
AI Hypercomputer est un système de supercalcul qui vous aide à déployer des charges de travail d'intelligence artificielle (IA) et de machine learning (ML) multihôtes à l'aide de machines GPU. Les services réseau sous-jacents que vous utilisez dans le déploiement sont déterminés par le type de machine GPU que vous choisissez.
Ce document est destiné à aider les architectes, les ingénieurs réseau et les développeurs à comprendre les services réseau sous-jacents liés aux machines GPU. Dans ce document, nous partons du principe que vous connaissez les concepts de base des réseaux cloud et de l'informatique distribuée.
Comprendre les services de mise en réseau des machines GPU est la première étape pour déployer et gérer efficacement vos charges de travail. C'est également essentiel pour optimiser les performances et le débit utile. Le débit utile mesure la progression effective d'un système sur une tâche d'entraînement de ML. Cette métrique offre des insights supplémentaires par rapport à des métriques telles que le temps total écoulé ou le débit brut.
Certains types de machines GPU présentent une hiérarchie distincte et multicouche qui optimise la communication à tous les niveaux. Cette hiérarchie s'étend de la structure du centre de données aux clusters optimisés pour l'IA et aux instances Compute Engine. Les sections suivantes expliquent ces composants hiérarchiques.
Architecture du réseau de GPU
AI Hypercomputer vous aide à déployer des machines GPU qui utilisent une architecture réseau hiérarchique et alignée sur les rails. La connectivité prévisible et performante de cette conception réduit au maximum la surcharge de communication, ce qui améliore directement le débit utile en permettant aux GPU de consacrer plus de temps au calcul plutôt qu'à l'attente des données.
L'arrangement des GPU alignés sur rails se compose de trois éléments principaux :
- Sous-blocs : il s'agit d'unités de base, qui sont constituées d'un groupe d'hôtes physiquement regroupés dans un même rack. Un commutateur de haut de rack (ToR, top-of-rack) connecte ces hôtes, ce qui permet une communication extrêmement efficace à saut unique entre deux GPU quelconques dans le sous-bloc. RDMA (Remote Direct Memory Access) over Converged Ethernet (RoCE) facilite cette communication directe. Une bibliothèque NCCL améliorée et optimisée pour la topologie alignée sur rails de Google gère les collectifs de communication GPU.
- Blocs : ils sont composés de plusieurs sous-blocs interconnectés avec une structure non bloquante, ce qui permet une interconnexion à haut débit. Tout GPU d'un bloc est accessible en deux sauts réseau maximum. Le système expose les métadonnées des blocs et des sous-blocs pour permettre un placement optimal des jobs.
- Clusters : ils sont formés de plusieurs blocs interconnectés, dont la taille peut atteindre plusieurs milliers de GPU. Ils vous permettent d'exécuter des charges de travail d'entraînement à grande échelle. La communication entre les différents blocs n'ajoute qu'un seul saut supplémentaire, ce qui maintient la prévisibilité et les performances élevées, même à grande échelle. Pour permettre un placement intelligent des jobs à grande échelle, des métadonnées au niveau du cluster sont également disponibles pour les orchestrateurs.
Technologies de communication entre les GPU
Les machines GPU utilisent une combinaison de technologies pour fournir des performances élevées, un débit élevé et une faible latence pour les charges de travail. Parmi ces technologies, citons RDMA over Converged Ethernet (RoCE), les cartes d'interface réseau NVIDIA et la topologie de réseau alignée sur rails à l'échelle du centre de données de Google.
Ces types de machines utilisent la technologie NVLink de NVIDIA pour créer des chemins de données directs à très haut débit entre les cartes d'interface réseau NVIDIA de chaque machine. De plus, RoCE permet une communication RDMA efficace entre les GPU sur différentes machines.
Piles réseau GPU
Une pile réseau est une collection de protocoles logiciels, de pilotes et de couches qui fonctionnent ensemble pour implémenter la communication entre les GPU. Différents types de machines GPU utilisent différentes piles réseau. Le tableau suivant définit les piles réseau et les types de machines associés :
| Pile Mise en réseau | Description | Type de machine GPU |
|---|---|---|
| GPUDirect RDMA | GPUDirect RDMA permet un chemin direct pour l'échange de données entre un GPU et un autre appareil. Pour les instances A4X Max et A4X, cette pile réseau utilise RDMA over Converged Ethernet (RoCE). Cette technologie permet aux appareils pairs de lire et d'écrire directement dans la mémoire du GPU, en contournant le processeur pour créer une connexion plus efficace pour l'échange de données à hautes performances. Pour en savoir plus, consultez Options de configuration des clusters avec GPUDirect RDMA. | |
| GPUDirect-TCPXO | GPUDirect-TCPXO améliore GPUDirect-TCPX en déchargeant le protocole TCP. Grâce à GPUDirect-TCPXO, le type de machine A3 Mega offre le double de la bande passante réseau proposée par les types de machines A3 High et A3 Edge. Pour savoir comment maximiser la bande passante réseau sur les clusters GKE qui utilisent GPUDirect-TCPXO, consultez Maximiser la bande passante réseau des GPU dans les clusters en mode Standard, puis sélectionnez l'onglet "GPUDirect-TCPXO". | |
| GPUDirect-TCPX | GPUDirect-TCPX améliore les performances réseau en permettant aux charges utiles des paquets de données d'être transférées directement de la mémoire GPU vers l'interface réseau. Pour savoir comment maximiser la bande passante réseau sur les clusters GKE qui utilisent GPUDirect-TCPX, consultez Maximiser la bande passante réseau des GPU dans les clusters en mode Standard, puis sélectionnez l'onglet GPUDirect-TCPX. |
Réseau du plan de données hôte et de stockage
un chemin réseau distinct gère tout le trafic autre que les communications directes entre les GPU. Ce trafic inclut l'accès à Cloud Storage, la gestion au niveau de l'hôte et la communication avec d'autres services Google Cloud . Pour gérer ce trafic, les types de machines GPU utilisent des cartes d'interface réseau Google Titanium.
Les cartes d'interface réseau Titanium déchargent les tâches de traitement réseau du processeur, ce qui permet à ce dernier de se concentrer sur vos charges de travail. Cette séparation garantit que le trafic à usage général et le trafic GPU à GPU dédié utilisent des interfaces physiques différentes, ce qui les empêche de se faire concurrence pour les mêmes ressources système.
Environnement multi-VPC
Toutes les charges de travail fonctionnent dans le cloud privé virtuel (VPC) de Google Cloud.
Les machines à accélérateurs hautes performances sont dotées d'une conception matérielle spécialisée qui utilise plusieurs interfaces réseau physiques pour gérer différents types de trafic. Pour gérer cette conception matérielle spécialisée, un environnement multi-VPC est nécessaire, que vous utilisiez Slurm, GKE ou Compute Engine pour exécuter vos charges de travail.
La configuration multi-VPC spécifique dépend du type de machine GPU et de sa pile réseau :
A4X Max, A4X, A4 et A3 Ultra avec GPUDirect RDMA : ces machines utilisent le réseau VPC par défaut pour le trafic hôte à usage général (gVNIC). Elles nécessitent un réseau VPC supplémentaire pour le trafic hôte à usage général et un réseau VPC partagé pour tout le trafic de GPU à GPU. Le réseau VPC de trafic GPU doit avoir le profil réseau RDMA activé. Pour en savoir plus sur cette configuration pour les VM A4 et A3 Ultra, consultez Créer un VPC et des sous-réseaux.
A3 Mega avec GPUDirect-TCPXO : ces machines nécessitent huit VPC distincts pour les cartes d'interface réseau GPU, qui sont dédiées à la communication à bande passante élevée. Pour obtenir des instructions détaillées sur la façon de procéder, consultez Créer des VPC et des sous-réseaux.
A3 High avec GPUDirect-TCPX : ces machines nécessitent quatre VPC distincts pour les cartes réseau GPU, qui sont dédiées à la communication à bande passante élevée. Pour obtenir des instructions détaillées sur la façon de réaliser cette configuration, consultez Créer des VPC et des sous-réseaux.
Cette configuration multi-VPC garantit que les opérations de stockage et les autres tâches système ne sont pas en concurrence pour la bande passante avec les communications critiques entre GPU.
La configuration réseau multi-VPC requise que vous devez configurer diffère selon votre type de machine GPU. Pour obtenir un guide détaillé sur la configuration réseau, les débits de bande passante et les cartes d'interface réseau pour tous les types de machines GPU compatibles, consultez Mise en réseau et machines GPU.
Le schéma suivant illustre l'architecture réseau d'une machine GPU, en mettant en évidence la séparation du trafic à usage général et du trafic GPU à GPU dédié sur différents plans de réseau.
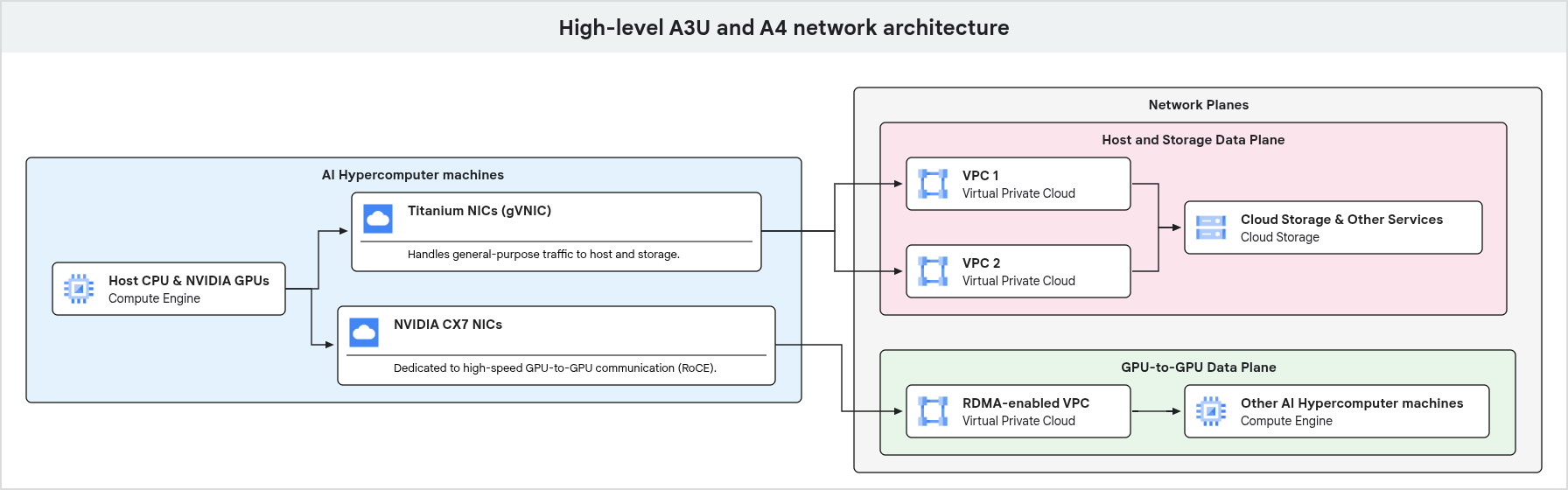
Comme illustré dans le schéma précédent, les machines GPU utilisent des chemins réseau dédiés pour différents types de trafic. Le trafic à usage général, y compris l'accès à la gestion et au stockage, transite par des cartes d'interface réseau Google Titanium connectées à un VPC. La communication hautes performances entre les GPU utilise des interfaces réseau et des VPC distincts, optimisés avec des technologies telles que RDMA, ce qui garantit une bande passante élevée et une faible latence pour les charges de travail d'IA et de ML.
Bibliothèques et composants de mise en réseau
Pour maximiser la bande passante et les performances réseau, les bibliothèques et composants réseau suivants vous permettent d'utiliser des GPU avec la pile réseau de Google :
- gVNIC : la carte d'interface réseau virtuelle Google (gVNIC) est une interface de réseau virtuel spécialement conçue pour Compute Engine. Elle améliore les performances, augmente la cohérence et réduit les problèmes de voisinage bruyant. Il est compatible et recommandé avec toutes les familles de machines, tous les types de machines et toutes les générations. Il s'agit de la vNIC recommandée pour la communication d'hôte à hôte. Pour en savoir plus, consultez Utiliser la carte d'interface réseau virtuelle Google.
- NCCL : la bibliothèque NVIDIA Collective Communications Library (NCCL) fournit des primitives optimisées pour les opérations de communication collective. Elle est spécifiquement conçue pour les environnements multi-GPU et multi-nœuds, à l'aide des GPU et du réseau NVIDIA. Exécutez des tests NCCL pour évaluer les performances des clusters déployés. Pour en savoir plus, consultez Déployer et exécuter un test NCCL.
- Multiréseau GKE : la compatibilité multiréseau des pods permet d'utiliser plusieurs interfaces sur les nœuds et les pods d'un cluster GKE. Pour savoir comment configurer le multiréseau dans le contexte de GPUDirect, consultez Maximiser la bande passante réseau des GPU dans les clusters en mode Standard et Options de configuration des clusters avec GPUDirect RDMA.
Pour en savoir plus sur les piles logicielles disponibles, consultez Images d'OS et Docker.
Étapes suivantes
- En savoir plus sur les services réseau pour les déploiements de clusters et de VM
- Découvrez les bonnes pratiques de mise en réseau dans AI Hypercomputer.
- Découvrez les types de machines GPU et les services de stockage pour AI Hypercomputer.