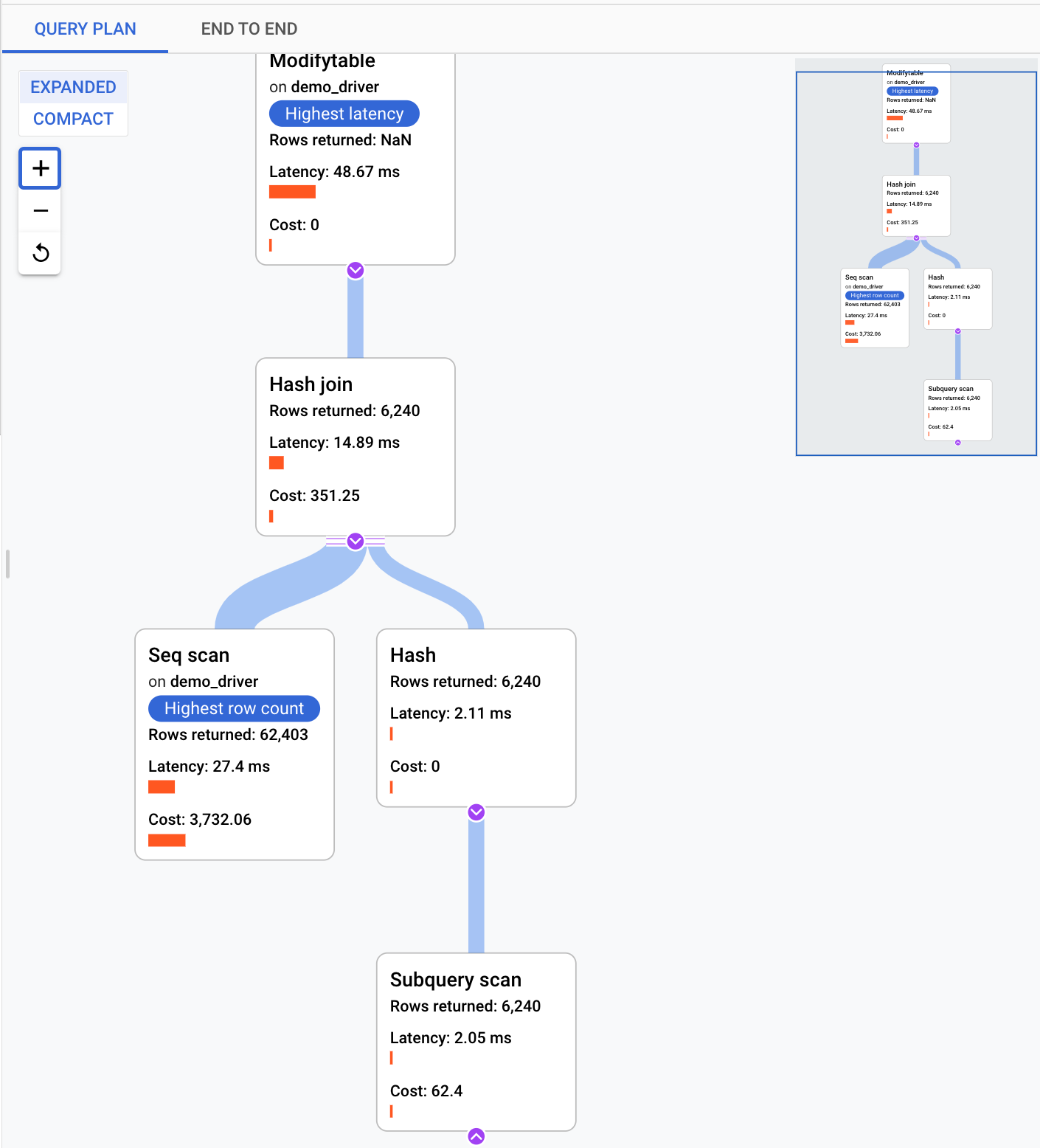
כדי לצמצם את הבעיה, כדאי לעיין בשאלות הבאות:
- מהו צריכת המשאבים?
- איך זה קשור לשאילתות אחרות?
- האם הרגלי הצפייה משתנים לאורך זמן?
בדיקת מעקב שנוצר על ידי שאילתה לדוגמה
בנוסף לצפייה בתוכנית השאילתה לדוגמה, אפשר להשתמש בתובנות לגבי שאילתות כדי לראות מעקב של אפליקציה מקצה לקצה בהקשר של שאילתה לדוגמה. המעקב הזה יכול לעזור לכם לזהות את המקור של שאילתה בעייתית על ידי הצגת פעילות מסד הנתונים עבור בקשה ספציפית. בנוסף, רשומות ביומן שהאפליקציה שולחת ל-Cloud Logging במהלך הבקשה מקושרות למעקב, מה שעוזר לכם בחקירה.
כדי לראות את המעקב בהקשר:
בחלונית Sample Query, לוחצים על הכרטיסייה End-to-end Trace. בכרטיסייה הזו מוצג תרשים גאנט עם פרטים על טווחי הזמן, שהם רשומות של פעולות נפרדות, עבור העקבות שנוצרו על ידי השאילתה.
כדי לראות פרטים נוספים על כל יחידה לוגית למעקב, כמו מאפיינים ומטא-נתונים, לוחצים על היחידה הלוגית למעקב.
אפשר לראות את העקבות גם בדף Trace Explorer. כדי לעשות את זה, לוחצים על הצגה ב-Cloud Trace. פרטים על השימוש בדף Trace Explorer כדי לנתח את נתוני העקבות זמינים במאמר חיפוש עקבות וניתוח שלהם.
הוספת תגים לשאילתות SQL
תיוג של שאילתות SQL מפשט את תהליך פתרון הבעיות באפליקציה. אפשר להשתמש ב-sqlcommenter כדי להוסיף תגים לשאילתות SQL באופן אוטומטי באמצעות מיפוי יחסי בין אובייקטים (ORM), או באופן ידני.
שימוש ב-sqlcommenter עם ORM
כשמשתמשים ב-ORM במקום לכתוב ישירות שאילתות SQL, יכול להיות שלא תמצאו קוד אפליקציה שגורם לבעיות בביצועים. יכול להיות שיהיה לכם קשה לנתח את ההשפעה של קוד האפליקציה על ביצועי השאילתות. כדי לפתור את הבעיה הזו, התובנות לגבי שאילתות מספקות ספרייה בקוד פתוח בשם sqlcommenter, שהיא ספריית מכשור ORM. הספרייה הזו שימושית למפתחים שמשתמשים ב-ORM ולמנהלים כדי לזהות איזה קוד אפליקציה גורם לבעיות בביצועים.
אם אתם משתמשים ב-ORM וב-sqlcommenter ביחד, התגים נוצרים אוטומטית בלי שתצטרכו לשנות או להוסיף קוד מותאם אישית לאפליקציה.
אפשר להתקין את sqlcommenter בשרת האפליקציות. ספריית המדידה מאפשרת להעביר מידע על האפליקציה שקשור למסגרת ה-MVC שלכם למסד הנתונים יחד עם השאילתות כהערת SQL. מסד הנתונים מזהה את התגים האלה ומתחיל לתעד ולצבור נתונים סטטיסטיים לפי תגים, שהם אורתוגונליים לנתונים סטטיסטיים שמצטברים לפי שאילתות מנורמלות. התובנות לגבי השאילתות מציגות את התגים כדי שתדעו איזו אפליקציה גורמת לעומס השאילתות. המידע הזה עוזר לכם לזהות איזה קוד אפליקציה גורם לבעיות בביצועים.
כשבודקים את התוצאות ביומני מסד הנתונים של SQL, הן מופיעות כך:
SELECT * from USERS /*action='run+this',
controller='foo%3',
traceparent='00-01',
tracestate='rojo%2'*/
התגים הנתמכים כוללים את שם הבקר, המסלול, המסגרת והפעולה.
קבוצת ה-ORM ב-sqlcommenter נתמכת בשפות תכנות שונות:
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
מידע נוסף על sqlcommenter ועל אופן השימוש בו במסגרת ORM זמין במאמרי העזרה של sqlcommenter ב-GitHub.
שימוש ב-sqlcommenter כדי להוסיף תגים באופן ידני
אם אתם לא משתמשים ב-ORM, אתם צריכים להוסיף תגי sqlcommenter באופן ידני לשאילתות ה-SQL. בשביל כל הצהרת SQL, צריך להוסיף לשאילתה הערה שמכילה צמד מפתח/ערך שעבר סריאליזציה. משתמשים לפחות באחד מהמקשים הבאים:
action=''controller=''framework=''route=''application=''db driver=''
התכונה 'תובנות לגבי שאילתות' משמיטה את כל המפתחות האחרים. אפשר לעיין בתיעוד של sqlcommenter כדי לראות את הפורמט הנכון של הערות SQL.
זמן ומשך הביצוע
התובנות לגבי שאילתות מספקות את המדד זמן ביצוע ממוצע (אלפיות השנייה), שמציג את הזמן הכולל שנדרש לכל משימות המשנה בכל העובדים המקבילים כדי להשלים את השאילתה. המדד הזה יכול לעזור לכם לבצע אופטימיזציה של השימוש המצטבר במשאבי מסדי הנתונים, על ידי איתור שאילתות שיוצרות את התקורה הגבוהה ביותר של CPU וביצוע אופטימיזציה שלהן.
כדי לראות את הזמן שחלף, אפשר למדוד את משך הזמן של שאילתה על ידי הרצת הפקודה \timing בלקוח psql. הפקודה מודדת את הזמן שחלף בין קבלת השאילתה לבין שליחת תגובה משרת PostgreSQL. המדד הזה יכול לעזור לכם להבין למה שאילתה מסוימת נמשכת יותר מדי זמן, ולהחליט אם כדאי לבצע אופטימיזציה כדי שהיא תפעל מהר יותר.
אם שאילתה מסוימת מושלמת על ידי משימה אחת בשרשור יחיד, משך הזמן וזמן הביצוע הממוצע נשארים זהים.
הפעלת תכונות מתקדמות של תובנות לגבי שאילתות ב-AlloyDB
התכונות המתקדמות של תובנות לגבי שאילתות בלוח הבקרה של AlloyDB משולבות בלוח הבקרה הרגיל של תובנות לגבי שאילתות. מידע נוסף על הפעלת התכונות המתקדמות של ניתוח שאילתות זמין במאמר שיפור הביצועים של שאילתות באמצעות התכונות המתקדמות של ניתוח שאילתות.
המאמרים הבאים
- סקירה כללית על תובנות לגבי שאילתות
- שיפור ביצועי השאילתות באמצעות תכונות מתקדמות של תובנות לגבי שאילתות ב-AlloyDB
- מדדי AlloyDB
- בלוג SQL Commenter: הכרת Sqlcommenter: ספריית קוד פתוח לתיעוד אוטומטי של ORM
- בלוג הדרכה: הפעלת תיוג שאילתות באמצעות Sqlcommenter