
Como criar IA de produção em Cloud TPUs com JAX
A pilha de IA do JAX estende o núcleo numérico do JAX com uma coleção de bibliotecas combináveis apoiadas pelo Google, transformando-o em uma plataforma robusta, completa e de código aberto para machine learning em grande escala. Assim, a pilha de IA do JAX consiste em um ecossistema abrangente e robusto que aborda todo o ciclo de vida de ML:
Fundamento em escala industrial:a pilha de IA do JAX foi projetada para escala massiva, aproveitando o ML Pathways para orquestrar o treinamento em dezenas de milhares de chips e o Orbax para checkpointing assíncrono resiliente e de alta taxa de transferência, permitindo o treinamento de modelos de última geração em nível de produção.
Kit de ferramentas completo e pronto para produção:a pilha de IA do JAX oferece um conjunto abrangente de bibliotecas para todo o processo de desenvolvimento: Flax para criação flexível de modelos, Optax para estratégias de otimização combináveis e Grain para os pipelines de dados determinísticos essenciais para execuções reproduzíveis em grande escala.
Desempenho máximo e especializado:para alcançar a utilização máxima do hardware, a pilha de IA do JAX oferece bibliotecas especializadas, incluindo Tokamax para kernels personalizados de última geração, Qwix para quantização não intrusiva que aumenta a velocidade de treinamento e inferência, e XProf para criação de perfis de desempenho profundos e integrados ao hardware.
Caminho completo para a produção:a pilha de IA do JAX oferece uma transição perfeita da pesquisa para a implantação. Isso inclui o MaxText como uma referência escalonável para treinamento de modelos de base, o Tunix para aprendizado por reforço (RL) e alinhamento de última geração, além de uma solução de inferência unificada com integração de vLLM TPU e o tempo de execução de serviço do JAX.
A filosofia da pilha de IA do JAX é de componentes pouco acoplados, cada um dos quais faz uma coisa bem. Em vez de ser um framework de ML monolítico, o JAX tem um escopo limitado e se concentra em operações eficientes de matrizes e transformações de programas. O ecossistema é criado com base nesse framework principal para oferecer uma ampla variedade de funcionalidades relacionadas ao treinamento de modelos de ML e a outros tipos de cargas de trabalho, como computação científica.
Esse sistema de componentes pouco acoplados permite selecionar e combinar bibliotecas da melhor maneira para atender aos seus requisitos. Do ponto de vista da engenharia de software, essa arquitetura também permite atualizar a funcionalidade que tradicionalmente seria considerada componentes principais do framework (por exemplo, pipelines de dados e checkpointing) de forma iterativa, sem o risco de desestabilizar o framework principal ou ficar preso em ciclos de lançamento. Como a maioria das funcionalidades é implementada em bibliotecas em vez de mudanças em um framework monolítico, isso torna a biblioteca numérica principal mais durável e adaptável a mudanças futuras no cenário tecnológico.
As seções a seguir oferecem uma visão geral técnica da pilha de IA do JAX, dos principais recursos dela, das decisões de design por trás deles e de como eles se combinam para criar uma plataforma durável para cargas de trabalho modernas de ML.
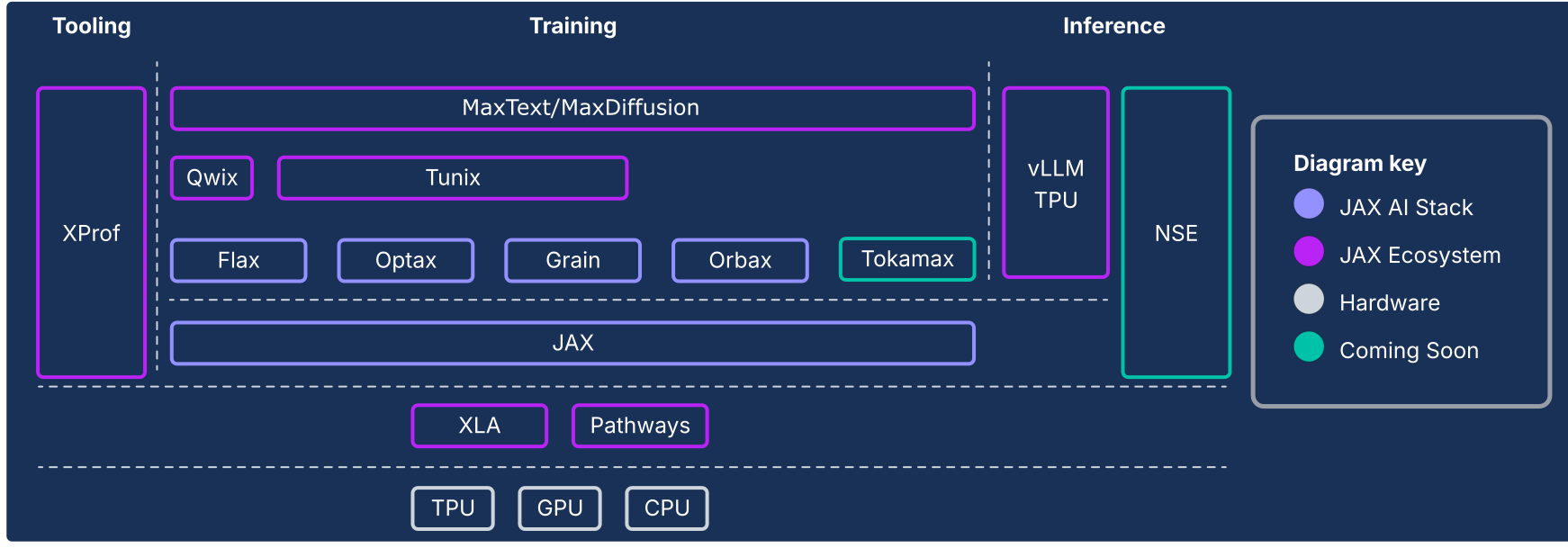
A pilha de IA do JAX e outros componentes do ecossistema
| Componente | Função / Descrição |
|---|---|
| Núcleo e componentes do conjunto de soluções de IA do JAX1 | |
| JAX | Computação de matrizes e transformação de programas orientadas a aceleradores (JIT, grad, vmap, pmap). |
| Flax (link em inglês) | Biblioteca flexível de criação de redes neurais para criação e modificação intuitivas de modelos. |
| Optax | Uma biblioteca de transformações de otimização e processamento de gradiente combináveis. |
| Orbax | Biblioteca de checkpoint distribuído "de qualquer escala" para resiliência de treinamento em escala hero. |
| Grão | Uma biblioteca de pipeline de dados de entrada escalonável, determinista e com capacidade de checkpoint. |
| Pilha de IA do JAX: infraestrutura | |
| XLA | Compilador de machine learning de código aberto para TPUs, CPUs e GPUs. |
| Pathways | Ambiente de execução distribuído para orquestrar a computação em dezenas de milhares de chips. |
| Conjunto de soluções de IA do JAX: Adv. Desenvolvimento | |
| Pallas | Uma extensão do JAX para escrever kernels personalizados de baixo nível e alto desempenho implementados em Python. |
| Tokamax | Uma biblioteca selecionada de kernels personalizados de alta performance e de última geração (por exemplo, atenção). |
| Qwix | Uma biblioteca abrangente e não intrusiva para quantização (PTQ, QAT, QLoRA). |
| Conjunto de soluções de IA do JAX: aplicativo | |
| MaxText / MaxDiffusion | Estruturas de referência principais e escalonáveis para treinamento de modelos de fundação (por exemplo, LLM e difusão). |
| Tunix | Um framework para pós-treinamento e alinhamento (RLHF, DPO) de última geração. |
| vLLM | Uma solução de inferência de LLM de alta performance usando a integração integrada do framework vLLM. |
| XProf | Um criador de perfil profundo e integrado ao hardware para análise de desempenho em todo o sistema. |
1Incluído no pacote jax-ai-stack do Python.
Figura 1: componentes da pilha e do ecossistema de IA do JAX
O imperativo arquitetônico: performance além dos frameworks
À medida que as arquiteturas de modelos convergem, por exemplo, em transformadores multimodais de combinação de especialistas (MoE), a busca pelo desempenho máximo está levando ao surgimento de Megakernels. Um Megakernel é efetivamente toda a transmissão direta (ou uma grande parte) de um modelo específico, codificado manualmente usando uma API de nível mais baixo, como o SDK CUDA em GPUs NVIDIA. Essa abordagem alcança a máxima utilização de hardware ao sobrepor agressivamente computação, memória e comunicação. Trabalhos recentes da comunidade de pesquisa demonstraram que essa abordagem pode gerar ganhos significativos de capacidade, mais de 22% em alguns casos, para inferência em GPUs. Essa tendência não se limita à inferência. Há evidências de que alguns esforços de treinamento em grande escala envolveram controle de hardware de baixo nível para alcançar ganhos de eficiência substanciais.
Se essa tendência se acelerar, todas as estruturas de alto nível, como existem hoje, correm o risco de se tornarem menos relevantes, já que o acesso de baixo nível ao hardware é o que importa para o desempenho em arquiteturas estáveis e maduras. Isso representa um desafio para todas as stacks de ML modernas: como oferecer controle de hardware de nível especializado sem sacrificar a produtividade e a flexibilidade de um framework de alto nível.
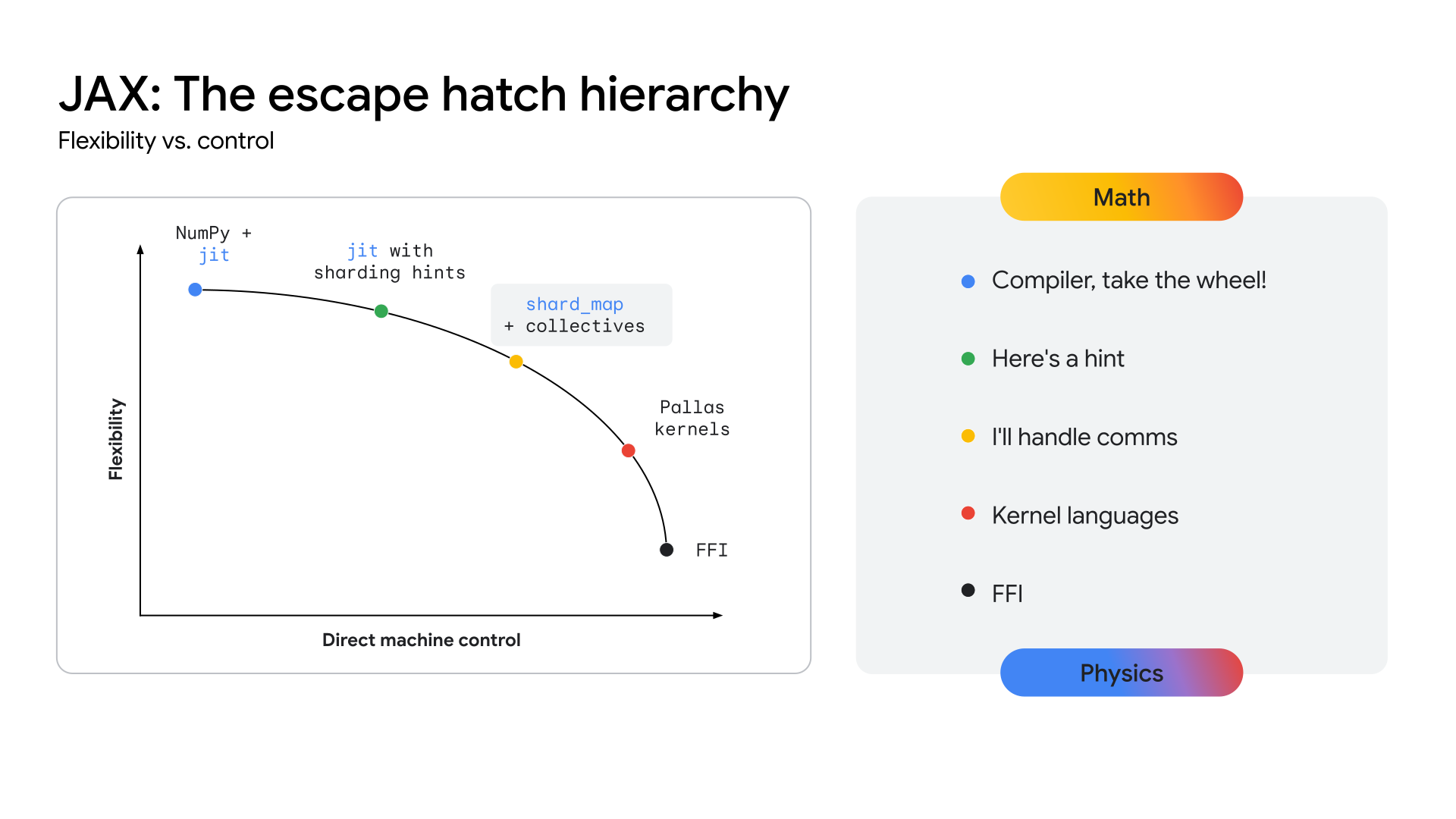
Para que as TPUs ofereçam um caminho claro para esse nível de desempenho, o ecossistema precisa expor uma camada de API mais próxima do hardware, permitindo o desenvolvimento desses kernels altamente especializados. A pilha JAX foi projetada para resolver esse problema oferecendo um continuum de abstração (consulte a Figura 2), desde as otimizações automatizadas de alto nível do compilador XLA até o controle manual e refinado da biblioteca de criação de kernel do Pallas.
Figura 2: o continuum de abstração do JAX
A pilha principal de IA do JAX
A principal pilha de IA do JAX consiste em cinco bibliotecas principais que fornecem a base para o desenvolvimento de modelos:
JAX: uma base para transformação de programas combináveis e de alto desempenho
O JAX é uma biblioteca Python para computação de matrizes e transformação de programas orientada a aceleradores, projetada para computação numérica de alto desempenho e machine learning em grande escala. Com o modelo de programação funcional e a API semelhante ao NumPy, o JAX oferece uma base sólida para bibliotecas de nível superior.
Com seu design que prioriza o compilador, o JAX promove a escalonabilidade usando o XLA (consulte a seção XLA) para análise, otimização e segmentação de hardware agressivas e de programa inteiro. A ênfase do JAX na programação funcional (por exemplo, funções puras) torna as transformações de programa principais mais tratáveis e, principalmente, combináveis.
Essas transformações principais podem ser combinadas para alcançar alto desempenho e escalonamento de cargas de trabalho em tamanhos de modelo e cluster e tipos de hardware:
- jit: compilação just-in-time de funções Python em executáveis XLA otimizados e combinados.
- grad: diferenciação automática, com suporte aos modos direto e inverso, além de derivadas de ordem superior.
- vmap: vetorização automática, permitindo o agrupamento em lote e o paralelismo de dados sem modificar a lógica da função.
- pmap / shard_map: paralelização automática em vários dispositivos (por exemplo, núcleos de TPU), formando a base para o treinamento distribuído.
A integração perfeita com o modelo GSPMD (SPMD de uso geral) do XLA permite que o JAX paralelize automaticamente os cálculos em grandes pods de TPU com mudanças mínimas no código. Na maioria dos casos, o escalonamento requer apenas anotações de fragmentação de alto nível.
Flax: criação flexível de redes neurais
O Flax simplifica a criação, a depuração e a análise de redes neurais no JAX, oferecendo uma abordagem intuitiva e orientada a objetos para a criação de modelos. Embora a API funcional do JAX seja poderosa, ela oferece uma abstração baseada em camadas mais familiar para desenvolvedores acostumados a frameworks como o PyTorch, sem perda de desempenho.
Esse design simplifica a modificação ou a combinação de componentes de modelos treinados.
Técnicas como LoRA e quantização exigem definições de modelo manipuláveis, que a API NNX do Flax oferece por uma interface Pythonic. O NNX encapsula o estado do modelo, reduzindo a carga cognitiva do usuário e permitindo a travessia e modificação programáticas da hierarquia do modelo.
Principais pontos fortes:
- API intuitiva orientada a objetos: simplifica a construção de modelos e permite casos de uso avançados, como substituição de submódulos e inicialização parcial.
- Consistente com o JAX principal: o Flax oferece transformações elevadas totalmente compatíveis com o paradigma funcional do JAX, oferecendo o desempenho total do JAX com mais facilidade para desenvolvedores.
Optax: estratégias de otimização e processamento de gradientes combináveis
O Optax é uma biblioteca de processamento e otimização de gradientes para JAX. Ele foi projetado para fornecer aos criadores de modelos elementos fundamentais que podem ser recombinados de maneiras personalizadas para treinar modelos de aprendizado profundo, entre outras aplicações. Ela se baseia nas capacidades da biblioteca principal do JAX para fornecer uma biblioteca de alto desempenho bem testada de funções de perda e otimizador, além de técnicas associadas que podem ser usadas para treinar modelos de ML.
Motivação
O cálculo e a minimização de perdas são a base do treinamento de modelos de ML. Com o suporte à diferenciação automática, a biblioteca JAX principal oferece os recursos numéricos para treinar modelos, mas não implementações padrão de otimizadores (por exemplo, RMSProp ou Adam) ou perdas (por exemplo, CrossEntropy ou MSE) conhecidos. Embora seja possível implementar essas funções (e alguns desenvolvedores avançados optem por fazer isso), um bug em uma implementação de otimizador introduziria problemas de qualidade do modelo difíceis de diagnosticar. Em vez de o usuário implementar essas partes críticas, a
Optax oferece implementações desses algoritmos que são testadas para
correção e desempenho.
O campo da teoria da otimização está diretamente no âmbito da pesquisa, mas sua função central no treinamento também o torna uma parte indispensável do treinamento de modelos de ML de produção. Uma biblioteca que desempenha essa função precisa ser flexível o suficiente para acomodar iterações rápidas de pesquisa e também robusta e eficiente o suficiente para ser confiável no treinamento de modelos de produção. Ela também precisa fornecer implementações bem testadas de algoritmos de última geração que correspondam às equações padrão. A biblioteca Optax, com sua arquitetura modular combinável e ênfase no código legível correto, foi projetada para isso.
Design
O Optax foi projetado para aumentar a velocidade da pesquisa e a transição da pesquisa para a produção, fornecendo implementações legíveis, bem testadas e eficientes de algoritmos principais. O Optax tem usos além do contexto do aprendizado profundo. No entanto, nesse contexto, ele pode ser visto como uma coleção de funções de perda, algoritmos de otimização e transformações de gradiente conhecidos implementados de maneira puramente funcional, de acordo com a filosofia do JAX. A coleção de perdas e otimizadores conhecidos permite que os usuários comecem a usar com facilidade e confiança.
A abordagem modular da Optax permite encadear vários otimizadores, seguidos por outras transformações comuns (por exemplo, corte de gradiente) e encapsulá-los usando técnicas comuns, como MultiStep ou Lookahead, para alcançar estratégias de otimização eficientes com algumas linhas de código. A interface flexível permite pesquisar novos algoritmos de otimização e usar técnicas avançadas de otimização de segunda ordem, como shampoo ou muon.
# Optax implementation of a RMSProp optimizer with a custom learning rate
# schedule, gradient clipping and gradient accumulation.
optimizer = optax.chain(
optax.clip_by_global_norm(GRADIENT_CLIP_VALUE),
optax.rmsprop(learning_rate=optax.cosine_decay_schedule(init_value=lr,decay_steps=decay)),
optax.apply_every(k=ACCUMULATION_STEPS)
)
# The same thing, in PyTorch
optimizer = optim.RMSprop(model_params, lr=LEARNING_RATE)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=TOTAL_STEPS)
for i, (inputs, targets) in enumerate(data_loader):
# ... Training loop body ...
if (i + 1) % ACCUMULATION_STEPS == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), GRADIENT_CLIP_VALUE)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
O snippet de código anterior mostra como configurar um otimizador com uma taxa de aprendizado, corte de gradiente e acúmulo de gradiente personalizados.
Pontos fortes
- Biblioteca robusta:oferece uma biblioteca abrangente de perdas, otimizadores e algoritmos com foco na correção e legibilidade.
- Transformações modulares encadeáveis:essa API flexível permite criar estratégias de otimização complexas e eficientes de forma declarativa, sem modificar o loop de treinamento.
- Funcional e escalonável:as implementações funcionais puras se integram perfeitamente aos mecanismos de paralelização do JAX (por exemplo, pmap), permitindo que você use o mesmo código para escalonar de um único host a grandes clusters.
Orbax / TensorStore: checkpoint distribuído em grande escala
O Orbax é uma biblioteca de checkpoint para JAX projetada para qualquer escala, desde treinamento em um único dispositivo até treinamento distribuído em grande escala. O objetivo é unificar implementações fragmentadas de checkpointing e oferecer recursos de desempenho críticos, como checkpointing assíncrono e de vários níveis, para um público mais amplo. O Orbax permite a resiliência necessária para trabalhos de treinamento em grande escala e oferece um formato flexível para publicar pontos de verificação.
Ao contrário dos sistemas generalizados de checkpoint e restauração que criam um snapshot de todo o estado do sistema, o checkpoint de ML com o Orbax persiste seletivamente apenas as informações essenciais para retomar o treinamento de pesos do modelo, o estado do otimizador e o estado do carregador de dados. Essa abordagem direcionada minimiza o tempo de inatividade do acelerador. O Orbax faz isso sobrepondo operações de E/S com computação, um recurso essencial para cargas de trabalho grandes. O tempo de inatividade dos aceleradores é reduzido à duração da transferência de dados do dispositivo para o host, que pode ser ainda mais sobreposta à próxima etapa de treinamento, tornando o checkpointing quase livre de uma perspectiva de performance.
Basicamente, o Orbax usa o TensorStore para leitura e gravação eficientes e paralelas de dados de matriz. A API Orbax abstrai essa complexidade, oferecendo uma interface fácil de usar para processar PyTrees, que são a representação padrão de modelos no JAX.
Principais pontos fortes:
- Adoção generalizada: com milhões de downloads mensais, o Orbax serve como um meio comum para compartilhar artefatos de ML.
- Simplifica complexidades: o Orbax abstrai as complexidades do checkpointing distribuído, incluindo salvamento assíncrono, atomicidade e detalhes do sistema de arquivos.
- Flexível: embora ofereça APIs para casos de uso comuns, o Orbax permite personalizar seu fluxo de trabalho para lidar com requisitos especializados.
- Alto desempenho e escalonabilidade: recursos como checkpointing assíncrono, um formato de armazenamento eficiente (OCDBT) e estratégias inteligentes de carregamento de dados garantem que o Orbax seja escalonado para execuções de treinamento envolvendo dezenas de milhares de nós.
Granularidade: pipelines de dados de entrada determinísticos e escalonáveis
O Grain é uma biblioteca Python para leitura e processamento de dados para treinamento e avaliação de modelos JAX. Ele é flexível, rápido e determinista, além de oferecer suporte a recursos avançados, como o checkpointing, que são essenciais para treinar grandes cargas de trabalho com sucesso. Ele aceita formatos de dados e back-ends de armazenamento conhecidos, além de oferecer uma API flexível para estender a compatibilidade a formatos e back-ends específicos do usuário que não são compatíveis nativamente. Embora o Grain tenha sido projetado principalmente para funcionar com o JAX, ele é independente de framework, não exige o JAX para ser executado e pode ser usado com outros frameworks também.
Motivação
Os pipelines de dados formam uma parte essencial da infraestrutura de treinamento. Eles precisam ser flexíveis para que as transformações comuns possam ser expressas de maneira eficiente e ter desempenho suficiente para manter os aceleradores ocupados o tempo todo. Eles também precisam ser capazes de acomodar vários formatos de armazenamento e back-ends. Devido aos tempos de etapa mais altos, o treinamento de modelos grandes em escala impõe requisitos adicionais ao pipeline de dados além daqueles exigidos por cargas de trabalho de treinamento regulares, principalmente focados em determinismo e reprodutibilidade2. A biblioteca Grain foi projetada com uma arquitetura flexível que atende a essas necessidades.
2Na seção 5.1 do artigo do PaLM, os autores observam que notaram picos de perda muito grandes, apesar de terem o corte de gradiente ativado. A solução foi remover os lotes de dados ofensivos e reiniciar o treinamento de um checkpoint antes do pico de perda. Isso só é possível com uma configuração de treinamento totalmente determinista e reproduzível.
Design
No nível mais alto, há duas maneiras de estruturar um pipeline de entrada: como um cluster separado de workers de dados ou colocando os workers de dados nos hosts que impulsionam os aceleradores. O Grain escolhe a segunda opção por vários motivos.
Os aceleradores são combinados com hosts potentes que normalmente ficam ociosos durante as etapas de treinamento, o que os torna uma escolha natural para executar o pipeline de dados de entrada. Essa implementação tem outras vantagens: ela simplifica sua visualização do particionamento de dados ao fornecer uma visão consistente do particionamento em entradas e computação. Pode-se argumentar que colocar o worker de dados no host do acelerador corre o risco de saturar a CPU do host. No entanto, isso não impede o descarregamento de transformações com uso intenso de computação para outro cluster usando RPCs3.
Na frente da API, com uma implementação Python pura que oferece suporte a vários processos e uma API flexível, o Grain permite implementar transformações de dados arbitrariamente complexas combinando etapas de pipeline com base em paradigmas de transformação bem compreendidos.
O Grain oferece suporte a formatos de dados de acesso aleatório eficientes, como ArrayRecord e Bagz, além de outros formatos de dados conhecidos, como Parquet e TFDS. O Grain inclui suporte para leitura de sistemas de arquivos locais e do Cloud Storage por padrão. Além de oferecer suporte a formatos e back-ends de armazenamento conhecidos, uma abstração limpa para a camada de armazenamento permite adicionar suporte ou encapsular suas fontes de dados atuais para que sejam compatíveis com a biblioteca Grain.
3É assim que os pipelines de dados multimodais precisam operar. Os tokenizadores de imagem e áudio, por exemplo, são modelos que são executados nos próprios clusters e aceleradores. Os pipelines de entrada fazem chamadas de RPC para converter exemplos de dados em fluxos de tokens.
Pontos fortes
- Ingestão determinística de dados:a colocação do worker de dados com o acelerador e o acoplamento com um embaralhamento global estável e iteradores com capacidade de checkpoint permitem que o estado do modelo e o estado do pipeline de dados sejam verificados juntos em um snapshot consistente usando o Orbax, aumentando o determinismo do processo de treinamento.
- APIs flexíveis para permitir transformações de dados avançadas:uma API de transformações flexível e pura em Python permite realizar transformações de dados extensas no pipeline de processamento de entrada.
- Suporte extensível a vários formatos e back-ends:uma API extensível de fontes de dados é compatível com formatos e back-ends de armazenamento conhecidos e permite adicionar suporte a novos formatos e back-ends.
- Interface de depuração avançada:as ferramentas de visualização de pipeline de dados e um modo de depuração permitem inspecionar, depurar e otimizar o desempenho dos pipelines de dados.
A pilha de IA JAX estendida
Além da pilha principal, um ecossistema rico de bibliotecas especializadas fornece a infraestrutura, as ferramentas avançadas e as soluções de camada de aplicativo necessárias para o desenvolvimento de ML de ponta a ponta.
Infraestrutura fundamental: compiladores e ambientes de execução
XLA: o mecanismo independente de hardware e centrado no compilador
Motivação
O XLA ou Accelerated Linear Algebra é o compilador específico de domínio do Google, que é bem integrado ao JAX e oferece suporte a dispositivos de hardware TPU, CPU e GPU. O XLA foi projetado para ser um gerador de código independente de hardware destinado a TPUs, GPUs e CPUs.
O design do compilador XLA, que prioriza o compilador, é uma escolha arquitetônica fundamental que cria uma vantagem duradoura em um cenário de pesquisa em rápida evolução. Em contraste, a abordagem predominante centrada no kernel em outros ecossistemas depende de bibliotecas otimizadas manualmente para desempenho. Embora isso seja altamente eficaz para arquiteturas de modelos estáveis e bem estabelecidas, cria um gargalo para a inovação. Quando uma nova pesquisa apresenta arquiteturas inovadoras, o ecossistema precisa esperar que novos kernels sejam escritos e otimizados. No entanto, nosso design centrado no compilador geralmente pode ser generalizado para novos padrões, fornecendo um caminho de alto desempenho para pesquisas de ponta desde o primeiro dia.
Design
O XLA funciona compilando Just-In-Time (JIT) os gráficos de computação que o JAX
gera durante o processo de rastreamento (por exemplo, quando uma função é decorada
com @jax.jit).
Essa compilação segue um pipeline de várias etapas:
- Gráfico de computação do JAX
- Otimizador de alto nível (HLO)
- Otimizador de baixo nível (LLO)
- Código do hardware
- Do gráfico JAX para HLO: o gráfico de computação JAX é convertido na representação HLO do XLA. Nesse nível, são aplicadas otimizações poderosas e independentes de hardware, como fusão de operadores e gerenciamento eficiente de memória. O dialeto StableHLO serve como uma interface durável e com versão para essa etapa.
- Do HLO ao LLO:depois das otimizações de alto nível, os back-ends específicos do hardware assumem o controle, reduzindo a representação do HLO para um LLO orientado à máquina.
- Do LLO ao código de hardware:o LLO é finalmente compilado em código de máquina altamente eficiente. Para TPUs, esse código é agrupado como pacotes de palavra de instrução muito longa (VLIW), que são enviados diretamente ao hardware.
Para escalonamento, o design do XLA é criado com base no paralelismo. Ele usa algoritmos para aproveitar ao máximo as unidades de multiplicação de matriz (MXUs) em um chip. Entre chips, o XLA usa SPMD (programa único e vários dados), uma técnica de paralelização baseada em compilador que usa um único programa em todos os dispositivos. Esse modelo poderoso é exposto pelas APIs JAX, permitindo que você gerencie dados, modelos ou paralelismo de pipeline com anotações de fragmentação de alto nível.
Para padrões de paralelismo mais complexos, também é possível usar vários programas e vários dados (MPMD). Além disso, bibliotecas como PartIR:MPMD permitem que os usuários do JAX forneçam anotações MPMD.
Pontos fortes
- Compilação: a compilação just-in-time do gráfico de computação permite otimizações no layout de memória, na alocação de buffer e no gerenciamento de memória. Alternativas como metodologias baseadas em kernel colocam esse ônus no desenvolvedor. Na maioria dos casos, o XLA pode alcançar um desempenho excelente sem comprometer a velocidade do desenvolvedor.
- Paralelismo:o XLA implementa várias formas de paralelismo com SPMD, e isso é exposto no nível do JAX. Isso permite expressar estratégias de fragmentação, possibilitando a experimentação e a escalonabilidade de modelos em milhares de chips.
Caminhos: um ambiente de execução unificado para computação distribuída em grande escala
Os Pathways oferecem abstrações para treinamento e inferência distribuídos com tolerância e recuperação de falhas integradas, permitindo que os pesquisadores de ML programem como se estivessem usando uma única máquina poderosa.
Motivação
Para treinar e implantar modelos grandes, são necessários centenas ou milhares de chips. Esses chips estão espalhados por vários racks e máquinas host. Um job de treinamento é um programa síncrono em grande escala que exige que todos esses chips e os respectivos hosts trabalhem em conjunto em computações XLA paralelizadas (fragmentadas). No caso de modelos de linguagem grandes, que podem precisar de mais de dezenas de milhares de chips, esse serviço precisa ser capaz de abranger vários pods em uma estrutura de data center, além de usar interconexão entre chips (ICI) e interconexão no chip (OCI) em um pod.
Design
O ML Pathways é o sistema que usamos para coordenar computações distribuídas em hosts e chips de TPU. Ele foi projetado para escalonabilidade e eficiência em centenas de milhares de aceleradores. Para treinamento em grande escala, ele oferece um único cliente Python para vários jobs de pod, integração do Megascale XLA, serviço de compilação e Python remoto. Ele também oferece suporte ao paralelismo entre intervalos e à tolerância de remoção, permitindo a recuperação automática de remoções de recursos.
O Pathways incorpora coletivos otimizados entre hosts que permitem que os gráficos de computação XLA se estendam além de um único pod de TPU. Ele expande o suporte do XLA para paralelismo de dados, modelos e pipelines para trabalhar em limites de fração de TPU usando a rede do data center (DCN) ao integrar um tempo de execução distribuído que gerencia a comunicação da DCN com primitivas de comunicação do XLA.
Pontos fortes
A arquitetura de controlador único, integrada ao JAX, é uma abstração fundamental. Isso permite que os pesquisadores explorem várias estratégias de fragmentação e paralelismo para treinamento e implantação, além de facilitar o escalonamento para dezenas de milhares de chips.
Desenvolvimento avançado: performance, dados e eficiência
Pallas: como escrever kernels personalizados de alto desempenho em JAX
Embora o JAX seja um compilador, há situações em que você pode querer um controle refinado sobre o hardware para alcançar o desempenho máximo. O Pallas é uma
extensão do JAX que permite escrever kernels personalizados para GPUs e TPUs. O objetivo é
oferecer controle preciso sobre o código gerado, combinado com a ergonomia
de alto nível do rastreamento do JAX e da API jax.numpy.
O Pallas expõe um modelo de paralelismo baseado em grade em que uma função de kernel definida pelo usuário é iniciada em uma grade multidimensional de grupos de trabalho paralelos. Ele permite o gerenciamento explícito da hierarquia de memória, definindo como os tensores são segmentados e transferidos entre uma memória maior e mais lenta (por exemplo, HBM) e uma memória on-chip menor e mais rápida (por exemplo, VMEM na TPU, memória compartilhada na GPU), usando mapas de índice para associar locais de grade a blocos de dados específicos. O Pallas pode reduzir a mesma definição de kernel para executar de forma eficiente em TPUs do Google e em várias GPUs. Para isso, ele compila kernels em uma representação intermediária adequada para a arquitetura de destino: Mosaic para TPUs ou tecnologias como Triton para GPUs. Com o Pallas, é possível escrever kernels de alto desempenho que especializam blocos como atenção para alcançar o melhor desempenho do modelo no hardware de destino sem precisar depender de kits de ferramentas específicos do fornecedor.
Tokamax: uma biblioteca selecionada de kernels de última geração
Se o Pallas é uma ferramenta para criar kernels, o Tokamax é uma biblioteca de kernels de aceleradores personalizados de última geração que oferecem suporte a TPUs e GPUs. O Tokamax é criado com base no JAX e no Pallas e permite usar todo o poder do hardware. Ele também oferece ferramentas para criar e ajustar automaticamente kernels personalizados.
Motivação
O JAX, com raízes no XLA, é uma estrutura de trabalho que prioriza o compilador. No entanto, há um conjunto limitado de casos em que talvez seja necessário controlar diretamente o hardware para alcançar o desempenho máximo4. Os kernels personalizados são essenciais para conseguir o melhor desempenho de recursos caros de aceleradores de ML, como TPUs e GPUs. Embora sejam amplamente usadas para permitir a execução eficiente de operadores principais, como a atenção, a implementação delas exige um conhecimento profundo do modelo e da arquitetura de hardware de destino. O Tokamax oferece uma fonte confiável de kernels selecionados, bem testados e de alto desempenho, além de uma infraestrutura compartilhada robusta para desenvolvimento, manutenção e gerenciamento do ciclo de vida. Essa biblioteca também pode servir como uma implementação de referência para você criar e personalizar conforme necessário. Assim, você pode se concentrar nos seus esforços de modelagem sem se preocupar com a infraestrutura.
4Esse é um paradigma bem estabelecido e tem precedentes no mundo da CPU, em que o código compilado forma a maior parte do programa, e os desenvolvedores usam intrínsecos ou assembly inline para otimizar seções críticas de desempenho.
Design
Para qualquer kernel, o Tokamax fornece uma API comum que pode ser compatível com várias implementações. Por exemplo, os kernels de TPU podem ser implementados por redução padrão do XLA ou explicitamente com Pallas/Mosaic-TPU. Os kernels de GPU podem ser implementados por redução padrão da XLA, com Mosaic-GPU ou Triton. Por padrão, a API Tokamax escolhe a implementação mais conhecida para uma determinada configuração, determinada por resultados armazenados em cache de execuções periódicas de ajuste automático e comparativos de mercado. No entanto, é possível escolher implementações específicas, se necessário. Novas implementações podem ser adicionadas ao longo do tempo para aproveitar melhor recursos específicos em novas gerações de hardware e melhorar ainda mais a performance.
Um componente essencial da biblioteca Tokamax, além dos próprios kernels, é a infraestrutura de suporte que permite escrever kernels personalizados. Por exemplo, a infraestrutura de ajuste automático permite definir um conjunto de parâmetros configuráveis (como tamanhos de bloco) que o Tokamax pode usar para fazer uma varredura completa e determinar e armazenar em cache as melhores configurações ajustadas possíveis. As regressões noturnas protegem você contra problemas inesperados de desempenho e numéricos causados por mudanças na infraestrutura do compilador ou em outras dependências.
Pontos fortes
- Experiência do desenvolvedor integrada:uma biblioteca unificada e selecionada oferece implementações de alto desempenho e conhecidas de kernels principais, com expressões claras de gerações de hardware compatíveis e desempenho esperado, tanto de forma programática quanto na documentação. Isso minimiza a fragmentação e o churn.
- Flexibilidade e gerenciamento do ciclo de vida:você pode escolher diferentes implementações, até mesmo mudando-as com o tempo, se for apropriado. Por exemplo, se o compilador XLA melhorar o suporte para determinadas operações e não exigir mais kernels personalizados, haverá um caminho para descontinuação e migração.
- Extensibilidade:você pode implementar seus próprios kernels e aproveitar uma infraestrutura compartilhada bem compatível, permitindo que você se concentre em recursos e otimizações de valor agregado. Implementações padrão claramente criadas servem como ponto de partida para os usuários aprenderem e ampliarem.
Qwix: quantização não intrusiva e abrangente
O Qwix é uma biblioteca de quantização abrangente para a pilha de IA do JAX, compatível com LLMs e outros tipos de modelos em todas as etapas, incluindo treinamento (treinamento com reconhecimento de quantização (QAT), técnica de quantização (QT), adaptação de baixa classificação quantizada (QLoRA)) e inferência pós quantização pós-treinamento (PTQ), direcionada a tempos de execução XLA e no dispositivo.
Motivação
As bibliotecas de quantização atuais, principalmente no ecossistema PyTorch, geralmente têm propósitos limitados (por exemplo, apenas PTQ ou apenas QLoRA). Esse cenário fragmentado força você a trocar de ferramentas, impedindo o uso consistente de código e a correspondência numérica precisa entre treinamento e inferência. Além disso, muitas soluções exigem modificações substanciais no modelo, acoplando a lógica do modelo à lógica de quantização.
Design
A filosofia de design do Qwix enfatiza uma solução abrangente e, principalmente, uma integração de modelo não intrusiva. Ela é arquitetada com um design hierárquico e extensível, criado com APIs funcionais reutilizáveis.
Essa integração não intrusiva é alcançada por um mecanismo de interceptação meticulosamente projetado que redireciona as funções JAX para as contrapartes quantizadas. Isso permite integrar seus modelos sem modificações, desacoplando completamente o código de quantização das definições de modelo.
O exemplo a seguir demonstra a aplicação da quantização w4a4 (um peso de 4 bits, ativação de 4 bits) às camadas MLP de um LLM e da quantização w8 (um peso de 8 bits) ao incorporador. Para mudar a receita de quantização, basta atualizar a lista de regras.
fp_model = ModelWithoutQuantization(...)
rules = [
qwix.QuantizationRule(
module_path=r'embedder',
weight_qtype='int8',
),
qwix.QuantizationRule(
module_path=r'layers_\d+/mlp',
weight_qtype='int4',
act_qtype='int4',
tile_size=128,
weight_calibration_method='rms,7',
),
]
quantized_model = qwix.quantize_model(fp_model, qwix.PtqProvider(rules))
Pontos fortes
- Solução abrangente:o Qwix é amplamente aplicável em vários cenários de quantização, garantindo o uso consistente do código entre treinamento e inferência.
- Integração de modelos não intrusiva:como o exemplo mostra, é possível integrar modelos com uma única linha de código. Isso permite usar hiperparâmetros em vários esquemas de quantização para encontrar o melhor trade-off entre qualidade e desempenho.
- Federação com outras bibliotecas:o Qwix se integra perfeitamente à pilha de IA do JAX. Por exemplo, o Tokamax se adapta automaticamente para usar versões quantizadas de kernels, sem código adicional do usuário, quando o modelo é quantizado com o Qwix.
- Adequado para pesquisa:as APIs fundamentais e a arquitetura extensível do Qwix permitem que os pesquisadores explorem novos algoritmos e facilitam comparações simples com ferramentas integradas de comparativo e avaliação.
A camada de aplicação: treinamento e alinhamento
Treinamento do modelo de fundação: MaxText e MaxDiffusion
O MaxText e o MaxDiffusion são os principais frameworks de treinamento de LLM e modelo de difusão do Google, respectivamente. Esses repositórios contêm uma seleção de implementações altamente otimizadas de modelos de código aberto conhecidos. Elas têm uma dupla finalidade: funcionam como uma base de código de treinamento de modelo pronta para uso e como uma referência que os criadores de modelos de fundação podem usar para criar.
Motivação
Há um rápido crescimento do interesse em treinar modelos de IA generativa em todo o setor. A popularidade dos modelos abertos acelerou essa tendência, fornecendo arquiteturas comprovadas. O treinamento e a adaptação desses modelos exigem alto desempenho, eficiência, escalonabilidade para um grande número de chips e código claro e compreensível. O MaxText e o MaxDiffusion são soluções abrangentes que podem ser usadas em TPUs ou GPUs e foram projetadas para atender a essas necessidades.
Design
O MaxText e o MaxDiffusion são bases de código de modelo de fundação projetadas com legibilidade e desempenho em mente. Eles são estruturados com componentes reutilizáveis e bem testados: definições de modelo que usam kernels personalizados (como o Tokamax) para desempenho máximo, um arnês de treinamento para orquestração e monitoramento e um sistema de configuração avançado que permite controlar detalhes como fragmentação e quantização (usando o Qwix) por uma interface intuitiva. Recursos avançados de confiabilidade, como o checkpointing de vários níveis, são incorporados para garantir uma boa taxa de transferência sustentada.
O MaxText e o MaxDiffusion usam as melhores bibliotecas JAX (Qwix, Tunix, Orbax e Optax) para oferecer recursos principais. Essas bibliotecas oferecem uma infraestrutura robusta e escalonável, reduzindo a sobrecarga de desenvolvimento e permitindo que você se concentre na tarefa de modelagem. Para inferência, o código do modelo é compartilhado para permitir uma disponibilização eficiente e escalonável.
Pontos fortes
- Performance por design:com a infraestrutura de treinamento configurada para alto "goodput" (capacidade de processamento útil) e implementações de modelo otimizadas para alta MFU (utilização de flops do modelo), o MaxText e o MaxDiffusion oferecem alto desempenho em escala imediatamente.
- Criado para escalonamento:aproveitando o poder da pilha de IA JAX (especialmente Pathways), esses frameworks permitem escalonar sem problemas de dezenas a dezenas de milhares de chips.
- Base sólida para criadores de modelos de fundação:as implementações legíveis e de alta qualidade servem como um ponto de partida sólido para os desenvolvedores usarem como uma solução completa ou como uma implementação de referência para as próprias personalizações.
Pós-treinamento e alinhamento: o framework Tunix
O Tunix oferece algoritmos de aprendizado por reforço (RL, na sigla em inglês) de código aberto de última geração, além de um framework e uma infraestrutura robustos, oferecendo um caminho simplificado para que os desenvolvedores testem técnicas de pós-treinamento de LLM, incluindo ajuste fino supervisionado (SFT) e alinhamento usando JAX e TPUs.
Motivação
A pós-treinamento é uma etapa essencial para aproveitar todo o potencial dos LLMs. A etapa de aprendizado por reforço (RL, na sigla em inglês) é particularmente crucial para desenvolver recursos de alinhamento e raciocínio. O desenvolvimento de código aberto nessa área tem sido quase exclusivamente baseado em PyTorch e GPUs, deixando uma lacuna fundamental para soluções de JAX e TPU. O Tunix (Tune-in-JAX) é uma biblioteca de alto desempenho nativa do JAX projetada para preencher essa lacuna.
Design
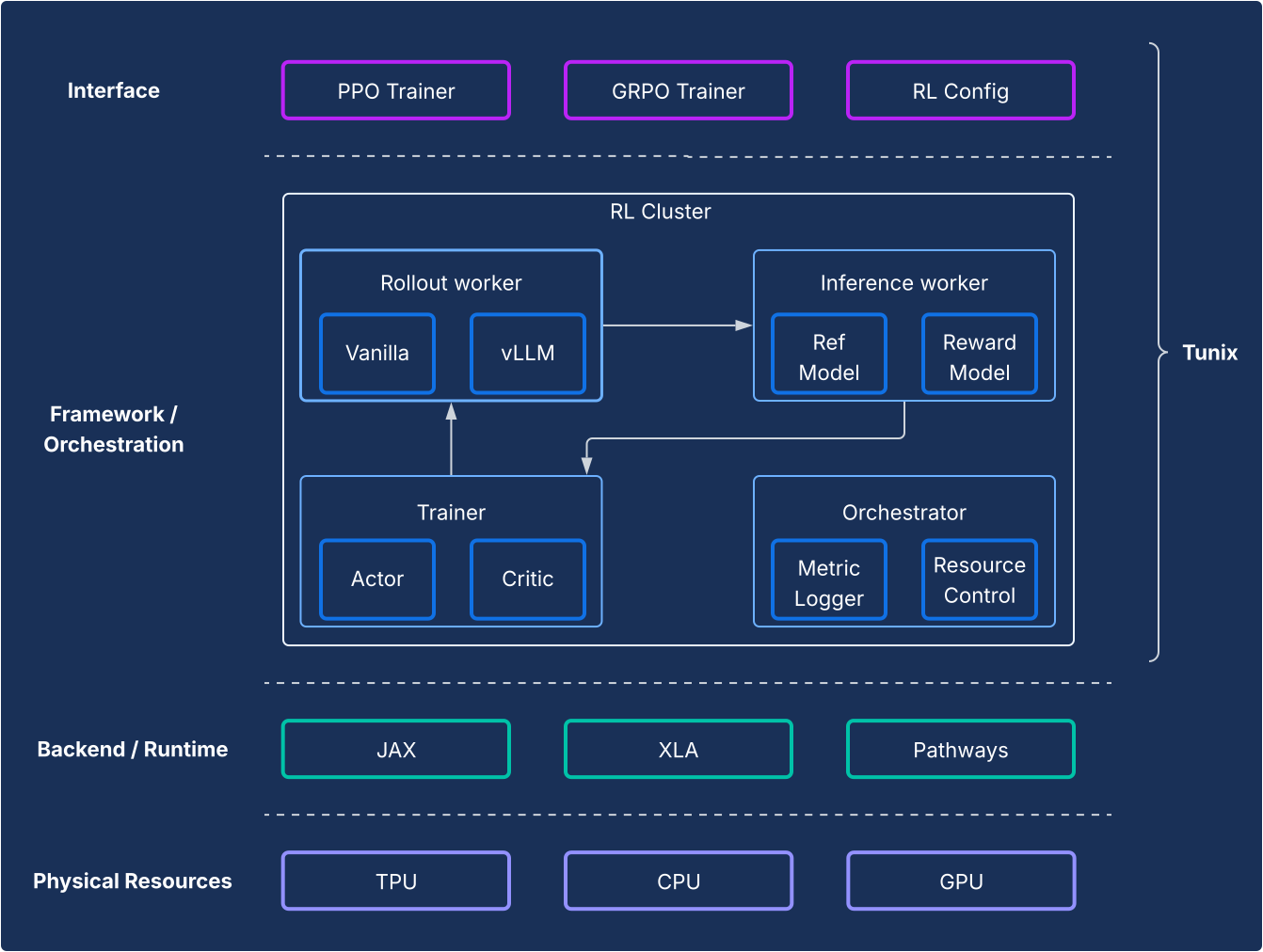
Do ponto de vista do framework, o Tunix permite uma configuração de última geração que separa claramente os algoritmos de RL da infraestrutura. Ela oferece uma API leve, semelhante a um cliente, que oculta a complexidade da infraestrutura de RL, permitindo que você desenvolva novos algoritmos. O Tunix oferece soluções prontas para uso para algoritmos conhecidos, incluindo otimização de política proximal (PPO), otimização de preferência direta (DPO) e outros.
Na parte de infraestrutura, o Tunix tem integração com o Pathways, permitindo uma arquitetura de controlador único que torna acessível o treinamento de RL de vários nós. No treinamento, o Tunix oferece suporte nativo ao treinamento eficiente em termos de parâmetros (por exemplo, LoRA) e usa o sharding do JAX e o XLA (paralelização geral e escalonável para gráfico de computação de ML (GSPMD)) para gerar um gráfico de computação de alto desempenho. Ele oferece suporte a modelos de código aberto conhecidos, como Gemma e Llama, sem precisar de configuração.
Pontos fortes
- Simplicidade:ela oferece uma API de alto nível, semelhante a um cliente, que abstrai as complexidades da infraestrutura distribuída subjacente.
- Eficiência do desenvolvedor:o Tunix acelera o ciclo de vida de P&D com algoritmos e "receitas" integrados, oferecendo um modelo funcional e permitindo iterações rápidas.
- Performance e escalonabilidade:o Tunix permite uma infraestrutura de treinamento altamente eficiente e escalonável horizontalmente ao aproveitar os Pathways como um único controlador no back-end.
A camada de aplicativo: produção e inferência
Um desafio histórico para a adoção do JAX tem sido o caminho da pesquisa para a produção. A pilha de IA do JAX agora oferece uma história de produção madura e dupla que oferece compatibilidade com o ecossistema e desempenho do JAX.
Inferência de LLM de alto desempenho: a solução vLLM
O vLLM-TPU é a pilha de inferência de alta performance do Google projetada para executar modelos de linguagem grandes (LLMs) do PyTorch e do JAX de maneira eficiente em TPUs do Cloud. Isso é possível porque ele integra nativamente o framework vLLM de código aberto com o ecossistema JAX e TPU do Google.
Motivação
O setor está evoluindo rapidamente, com uma demanda crescente por soluções de inferência integradas, de alto desempenho e fáceis de usar. Os desenvolvedores geralmente enfrentam desafios significativos devido a ferramentas complexas e inconsistentes, desempenho abaixo do ideal e compatibilidade limitada de modelos. A pilha vLLM resolve esses problemas fornecendo uma plataforma unificada, eficiente e intuitiva.
Design
Essa solução estende o framework vLLM, em vez de reinventá-lo. O vLLM-TPU é um mecanismo de veiculação de LLM de código aberto altamente otimizado conhecido pela alta capacidade de processamento, alcançada usando recursos principais como PagedAttention (que gerencia caches KV como memória virtual para minimizar a fragmentação) e Lotes contínuos (que adicionam solicitações dinamicamente ao lote para melhorar a utilização).
O vLLM-TPU se baseia nessa fundação e desenvolve componentes principais para processamento, programação e gerenciamento de memória de solicitações. Ele apresenta um backend baseado em JAX que atua como uma ponte, traduzindo o gráfico computacional e as operações de memória do vLLM em código executável na TPU. Esse back-end processa interações com dispositivos, execução de modelos JAX e os detalhes do gerenciamento do cache KV no hardware de TPU. Ele incorpora otimizações específicas da TPU, como mecanismos de atenção eficientes (por exemplo, aproveitando os kernels JAX Pallas para atenção paginada irregular) e quantização, tudo adaptado para a arquitetura da TPU.
Pontos fortes
- Custo zero de integração/desintegração para usuários:os usuários podem adotar essa solução sem grandes dificuldades. Do ponto de vista da experiência do usuário, o processamento de solicitações de inferência em TPUs deve ser o mesmo que em GPUs. A CLI para iniciar o servidor, aceitar solicitações e retornar saídas é compartilhada.
- Aproveite totalmente o ecossistema:essa abordagem usa e contribui para a interface e a experiência do usuário do vLLM, garantindo compatibilidade e facilidade de uso.
- Fungibilidade entre TPUs e GPUs:a solução funciona de maneira eficiente em TPUs e GPUs, oferecendo flexibilidade.
- Econômico (melhor desempenho/custo): otimiza o desempenho para oferecer a melhor relação desempenho/custo para modelos conhecidos.
Veiculação do JAX: serialização do Orbax e mecanismo de veiculação do Neptune
Para modelos que não sejam LLMs ou para usuários que desejam um pipeline totalmente nativo do JAX, a biblioteca de serialização Orbax e o sistema de mecanismo de exibição do Neptune (NSE, na sigla em inglês) oferecem uma solução de exibição completa e de alta performance.
Motivação
Historicamente, os modelos do JAX costumavam depender de um caminho indireto para a produção, como serem encapsulados em gráficos do TensorFlow e implantados usando o TensorFlow Serving. Essa abordagem introduziu limitações e ineficiências significativas, forçando os desenvolvedores a interagir com um ecossistema separado e diminuindo a iteração. Um sistema de veiculação dedicado nativo do JAX é essencial para sustentabilidade, redução da complexidade e desempenho otimizado.
Design
Esta solução consiste em dois componentes principais, conforme ilustrado no diagrama a seguir.
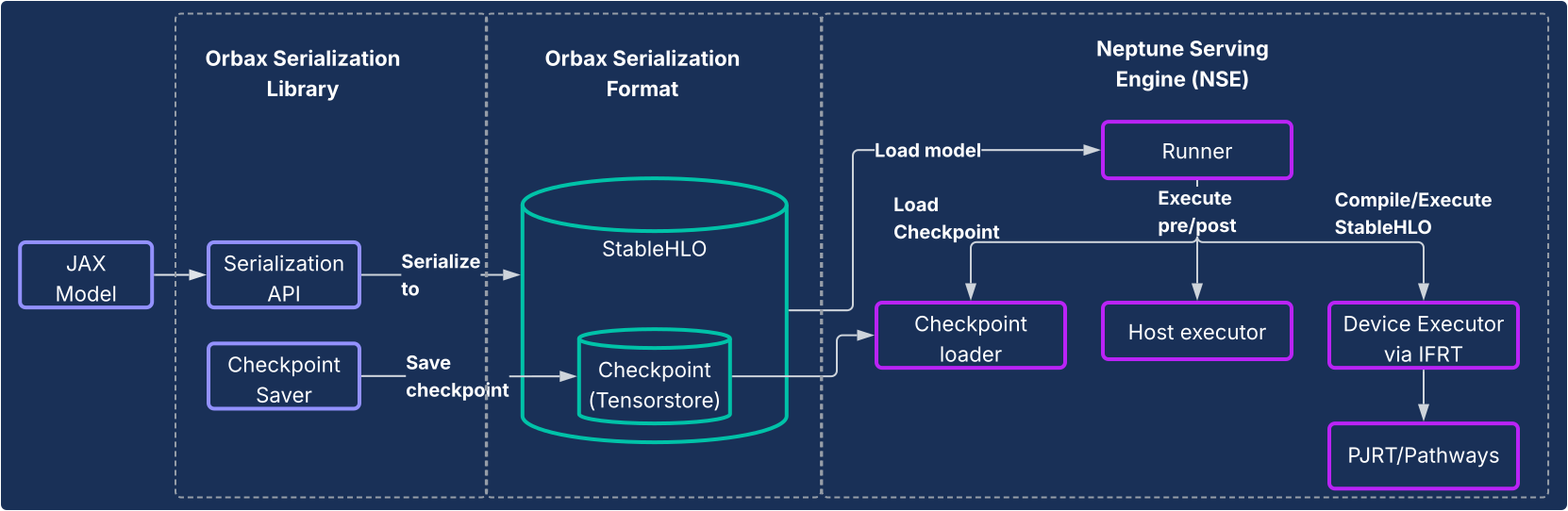
- Biblioteca de serialização do Orbax:oferece APIs fáceis de usar para serializar modelos do JAX em um novo formato de serialização robusto do Orbax. Esse formato é otimizado para implantação em produção. Ele representa diretamente as computações do modelo JAX usando StableHLO, permitindo que o gráfico de computação seja representado de forma nativa. Ele também usa o TensorStore para armazenar pesos, permitindo o carregamento rápido de checkpoints para veiculação.
- Neptune Serving Engine (NSE): é o mecanismo de exibição flexível e de alto desempenho (geralmente implantado como um binário C++) projetado para executar modelos JAX no formato Orbax de maneira nativa. O NSE oferece recursos essenciais para produção, como carregamento rápido de modelos, disponibilização simultânea de alta capacidade com agrupamento em lote integrado, suporte para várias versões de modelos e disponibilização de host único e múltiplo (aproveitando PJRT e Pathways). Use o Neptune Serving Engine para:
- Modelos não LLM: é uma solução de uso geral ideal para cargas de trabalho como sistemas de recomendação, modelos de difusão e outros modelos de IA.
- LLMs pequenos e exibição "única": projetado para modelos não autorregressivos ou menores que são exibidos de maneira "unária", em que toda a saída é gerada em uma única transmissão sem a necessidade de gerenciamento de estado complexo, como um cache KV.
Em resumo, o Neptune Serving Engine preenche a lacuna para veicular a grande variedade de modelos que não são modelos de linguagem grandes e autorregressivos, oferecendo uma solução nativa de TPU de alta performance para o ecossistema de ML mais amplo.
Pontos fortes
- Disponibilização nativa do JAX:a solução é criada nativamente para o JAX, eliminando o overhead entre frameworks na serialização e disponibilização de modelos. Isso garante carregamento rápido do modelo e execução otimizada em CPUs, GPUs e TPUs.
- Implantação de produção sem esforço:os modelos serializados oferecem um caminho de implantação hermético que não é afetado pelo desvio nas dependências do Python e permite verificações de integridade do modelo em tempo de execução. Isso oferece um caminho simples e intuitivo para a produção de modelos do JAX.
- Experiência de desenvolvedor aprimorada:ao eliminar a necessidade de um encapsulamento de framework complicado, essa solução reduz significativamente as dependências e a complexidade do sistema, acelerando a iteração para desenvolvedores do JAX.
Análise e criação de perfis em todo o sistema
XProf: criação de perfil de desempenho detalhada e integrada ao hardware
O XProf é uma ferramenta de criação de perfis e análise de desempenho que oferece visibilidade detalhada de vários aspectos da execução de cargas de trabalho de ML, permitindo depurar e otimizar o desempenho. Ele está totalmente integrado aos ecossistemas do JAX e da TPU.
Motivação
Por um lado, as cargas de trabalho de ML estão ficando cada vez mais complicadas. Por outro lado, há uma explosão de recursos de hardware especializados voltados para essas cargas de trabalho. É fundamental combinar os dois de maneira eficaz para garantir o máximo de desempenho e eficiência, considerando os enormes custos da infraestrutura de ML. Isso exige visibilidade detalhada da carga de trabalho e do hardware, apresentada de forma rapidamente consumível. O XProf é excelente nisso.
Design
O XProf consiste em dois componentes principais: coleta e análise.
- Coleta:o XProf captura informações de várias fontes: anotações no seu código JAX, modelos de custo para operações no compilador XLA e recursos de criação de perfil de hardware criados especificamente na TPU. Essa coleta pode ser acionada programaticamente ou sob demanda, gerando um artefato de evento abrangente.
- Análise:o XProf pós-processa os dados coletados e cria um conjunto de visualizações avançadas, acessadas com um navegador.
Pontos fortes
O verdadeiro poder do XProf vem da integração profunda com a pilha completa, oferecendo uma amplitude e profundidade de análise que é um benefício tangível do ecossistema JAX/TPU projetado em conjunto.
- Projetado em conjunto com a TPU:o XProf usa recursos de hardware projetados especificamente para coleta de perfis sem problemas, permitindo uma sobrecarga de coleta de menos de 1%. Isso permite que a criação de perfis seja uma parte leve e iterativa do desenvolvimento.
- Amplitude e profundidade da análise:o XProf gera análises detalhadas em vários eixos. As ferramentas incluem:
- Trace Viewer:uma visualização da linha do tempo de execução de operações em diferentes unidades de hardware (por exemplo, TensorCores).
- Perfil de operação de HLO:divide o tempo total gasto em diferentes categorias de operações.
- Memory Viewer:detalha as alocações de memória por diferentes operações durante a janela analisada.
- Análise de desempenho máximo:ajuda a identificar se operações específicas estão vinculadas à computação ou à memória e a distância delas em relação aos recursos máximos do hardware.
- Visualizador de gráficos:oferece uma visão do gráfico HLO completo executado pelo hardware.
Uma perspectiva comparativa: a pilha JAX/TPU como uma opção atraente
O cenário moderno de machine learning oferece muitas toolchains excelentes e maduras. A pilha de IA do JAX apresenta um conjunto único e atraente de vantagens para desenvolvedores focados em ML de alto desempenho e em grande escala, decorrentes diretamente do design modular e do co-design de hardware avançado.
Embora muitos frameworks ofereçam uma ampla variedade de recursos, a JAX AI Stack oferece diferenciais específicos e poderosos em áreas importantes do ciclo de vida de desenvolvimento:
- Uma experiência de desenvolvedor mais simples e poderosa:o paradigma de transformação de gradiente encadeável do Optax permite estratégias de otimização mais poderosas e flexíveis que são declaradas uma vez, em vez de serem gerenciadas de forma imperativa no loop de treinamento. No nível do sistema, a interface de controlador único mais simples do Pathways abstrai a complexidade do treinamento multislice, uma simplificação significativa para os pesquisadores.
- Projetado para resiliência em grande escala:a pilha JAX foi criada para treinamento em grande escala. O Orbax oferece recursos de "resiliência de treinamento em escala heroica" como checkpoints de emergência e de vários níveis. Isso é complementado pelo Grain, que oferece suporte total à reprodutibilidade com embaralhamentos globais determinísticos e carregadores de dados com capacidade de checkpoint. A capacidade de criar um ponto de verificação atômico do estado do pipeline de dados (Grain) com o estado do modelo (Orbax) é fundamental para garantir a capacidade de reprodução em jobs de longa duração.
- Um ecossistema completo de ponta a ponta:a pilha oferece uma solução coesa de ponta a ponta. Os desenvolvedores podem usar o MaxText como uma referência SOTA para treinamento, o Tunix para alinhamento e seguir um caminho duplo e claro para a produção com o vLLM-TPU (para compatibilidade com vLLM) e o NSE (para desempenho do JAX).
Embora muitas stacks sejam semelhantes do ponto de vista de software de alto nível, o fator decisivo geralmente se resume a Performance/TCO, que é onde o projeto conjunto do JAX e das TPUs oferece uma vantagem distinta. Esse benefício de performance/TCO é resultado direto da integração vertical entre o software e o hardware da TPU. A capacidade do compilador XLA de combinar operações especificamente para a arquitetura de TPU ou do criador de perfis XProf de usar hooks de hardware para criação de perfis com menos de 1% de sobrecarga são benefícios tangíveis dessa integração profunda.
Para organizações que adotam essa pilha, a natureza completa da pilha de IA do JAX minimiza o custo da migração. Para clientes que usam arquiteturas de modelos abertos populares, a mudança de outros frameworks para o MaxText geralmente é uma questão de configurar arquivos de configuração. Além disso, a capacidade da pilha de ingerir formatos de checkpoint populares, como safetensors, permite que os checkpoints atuais sejam migrados sem a necessidade de um novo treinamento caro.
A tabela a seguir mostra um mapeamento dos componentes fornecidos pela pilha de IA do JAX e seus equivalentes em outros frameworks ou bibliotecas.
| Function | JAX | Alternativas/equivalentes em outras estruturas5 |
| Compilador / ambiente de execução | Álgebra linear acelerada (XLA, na sigla em inglês) | Indutor, ansioso |
| Treinamento com vários pods | Módulos | Estratégias de iluminação do Torch, Ray Train, Monarch (novo). |
| Framework principal | JAX | PyTorch |
| Criação de modelos | Modelos Flax, Max* | torch.nn.*,
NVidia TransformerEngine, Transformers do HuggingFace
|
| Otimizadores e perdas | Optax | torch.optim.*, torch.nn.*Loss |
| Carregadores de dados | Granulação | Ray Data, carregadores de dados do HuggingFace |
| Como estabelecer pontos de verificação | Orbax | Checkpoint distribuído do PyTorch e do NeMo |
| Quantização | Qwix | TorchAO, bitsandbytes |
| Criação de kernel e implementações conhecidas | Pallas / Tokamax | Triton/Helion, Liger-kernel, TransformerEngine |
| Pós-treinamento / ajuste | Tunix | VERL, NeMoRL |
| Criação de perfil | XProf | Criador de perfil do PyTorch, sistemas NSight, NSight Compute |
| Treinamento do modelo de fundação | MaxText, MaxDiffusion | NeMo-Megatron, DeepSpeed, TorchTitan |
| Inferência de LLM | vLLM | SGLang |
| Inferência não relacionada a LLM | NSE | Servidor de inferência Triton, RayServe |
5Alguns dos equivalentes aqui não são comparações sempre verdadeiras porque outros frameworks definem limites de API de maneira diferente em comparação com o JAX. A lista de equivalentes não é completa, e novas bibliotecas aparecem com frequência.
Conclusão: uma plataforma durável e pronta para produção para o futuro da IA
Os dados fornecidos na tabela anterior ilustram uma conclusão evidente: essas stacks têm pontos fortes e fracos em um pequeno número de áreas, mas são muito semelhantes do ponto de vista do software. As duas stacks oferecem soluções prontas para pré-treinamento, adaptação pós-treinamento e implantação de modelos fundamentais.
A pilha de IA do JAX oferece uma solução atraente e robusta para treinar e implantar modelos de ML em qualquer escala. Ele aproveita a integração vertical profunda em software e hardware de TPU para oferecer desempenho líder da categoria e custo total de propriedade.
Ao se basear em sistemas internos testados em batalha, a pilha evoluiu para oferecer confiabilidade e escalonabilidade inerentes, permitindo que os usuários desenvolvam e implantem com confiança até mesmo os maiores modelos. O design modular e combinável, baseado na filosofia da pilha de IA JAX, oferece aos usuários liberdade e controle incomparáveis, permitindo que eles adaptem a pilha às necessidades específicas sem as restrições de uma estrutura monolítica.
Com o XLA e o Pathways fornecendo uma base escalonável e tolerante a falhas, o JAX oferecendo uma biblioteca numérica eficiente e expressiva, bibliotecas de desenvolvimento principais eficientes como Flax, Optax, Grain e Orbax, ferramentas avançadas de desempenho como Pallas, Tokamax e Qwix, além de uma camada robusta de aplicativos e produção em MaxText, vLLM e NSE, a pilha de IA do JAX oferece uma base durável para os usuários criarem e levarem rapidamente pesquisas de ponta para a produção.