
Gemini Enterprise Agent Platform Vision 앱에 BigQuery 커넥터를 추가하면 연결된 모든 앱 모델 출력이 대상 테이블로 수집됩니다.
자체 BigQuery 테이블을 만들고 앱에 BigQuery 커넥터를 추가할 때 해당 테이블을 지정하거나 Gemini Enterprise Agent Platform Vision 앱 플랫폼에서 테이블을 자동으로 만들도록 할 수 있습니다.
자동 테이블 생성
Gemini Enterprise Agent Platform Vision 앱 플랫폼에서 테이블을 자동으로 만들도록 하는 경우 BigQuery 커넥터 노드를 추가할 때 이 옵션을 지정할 수 있습니다.
자동 테이블 생성을 사용하려면 다음 데이터 세트 및 테이블 조건이 적용됩니다.
- 데이터 세트: 자동으로 생성되는 데이터 세트 이름은
visionai_dataset입니다. - 테이블: 자동으로 생성되는 테이블 이름은
visionai_dataset.APPLICATION_ID입니다. 오류 처리:
- 동일한 데이터 세트 아래에 동일한 이름의 테이블이 있으면 자동 생성이 발생하지 않습니다.
콘솔
Gemini Enterprise Agent Platform Vision 대시보드의 애플리케이션 탭을 엽니다.
목록에서 애플리케이션 이름 옆에 있는 앱 보기 를 선택합니다.
애플리케이션 빌더 페이지의 커넥터 섹션에서 BigQuery 를 선택합니다.
BigQuery 경로 필드를 비워 둡니다.
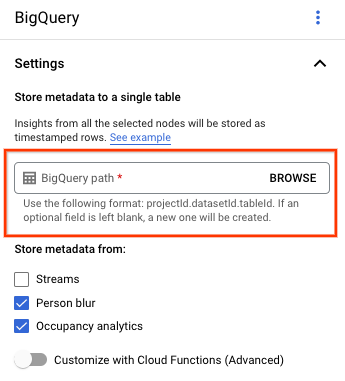
다른 설정을 변경합니다.
REST 및 명령줄
앱 플랫폼에서 테이블 스키마를 유추하도록 하려면 앱을 만들거나 업데이트할 때 BigQueryConfig
의
createDefaultTableIfNotExists 필드를 사용합니다.
테이블 수동으로 만들기 및 지정
출력 테이블을 수동으로 관리하려면 테이블에 테이블 스키마의 하위 집합으로 필수 스키마가 있어야 합니다.
기존 테이블에 호환되지 않는 스키마가 있으면 배포가 거부됩니다.
기본 스키마 사용
모델 출력 테이블에 기본 스키마를 사용하는 경우 테이블에 다음 필수 열만 포함되어 있는지 확인합니다. BigQuery 테이블을 만들 때 다음 스키마 텍스트를 직접 복사할 수 있습니다. BigQuery 테이블 만들기에 대한 자세한 내용은 테이블 만들기 및 사용을 참조하세요. 테이블을 만들 때 스키마 지정에 대한 자세한 내용은 스키마 지정을 참조하세요.
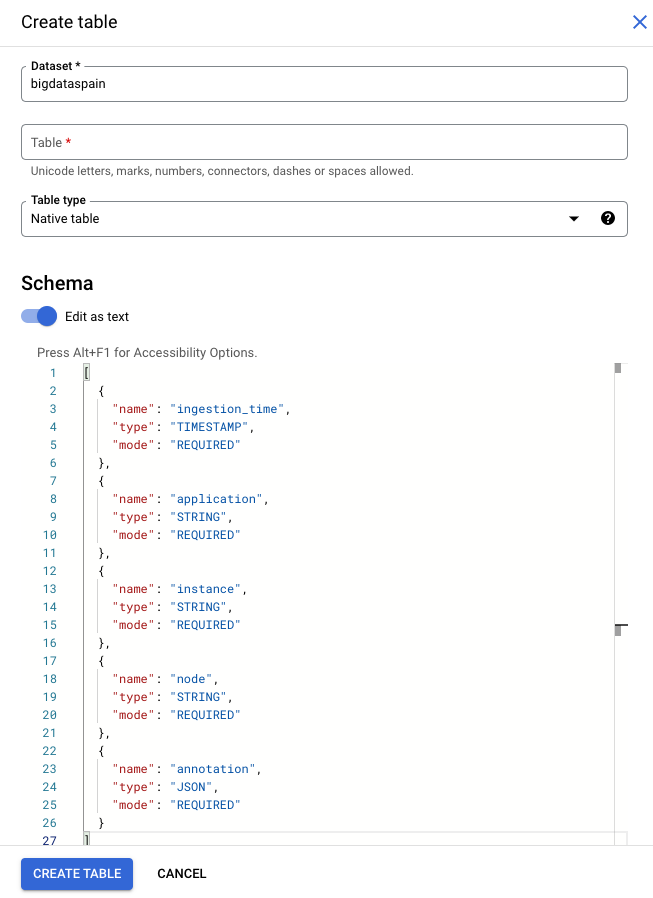
테이블을 만들 때 다음 텍스트를 사용하여 스키마를 설명합니다.
`JSON` 열 유형
("type": "JSON") 사용에 대한 자세한 내용은 표준 SQL에서 JSON 데이터 작업을 참조하세요.
JSON 열 유형은 주석 쿼리에 권장됩니다.
"type" : "STRING"을 사용할 수도 있습니다.
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "application",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "instance",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "node",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "annotation",
"type": "JSON",
"mode": "REQUIRED"
}
]
Google Cloud 콘솔
콘솔에서 Google Cloud BigQuery 페이지로 이동합니다.
프로젝트를 선택합니다.
옵션 더보기 를 선택합니다.
테이블 만들기 를 클릭합니다.
'스키마' 섹션에서 텍스트로 편집을 사용 설정합니다.
gcloud
다음 예시에서는 먼저 요청 JSON 파일을 만든 다음
gcloud alpha bq tables create 명령어를 사용합니다.
먼저 요청 JSON 파일을 만듭니다.
echo "{ \"schema\": [ { \"name\": \"ingestion_time\", \"type\": \"TIMESTAMP\", \"mode\": \"REQUIRED\" }, { \"name\": \"application\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"instance\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"node\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"annotation\", \"type\": \"JSON\", \"mode\": \"REQUIRED\" } ] } " >> bigquery_schema.jsongcloud명령어를 전송합니다. 다음을 바꿉니다.TABLE_NAME: 테이블의 ID 또는 테이블의 정규화된 식별자
DATASET: BigQuery 데이터 세트의 ID
gcloud alpha bq tables create TABLE_NAME \ --dataset=DATASET \ --schema-file=./bigquery_schema.json
Gemini Enterprise Agent Platform Vision 앱에서 생성된 BigQuery 행 샘플:
| ingestion_time | 애플리케이션 | 인스턴스 | 노드 | 주석 |
|---|---|---|---|---|
| 2022-05-11 23:3211.911378 UTC | my_application | 5 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE1Eg5teV9hcHBsaWNhdGlvbgjS+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911338 UTC | my_application | 1 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgExEg5teV9hcHBsaWNhdGlvbgiq+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911313 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgiR+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3212.235327 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgi/3J3Ozdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
맞춤설정된 스키마 사용
기본 스키마가 사용 사례에 적합하지 않은 경우 Cloud Run Functions를 사용하여 사용자 정의 스키마로 BigQuery 행을 생성할 수 있습니다. 커스텀 스키마를 사용하는 경우 BigQuery 테이블 스키마에 대한 기본 요건이 없습니다.
BigQuery 노드가 선택된 앱 그래프
BigQuery 커넥터는 동영상 또는 프로토 기반 주석을 출력하는 모든 모델에 연결할 수 있습니다.
- 동영상 입력의 경우 BigQuery 커넥터는 스트림 헤더에 저장된 메타데이터만 추출하고 이 데이터를 다른 모델 주석 출력으로 BigQuery에 수집합니다. 동영상 자체는 저장되지 않습니다.
- 스트림에 메타데이터가 없으면 BigQuery에 아무것도 저장되지 않습니다.
테이블 데이터 쿼리
기본 BigQuery 테이블 스키마를 사용하면 테이블에 데이터가 채워진 후 강력한 분석을 실행할 수 있습니다.
샘플 쿼리
BigQuery에서 다음 샘플 쿼리를 사용하여 Gemini Enterprise Agent Platform Vision 모델에서 통계를 얻을 수 있습니다.
예를 들어 BigQuery를 사용하여 다음 쿼리로 사람 / 차량 감지기 모델의 데이터를 사용하여 분당 감지된 최대 사람 수에 대한 시간 기반 곡선을 그릴 수 있습니다.
WITH nested3 AS( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["fullFrameCount"]) AS counts FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT ingestion_time, e FROM nested, UNNEST(nested.counts) AS e) SELECT STRING(TIMESTAMP_TRUNC(nested2.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested2.e["count"]), 0) AS person_count FROM nested2 WHERE JSON_VALUE(nested2.e["entity"]["labelString"])="Person") SELECT time, MAX(person_count) FROM nested3 GROUP BY time
마찬가지로 BigQuery와 점유 분석 모델의 교차 선 수 기능 으로 분당 교차 선을 통과하는 총 차량 수를 계산하는 쿼리를 만들 수 있습니다.
WITH nested4 AS ( WITH nested3 AS ( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["crossingLineCounts"]) AS lines FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT nested.ingestion_time, JSON_QUERY_ARRAY(line["positiveDirectionCounts"]) AS entities FROM nested, UNNEST(nested.lines) AS line WHERE JSON_VALUE(line.annotation.id) = "LINE_ANNOTATION_ID") SELECT ingestion_time, entity FROM nested2, UNNEST(nested2.entities) AS entity ) SELECT STRING(TIMESTAMP_TRUNC(nested3.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested3.entity["count"]), 0) AS vehicle_count FROM nested3 WHERE JSON_VALUE(nested3.entity["entity"]["labelString"])="Vehicle" ) SELECT time, SUM(vehicle_count) FROM nested4 GROUP BY time
쿼리 실행
Google 표준 SQL 쿼리의 형식을 지정한 후 콘솔을 사용하여 쿼리를 실행할 수 있습니다.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
데이터 세트 이름 옆에 있는 펼치기 를 선택하고 테이블 이름을 선택합니다.
테이블 세부정보 뷰에서 새 쿼리 작성을 클릭합니다.

쿼리 편집기 텍스트 영역에 Google 표준 SQL 쿼리를 입력합니다. 쿼리 예시는 샘플 쿼리를 참조하세요.
선택사항: 데이터 처리 위치를 변경하려면 수정 > 쿼리 설정을 클릭합니다. 처리 위치에서 자동 선택을 클릭하고 데이터의 위치를 선택합니다. 마지막으로 저장 을 클릭하여 쿼리 설정을 업데이트합니다.
실행을 클릭합니다.
그러면 임시 테이블에 출력을 쓰는 쿼리 작업이 생성됩니다.
Cloud Run Functions 통합
Cloud Run Functions를 사용하여 맞춤설정된 BigQuery 수집으로 추가 데이터 처리를 트리거할 수 있습니다. 맞춤설정된 BigQuery 수집에 Cloud Run Functions를 사용하려면 다음 단계를 따르세요.
콘솔을 사용하는 경우 연결된 각 모델의 드롭다운 메뉴에서 해당하는 Cloud 함수를 선택합니다. Google Cloud
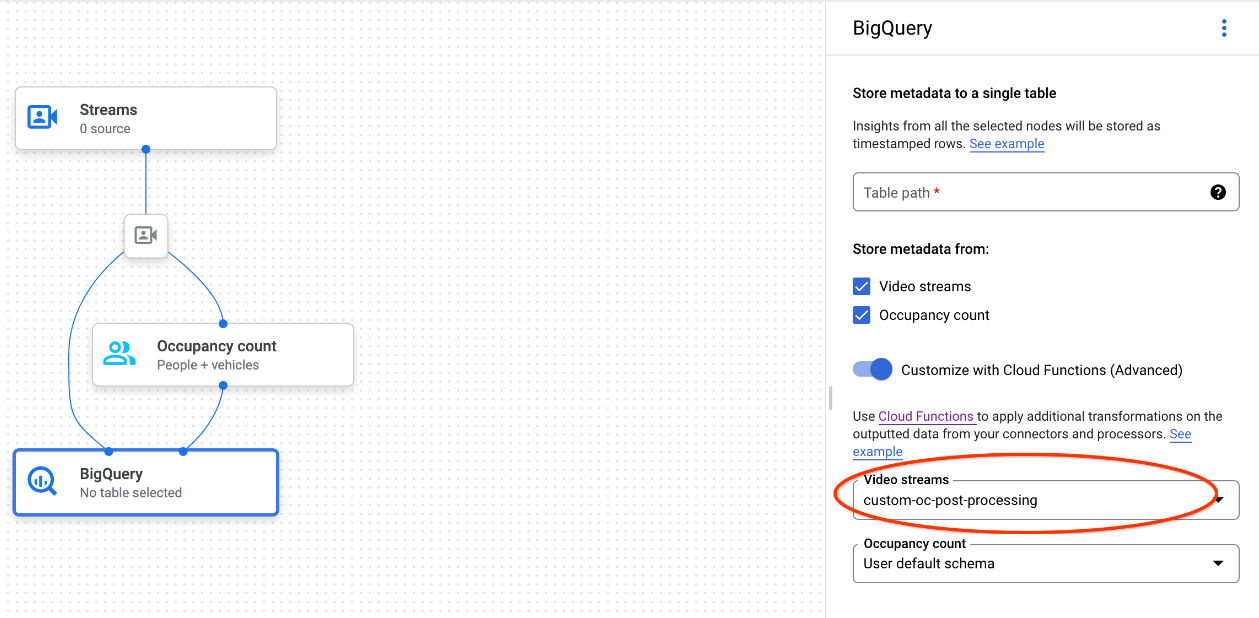
Gemini Enterprise Agent Platform Vision API를 사용하는 경우 BigQuery 노드의
cloud_function_mapping필드에BigQueryConfig키-값 쌍 하나를 추가합니다. 키는 BigQuery 노드 이름이고 값은 대상 함수의 HTTP 트리거입니다.
맞춤설정된 BigQuery 수집에 Cloud Run Functions를 사용하려면 함수가 다음 요구사항을 충족해야 합니다.
- BigQuery 노드를 만들기 전에 Cloud Run Functions 인스턴스를 만들어야 합니다.
- Gemini Enterprise Agent Platform Vision API는
AppendRowsRequestCloud Run Functions에서 반환된 주석을 수신할 것으로 예상합니다. - 모든
CloudFunction응답에proto_rows.writer_schema필드를 설정해야 합니다.write_stream은 무시해도 됩니다.
Cloud Run Functions 통합 예시
다음 예시에서는 점유 수 노드 출력(OccupancyCountPredictionResult)을 파싱하고 여기에서 ingestion_time, person_count, vehicle_count 테이블 스키마를 추출하는 방법을 보여줍니다.
다음 샘플의 결과는 스키마가 있는 BigQuery 테이블입니다.
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "person_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "vehicle_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
]
다음 코드를 사용하여 이 테이블을 만듭니다.
작성할 테이블 필드의 프로토콜 버퍼 (예:
test_table_schema.proto)를 정의합니다.syntax = "proto3"; package visionai.testing; message TestTableSchema { int64 ingestion_time = 1; int32 person_count = 2; int32 vehicle_count = 3; }프로토콜 버퍼 파일을 컴파일하여 프로토콜 버퍼 Python 파일을 생성합니다.
protoc -I=./ --python_out=./ ./test_table_schema.proto생성된 Python 파일을 가져오고 Cloud 함수를 작성합니다.
Python
import base64 import sys from flask import jsonify import functions_framework from google.protobuf import descriptor_pb2 from google.protobuf.json_format import MessageToDict import test_table_schema_pb2 def table_schema(): schema = descriptor_pb2.DescriptorProto() test_table_schema_pb2.DESCRIPTOR.message_types_by_name[ 'TestTableSchema'].CopyToProto(schema) return schema def bigquery_append_row_request(row): append_row_request = {} append_row_request['protoRows'] = { 'writerSchema': { 'protoDescriptor': MessageToDict(table_schema()) }, 'rows': { 'serializedRows': base64.b64encode(row.SerializeToString()).decode('utf-8') } } return append_row_request @functions_framework.http def hello_http(request): request_json = request.get_json(silent=False) annotations = [] payloads = [] if request_json and 'annotations' in request_json: for annotation_with_timestamp in request_json['annotations']: row = test_table_schema_pb2.TestTableSchema() row.person_count = 0 row.vehicle_count = 0 if 'ingestionTimeMicros' in annotation_with_timestamp: row.ingestion_time = int( annotation_with_timestamp['ingestionTimeMicros']) if 'annotation' in annotation_with_timestamp: annotation = annotation_with_timestamp['annotation'] if 'stats' in annotation: stats = annotation['stats'] for count in stats['fullFrameCount']: if count['entity']['labelString'] == 'Person': if 'count' in count: row.person_count = count['count'] elif count['entity']['labelString'] == 'Vehicle': if 'count' in count: row.vehicle_count = count['count'] payloads.append(bigquery_append_row_request(row)) for payload in payloads: annotations.append({'annotation': payload}) return jsonify(annotations=annotations)
Cloud Run Functions에 종속 항목을 포함하려면 생성된
test_table_schema_pb2.py파일도 업로드하고 다음과 같이requirements.txt를 지정해야 합니다.functions-framework==3.* click==7.1.2 cloudevents==1.2.0 deprecation==2.1.0 Flask==1.1.2 gunicorn==20.0.4 itsdangerous==1.1.0 Jinja2==2.11.2 MarkupSafe==1.1.1 pathtools==0.1.2 watchdog==1.0.2 Werkzeug==1.0.1 protobuf==3.12.2Cloud 함수를 배포하고 해당하는 HTTP 트리거를
BigQueryConfig에서 설정합니다.