
Quando aggiungi un connettore BigQuery all'app Vision della piattaforma agentica Gemini Enterprise, tutti gli output del modello dell'app connessa vengono importati nella tabella di destinazione.
Puoi creare la tua tabella BigQuery e specificarla quando aggiungi un connettore BigQuery all'app oppure lasciare che la piattaforma dell'app Vision della piattaforma agentica Gemini Enterprise crei automaticamente la tabella.
Creazione automatica della tabella
Se consenti alla piattaforma dell'app Vision della piattaforma agentica Gemini Enterprise di creare automaticamente la tabella, puoi specificare questa opzione quando aggiungi il nodo del connettore BigQuery.
Se vuoi utilizzare la creazione automatica della tabella, si applicano le seguenti condizioni per il set di dati e la tabella:
- Set di dati: il nome del set di dati creato automaticamente è
visionai_dataset. - Tabella: il nome della tabella creata automaticamente è
visionai_dataset.APPLICATION_ID. Gestione degli errori:
- Se esiste già una tabella con lo stesso nome nello stesso set di dati, non viene eseguita la creazione automatica.
Console
Apri la scheda Applicazioni della dashboard Vision della piattaforma agentica Gemini Enterprise.
Seleziona Visualizza app accanto al nome dell'applicazione nell'elenco.
Nella pagina del builder di applicazioni, seleziona BigQuery nella sezione Connettori.
Lascia vuoto il campo Percorso BigQuery.
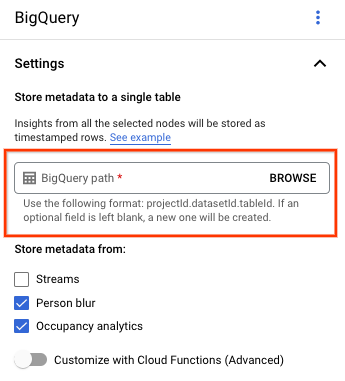
Modifica le altre impostazioni.
REST e riga di comando
Per consentire alla piattaforma dell'app di dedurre uno schema della tabella, utilizza il
createDefaultTableIfNotExists campo di BigQueryConfig
quando crei o aggiorni un'app.
Creare e specificare manualmente una tabella
Se vuoi gestire manualmente la tabella di output, la tabella deve avere lo schema richiesto come sottoinsieme dello schema della tabella.
Se la tabella esistente ha schemi incompatibili, il deployment viene rifiutato.
Utilizzare lo schema predefinito
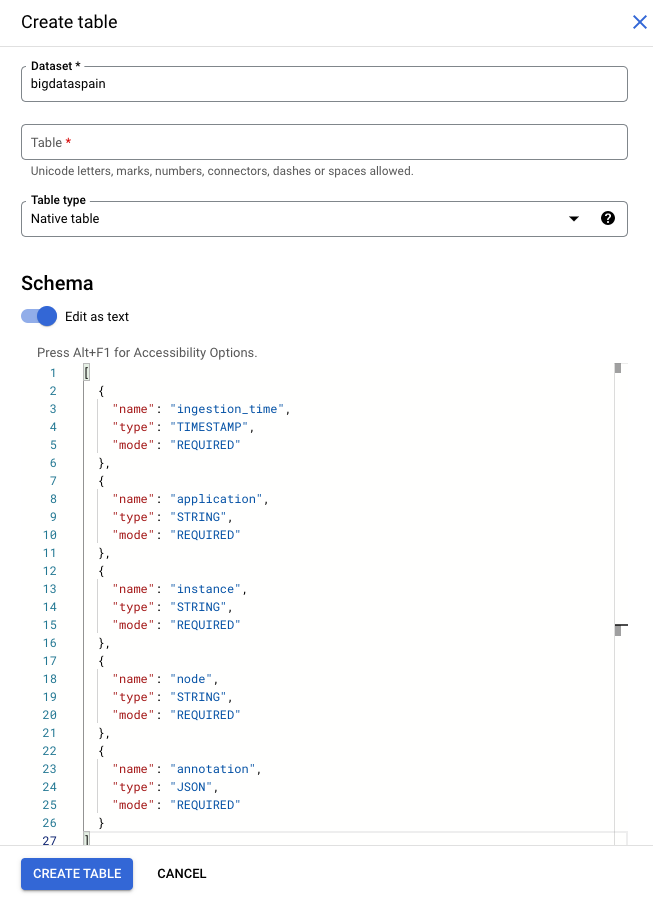
Se utilizzi lo schema predefinito per le tabelle di output del modello, assicurati che la tabella contenga solo le seguenti colonne obbligatorie. Puoi copiare direttamente il seguente testo dello schema quando crei la tabella BigQuery. Per informazioni più dettagliate sulla creazione di una tabella BigQuery, vedi Creare e utilizzare le tabelle. Per ulteriori informazioni sulla specifica dello schema quando crei una tabella, vedi Specificare uno schema.
Utilizza il seguente testo per descrivere lo schema quando crei una tabella. Per
informazioni sull'utilizzo del tipo di colonna JSON
("type": "JSON"), vedi Utilizzo dei dati di tipo JSON in SQL standard.
Il tipo di colonna JSON è consigliato per la query di annotazione. Puoi anche utilizzare
"type" : "STRING".
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "application",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "instance",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "node",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "annotation",
"type": "JSON",
"mode": "REQUIRED"
}
]
Google Cloud Console
Nella Google Cloud console, vai alla pagina BigQuery.
Seleziona il progetto.
Seleziona altre opzioni .
Fai clic su Crea tabella.
Nella sezione "Schema", abilita Modifica come testo.
gcloud
L'esempio seguente crea prima il file JSON di richiesta, quindi utilizza il
gcloud alpha bq tables create comando.
Crea prima il file JSON di richiesta:
echo "{ \"schema\": [ { \"name\": \"ingestion_time\", \"type\": \"TIMESTAMP\", \"mode\": \"REQUIRED\" }, { \"name\": \"application\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"instance\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"node\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"annotation\", \"type\": \"JSON\", \"mode\": \"REQUIRED\" } ] } " >> bigquery_schema.jsonInvia il comando
gcloud. Esegui le seguenti sostituzioni:TABLE_NAME: l'ID della tabella o l'identificatore completo della tabella.
DATASET: l'ID del set di dati BigQuery.
gcloud alpha bq tables create TABLE_NAME \ --dataset=DATASET \ --schema-file=./bigquery_schema.json
Esempio di righe BigQuery generate da un'app Vision della piattaforma agentica Gemini Enterprise:
| ingestion_time | application | instance | node | annotation |
|---|---|---|---|---|
| 2022-05-11 23:3211.911378 UTC | my_application | 5 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE1Eg5teV9hcHBsaWNhdGlvbgjS+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911338 UTC | my_application | 1 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgExEg5teV9hcHBsaWNhdGlvbgiq+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911313 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgiR+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3212.235327 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgi/3J3Ozdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
Utilizzare uno schema personalizzato
Se lo schema predefinito non funziona per il tuo caso d'uso, puoi utilizzare Cloud Run Functions per generare righe BigQuery con uno schema definito dall'utente. Se utilizzi uno schema personalizzato, non è necessario uno schema della tabella BigQuery.
Grafico dell'app con il nodo BigQuery selezionato
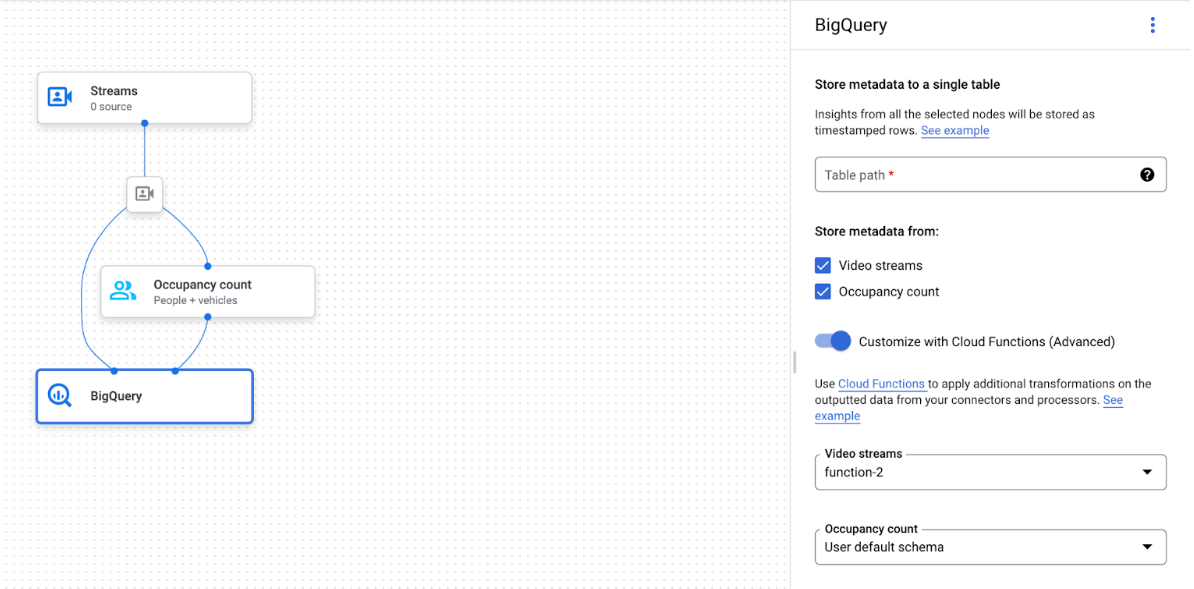
Il connettore BigQuery può essere collegato a qualsiasi modello che restituisce annotazioni basate su video o proto:
- Per l'input video, il connettore BigQuery estrae solo i dati dei metadati archiviati nell'intestazione del flusso e li importa in BigQuery come altri output di annotazione del modello. Il video non viene archiviato.
- Se il flusso non contiene metadati, non verrà archiviato nulla in BigQuery.
Esegui query sui dati della tabella
Con lo schema della tabella BigQuery predefinito, puoi eseguire analisi efficaci dopo che la tabella è stata compilata con i dati.
Query di esempio
Puoi utilizzare le seguenti query di esempio in BigQuery per ottenere informazioni dai modelli Vision della piattaforma agentica Gemini Enterprise.
Ad esempio, puoi utilizzare BigQuery per tracciare una curva basata sul tempo per il numero massimo di persone rilevate al minuto utilizzando i dati del modello di rilevamento di persone / veicoli con la seguente query:
WITH nested3 AS( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["fullFrameCount"]) AS counts FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT ingestion_time, e FROM nested, UNNEST(nested.counts) AS e) SELECT STRING(TIMESTAMP_TRUNC(nested2.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested2.e["count"]), 0) AS person_count FROM nested2 WHERE JSON_VALUE(nested2.e["entity"]["labelString"])="Person") SELECT time, MAX(person_count) FROM nested3 GROUP BY time
Allo stesso modo, puoi utilizzare BigQuery e la funzionalità di conteggio delle linee di attraversamento del modello di analisi dell'occupazione per creare una query che conta il numero totale di veicoli che attraversano la linea di attraversamento al minuto:
WITH nested4 AS ( WITH nested3 AS ( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["crossingLineCounts"]) AS lines FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT nested.ingestion_time, JSON_QUERY_ARRAY(line["positiveDirectionCounts"]) AS entities FROM nested, UNNEST(nested.lines) AS line WHERE JSON_VALUE(line.annotation.id) = "LINE_ANNOTATION_ID") SELECT ingestion_time, entity FROM nested2, UNNEST(nested2.entities) AS entity ) SELECT STRING(TIMESTAMP_TRUNC(nested3.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested3.entity["count"]), 0) AS vehicle_count FROM nested3 WHERE JSON_VALUE(nested3.entity["entity"]["labelString"])="Vehicle" ) SELECT time, SUM(vehicle_count) FROM nested4 GROUP BY time
Esegui la query
Dopo aver formattato la query SQL standard di Google, puoi utilizzare la console per eseguirla:
Console
Nella Google Cloud console, apri la pagina BigQuery.
Seleziona Espandi accanto al nome del set di dati e seleziona il nome della tabella.
Nella visualizzazione dei dettagli della tabella, fai clic su Crea nuova query.

Inserisci una query SQL standard di Google nell'area di testo Editor query. Per le query di esempio, vedi query di esempio.
(Facoltativo) Per modificare la località di trattamento dei dati, fai clic su Altro, quindi su Impostazioni query. In Località di trattamento, fai clic su Selezione automatica e scegli la località dei dati. Infine, fai clic su Salva per aggiornare le impostazioni della query.
Fai clic su Esegui.
Viene creato un job query che scrive l'output in una tabella temporanea.
Integrazione di Cloud Run Functions
Puoi utilizzare Cloud Run Functions per attivare il trattamento aggiuntivo dei dati con l'importazione BigQuery personalizzata. Per utilizzare Cloud Run Functions per l'importazione BigQuery personalizzata:
Quando utilizzi la Google Cloud console, seleziona la funzione Cloud corrispondente dal menu a discesa di ogni modello connesso.

Quando utilizzi l'API Vision della piattaforma agentica Gemini Enterprise, aggiungi una coppia chiave-valore al
cloud_function_mappingcampo diBigQueryConfignel nodo BigQuery. La chiave è il nome del nodo BigQuery e il valore è il trigger HTTP della funzione di destinazione.
Per utilizzare Cloud Run Functions con l'importazione BigQuery personalizzata, la funzione deve soddisfare i seguenti requisiti:
- L'istanza di Cloud Run Functions deve essere creata prima di creare il nodo BigQuery.
- L'API Vision della piattaforma agentica Gemini Enterprise prevede di ricevere un
AppendRowsRequestannotazione restituita da Cloud Run Functions. - Devi impostare il
proto_rows.writer_schemacampo per tutte leCloudFunctionrisposte;write_streampuò essere ignorato.
Esempio di integrazione di Cloud Run Functions
L'esempio seguente mostra come analizzare l'output del nodo di conteggio dell'occupazione (OccupancyCountPredictionResult) ed estrarre da esso uno schema della tabella ingestion_time, person_count e vehicle_count.
Il risultato dell'esempio seguente è una tabella BigQuery con lo schema:
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "person_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "vehicle_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
]
Utilizza il seguente codice per creare questa tabella:
Definisci un proto (ad esempio,
test_table_schema.proto) per i campi della tabella in cui vuoi scrivere:syntax = "proto3"; package visionai.testing; message TestTableSchema { int64 ingestion_time = 1; int32 person_count = 2; int32 vehicle_count = 3; }Compila il file proto per generare il file Python del buffer di protocollo:
protoc -I=./ --python_out=./ ./test_table_schema.protoImporta il file Python generato e scrivi la funzione Cloud.
Python
import base64 import sys from flask import jsonify import functions_framework from google.protobuf import descriptor_pb2 from google.protobuf.json_format import MessageToDict import test_table_schema_pb2 def table_schema(): schema = descriptor_pb2.DescriptorProto() test_table_schema_pb2.DESCRIPTOR.message_types_by_name[ 'TestTableSchema'].CopyToProto(schema) return schema def bigquery_append_row_request(row): append_row_request = {} append_row_request['protoRows'] = { 'writerSchema': { 'protoDescriptor': MessageToDict(table_schema()) }, 'rows': { 'serializedRows': base64.b64encode(row.SerializeToString()).decode('utf-8') } } return append_row_request @functions_framework.http def hello_http(request): request_json = request.get_json(silent=False) annotations = [] payloads = [] if request_json and 'annotations' in request_json: for annotation_with_timestamp in request_json['annotations']: row = test_table_schema_pb2.TestTableSchema() row.person_count = 0 row.vehicle_count = 0 if 'ingestionTimeMicros' in annotation_with_timestamp: row.ingestion_time = int( annotation_with_timestamp['ingestionTimeMicros']) if 'annotation' in annotation_with_timestamp: annotation = annotation_with_timestamp['annotation'] if 'stats' in annotation: stats = annotation['stats'] for count in stats['fullFrameCount']: if count['entity']['labelString'] == 'Person': if 'count' in count: row.person_count = count['count'] elif count['entity']['labelString'] == 'Vehicle': if 'count' in count: row.vehicle_count = count['count'] payloads.append(bigquery_append_row_request(row)) for payload in payloads: annotations.append({'annotation': payload}) return jsonify(annotations=annotations)
Per includere le dipendenze in Cloud Run Functions, devi anche caricare il file
test_table_schema_pb2.pygenerato e specificarerequirements.txtin modo simile al seguente:functions-framework==3.* click==7.1.2 cloudevents==1.2.0 deprecation==2.1.0 Flask==1.1.2 gunicorn==20.0.4 itsdangerous==1.1.0 Jinja2==2.11.2 MarkupSafe==1.1.1 pathtools==0.1.2 watchdog==1.0.2 Werkzeug==1.0.1 protobuf==3.12.2Esegui il deployment della funzione Cloud e imposta il trigger HTTP corrispondente in the
BigQueryConfig.