
Tutorial ini menjelaskan cara menyiapkan dan melakukan penelusuran vektor di AlloyDB untuk PostgreSQL menggunakan Google Cloud konsol. Contoh disertakan untuk menunjukkan kemampuan penelusuran vektor, dan hanya ditujukan untuk tujuan demonstrasi.
Untuk mengetahui informasi tentang cara menggunakan penelusuran vektor yang difilter untuk menyempurnakan penelusuran kemiripan, lihat Penelusuran vektor yang difilter di AlloyDB untuk PostgreSQL.
Untuk mempelajari cara melakukan penelusuran vektor dengan embedding Vertex AI, lihat Mulai menggunakan Embedding Vektor dengan AlloyDB AI.
Tujuan
- Membuat cluster AlloyDB dan instance utama.
- Menghubungkan ke database dan menginstal ekstensi yang diperlukan.
- Membuat tabel
productdanproduct inventory. - Menyisipkan data ke tabel
productdanproduct inventoryserta melakukan penelusuran vektor dasar. - Membuat indeks ScaNN di tabel produk.
- Melakukan penelusuran vektor dasar.
- Melakukan penelusuran vektor kompleks dengan filter dan gabungan.
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen yang dapat ditagih berikut Google Cloud:
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Setelah menyelesaikan tugas yang dijelaskan dalam dokumen ini, Anda dapat menghindari penagihan berkelanjutan dengan menghapus resource yang Anda buat. Untuk mengetahui informasi selengkapnya, baca bagian Pembersihan.
Sebelum memulai
Mengaktifkan penagihan dan API yang diperlukan
DI konsol, buka halaman Clusters. Google Cloud
Pastikan penagihan diaktifkan untuk Google Cloud project Anda.
Aktifkan Cloud API yang diperlukan untuk membuat dan menghubungkan ke AlloyDB untuk PostgreSQL.
- Pada langkah Confirm project, klik Next untuk mengonfirmasi nama project yang akan Anda ubah.
Pada langkah Enable APIs, klik Enable untuk mengaktifkan hal berikut:
- AlloyDB API
- Compute Engine API
- Service Networking API
- Vertex AI API
Membuat cluster AlloyDB dan instance utama
DI konsol, buka halaman Clusters. Google Cloud
Klik Create cluster.
Di Cluster ID, masukkan
my-cluster.Masukkan sandi. Catat sandi ini karena Anda akan menggunakannya dalam tutorial ini.
Pilih region—misalnya,
us-central1 (Iowa).Pilih jaringan default.
Jika Anda memiliki koneksi akses pribadi, lanjutkan ke langkah berikutnya. Jika tidak, klik Set up connection dan ikuti langkah-langkah berikut:
- Di Allocate an IP range, klik Use an automatically allocated IP range.
- Klik Continue , lalu klik Create connection.
Di Zonal availability, pilih Single zone.
Pilih jenis mesin
2 vCPU,16 GB.Di Connectivity, pilih Enable public IP.
Klik Create cluster. Mungkin perlu waktu beberapa menit agar AlloyDB membuat cluster dan menampilkannya di halaman Overview cluster utama.
Di Instances in your cluster, luaskan panel Connectivity. Catat Connection URI karena Anda akan menggunakannya dalam tutorial ini.
URI koneksi dalam format
projects/<var>PROJECT_ID</var>/locations/<var>REGION_ID</var>/clusters/my-cluster/instances/my-cluster-primary.
Memberikan izin pengguna Vertex AI ke agen layanan AlloyDB
Agar AlloyDB dapat menggunakan model embedding teks Vertex AI, Anda harus menambahkan izin pengguna Vertex AI ke agen layanan AlloyDB untuk project tempat cluster dan instance Anda berada.
Untuk mengetahui informasi selengkapnya tentang cara menambahkan izin, lihat Memberikan izin pengguna Vertex AI ke agen layanan AlloyDB.
Menghubungkan ke database menggunakan browser web
DI konsol, buka halaman Clusters. Google Cloud
Di kolom Resource name, klik nama cluster Anda,
my-cluster.Di panel navigasi, klik AlloyDB Studio.
Di halaman Sign in to AlloyDB Studio, ikuti langkah-langkah berikut:
- Pilih database
postgres. - Pilih pengguna
postgres. - Masukkan sandi yang Anda buat di Membuat cluster dan instance utamanya.
- Klik Authenticate. Panel Explorer menampilkan daftar objek di database
postgres.
- Pilih database
Buka tab baru dengan mengklik + New SQL editor tab atau + New tab.
Menginstal ekstensi yang diperlukan
Jalankan kueri berikut untuk menginstal ekstensi vector dan alloydb_scann:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Menyisipkan data produk dan inventaris produk serta melakukan penelusuran vektor dasar
Jalankan pernyataan berikut untuk membuat tabel
productyang melakukan hal berikut:- Menyimpan informasi produk dasar.
- Menyertakan kolom vektor
embeddingyang menghitung dan menyimpan vektor embedding untuk deskripsi produk setiap produk.
CREATE TABLE product ( id INT PRIMARY KEY, name VARCHAR(255) NOT NULL, description TEXT, category VARCHAR(255), color VARCHAR(255), embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005', description)) STORED );Jika diperlukan, Anda dapat menggunakan Logs Explorer untuk melihat log dan memecahkan masalah error.
Jalankan kueri berikut untuk membuat tabel
product_inventoryyang menyimpan informasi tentang inventaris yang tersedia dan harga yang sesuai. Tabelproduct_inventorydanproductdigunakan dalam tutorial ini untuk menjalankan kueri penelusuran vektor yang kompleks.CREATE TABLE product_inventory ( id INT PRIMARY KEY, product_id INT REFERENCES product(id), inventory INT, price DECIMAL(10,2) );Jalankan kueri berikut untuk menyisipkan data produk ke dalam tabel
product:INSERT INTO product (id, name, description,category, color) VALUES (1, 'Stuffed Elephant', 'Soft plush elephant with floppy ears.', 'Plush Toys', 'Gray'), (2, 'Remote Control Airplane', 'Easy-to-fly remote control airplane.', 'Vehicles', 'Red'), (3, 'Wooden Train Set', 'Classic wooden train set with tracks and trains.', 'Vehicles', 'Multicolor'), (4, 'Kids Tool Set', 'Toy tool set with realistic tools.', 'Pretend Play', 'Multicolor'), (5, 'Play Food Set', 'Set of realistic play food items.', 'Pretend Play', 'Multicolor'), (6, 'Magnetic Tiles', 'Set of colorful magnetic tiles for building.', 'Construction Toys', 'Multicolor'), (7, 'Kids Microscope', 'Microscope for kids with different magnification levels.', 'Educational Toys', 'White'), (8, 'Telescope for Kids', 'Telescope designed for kids to explore the night sky.', 'Educational Toys', 'Blue'), (9, 'Coding Robot', 'Robot that teaches kids basic coding concepts.', 'Educational Toys', 'White'), (10, 'Kids Camera', 'Durable camera for kids to take pictures and videos.', 'Electronics', 'Pink'), (11, 'Walkie Talkies', 'Set of walkie talkies for kids to communicate.', 'Electronics', 'Blue'), (12, 'Karaoke Machine', 'Karaoke machine with built-in microphone and speaker.', 'Electronics', 'Black'), (13, 'Kids Drum Set', 'Drum set designed for kids with adjustable height.', 'Musical Instruments', 'Blue'), (14, 'Kids Guitar', 'Acoustic guitar for kids with nylon strings.', 'Musical Instruments', 'Brown'), (15, 'Kids Keyboard', 'Electronic keyboard with different instrument sounds.', 'Musical Instruments', 'Black'), (16, 'Art Easel', 'Double-sided art easel with chalkboard and whiteboard.', 'Arts & Crafts', 'White'), (17, 'Finger Paints', 'Set of non-toxic finger paints for kids.', 'Arts & Crafts', 'Multicolor'), (18, 'Modeling Clay', 'Set of colorful modeling clay.', 'Arts & Crafts', 'Multicolor'), (19, 'Watercolor Paint Set', 'Watercolor paint set with brushes and palette.', 'Arts & Crafts', 'Multicolor'), (20, 'Beading Kit', 'Kit for making bracelets and necklaces with beads.', 'Arts & Crafts', 'Multicolor'), (21, '3D Puzzle', '3D puzzle of a famous landmark.', 'Puzzles', 'Multicolor'), (22, 'Race Car Track Set', 'Race car track set with cars and accessories.', 'Vehicles', 'Multicolor'), (23, 'RC Monster Truck', 'Remote control monster truck with oversized tires.', 'Vehicles', 'Green'), (24, 'Train Track Expansion Set', 'Expansion set for wooden train tracks.', 'Vehicles', 'Multicolor');Opsional: Jalankan kueri berikut untuk memverifikasi bahwa data disisipkan dalam tabel
product:SELECT * FROM product;Jalankan kueri berikut untuk menyisipkan data inventaris ke dalam tabel
product_inventory:INSERT INTO product_inventory (id, product_id, inventory, price) VALUES (1, 1, 9, 13.09), (2, 2, 40, 79.82), (3, 3, 34, 52.49), (4, 4, 9, 12.03), (5, 5, 36, 71.29), (6, 6, 10, 51.49), (7, 7, 7, 37.35), (8, 8, 6, 10.87), (9, 9, 7, 42.47), (10, 10, 3, 24.35), (11, 11, 4, 10.20), (12, 12, 47, 74.57), (13, 13, 5, 28.54), (14, 14, 11, 25.58), (15, 15, 21, 69.84), (16, 16, 6, 47.73), (17, 17, 26, 81.00), (18, 18, 11, 91.60), (19, 19, 8, 78.53), (20, 20, 43, 84.33), (21, 21, 46, 90.01), (22, 22, 6, 49.82), (23, 23, 37, 50.20), (24, 24, 27, 99.27);Jalankan kueri penelusuran vektor berikut yang mencoba menemukan produk yang mirip dengan kata
music. Artinya, meskipun katamusictidak disebutkan secara eksplisit dalam deskripsi produk, hasilnya akan menampilkan produk yang relevan dengan kueri:SELECT * FROM product ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector LIMIT 3;Hasil kueri adalah sebagai berikut:
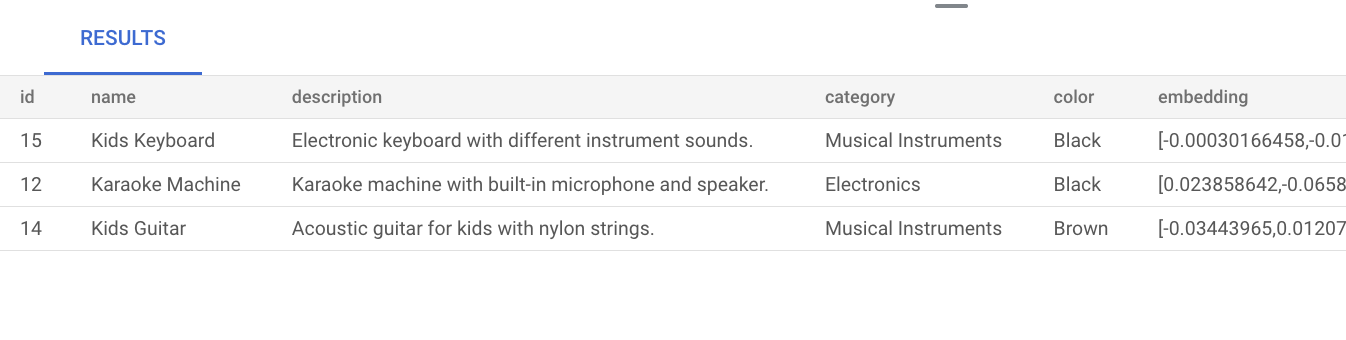
Melakukan penelusuran vektor dasar tanpa membuat indeks menggunakan penelusuran tetangga terdekat yang tepat (KNN), yang memberikan recall yang efisien. Dalam skala besar, penggunaan KNN dapat memengaruhi performa. Untuk performa kueri yang lebih baik, sebaiknya gunakan indeks ScaNN untuk penelusuran perkiraan tetangga terdekat (ANN), yang memberikan recall tinggi dengan latensi rendah.
Tanpa membuat indeks, AlloyDB akan menggunakan penelusuran tetangga terdekat yang tepat (KNN) secara default.
Untuk mempelajari lebih lanjut cara menggunakan ScaNN dalam skala besar, lihat Mulai menggunakan Embedding Vektor dengan AlloyDB AI.
Membuat indeks ScaNN yang disesuaikan secara manual di tabel produk
Jalankan kueri berikut untuk membuat indeks ScaNN product_index di tabel product:
CREATE INDEX product_index ON product
USING scann (embedding cosine)
WITH (mode='MANUAL', num_leaves=4);
Untuk mengetahui informasi selengkapnya tentang cara membuat indeks ScaNN, lihat Membuat indeks ScaNN.
Melakukan penelusuran vektor
Jalankan kueri penelusuran vektor berikut yang mencoba menemukan produk yang mirip dengan kueri bahasa natural
music. Meskipun kata music tidak disertakan dalam
deskripsi produk, hasilnya akan menampilkan produk yang relevan dengan kueri:
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
Hasil kueri adalah sebagai berikut:

Parameter kueri scann.num_leaves_to_search mengontrol jumlah node daun yang ditelusuri selama penelusuran kemiripan. Nilai parameter num_leaves dan
scann.num_leaves_to_search membantu mencapai keseimbangan
performa dan recall.
Melakukan penelusuran vektor yang menggunakan filter dan gabungan
Anda dapat menjalankan kueri penelusuran vektor yang difilter secara efisien meskipun menggunakan indeks ScaNN. Jalankan kueri penelusuran vektor kompleks berikut, yang menampilkan hasil relevan yang memenuhi kondisi kueri, bahkan dengan filter:
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product p
JOIN product_inventory pi ON p.id = pi.product_id
WHERE pi.price < 80.00
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
Mempercepat penelusuran vektor yang difilter
Anda dapat menggunakan penyimpanan konten columnar engine untuk meningkatkan performa penelusuran kemiripan vektor, khususnya penelusuran Tetangga Terdekat (KNN), jika dikombinasikan dengan pemfilteran predikat yang sangat selektif—misalnya, menggunakan LIKE—dalam database. Di bagian ini, Anda akan menggunakan ekstensi vector dan
AlloyDB
google_columnar_engine ekstensi.
Untuk mengetahui informasi selengkapnya tentang cara kerja columnar engine, lihat
Tentang columnar engine AlloyDB.
Peningkatan performa berasal dari efisiensi bawaan columnar engine dalam memindai set data besar dan menerapkan filter—seperti predikat LIKE—yang dipadukan dengan kemampuannya, menggunakan dukungan vektor, untuk melakukan pra-filter baris. Fungsi ini mengurangi jumlah subset data yang diperlukan untuk perhitungan jarak vektor KNN berikutnya, dan membantu mengoptimalkan kueri analisis kompleks yang melibatkan pemfilteran standar dan penelusuran vektor.
Penyimpanan columnar menawarkan dua opsi untuk mengelola kontennya:
- Mengelola konten penyimpanan kolom secara otomatis: instance AlloyDB baru menggunakan kolom otomatis secara default. Atau, Anda dapat menjalankan fungsi kolom otomatis secara manual.
- Mengelola konten penyimpanan kolom secara manual: jika perlu mengelola kolom di penyimpanan kolom secara manual untuk workload Anda, Anda dapat menonaktifkan kolom otomatis.
Untuk membandingkan waktu eksekusi penelusuran vektor KNN yang difilter oleh predikat LIKE sebelum dan sesudah Anda mengaktifkan columnar engine, ikuti langkah-langkah berikut:
Aktifkan ekstensi
vectoruntuk mendukung jenis dan operasi data vektor. Jalankan pernyataan berikut untuk membuat tabel contoh (item) dengan ID, deskripsi teks, dan kolom embedding vektor 512 dimensi.CREATE EXTENSION IF NOT EXISTS vector; CREATE TABLE items ( id SERIAL PRIMARY KEY, description TEXT, embedding VECTOR(512) );Isi data dengan menjalankan pernyataan berikut untuk menyisipkan 1 juta baris ke dalam tabel
itemscontoh.-- Simplified example of inserting matching (~0.1%) and non-matching data INSERT INTO items (description, embedding) SELECT CASE WHEN g % 1000 = 0 THEN 'product_' || md5(random()::text) || '_common' -- ~0.1% match ELSE 'generic_item_' || g || '_' || md5(random()::text) -- ~99.9% don't match END, random_vector(512) -- Assumes random_vector function exists FROM generate_series(1, 999999) g;Ukur performa dasar penelusuran kemiripan vektor tanpa columnar engine.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;Aktifkan columnar engine dan dukungan vektor dengan menjalankan perintah berikut di Google Cloud CLI. Untuk menggunakan gcloud CLI, Anda dapat menginstal dan melakukan inisialisasi gcloud CLI.
gcloud beta alloydb instances update INSTANCE_ID \ --cluster=CLUSTER_ID \ --region=REGION_ID \ --project=PROJECT_ID \ --database-flags=google_columnar_engine.enabled=on,google_columnar_engine.enable_vector_support=onGanti kode berikut:
INSTANCE_ID: ID instance.CLUSTER_ID: ID cluster.REGION_ID: region tempat cluster berada.PROJECT_ID: ID project tempat cluster berada.
Tambahkan tabel
itemske columnar engine:SELECT google_columnar_engine_add('items');Ukur performa penelusuran kemiripan vektor menggunakan columnar engine. Anda menjalankan kembali kueri yang sebelumnya Anda jalankan untuk mengukur performa dasar.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;Untuk memeriksa apakah kueri berjalan dengan columnar engine, jalankan perintah berikut:
explain (analyze) SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;
Pembersihan
DI konsol, buka halaman Clusters. Google Cloud
Klik nama cluster Anda,
my-cluster, di kolom Resource name.Klik delete Delete cluster.
Di Delete cluster my-cluster, masukkan
my-clusteruntuk mengonfirmasi bahwa Anda ingin menghapus cluster.Klik Delete.
Jika Anda membuat koneksi pribadi saat Anda membuat cluster, buka Google Cloud konsol halaman Networking dan klik Delete VPC network.
Langkah berikutnya
- Pelajari kasus penggunaan penelusuran vektor di dunia nyata.
- Mulai menggunakan embedding vektor menggunakan AlloyDB AI.
- Pelajari cara membuat aplikasi AI generatif menggunakan AlloyDB AI.
- Buat indeks ScaNN.
- Sesuaikan indeks ScaNN Anda.
- Pelajari cara membuat asisten belanja cerdas dengan AlloyDB, pgvector, dan pengelolaan endpoint model.
- Percepat penelusuran vektor dengan columnar engine.