

A solução é a decodificação especulativa. Essa técnica de otimização acelera o processo lento e sequencial do LLM grande (o modelo de destino) gerando um token por vez, introduzindo um mecanismo de rascunho.
Esse mecanismo de rascunho propõe rapidamente vários próximos tokens de uma só vez. O modelo de destino grande verifica essas propostas em um único lote paralelo. Ele aceita o prefixo correspondente mais longo das próprias previsões e continua a geração a partir desse novo ponto.
Mas nem todos os mecanismos de rascunho são iguais. A abordagem clássica de rascunho-destino usa um modelo de LLM separado e menor como redator, o que significa que você precisa hospedar e gerenciar mais recursos de veiculação, causando custos adicionais.
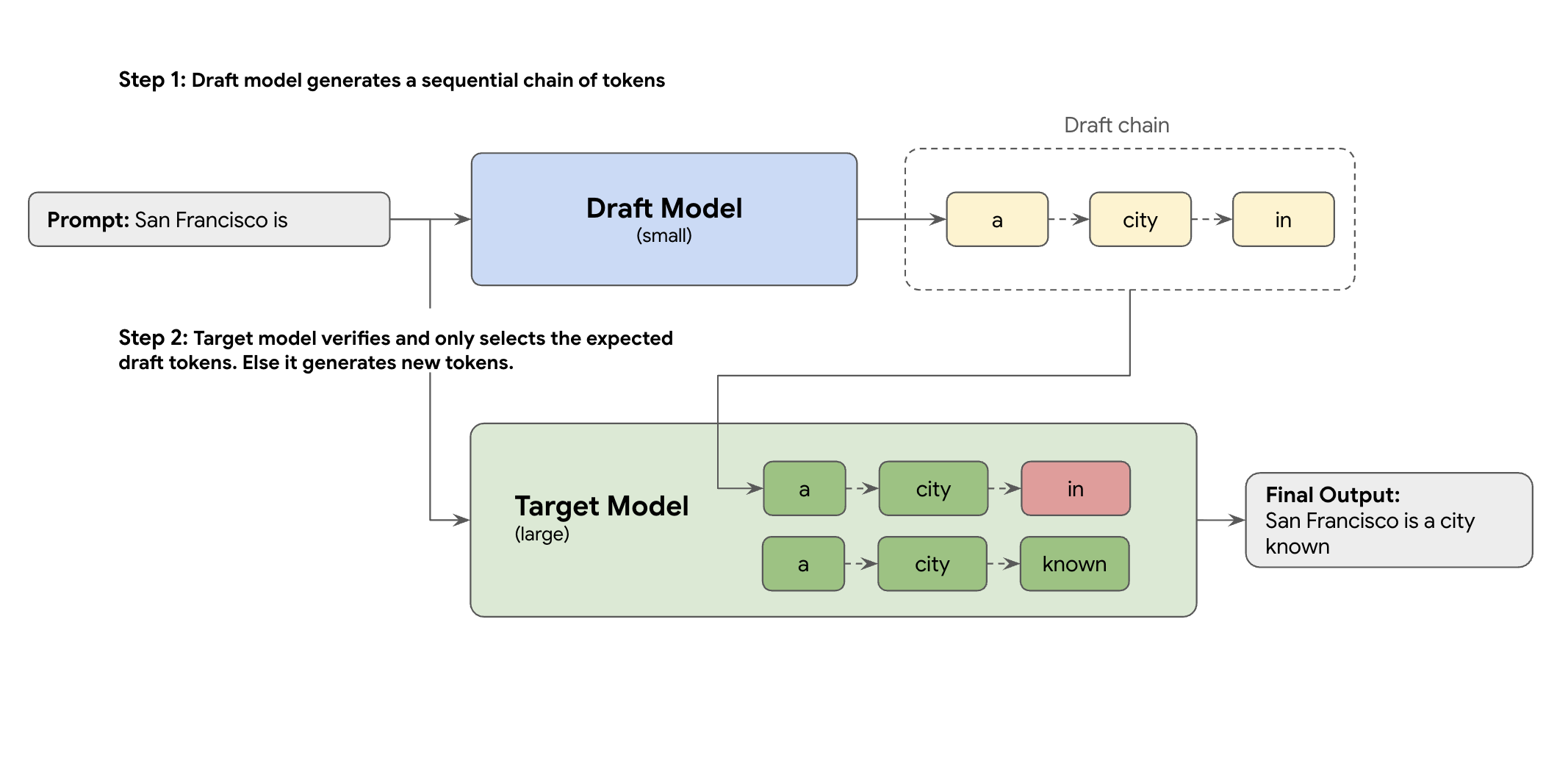
É aí que entra o EAGLE-3 (Extrapolative Attention Guided LEarning). O EAGLE-3 é uma abordagem mais avançada. Em vez de um modelo totalmente separado, ele anexa um "cabeçalho de rascunho" extremamente leve (apenas 2 a 5% do tamanho do modelo de destino) diretamente às camadas internas. Esse cabeçalho opera no nível de recurso e de token, ingerindo recursos dos estados ocultos do modelo de destino para extrapolar e prever uma árvore de tokens futuros.
O resultado disso? Todos os benefícios da decodificação especulativa, eliminando a sobrecarga de treinar e executar um segundo modelo.
A abordagem do EAGLE-3 é muito mais eficiente do que a tarefa complexa e com uso intensivo de recursos de treinar e manter um modelo de rascunho separado com bilhões de parâmetros. Você treina apenas um "cabeçalho de rascunho" leve, apenas 2% a 5% do tamanho do modelo de destino, que é adicionado como parte do modelo atual. Esse processo de treinamento mais simples e eficiente oferece um ganho significativo de desempenho de decodificação de 2 a 3 vezes para modelos como o Llama 70B (dependendo dos tipos de carga de trabalho, por exemplo, multiturbo, código, contexto longo e muito mais).
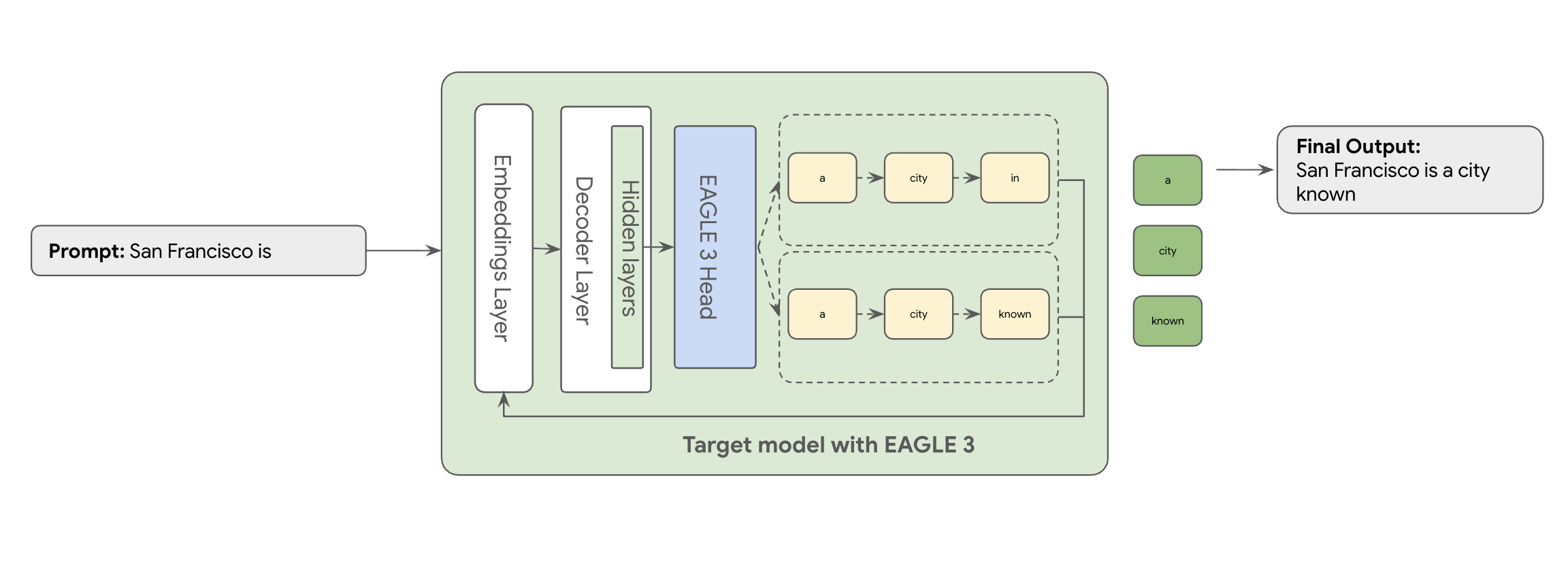
Mas mover até mesmo essa abordagem simplificada do EAGLE-3 de um artigo para um serviço de nuvem escalonado e pronto para produção é uma jornada de engenharia real. Esta postagem compartilha nosso pipeline técnico, os principais desafios e as lições aprendidas ao longo do caminho.
Desafio 1: preparar os dados
A cabeça do EAGLE-3 precisa ser treinada. A primeira etapa óbvia é usar um conjunto de dados público genérico disponível. A maioria desses conjuntos de dados apresenta desafios, incluindo:
- Termos de Uso estritos:esses conjuntos de dados são gerados usando modelos que não permitem o uso deles para desenvolver modelos que concorram com os provedores originais.
- Contaminação de PII:alguns desses conjuntos de dados contêm PII significativas, incluindo nomes, locais e até mesmo identificadores financeiros.
- Qualidade não garantida:alguns conjuntos de dados funcionam bem apenas para casos de uso gerais de "demonstração", mas não para a carga de trabalho especializada de clientes reais.
Usar esses dados como estão não é uma opção.
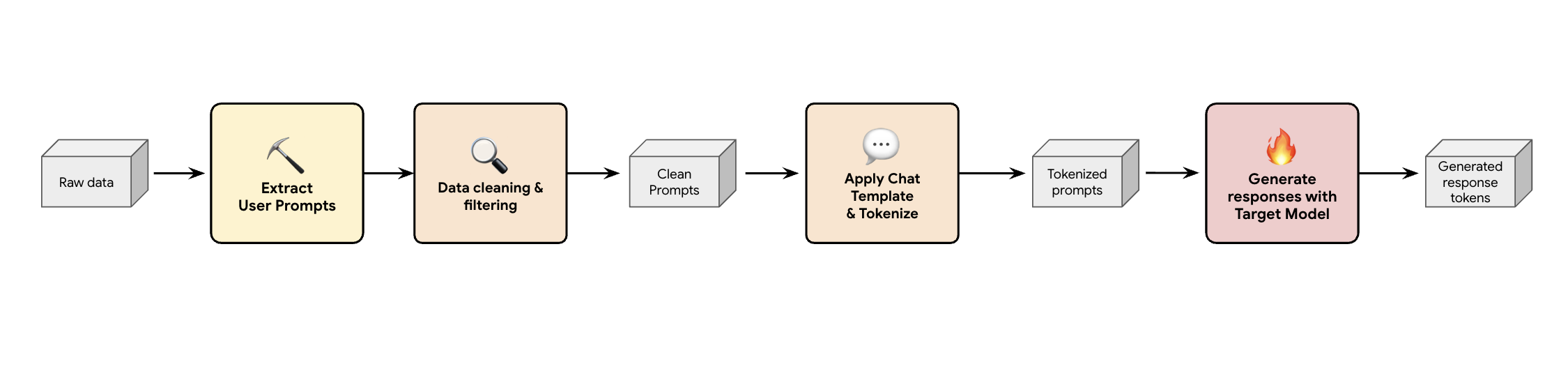
Lição 1: criar um pipeline de geração de dados sintéticos
Uma solução é criar um pipeline de geração de dados sintéticos. Dependendo dos casos de uso do cliente, selecionamos o conjunto de dados certo não apenas com boa qualidade, mas também que melhor corresponde ao tráfego de produção do cliente para várias cargas de trabalho diferentes. Em seguida, extraia apenas os comandos do usuário desses conjuntos de dados e aplique uma DLP (prevenção contra perda de dados) e uma filtragem de PII rigorosas. Esses comandos limpos aplicam um modelo de chat, tokenizam e podem ser enviados ao modelo de destino (por exemplo, Llama 3.3 70B) para coletar as respostas.
Essa abordagem fornece dados gerados pela meta que não são apenas compatíveis e limpos, mas também bem correspondentes à distribuição real de saída do modelo. Isso é ideal para treinar o cabeçalho do rascunho.
Desafio 2: engenharia do pipeline de treinamento
Outra decisão importante é como fornecer os dados de treinamento ao cabeçalho do EAGLE-3. Há dois caminhos distintos: treinamento on-line, em que os embeddings são "gerados na hora", e treinamento off-line, em que os "embeddings são gerados antes do treinamento".
No nosso caso, escolhemos uma abordagem de treinamento off-line porque ela exige muito menos hardware do que o treinamento on-line. Esse processo envolve o pré-cálculo de todos os recursos e incorporações antes do treinamento do cabeçalho EAGLE-3. Eles são salvos no GCS e se tornam os dados de treinamento para nosso cabeçalho EAGLE-3 leve. Depois que você tem os dados, o treinamento em si é rápido. Devido ao tamanho diminuto da cabeça do EAGLE-3, o treinamento inicial com nosso conjunto de dados original exigiu aproximadamente um dia em um único host. No entanto, à medida que dimensionamos nosso conjunto de dados, os tempos de treinamento aumentaram proporcionalmente, agora abrangendo vários dias.

Esse processo nos ensinou duas lições importantes que você precisa ter em mente.
Lição 2: os modelos de chat não são opcionais
Durante o treinamento do modelo ajustado por instruções, descobrimos que a performance do EAGLE-3 pode variar muito quando o modelo de chat não está correto. Você precisa aplicar o modelo de chat específico do modelo de destino (por exemplo, Llama 3) antes de gerar os recursos e embeddings. Se você apenas concatenar texto bruto, os embeddings vão estar incorretos, e sua cabeça vai aprender a prever a distribuição errada.
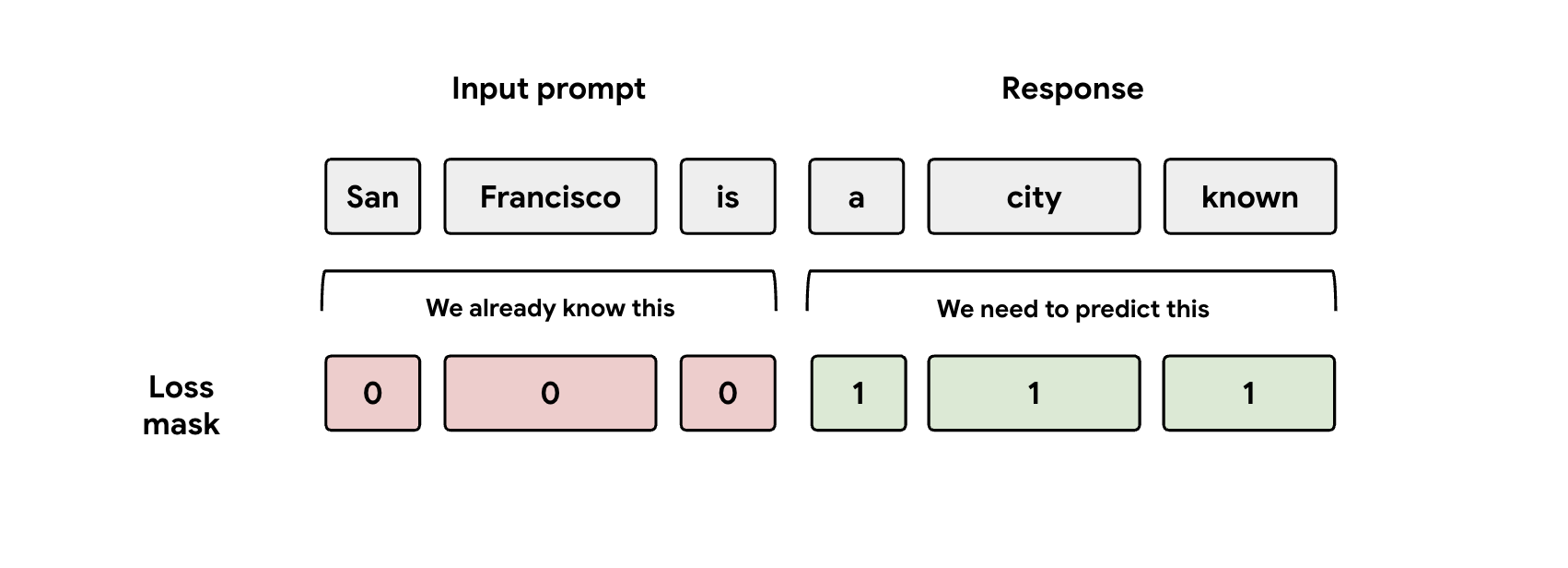
Lição 3: Mind the Mask
Durante o treinamento, o modelo recebe as representações de comando e resposta. Mas a cabeça EAGLE-3 só deve aprender a prever a representação da resposta. É necessário mascarar manualmente a parte do comando na função de perda. Se você não fizer isso, a capacidade de aprendizado do cabeçalho será desperdiçada ao tentar prever o comando que já foi fornecido, e a performance será prejudicada.
Desafio 3: exibição e escalonamento
Com um cabeçalho EAGLE-3 treinado, passamos para a fase de disponibilização. Essa fase introduziu desafios de escalonamento significativos. Confira os principais aprendizados.
Lição 4: seu framework de exibição é fundamental
Trabalhando em parceria com a equipe do SGLang, lançamos o EAGLE-3 na produção com o melhor desempenho. O motivo técnico é que o SGLang implementa um kernel de atenção de árvore crucial. Esse kernel especial é crucial porque o EAGLE-3 gera uma "árvore de rascunho" de possibilidades (não apenas uma cadeia simples), e o kernel do SGLang foi projetado especificamente para verificar todos esses caminhos de ramificação em paralelo em uma única etapa. Sem isso, você vai perder performance.
Lição 5: não deixe a CPU prejudicar a GPU
Mesmo depois de acelerar seu LLM com o EAGLE-3, você pode atingir outro limite de desempenho: a CPU. Quando as GPUs executam inferência de LLM, um software não otimizado desperdiça muito tempo com a sobrecarga da CPU, como inicialização do kernel e contabilidade de metadados. Em um programador síncrono normal, a GPU executa uma etapa (como Rascunho) e fica ociosa enquanto a CPU faz a contabilidade e inicia a próxima etapa Verificar. Essas bolhas de sincronização se acumulam, desperdiçando grandes quantidades de tempo valioso da GPU.

Para resolver isso, usamos o Zero-Overhead Overlap Scheduler (em inglês) do SGLang. Esse
agendador é ajustado especificamente para o fluxo de trabalho de várias etapas Rascunho ->
Verificar -> Extensão do rascunho da decodificação especulativa . A chave é sobrepor a computação. Enquanto a GPU está ocupada executando a etapa atual de Verificação, a CPU já está trabalhando em paralelo para iniciar os kernels das próximas etapas de Rascunho e Extensão do rascunho .
Isso elimina a bolha ociosa, garantindo que o próximo job da GPU esteja sempre pronto,
usando um FutureMap, uma estrutura de dados inteligente que permite à CPU preparar o próximo
lote ENQUANTO a GPU ainda está trabalhando.

Ao eliminar essa sobrecarga de CPU, o programador de sobreposição oferece um aumento de velocidade adicional de 10% a 20% em todos os casos. Isso prova que um ótimo modelo é apenas metade da batalha. Você precisa de um tempo de execução que possa acompanhar.
Resultados da comparação
Depois dessa jornada, valeu a pena? Com certeza.
Comparação da nossa cabeça EAGLE-3 treinada com o modelo não especulativo usando SGLang com Llama 4 Scout 17B Instruct. Nossos comparativos mostram uma aceleração de 2 a 3 vezes na latência de decodificação e ganhos significativos de capacidade, dependendo dos tipos de carga de trabalho.
Confira todos os detalhes e faça o comparativo por conta própria usando nosso notebook completo.
Métrica 1: tempo mediano por token de saída (TPOT)
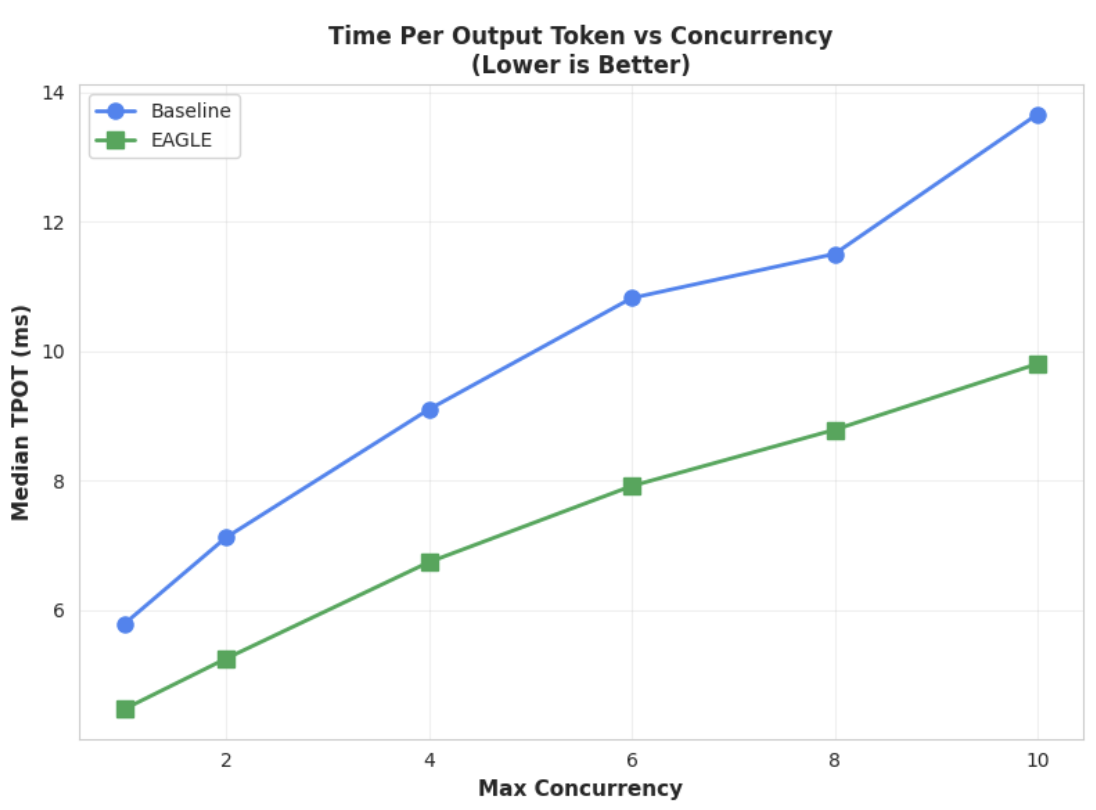
Este gráfico mostra a melhor performance de latência do EAGLE-3. O gráfico de tempo por token de saída (TPOT, na sigla em inglês) mostra que o modelo acelerado pelo EAGLE-3 (linha verde) atinge consistentemente uma latência menor (mais rápida) do que o modelo de referência (linha azul) em todos os níveis de simultaneidade testados.
Métrica 2: capacidade de saída
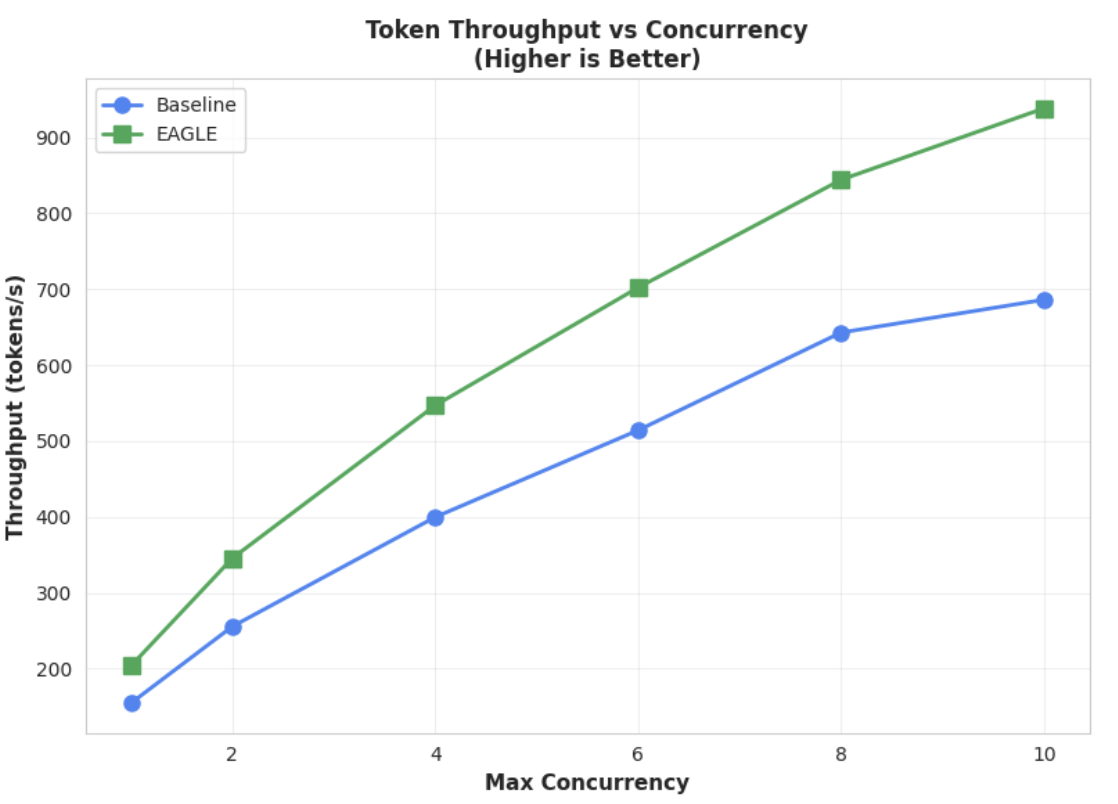
Esse gráfico destaca ainda mais a vantagem de capacidade de processamento do EAGLE-3. O gráfico de taxa de transferência de tokens x simultaneidade demonstra claramente que o modelo acelerado EAGLE-3 (linha verde) supera de forma consistente e substancial o modelo de base (linha azul).
Embora observações semelhantes sejam válidas para modelos maiores, vale a pena notar que um aumento no tempo até o primeiro token (TTFT, na sigla em inglês) pode ser observado em comparação com outras métricas de desempenho. Além disso, essas performances variam de acordo com a tarefa dependente da tarefa, conforme ilustrado nos exemplos a seguir:
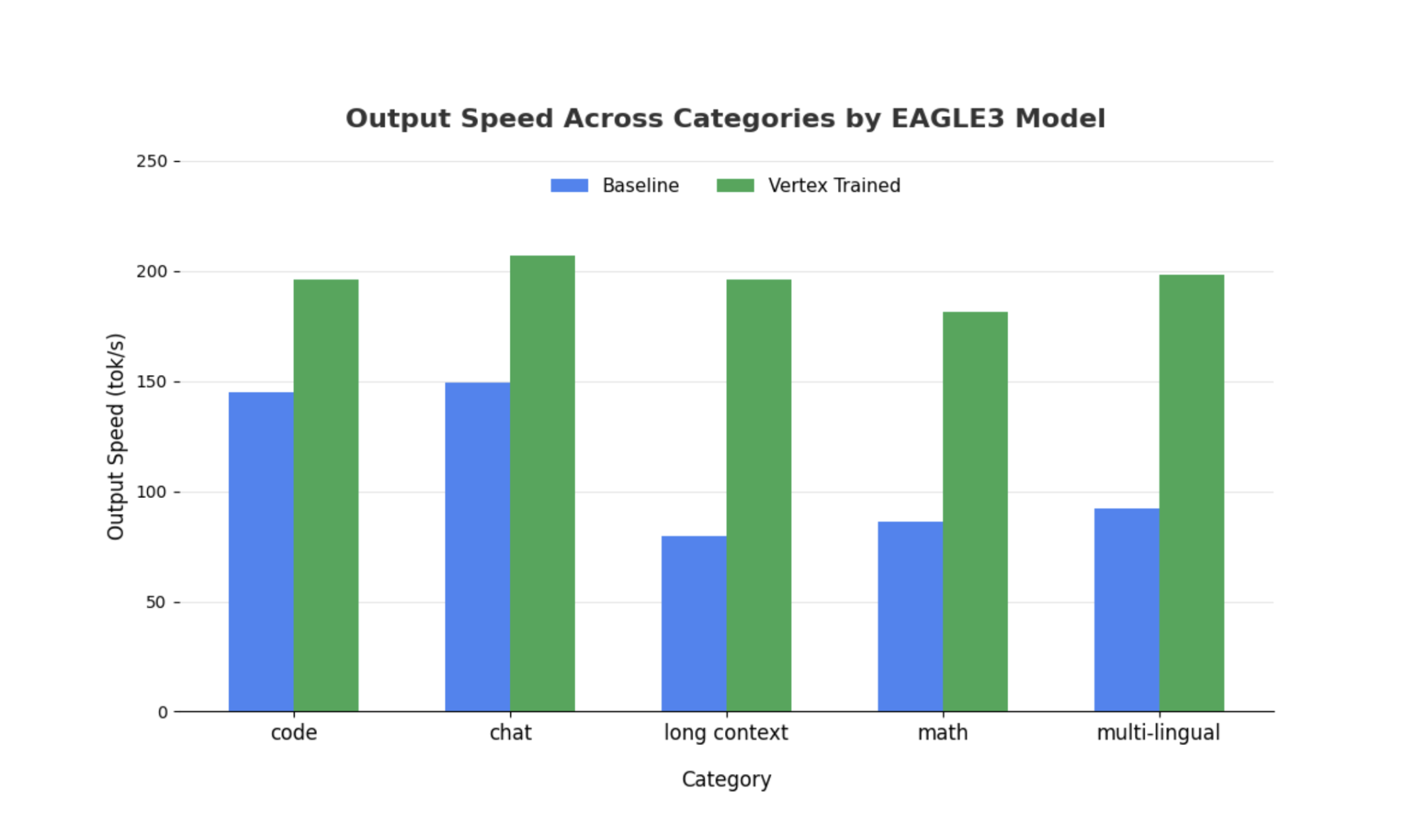
Conclusão: agora é sua vez
O EAGLE-3 não é apenas um conceito de pesquisa, mas um padrão pronto para produção que pode oferecer uma aceleração tangível de 2 vezes na latência de decodificação. Mas para isso, é preciso um esforço de engenharia real. Para implantar essa tecnologia de maneira confiável para seus usuários, você precisa:
- Criar um pipeline de dados sintéticos em conformidade.
- Processe corretamente modelos de chat e máscaras de perda e treine o modelo em um conjunto de dados de grande escala.
Na Vertex AI, já simplificamos todo esse processo para você, fornecendo um contêiner e uma infraestrutura otimizados projetados para escalonar seus aplicativos baseados em LLM. Para começar, confira os seguintes recursos:
Agradecemos a leitura
Queremos saber sua opinião e responder às suas dúvidas sobre a Vertex AI.
Agradecimentos
Gostaríamos de expressar nossa sincera gratidão à equipe do SGLang, principalmente Ying Sheng, Lianmin Zheng, Yineng Zhang, Xinyuan Tong e Liangsheng Yin, bem como à equipe do SGLang/SpecForge, principalmente Shenggui Li e Yikai Zhu, pelo apoio inestimável ao longo deste projeto. A assistência generosa e os insights técnicos profundos foram essenciais para o sucesso deste projeto.