
Saat Anda menambahkan konektor BigQuery ke aplikasi Gemini Enterprise Agent Platform Vision, semua output model aplikasi yang terhubung akan di-ingest ke tabel target.
Anda dapat membuat tabel BigQuery sendiri dan menentukan tabel tersebut saat menambahkan konektor BigQuery ke aplikasi, atau membiarkan platform aplikasi Gemini Enterprise Agent Platform Vision membuat tabel secara otomatis.
Pembuatan tabel otomatis
Jika Anda mengizinkan platform aplikasi Gemini Enterprise Agent Platform Vision membuat tabel secara otomatis, Anda dapat menentukan opsi ini saat menambahkan node konektor BigQuery.
Kondisi set data dan tabel berikut berlaku jika Anda ingin menggunakan pembuatan tabel otomatis:
- Set data: Nama set data yang dibuat secara otomatis adalah
visionai_dataset. - Tabel: Nama tabel yang dibuat secara otomatis adalah
visionai_dataset.APPLICATION_ID. Penanganan error:
- Jika tabel dengan nama yang sama di set data yang sama sudah ada, pembuatan otomatis tidak akan terjadi.
Konsol
Buka tab Aplikasi di dasbor Gemini Enterprise Agent Platform Vision.
Pilih Lihat aplikasi di samping nama aplikasi Anda dari daftar.
Di halaman pembuat aplikasi, pilih BigQuery dari bagian Konektor.
Biarkan kolom Jalur BigQuery kosong.
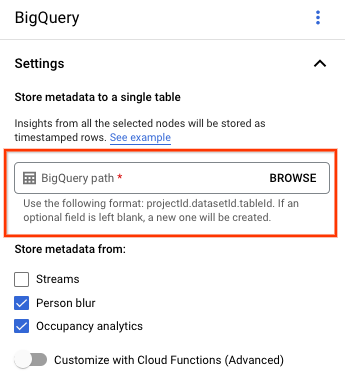
Ubah setelan lainnya.
REST &CMD LINE
Untuk mengizinkan platform aplikasi menyimpulkan skema tabel, gunakan kolom
createDefaultTableIfNotExists dari BigQueryConfig
saat Anda membuat atau memperbarui aplikasi.
Membuat dan menentukan tabel secara manual
Jika ingin mengelola tabel output secara manual, tabel harus memiliki skema yang diperlukan sebagai subset skema tabel.
Jika tabel yang ada memiliki skema yang tidak kompatibel, deployment akan ditolak.
Menggunakan skema default
Jika Anda menggunakan skema default untuk tabel output model, pastikan tabel hanya berisi kolom yang diperlukan berikut dalam tabel. Anda dapat langsung menyalin teks skema berikut saat membuat tabel BigQuery. Untuk informasi lebih mendetail tentang cara membuat tabel BigQuery, lihat Membuat dan menggunakan tabel. Untuk mengetahui informasi selengkapnya tentang spesifikasi skema saat Anda membuat tabel, lihat Menentukan skema.
Gunakan teks berikut untuk mendeskripsikan skema saat Anda membuat tabel. Untuk
mengetahui informasi tentang cara menggunakan jenis kolom JSON
("type": "JSON"), lihat Bekerja dengan data JSON di SQL Standar.
Jenis kolom JSON direkomendasikan untuk kueri anotasi. Anda juga dapat menggunakan
"type" : "STRING".
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "application",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "instance",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "node",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "annotation",
"type": "JSON",
"mode": "REQUIRED"
}
]
Google Cloud Konsol
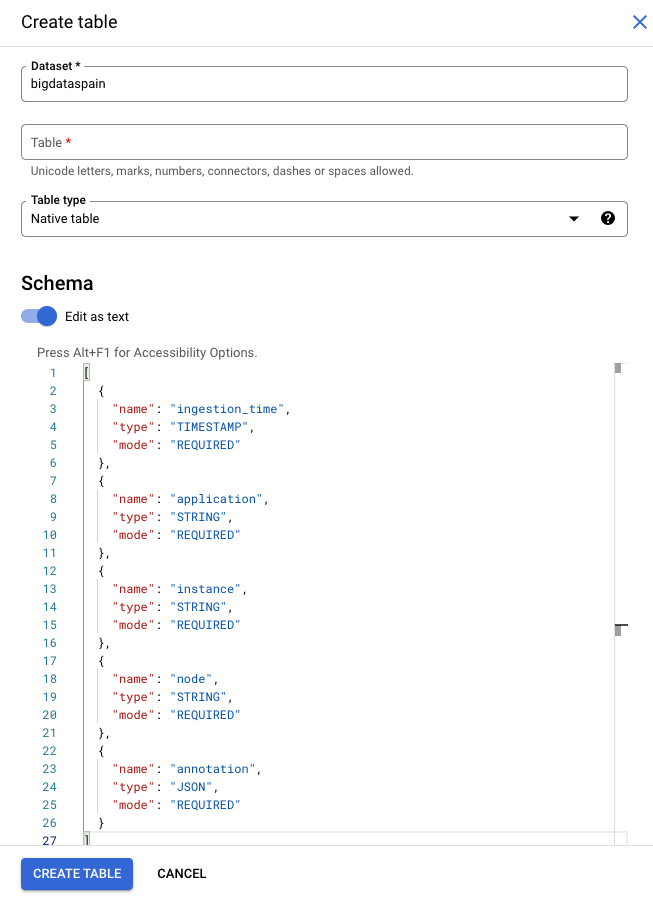
Di Google Cloud konsol, buka halaman BigQuery.
Pilih project Anda.
Pilih opsi lainnya .
Klik Create table.
Di bagian "Schema", aktifkan Edit as text.
gcloud
Contoh berikut pertama-tama membuat file JSON permintaan, lalu menggunakan perintah
gcloud alpha bq tables create command.
Buat file JSON permintaan terlebih dahulu:
echo "{ \"schema\": [ { \"name\": \"ingestion_time\", \"type\": \"TIMESTAMP\", \"mode\": \"REQUIRED\" }, { \"name\": \"application\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"instance\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"node\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"annotation\", \"type\": \"JSON\", \"mode\": \"REQUIRED\" } ] } " >> bigquery_schema.jsonKirim perintah
gcloud. Lakukan penggantian berikut:TABLE_NAME: ID tabel atau ID yang sepenuhnya memenuhi syarat untuk tabel.
DATASET: ID set data BigQuery.
gcloud alpha bq tables create TABLE_NAME \ --dataset=DATASET \ --schema-file=./bigquery_schema.json
Contoh baris BigQuery yang dihasilkan oleh aplikasi Gemini Enterprise Agent Platform Vision:
| ingestion_time | application | instance | node | annotation |
|---|---|---|---|---|
| 2022-05-11 23:3211.911378 UTC | my_application | 5 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE1Eg5teV9hcHBsaWNhdGlvbgjS+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911338 UTC | my_application | 1 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgExEg5teV9hcHBsaWNhdGlvbgiq+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911313 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgiR+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3212.235327 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgi/3J3Ozdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
Menggunakan skema yang disesuaikan
Jika skema default tidak berfungsi untuk kasus penggunaan Anda, Anda dapat menggunakan Cloud Run Functions untuk membuat baris BigQuery dengan skema yang ditentukan pengguna. Jika Anda menggunakan skema kustom, tidak ada prasyarat untuk skema tabel BigQuery.
Grafik aplikasi dengan node BigQuery dipilih
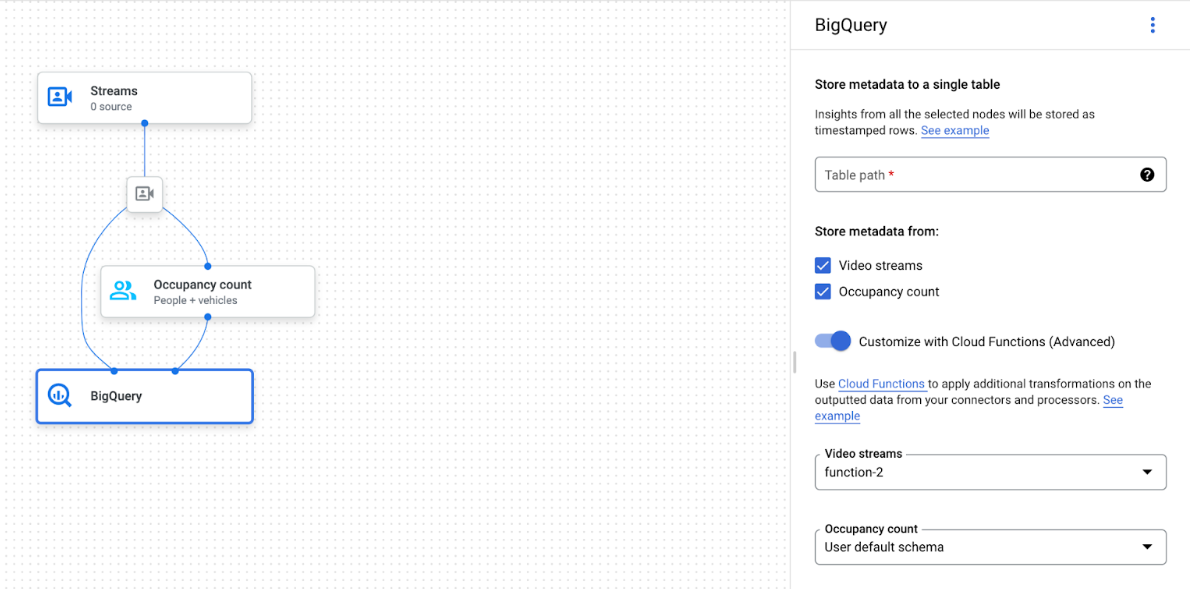
Konektor BigQuery dapat terhubung ke model apa pun yang menghasilkan anotasi berbasis video atau proto:
- Untuk input video, konektor BigQuery hanya mengekstrak data metadata yang disimpan di header streaming dan meng-ingest data ini ke BigQuery sebagai output anotasi model lainnya. Video itu sendiri tidak disimpan.
- Jika streaming Anda tidak berisi metadata, tidak ada yang akan disimpan ke BigQuery.
Membuat kueri data tabel
Dengan skema tabel BigQuery default, Anda dapat melakukan analisis yang efektif setelah tabel diisi dengan data.
Contoh kueri
Anda dapat menggunakan contoh kueri berikut di BigQuery untuk mendapatkan insight dari model Gemini Enterprise Agent Platform Vision.
Misalnya, Anda dapat menggunakan BigQuery untuk membuat kurva berbasis waktu untuk jumlah maksimum orang yang terdeteksi per menit menggunakan data dari model Pendeteksi orang / kendaraan dengan kueri berikut:
WITH nested3 AS( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["fullFrameCount"]) AS counts FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT ingestion_time, e FROM nested, UNNEST(nested.counts) AS e) SELECT STRING(TIMESTAMP_TRUNC(nested2.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested2.e["count"]), 0) AS person_count FROM nested2 WHERE JSON_VALUE(nested2.e["entity"]["labelString"])="Person") SELECT time, MAX(person_count) FROM nested3 GROUP BY time
Demikian pula, Anda dapat menggunakan BigQuery dan fitur penghitungan garis persimpangan dari model Analisis okupansi untuk membuat kueri yang menghitung jumlah total kendaraan yang melewati garis persimpangan per menit:
WITH nested4 AS ( WITH nested3 AS ( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["crossingLineCounts"]) AS lines FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT nested.ingestion_time, JSON_QUERY_ARRAY(line["positiveDirectionCounts"]) AS entities FROM nested, UNNEST(nested.lines) AS line WHERE JSON_VALUE(line.annotation.id) = "LINE_ANNOTATION_ID") SELECT ingestion_time, entity FROM nested2, UNNEST(nested2.entities) AS entity ) SELECT STRING(TIMESTAMP_TRUNC(nested3.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested3.entity["count"]), 0) AS vehicle_count FROM nested3 WHERE JSON_VALUE(nested3.entity["entity"]["labelString"])="Vehicle" ) SELECT time, SUM(vehicle_count) FROM nested4 GROUP BY time
Menjalankan kueri
Setelah memformat kueri SQL Standar Google, Anda dapat menggunakan konsol untuk menjalankan kueri:
Konsol
Di Google Cloud konsol, buka halaman BigQuery.
Pilih Luaskan di samping nama set data, lalu pilih nama tabel.
Di tampilan detail tabel, klik Buat kueri baru.

Masukkan kueri SQL Standar Google di area teks Editor kueri. Untuk contoh kueri, lihat contoh kueri.
Opsional: Untuk mengubah lokasi pemrosesan data, klik Lainnya, lalu Setelan kueri. Di bagian Lokasi pemrosesan, klik Pilih otomatis dan pilih lokasi data Anda. Terakhir, klik Simpan untuk memperbarui setelan kueri.
Klik Jalankan.
Tindakan ini akan membuat tugas kueri yang menulis output ke tabel sementara.
Integrasi Cloud Run Functions
Anda dapat menggunakan Cloud Run Functions untuk memicu pemrosesan data tambahan dengan ingestion BigQuery yang disesuaikan. Untuk menggunakan Cloud Run Functions untuk ingestion BigQuery yang disesuaikan, lakukan hal berikut:
Saat menggunakan Google Cloud konsol, pilih Cloud Function yang sesuai dari menu dropdown setiap model yang terhubung.
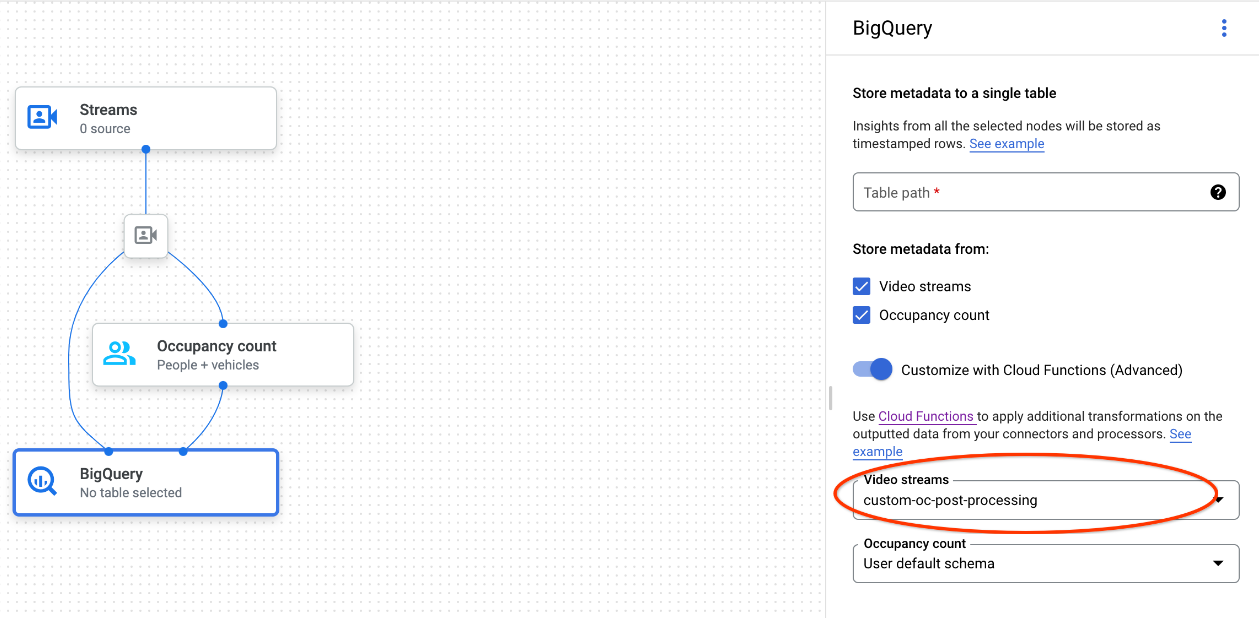
Saat menggunakan Gemini Enterprise Agent Platform Vision API, tambahkan satu pasangan nilai kunci ke kolom
cloud_function_mappingdariBigQueryConfigdi node BigQuery. Kunci adalah nama node BigQuery dan nilai adalah pemicu http dari fungsi target.
Untuk menggunakan Cloud Run Functions dengan ingestion BigQuery yang disesuaikan, fungsi harus memenuhi persyaratan berikut:
- Instance Cloud Run Functions harus dibuat sebelum Anda membuat node BigQuery.
- Gemini Enterprise Agent Platform Vision API diharapkan menerima an
AppendRowsRequestanotasi yang ditampilkan dari Cloud Run Functions. - Anda harus menetapkan kolom
proto_rows.writer_schemauntuk semuaCloudFunctionrespons;write_streamdapat diabaikan.
Contoh integrasi Cloud Run Functions
Contoh berikut menunjukkan cara mengurai output node penghitungan okupansi (OccupancyCountPredictionResult), dan mengekstrak skema tabel ingestion_time, person_count, dan vehicle_count dari output tersebut.
Hasil contoh berikut adalah tabel BigQuery dengan skema:
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "person_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "vehicle_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
]
Gunakan kode berikut untuk membuat tabel ini:
Tentukan proto (misalnya,
test_table_schema.proto) untuk kolom tabel yang ingin Anda tulis:syntax = "proto3"; package visionai.testing; message TestTableSchema { int64 ingestion_time = 1; int32 person_count = 2; int32 vehicle_count = 3; }Kompilasi file proto untuk membuat file Python buffer protokol:
protoc -I=./ --python_out=./ ./test_table_schema.protoImpor file Python yang dihasilkan dan tulis Cloud Function.
Python
import base64 import sys from flask import jsonify import functions_framework from google.protobuf import descriptor_pb2 from google.protobuf.json_format import MessageToDict import test_table_schema_pb2 def table_schema(): schema = descriptor_pb2.DescriptorProto() test_table_schema_pb2.DESCRIPTOR.message_types_by_name[ 'TestTableSchema'].CopyToProto(schema) return schema def bigquery_append_row_request(row): append_row_request = {} append_row_request['protoRows'] = { 'writerSchema': { 'protoDescriptor': MessageToDict(table_schema()) }, 'rows': { 'serializedRows': base64.b64encode(row.SerializeToString()).decode('utf-8') } } return append_row_request @functions_framework.http def hello_http(request): request_json = request.get_json(silent=False) annotations = [] payloads = [] if request_json and 'annotations' in request_json: for annotation_with_timestamp in request_json['annotations']: row = test_table_schema_pb2.TestTableSchema() row.person_count = 0 row.vehicle_count = 0 if 'ingestionTimeMicros' in annotation_with_timestamp: row.ingestion_time = int( annotation_with_timestamp['ingestionTimeMicros']) if 'annotation' in annotation_with_timestamp: annotation = annotation_with_timestamp['annotation'] if 'stats' in annotation: stats = annotation['stats'] for count in stats['fullFrameCount']: if count['entity']['labelString'] == 'Person': if 'count' in count: row.person_count = count['count'] elif count['entity']['labelString'] == 'Vehicle': if 'count' in count: row.vehicle_count = count['count'] payloads.append(bigquery_append_row_request(row)) for payload in payloads: annotations.append({'annotation': payload}) return jsonify(annotations=annotations)
Untuk menyertakan dependensi di Cloud Run Functions, Anda juga harus mengupload file
test_table_schema_pb2.pyyang dihasilkan dan menentukanrequirements.txtyang mirip dengan berikut:functions-framework==3.* click==7.1.2 cloudevents==1.2.0 deprecation==2.1.0 Flask==1.1.2 gunicorn==20.0.4 itsdangerous==1.1.0 Jinja2==2.11.2 MarkupSafe==1.1.1 pathtools==0.1.2 watchdog==1.0.2 Werkzeug==1.0.1 protobuf==3.12.2Deploy Cloud Function dan tetapkan pemicu http yang sesuai di
BigQueryConfig.