
本文档介绍了如何配置一个使用智能体开发套件 (ADK) 框架构建的 AI 代理来收集和存储多模态提示和回答。它还介绍了如何查看、分析和评估存储的多模态媒体内容:
您可以使用 Trace 探索器页面查看单个提示或回答,也可以查看整个对话。您可以选择以渲染格式或原始格式查看媒体内容。如需了解详情,请参阅查看多模态提示和回答。
使用 BigQuery 服务分析多模态数据。例如,您可以使用
AI.GENERATE之类的函数来总结对话。如需了解详情,请参阅使用 BigQuery 分析提示-回答数据。使用 Vertex AI SDK 评估对话。例如,您可以使用 Google Colaboratory 执行情感分析。如需了解详情,请参阅使用 Colaboratory 对提示-回答数据运行评估。
您可以收集的媒体类型
您可以收集以下类型的媒体内容:
- 音频。
- 文档。
- 图片。
- 纯文本和采用 Markdown 格式的文本。
- 视频。
您的提示和回答可以包含内嵌内容和链接。链接可以指向公共资源或 Cloud Storage 存储桶。
提示和回答的存储位置
当代理应用创建或接收提示或回答时,ADK 会调用 OpenTelemetry 插桩。该插桩会根据 OpenTelemetry 生成式 AI 语义惯例 1.37.0 版,对提示和回答以及其中可能包含的多模态数据进行格式化。同时也支持更高版本。
接下来,OpenTelemetry 插桩会执行以下操作:
它会为提示和回答数据创建对象标识符,然后将这些数据写入您的 Cloud Storage 存储桶。Cloud Storage 存储桶中的条目以 JSON Lines 格式保存。
它会将日志和跟踪记录数据发送到您的 Google Cloud 项目,Logging 和 Trace 服务会通过该项目提取并存储这些数据。OpenTelemetry 语义惯例决定了附加到日志条目或跟踪记录 span 的许多属性和字段。
当 OpenTelemetry 插桩创建 Cloud Storage 存储桶对象时,它还会写入一条包含这些对象引用的日志条目。以下示例展示了包含对象引用的部分日志条目:
{ ... "labels": { "gen_ai.system": "vertex_ai", "event.name": "gen_ai.client.inference.operation.details", "gen_ai.output.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_output.jsonl", "gen_ai.system.instructions_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_system_instructions.jsonl", "gen_ai.input.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_input.jsonl" }, "logName": "projects/my-project/logs/gen_ai.client.inference.operation.details", "trace": "projects/my-project/traces/963761020fc7713e4590cad89ad03229", "spanId": "1234512345123451", ... }在日志条目示例中,请注意以下几点:
- 标签
"event.name": "gen_ai.client.inference.operation.details"表示相应日志条目包含对 Cloud Storage 对象的引用。 - 键名包含
gen_ai的标签均引用 Cloud Storage 存储桶中的对象。 - 包含对象引用的所有日志条目都会写入同一个日志,该日志名为
projects/my-project/logs/gen_ai.client.inference.operation.details。
如需了解如何显示包含对象引用的日志条目,请参阅本文档的查找引用提示和回答的所有日志条目部分。
- 标签
收集多模态提示和回答
ADK 会自动调用 OpenTelemetry 来存储提示和回答,并将日志和跟踪记录数据发送到您的 Google Cloud 项目。您无需修改应用。不过,您需要配置您的 Google Cloud 项目和 ADK。
如需从应用中收集并查看多模态提示和回答,请执行以下操作:
配置您的项目:
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI, Cloud Storage, Telemetry, Cloud Logging, and Cloud Trace APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 确保您有一个 Cloud Storage 存储桶。如有必要,请创建一个 Cloud Storage 存储桶。
建议您执行以下操作:
在存储应用日志数据的日志存储桶所在的同一位置创建 Cloud Storage 存储桶。此配置可使 BigQuery 查询更高效。
确保您的 Cloud Storage 存储桶的存储类别支持外部表。借助此功能,您可以使用 BigQuery 查询提示和回答。如果您不打算对新的 Cloud Storage 存储桶使用默认设置,请在创建存储桶之前,先查阅创建 Cloud Storage 外部表。
设置 Cloud Storage 存储桶的保留期限,使其与存储日志条目的日志存储桶的保留期限一致。日志数据的默认保留期限为 30 天。如需了解如何设置 Cloud Storage 存储桶的保留期限,请参阅存储桶锁定。
向应用使用的服务账号授予对 Cloud Storage 存储桶的
storage.objects.create权限。此权限可让您的应用向 Cloud Storage 存储桶写入对象。这些对象用于存储您的代理应用创建或接收的提示和回答。如需了解详情,请参阅为存储桶设置和管理 IAM 政策。
-
配置 ADK:
安装并升级以下依赖项:
google-adk>=1.16.0opentelemetry-instrumentation-google-genai>=0.4b0fsspec[gcs]
更新您的 ADK 调用以开启
otel_to_cloud标志:如果您使用的是 ADK 的 CLI,请运行以下命令:
adk web --otel_to_cloud [other options]否则,在创建 FastAPI 应用时传递该标志:
get_fast_api_app(..., otel_to_cloud=True)
设置以下环境变量:
指示 OpenTelemetry 将 Cloud Storage 对象格式化为 JSON Lines。
OTEL_INSTRUMENTATION_GENAI_UPLOAD_FORMAT='jsonl'指示 OpenTelemetry 上传提示和回答数据,而不是将这些内容嵌入到跟踪记录 span 中。所上传对象的引用包含在日志条目中。
OTEL_INSTRUMENTATION_GENAI_COMPLETION_HOOK='upload'指示 OpenTelemetry 使用最新的生成式 AI 语义惯例。
OTEL_SEMCONV_STABILITY_OPT_IN='gen_ai_latest_experimental'指定对象的路径:
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH='gs://STORAGE_BUCKET/PATH'在上面的表达式中,STORAGE_BUCKET 指的是 Cloud Storage 存储桶的名称。PATH 指的是存储对象的路径。
查看多模态提示和回答
为了确定要为 span 显示的提示和回答,Cloud Trace 会发出查询来读取日志数据和 Cloud Storage 存储桶中存储的数据。您对所查询资源所拥有的 Identity and Access Management (IAM) 角色决定了是否会返回相应数据。在某些情况下,您可能会看到错误消息。例如,如果您没有从 Cloud Storage 存储桶读取数据的权限,则尝试访问相应数据会导致“权限遭拒”错误。
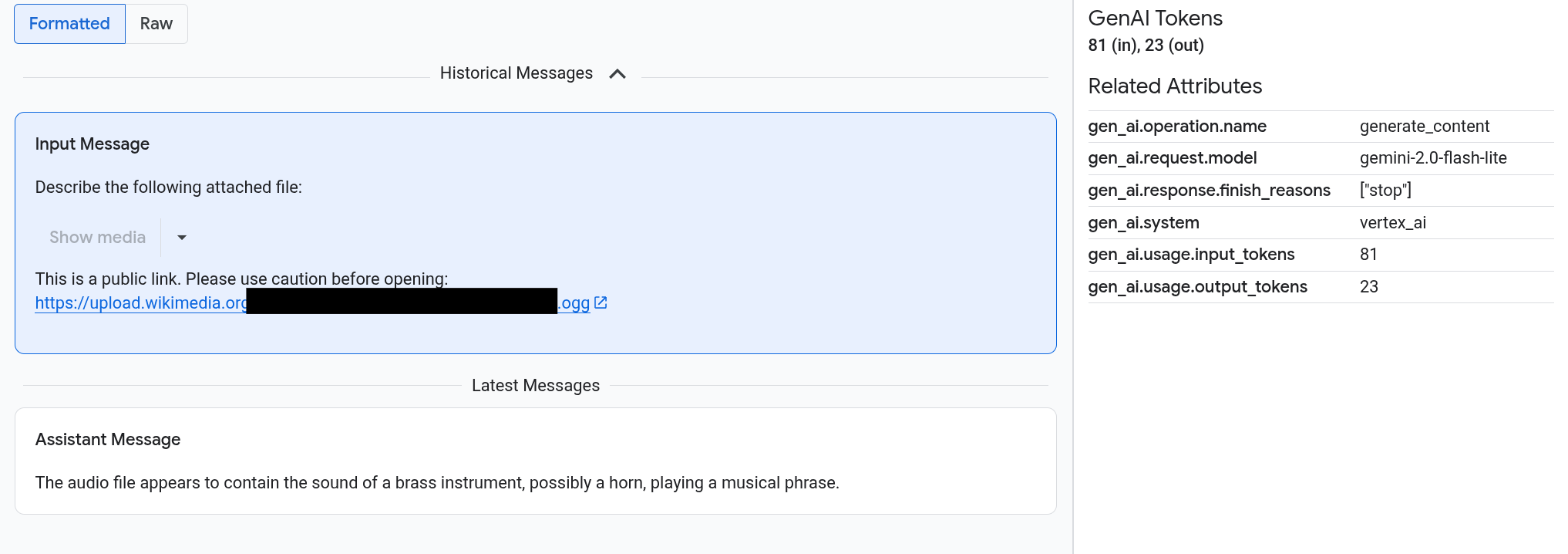
提示和回答以类似聊天的格式显示,您可以选择媒体内容(例如图片)是自动进行渲染还是以源格式呈现。同样,您可以查看整个对话历史记录,也可以仅查看附加到某个 span 的提示和回答。
例如,以下示例展示了提示和回答的显示方式,以及 OpenTelemetry:属性的摘要显示方式:
准备工作
如需获得查看多模态提示和回答所需的权限,请让您的管理员为您授予项目的以下 IAM 角色:
-
Cloud Trace User (
roles/cloudtrace.user) -
Logs Viewer (
roles/logging.viewer) -
Storage Object Viewer (
roles/storage.objectViewer)
如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
查找包含多模态提示和回答的 span
如需查找包含多模态提示和回答的 span,请执行以下操作:
-
在 Google Cloud 控制台中,前往 Trace 探索器页面:
您也可以使用搜索栏查找此页面。
在 span 过滤条件窗格中,前往 span 名称部分,然后选择
generate_content。或者,添加过滤条件
gen_ai.operation.name: generate_content。从 span 列表中选择一个 span。
系统会打开相应 span 的详情页面。此页面会在跟踪记录上下文中显示相应 span。如果某个 span 名称旁边有一个标有输入/输出的按钮
 ,则表示有生成式 AI 事件可用。下一部分探索多模态提示和回答将介绍数据的呈现方式和可视化选项。
,则表示有生成式 AI 事件可用。下一部分探索多模态提示和回答将介绍数据的呈现方式和可视化选项。
探索多模态提示和回答
输入/输出标签页包含两个部分。一个部分显示提示和回答,另一个部分显示 OpenTelemetry:属性。仅当发送到 Trace 的 span 遵循 OpenTelemetry 生成式 AI 语义惯例 1.37.0 版或更高版本(从而生成名称以 gen_ai 开头的消息)时,才会显示此标签页。
输入/输出标签页会以类似聊天的格式显示您的消息。您可以使用标签页上的选项控制显示哪些消息及其格式:
- 如需查看整个对话,请展开历史消息窗格。
- 如需仅查看所选 span 中的提示和回答,请使用最新消息窗格。
如需查看图片、视频或其他媒体内容,请选择已格式化。
系统并不总是会显示媒体内容。为了保护您,如果提示或回答包含指向公共图片、文档或视频的链接,您必须确认是否要显示相应媒体内容。同样,如果提示或回答包含存储在 Cloud Storage 存储桶中的媒体,且该媒体非常大,则您必须确认是否要显示相应媒体内容。
有些媒体(例如图片和视频)会附带一个菜单。您可以使用此菜单执行一些操作,例如将图片下载到本地硬盘。菜单选项取决于媒体类型。
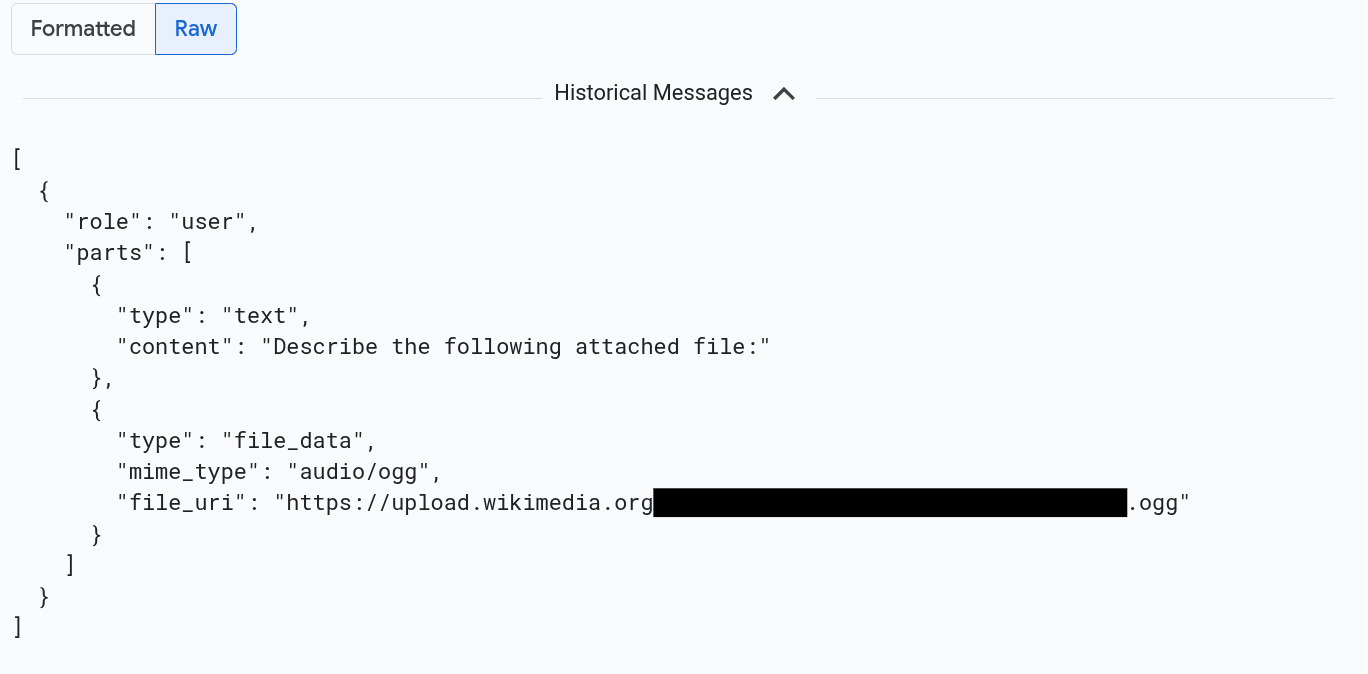
如需以 JSON 格式查看消息,请选择原始。选择此选项后,系统不会渲染图片等媒体。
例如,下图展示了以原始格式显示的对话:
查找引用提示和回答的所有日志条目
如需列出包含多模态提示和回答对象引用的日志条目,请执行以下操作:
-
在 Google Cloud 控制台中,转到 Logs Explorer 页面:
如果您使用搜索栏查找此页面,请选择子标题为 Logging 的结果。
在项目选择器中,选择您的 Google Cloud 项目。
在工具栏中,展开所有日志名称,在过滤条件中输入
gen_ai,然后选择名为 gen_ai.client.inference.operation.details 的日志。上述步骤会将以下查询添加到 Logs Explorer:
logName="projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details"如果您愿意,可以复制该语句并将其粘贴到 Logs Explorer 的查询窗格中,但在复制该语句之前,请将 PROJECT_ID 替换为您的项目 ID。
您还可以按标签值过滤日志数据。例如,如果您添加以下过滤条件,则系统只会显示包含指定标签的日志条目:
labels."event.name"="gen_ai.client.inference.operation.details"如需查看日志条目引用的提示和回答,请在日志条目中点击
 查看跟踪记录详情。
查看跟踪记录详情。如需了解如何使用输入/输出标签页上的选项,请参阅本文档的探索多模态提示和回答部分。
使用 BigQuery 分析提示-回答数据
您可以使用 BigQuery 分析 Cloud Storage 存储桶中存储的提示和回答。在执行此分析之前,请完成以下步骤:
- 启用所需的 API 并确保您已被授予必要的 IAM 角色。
- 在您的日志存储桶上创建一个关联的数据集。
- 向 BigQuery 授予从您的 Cloud Storage 存储桶读取数据的权限。
- 创建一个外部表。
创建外部表后,您可以将日志存储桶中的数据与外部表进行联接,并对联接后的数据执行分析。本部分将演示如何联接表并提取特定字段。它还说明了如何使用 BigQuery ML 函数分析联接表。
准备工作
本部分列出的 IAM 角色是执行升级日志存储桶和创建外部表等操作所必需的。不过,配置完成后,运行查询所需的权限会减少。
-
Enable the BigQuery and BigQuery Connection APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
如需获得配置系统以便在 BigQuery 中查看多模态提示和回答所需的权限,请让您的管理员为您授予项目的以下 IAM 角色:
-
Logs Configuration Writer (
roles/logging.configWriter) -
Storage Admin (
roles/storage.admin) -
BigQuery Connection Admin (
roles/bigquery.connectionAdmin) -
BigQuery Data Viewer (
roles/bigquery.dataViewer) -
BigQuery Studio User (
roles/bigquery.studioUser)
如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
-
Logs Configuration Writer (
在日志存储桶上创建关联的数据集
如需确定存储日志数据的日志存储桶是否已升级为支持 Log Analytics,请运行以下命令:
gcloud logging buckets describe LOG_BUCKET_ID --location=LOCATION运行命令前,请替换以下内容:
- LOG_BUCKET_ID:日志存储桶的 ID。
- LOCATION:日志存储桶的位置。
如果日志存储桶已升级为支持 Log Analytics,
describe命令的结果会包含以下语句:analyticsEnabled: true如果您的日志存储桶尚未升级,请运行以下命令:
gcloud logging buckets update LOG_BUCKET_ID --location=LOCATION --enable-analytics --async升级可能需要几分钟才能完成。当
describe命令报告lifecycleState为ACTIVE时,即表示升级完成。如需在日志存储桶上创建关联的数据集,请运行以下命令:
gcloud logging links create LINKED_DATASET_NAME --bucket=LOG_BUCKET_ID --location=LOCATION运行命令前,请替换以下内容:
- LOG_BUCKET_ID:日志存储桶的 ID。
- LOCATION:日志存储桶的位置。
- LINKED_DATASET_NAME:要创建的关联数据集的名称。
通过关联的数据集,BigQuery 可以读取存储在日志存储桶中的日志数据。如需了解详情,请参阅查询关联的 BigQuery 数据集。
如需确认关联是否存在,请运行以下命令:
gcloud logging links list --bucket=LOG_BUCKET_ID --location=LOCATION如果成功,上一条命令的响应将包含以下行:
LINK_ID: LINKED_DATASET_NAME
向 BigQuery 授予从 Cloud Storage 存储桶读取数据的权限
如需创建 BigQuery 连接,请运行以下命令:
bq mk --connection --location=CONNECTION_LOCATION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID运行命令前,请替换以下内容:
- PROJECT_ID:项目的标识符。
- CONNECTION_ID:要创建的连接的 ID。
- CONNECTION_LOCATION:连接的位置。
命令成功完成后,会显示类似以下内容的消息:
Connection 151560119848.CONNECTION_LOCATION.CONNECTION_ID successfully created验证连接。
bq show --connection PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID该命令的响应会列出连接 ID 和一个服务账号:
{"serviceAccountId": "bqcx-151560119848-s1pd@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}向 BigQuery 连接的服务账号授予 IAM 角色,使其能够读取存储在 Cloud Storage 存储桶中的数据:
gcloud storage buckets add-iam-policy-binding gs://STORAGE_BUCKET \ --member=serviceAccount:SERVICE_ACCT_EMAIL \ --role=roles/storage.objectViewer运行命令前,请替换以下内容:
- STORAGE_BUCKET - Cloud Storage 存储桶的名称。
- SERVICE_ACCT_EMAIL:您的服务账号的邮箱。
创建外部 BigLake 表
如需使用 BigQuery 查询 BigQuery 未存储的数据,请创建一个外部表。由于 Cloud Storage 存储桶会存储提示和回答,因此请创建一个 BigLake 外部表。
-
在 Google Cloud 控制台中,前往 BigQuery 页面:
您也可以使用搜索栏查找此页面。
在查询编辑器中,输入以下语句:
CREATE OR REPLACE EXTERNAL TABLE `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ( -- Schema matching the JSON structure in a Cloud Storage bucket. parts ARRAY< STRUCT< type STRING, content STRING, -- multimodal attachments mime_type STRING, uri STRING, data BYTES, -- tool calls id STRING, name STRING, arguments JSON, response JSON > >, role STRING, `index` INT64, ) WITH CONNECTION `PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID` OPTIONS ( format = 'NEWLINE_DELIMITED_JSON', uris = ['gs://STORAGE_BUCKET/PATH/*'], ignore_unknown_values = TRUE );运行命令前,请替换以下内容:
- PROJECT_ID:项目的标识符。
- EXT_TABLE_DATASET_NAME:要创建的数据集的名称。
- EXT_TABLE_NAME:要创建的外部 BigLake 表的名称。
- CONNECTION_LOCATION:您的 CONNECTION_ID 的位置。
- CONNECTION_ID:连接的 ID。
- STORAGE_BUCKET:Cloud Storage 存储桶的名称。
- PATH:提示和回答的路径。
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH环境变量指定了该路径。
点击运行。
如需详细了解外部表,请参阅以下内容:
将外部表与日志数据联接
本部分说明了如何在 BigQuery 中分析多模态提示。该解决方案依赖于将外部 BigLake 表与日志数据联接,从而让您能够从 Cloud Storage 存储桶中检索对象。此示例基于输入消息的 URI (gen_ai.input.messages) 进行联接。您还可以基于输出消息的 URI (gen_ai.output.messages) 或系统指令的 URI (gen_ai.system.instructions) 进行联接。
如需将外部 BigLake 表与日志数据联接,请执行以下操作:
-
在 Google Cloud 控制台中,前往 BigQuery 页面:
您也可以使用搜索栏查找此页面。
在查询编辑器中,输入以下查询,该查询会在 Cloud Storage 存储桶条目的路径上联接您的日志数据和外部表:
-- Query the linked dataset for completion logs. FROM-- Join completion log entries with the external table. |> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ON messages_ref_uri = _FILE_NAME |> RENAME `index` AS message_idx -- Flatten. |> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx -- Print fields. |> SELECT insert_id, labels, timestamp, trace, span_id, role, part.content, part.uri, part.mime_type, TO_HEX(MD5(part.data)) AS data_md5_hex, part.id AS tool_id, part.name AS tool_name, part.arguments AS tool_args, part.response AS tool_response, message_idx, part_idx, |> ORDER BY timestamp, message_idx, part_idx; |> LIMIT 10;PROJECT_ID.LINKED_DATASET_NAME._AllLogs|> WHERE log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details' AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) |> SELECT insert_id, timestamp, labels, trace, span_id, STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri运行查询前,请替换以下内容:
- PROJECT_ID:项目的标识符。
- LINKED_DATASET_NAME:关联数据集的名称。
- EXT_TABLE_DATASET_NAME:外部 BigLake 表的数据集的名称。
- EXT_TABLE_NAME:外部 BigLake 表的名称。
可选:上面的查询按日志名称和时间戳进行过滤。如果您还想按特定的跟踪记录 ID 进行过滤,请将以下语句添加到
WHERE子句中:AND trace = 'projects/PROJECT_ID/traces/TRACE_ID'在上面的表达式中,将 TRACE_ID 替换为包含跟踪记录 ID 的 16 字节十六进制字符串。
使用 BigQuery ML 函数
您可以对存储在 Cloud Storage 存储桶中的提示和回答使用 BigQuery ML 函数,例如 AI.GENERATE。
例如,以下查询会将完成日志条目与外部表联接,并对联接结果进行展平和过滤。接下来,提示运行 AI.GENERATE 来分析条目是否包含图片,并生成每个条目的摘要:
-- Query the linked dataset for completion logs.
FROM PROJECT_ID.LINKED_DATASET_NAME._AllLogs
|> WHERE
log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details'
AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
|> SELECT
insert_id,
timestamp,
labels,
trace,
span_id,
STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri
-- Join completion log entries with the external table.
|> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME`
ON messages_ref_uri = _FILE_NAME
|> RENAME `index` AS message_idx
-- Flatten.
|> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx
|> WHERE part.uri IS NOT NULL AND part.uri LIKE 'gs://%'
|> LIMIT 10
-- Use natural language to search for images, and then summarize the entry.
|> EXTEND
AI.GENERATE(
(
'Describe the attachment in one sentence and whether the image contains a diagram.',
OBJ.FETCH_METADATA(OBJ.MAKE_REF(part.uri, 'CONNECTION_LOCATION.CONNECTION_ID'))),
connection_id => 'CONNECTION_LOCATION.CONNECTION_ID',
endpoint => 'gemini-2.5-flash-lite',
output_schema => 'description STRING, is_match BOOLEAN') AS gemini_summary
|> SELECT insert_id, trace, span_id, timestamp, part_idx, part.uri, part.mime_type, gemini_summary
|> WHERE gemini_summary.is_match = TRUE
|> ORDER BY timestamp DESC
运行查询前,请替换以下内容:
- PROJECT_ID:项目的标识符。
- LINKED_DATASET_NAME:关联数据集的名称。
- EXT_TABLE_DATASET_NAME:外部 BigLake 表的数据集的名称。
- EXT_TABLE_NAME:外部 BigLake 表的名称。
- CONNECTION_LOCATION:您的 CONNECTION_ID 的位置。
- CONNECTION_ID:连接的 ID。
使用 Colaboratory 对提示-回答数据运行评估
您可以使用 Vertex AI SDK for Python 评估提示和回答。
如需使用 Google Colaboratory 笔记本运行评估,请执行以下操作:
如需查看示例笔记本,请点击
evaluating_observability_datasets.ipynb。GitHub 会打开并显示有关如何使用笔记本的说明。
选择在 Colab 中打开。
Colaboratory 会打开并显示
evaluating_observability_datasets.ipynb文件。在工具栏中,点击复制到云端硬盘。
Colaboratory 会创建一个笔记本副本,将其保存到您的云端硬盘,然后打开该副本。
在您的副本中,前往标题为设置 Google Cloud 项目信息的部分,然后输入您的 Google Cloud 项目 ID 和 Vertex AI 支持的位置。例如,您可以将位置设置为
"us-central1"。前往标题为在 Google Observability 生成式 AI 数据集中加载的部分,然后为以下来源输入值:
- INPUT_SOURCE
- OUTPUT_SOURCE
- SYSTEM_SOURCE
您可以使用附加到日志条目的
gen_ai标签来查找这些字段的值。例如,对于 INPUT_SOURCE,该值类似于以下内容:'gs://STORAGE_BUCKET/PATH/REFERENCE_inputs.jsonl'在上面的表达式中,各个字段的含义如下:
- STORAGE_BUCKET:Cloud Storage 存储桶的名称。
- PATH:提示和回答的路径。
- REFERENCE:Cloud Storage 存储桶中数据的标识符。
如需了解如何查找这些来源的值,请参阅查找引用提示和回答的所有日志条目。
在工具栏中,点击全部运行。