
AI Hypercomputer היא מערכת מחשוב-על שעוזרת לכם לפרוס עומסי עבודה של בינה מלאכותית (AI) ולמידת מכונה (ML) במכונות GPU מרובות. שירותי הרשת הבסיסיים שבהם אתם משתמשים בפריסה נקבעים לפי סוג המכונה עם GPU שבחרתם.
המסמך הזה מיועד לאדריכלים, למהנדסי רשת ולמפתחים, כדי לעזור להם להבין את שירותי הרשת הבסיסיים שקשורים למכונות GPU. ההנחה במסמך הזה היא שיש לכם היכרות בסיסית עם רישות בענן ועם מושגים של מחשוב מבוזר.
הבנה של שירותי הרשת של מכונות ה-GPU היא השלב הראשון בפריסה ובניהול מוצלחים של עומסי העבודה, והיא חיונית לאופטימיזציה של הביצועים ושל התפוקה. המדד 'קצב העברת נתונים יעיל' (goodput) מודד את ההתקדמות האפקטיבית של מערכת במשימת אימון של ML. המדד הזה מספק תובנות נוספות בהשוואה למדדים כמו סך הזמן שחלף או קצב העברת הנתונים הגולמי.
חלק מסוגי המכונות של GPU כוללים היררכיה מובחנת ושכבתית שמבצעת אופטימיזציה של התקשורת בכל רמה. ההיררכיה הזו נעה בין רשת מרכז הנתונים לבין אשכולות שעברו אופטימיזציה ל-AI ומופעים של Compute Engine. בקטעים הבאים מוסבר על הרכיבים ההיררכיים האלה.
ארכיטקטורת רשת GPU
AI Hypercomputer עוזר לכם לפרוס מכונות GPU שמשתמשות בארכיטקטורת רשת היררכית ומותאמת למסילות. העיצוב הזה מאפשר קישוריות צפויה וביצועים גבוהים, ומצמצם את התקורה של התקשורת. כך הוא משפר ישירות את קצב העברת הנתונים (goodput), כי המעבדים הגרפיים יכולים להקדיש יותר זמן לחישובים במקום לחכות לנתונים.
הסידור של יחידות ה-GPU בארכיטקטורת rail-aligned מורכב משלושה רכיבים עיקריים:
- תתי-בלוקים: אלה יחידות בסיסיות שמורכבות מקבוצה של מארחים שממוקמים פיזית באותו מתקן. מתג ToR (Top-of-Rack) מחבר בין המארחים האלה, ומאפשר תקשורת יעילה במיוחד של קפיצה אחת בין כל שני מעבדים גרפיים בתוך תת-הבלוק. RDMA over Converged Ethernet (RoCE) מאפשר תקשורת ישירה כזו. ספריית NCCL משופרת שעברה אופטימיזציה לטופולוגיה של Google שמתאימה למסילות, מטפלת בקולקטיבים של תקשורת בין מעבדי GPU.
- בלוקים: הבלוקים מורכבים מכמה תת-בלוקים שמחוברים ביניהם באמצעות בד לא חוסם, שמאפשר חיבור עם רוחב פס גבוה. כל יחידת GPU בבלוק ניתנת להגעה בתוך שני קפיצות רשת לכל היותר. המערכת חושפת מטא-נתונים של בלוקים ותתי-בלוקים כדי לאפשר מיקום אופטימלי של משימות.
- אשכולות: אשכולות נוצרים על ידי כמה בלוקים שמחוברים ביניהם, והם יכולים להתרחב לאלפי מעבדי GPU. הם מאפשרים להריץ עומסי עבודה של אימון בקנה מידה גדול. התקשורת בין בלוקים שונים מוסיפה רק צעד אחד נוסף, כך שהביצועים והיכולת לחזות את התוצאות נשמרים ברמה גבוהה גם בהיקף גדול מאוד. כדי לאפשר הצבה חכמה של משרות בהיקף גדול, מטא-נתונים ברמת האשכול זמינים גם למנהלי התזמור.
טכנולוגיות לתקשורת בין GPU
מכונות עם מעבד גרפי משתמשות בשילוב של טכנולוגיות כדי לספק ביצועים גבוהים, תפוקה גבוהה וזמן אחזור נמוך לעומסי עבודה. הטכנולוגיות האלה כוללות RDMA over Converged Ethernet (RoCE), כרטיסי רשת של NVIDIA וטופולוגיית רשת של Google בארכיטקטורת rail-aligned שמתאימה לכל מרכז הנתונים.
סוגי המכונות האלה משתמשים בטכנולוגיית NVLink של NVIDIA כדי ליצור נתיבי נתונים ישירים במהירות גבוהה במיוחד בין כרטיסי ה-NIC של NVIDIA בכל מכונה. בנוסף, פרוטוקול RoCE מאפשר RDMA יעיל בין יחידות GPU במכונות שונות.
ערימות נטוורקינג של GPU
מערך פרוטוקולים לרשת הוא אוסף של פרוטוקולי תוכנה, דרייברים ושכבות שפועלים יחד כדי להטמיע תקשורת בין GPU ל-GPU. סוגים שונים של מכונות GPU משתמשים בסטאקים שונים של רשתות. בטבלה הבאה מוגדרות ערימות הרשת וסוגי המכונות שמשויכים אליהן:
| רשימת רשתות בתהליך בחירת הרשת | תיאור | סוג מכונה עם GPU |
|---|---|---|
| GPUDirect RDMA | GPUDirect RDMA מאפשר נתיב ישיר להחלפת נתונים בין GPU למכשיר אחר. במקרים של A4X Max ו-A4X, מערך הרשת הזה משתמש ב-RDMA over Converged Ethernet (RoCE). הטכנולוגיה הזו מאפשרת למכשירים עמיתים לקרוא ולכתוב ישירות בזיכרון של ה-GPU, בלי לעבור דרך ה-CPU, וכך ליצור חיבור יעיל יותר להחלפת נתונים עם ביצועים גבוהים. מידע נוסף זמין במאמר בנושא אפשרויות להגדרת אשכול עם GPUDirect RDMA. | |
| GPUDirect-TCPXO | GPUDirect-TCPXO הוא שיפור של GPUDirect-TCPX, שמתבטא בהעברת העומס של פרוטוקול TCP. באמצעות GPUDirect-TCPXO, סוג המכונה A3 Mega מכפיל את רוחב הפס של הרשת בהשוואה לסוגי המכונות A3 High ו-A3 Edge. מידע על מיקסום רוחב הפס של הרשת באשכולות GKE שמשתמשים ב-GPUDirect-TCPXO זמין במאמר מיקסום רוחב הפס של רשת ה-GPU באשכולות במצב רגיל. צריך לבחור בכרטיסייה GPUDirect-TCPXO. | |
| GPUDirect-TCPX | GPUDirect-TCPX משפר את ביצועי הרשת בכך שהוא מאפשר להעביר את המטען הייעודי (payload) של מנות הנתונים ישירות מזיכרון ה-GPU לממשק הרשת. מידע על מיקסום רוחב הפס של הרשת באשכולות GKE שמשתמשים ב-GPUDirect-TCPX זמין במאמר מיקסום רוחב הפס של רשת ה-GPU באשכולות במצב רגיל. צריך לבחור בכרטיסייה GPUDirect-TCPX. |
רשת מישור הנתונים של המארח והאחסון
נתיב רשת נפרד מטפל בכל התנועה שאינה תקשורת ישירה בין מעבדי GPU. התעבורה הזו כוללת גישה ל-Cloud Storage, ניהול ברמת המארח ותקשורת עם שירותים אחרים של Google Cloud . כדי לנהל את התנועה הזו, סוגי המכונות עם GPU משתמשים בכרטיסי רשת של Google Titanium.
כרטיסי רשת של Titanium מעבירים משימות עיבוד ברשת מהמעבד, וכך מאפשרים למעבד להתמקד בעומסי העבודה. ההפרדה הזו מבטיחה שתנועה למטרות כלליות ותנועה ייעודית מ-GPU ל-GPU ישתמשו בממשקים פיזיים שונים, וכך לא יתחרו על אותם משאבי מערכת.
סביבת Multi-VPC
כל עומסי העבודה פועלים בענן הווירטואלי הפרטי (VPC) של Google Cloud.
מכונות עם מאיץ ביצועים גבוהות כוללות עיצוב חומרה מיוחד שמשתמש בכמה ממשקי רשת פיזיים כדי לטפל בסוגים שונים של תעבורה. כדי לטפל בעיצוב החומרה המיוחד הזה, נדרשת סביבת VPC מרובה, ללא קשר לשאלה אם משתמשים ב-Slurm, ב-GKE או ב-Compute Engine כדי להריץ את עומסי העבודה.
ההגדרה הספציפית של כמה רשתות VPC תלויה בסוג מכונת ה-GPU ובמערך הרשת שלה:
A4X Max, A4X, A4 ו-A3 Ultra עם GPUDirect RDMA: המכונות האלה משתמשות ברשת ה-VPC שמוגדרת כברירת מחדל לתעבורת נתונים של מארח למטרות כלליות (gVNIC), ונדרשת רשת VPC נוספת לתעבורת נתונים של מארח למטרות כלליות, ורשת VPC משותפת אחת לתעבורת נתונים מ-GPU ל-GPU. צריך להפעיל את פרופיל רשת RDMA ב-VPC של תנועת ה-GPU. מידע נוסף על ההגדרה הזו למכונות וירטואליות מסוג A4 ולמכונות וירטואליות מסוג A3 Ultra זמין במאמר יצירת VPC ורשתות משנה.
A3 Mega עם GPUDirect-TCPXO: המכונות האלה דורשות שמונה רשתות VPC נפרדות עבור כרטיסי ה-NIC של ה-GPU, שמוקדשים לתקשורת עם רוחב פס גבוה. שלבים מפורטים להשלמת ההגדרה הזו מופיעים במאמר יצירה של רשתות VPC ורשתות משנה.
A3 High עם GPUDirect-TCPX: המכונות האלה דורשות ארבעה רשתות VPC נפרדות עבור כרטיסי ה-NIC של ה-GPU, שמוקדשים לתקשורת עם רוחב פס גבוה. שלבים מפורטים להשלמת ההגדרה הזו מופיעים במאמר יצירה של רשתות VPC ורשתות משנה.
ההגדרה הזו של כמה VPC מבטיחה שפעולות אחסון ומשימות מערכת אחרות לא יתחרו על רוחב הפס עם תקשורת קריטית בין GPU ל-GPU.
הגדרת הרשת הנדרשת של כמה רשתות VPC שצריך להגדיר משתנה בהתאם לסוג מכונת ה-GPU. מדריך מפורט בנושא סידור הרשת, מהירויות רוחב הפס וכרטיסי רשת לכל סוגי המכונות הנתמכים עם GPU זמין במאמר רשתות ומכונות עם GPU.
בתרשים הבא מוצגת ארכיטקטורת הרשת של מכונת GPU, עם הדגשה של ההפרדה בין תנועה למטרות כלליות לבין תנועה ייעודית מ-GPU ל-GPU במישורים שונים של הרשת.
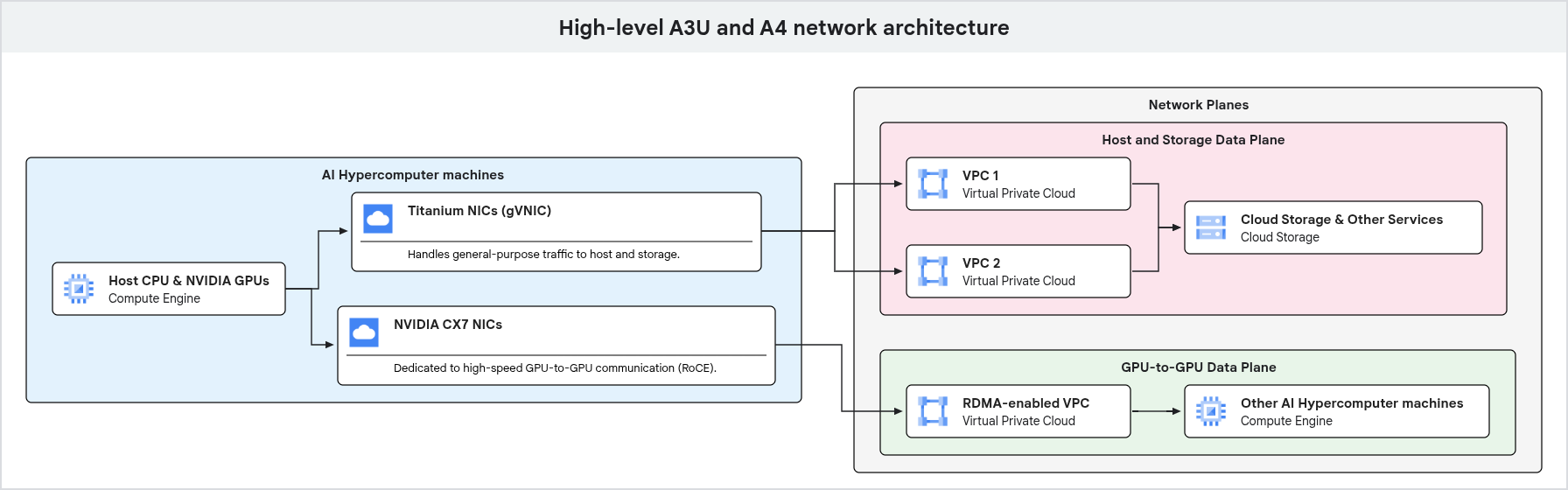
כפי שמוצג בתרשים הקודם, מכונות ה-GPU משתמשות בנתיבי רשת ייעודיים לסוגים שונים של תעבורה. תעבורה למטרות כלליות, כולל גישה לניהול ולאחסון, עוברת דרך כרטיסי רשת של Google Titanium שמחוברים ל-VPC. תקשורת GPU ל-GPU עם ביצועים גבוהים משתמשת בממשקי רשת נפרדים וב-VPC, שעברו אופטימיזציה באמצעות טכנולוגיות כמו RDMA, כדי להבטיח רוחב פס גבוה וחביון נמוך לעומסי עבודה של AI ו-ML.
ספריות ורכיבים של רשתות
כדי למקסם את רוחב הפס והביצועים של הרשת, אפשר להשתמש בספריות ובמרכיבים הבאים של הרשת כדי להשתמש במעבדי GPU עם מחסנית הרשת של Google:
- gVNIC: Google Virtual NIC (gVNIC) הוא ממשק רשת וירטואלי שנועד במיוחד ל-Compute Engine. gVNIC משפר את הביצועים, מגביר את העקביות ומפחית את הבעיות שנובעות משימוש במשאבים משותפים. היא נתמכת ומומלצת בכל משפחות המכונות, סוגי המכונות והדורות, והיא ה-vNIC המומלץ לתקשורת בין מחשבים מארחים. מידע נוסף זמין במאמר בנושא שימוש בממשק רשת וירטואלי של Google.
- NCCL: ספריית NVIDIA Collective Communications Library (NCCL) מספקת פרימיטיבים אופטימליים לפעולות תקשורת קולקטיביות. היא מיועדת במיוחד לסביבות מרובות GPU ומרובות צמתים, שבהן נעשה שימוש ב-GPU וברשתות של NVIDIA. מריצים בדיקות NCCL כדי להעריך את הביצועים של אשכולות שנפרסו. מידע נוסף זמין במאמר פריסה והפעלה של בדיקת NCCCL.
- ריבוי רשתות ב-GKE: תמיכה בריבוי רשתות עבור Pods מאפשרת שימוש בכמה ממשקים בצמתים וב-Pods באשכול GKE. פרטים על הגדרת ריבוי רשתות בהקשר של GPUDirect זמינים במאמרים Maximize GPU network bandwidth in Standard mode clusters ו-Cluster configuration options with GPUDirect RDMA.
לפרטים נוספים על חבילות התוכנה שזמינות, אפשר לעיין במאמר תמונות של מערכות הפעלה ו-Docker.
המאמרים הבאים
- מידע על שירותי רשת לפריסות של אשכולות ומכונות וירטואליות
- שיטות מומלצות לשימוש ברשת ב-AI Hypercomputer
- מידע נוסף על סוגי מכונות עם GPU ועל שירותי אחסון ל-AI Hypercomputer.