

RAG Engine en Gemini Enterprise Agent Platform proporciona diferentes modos de implementación para operar tus instancias de RAG. La elección del modo de implementación determina dónde se almacenan tus datos, cómo se escala ese almacenamiento a medida que crecen tus datos y qué nivel de administración de infraestructura necesitas. Si comprendes cómo funcionan estos modos, puedes elegir el equilibrio adecuado de simplicidad, escalabilidad y costos para tu proyecto.
RAG Engine ofrece dos modos de implementación: sin servidores y Spanner. Puedes cambiar entre ambos modos sin problemas. Los datos dentro de cada modo permanecen aislados del otro.
Modos de implementación disponibles
En esta sección, analizamos los dos modos de implementación disponibles para RAG Engine:
Modo sin servidores
El modo sin servidores es la forma más económica y recomendada de comenzar a usar RAG Engine. Proporciona una base de datos completamente administrada, a escala planetaria y lista para la empresa que abstrae todo el aprovisionamiento y el escalamiento de la base de datos.
- Ideal para: La mayoría de los usuarios, la incorporación rápida y el escalamiento sin problemas sin la necesidad de administrar las configuraciones de infraestructura.
- Funciones clave: No requiere administración de niveles. Usa automáticamente Vector Search administrado por RAG como la base de datos vectorial predeterminada para proporcionar una experiencia de RAG optimizada y lista para usar.
En el modo sin servidores, la base de datos administrada por RAG se usa para administrar las operaciones comerciales de RAG y almacenar recursos de RAG. Estos recursos incluyen (entre otros) RagCorpus, RagFiles, RagMetadata, DataSchema, etcétera. Sin embargo, ya no se puede usar para la indexación de incorporación y la búsqueda de vectores.
Los usuarios siempre deberán elegir una base de datos vectorial diferente por separado. En el modo sin servidores, de forma predeterminada, RAG Engine aprovisiona una colección de Vector Search 2.0 en tu proyecto para la indexación de incorporación y la búsqueda de vectores. En comparación con el modo de Spanner, el aprovisionamiento de Vector Search 2.0 en tu proyecto te brinda visibilidad y control totales sobre el uso y los costos de la base de datos vectorial. Consulta la sección Modo de Spanner en comparación con el modo sin servidores para obtener una comparación detallada.
Modo de Spanner
El modo de Spanner asigna una infraestructura de Spanner dedicada específicamente para que sirva como base de la implementación de RAG Engine. Está diseñado para cargas de trabajo que requieren funciones de cumplimiento específicas (como CMEK) o instancias de base de datos aisladas y dedicadas. El modo de Spanner se asigna como predeterminado si no se selecciona explícitamente una opción de modo.
Cuando usas el modo de Spanner, debes administrar tu infraestructura seleccionando un nivel de rendimiento:
- Nivel básico (predeterminado): Un nivel fijo, rentable y de baja capacidad de procesamiento adecuado para la experimentación, tamaños de datos pequeños o cargas de trabajo que no son sensibles a la latencia.
- Nivel escalado: Ofrece un rendimiento a escala de producción con funcionalidad de ajuste de escala automático. Es adecuado para clientes con grandes cantidades de datos o cargas de trabajo sensibles al rendimiento.
Aislamiento de datos y cambio de modos
RAG Engine te permite cambiar el modo de implementación de tu proyecto siempre que no haya operaciones en curso en tu modo de implementación activo. Puedes tener datos en ambos modos. Sin embargo, solo un modo puede estar activo a la vez, y los datos están estrictamente aislados entre los modos de implementación.
Como herramienta útil, puedes imaginar que tu proyecto se comporta como si tuviera dos backends completamente separados. Los recursos que creas (corpora, archivos importados y subidos, y las incorporaciones analizadas) están vinculados de forma permanente al modo de implementación que estaba activo durante su creación. Cualquier solicitud de recuperación, ya sea directamente o a través de Gemini, también se limitará a los corpora y los archivos que estén presentes en tu modo de implementación actual. Cambiar entre los dos modos no mueve tus datos ni los borra del otro modo.
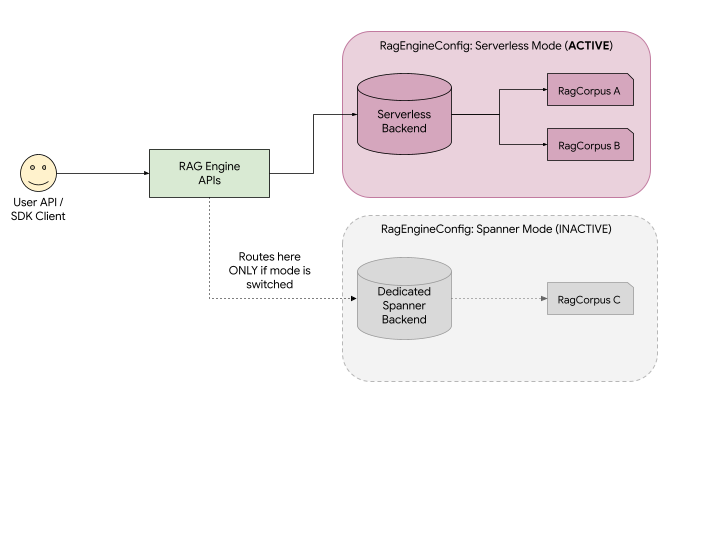
Como se ilustra en el diagrama, ocurre lo siguiente:
- API unificada: Usas las mismas APIs de RAG de Agent Platform para crear y administrar recursos. La API enruta automáticamente tus solicitudes al backend asociado con tu modo de implementación activo.
- Visibilidad: Si el modo sin servidores está activo, tu aplicación solo puede ver e interactuar con RagCorpus A y B. RagCorpus C, que se creó en el modo de Spanner, permanece almacenado de forma segura, pero está completamente oculto y es inaccesible para tu aplicación hasta que vuelvas a cambiar el modo de tu proyecto a Spanner.
- Sin pérdida de datos: Cambiar de modo no borra tus datos. Solo cambia el "backend" que observa la API.
Administra tu modo de implementación
El modo de implementación es un parámetro de configuración a nivel del proyecto. Puedes ver o cambiar tu modo actual con las APIs de GetRagEngineConfig y UpdateRagEngineConfig. Consulta la página Cambio entre modos para obtener detalles sobre cómo cambiar entre tus modos de implementación y elegir un nivel adecuado para tu modo de Spanner.
Borra los datos y detén la facturación
Debido a que los datos están aislados entre los modos, los procesos para limpiar los recursos y detener la facturación difieren ligeramente según dónde residan tus datos.
- Para borrar datos sin servidores: Asegúrate de que tu modo activo esté configurado como sin servidores. Llama a la API de
ListRagCorporapara ver tus recursos y, luego, borra manualmente cada corpus con la API deDeleteRagCorpus. - Para borrar datos de Spanner (desaprovisionamiento): Asegúrate de que tu modo activo esté configurado como Spanner. Actualiza tu
RagEngineConfigy establece el nivel de Spanner enUnprovisioned. Esto borrará de inmediato tu instancia de Spanner dedicada y todos los datos de RAG que contenga, y detendrá cualquier facturación asociada para el modo de Spanner. Nota: Los datos borrados con el nivel no aprovisionado no se pueden recuperar.
Modo de Spanner en comparación con el modo sin servidores
| Función | Modo sin servidores | Modo de Spanner |
|---|---|---|
| Costo |
|
|
| Escalamiento | Ajuste de escala automático completamente administrado | Se debe configurar la elección del nivel, pero ofrece un nivel de ajuste de escala automático. |
| Aislamiento | El almacenamiento no está aislado. | Proporciona aislamiento de almacenamiento y rendimiento. |
| CMEK | No hay CMEK por el momento. | Ofrece compatibilidad con CMEK. |
| Controles de seguridad de VPC | Admitido | Admitido |
| Bases de datos vectoriales admitidas |
|
|
¿Qué sigue?
- Para comenzar a usar RAG Engine, consulta Inicio rápido de RAG.
- Para cambiar el modo de implementación o actualizar el nivel del modo de Spanner, consulta Cambio entre modos.
- Para borrar tu instancia de Spanner, consulta Actualiza al nivel no aprovisionado.
- Para obtener más información sobre el modo de Spanner, consulta Administra el modo de Spanner.
- Para obtener más información sobre el modo sin servidores, consulta Modo sin servidores.
- Para obtener información sobre los precios, consulta Facturación de RAG Engine en Gemini Enterprise Agent Platform.