
Chirp 3 adalah model generatif khusus Pengenalan Ucapan Otomatis (ASR) multi-bahasa generasi terbaru dari Google, yang dirancang untuk memenuhi kebutuhan pengguna berdasarkan masukan dan pengalaman. Chirp 3 memberikan akurasi dan kecepatan yang lebih baik dibandingkan model Chirp sebelumnya, serta menyediakan diarisasi dan deteksi bahasa otomatis.
Detail model
Chirp 3: Transkripsi, hanya tersedia dalam Speech-to-Text API V2.
ID model
Anda dapat menggunakan Chirp 3: Transcription seperti model lainnya dengan menentukan ID model yang sesuai dalam permintaan pengenalan saat menggunakan API atau nama model saat berada di konsol Google Cloud . Tentukan ID yang sesuai dalam pengenalan Anda.
| Model | Pengenal model |
|---|---|
| Chirp 3 | chirp_3 |
Metode API
Tidak semua metode pengenalan mendukung set ketersediaan bahasa yang sama. Karena Chirp 3 tersedia di Speech-to-Text API V2, Chirp 3 mendukung metode pengenalan berikut:
| Versi API | Metode API | Dukungan |
|---|---|---|
| V2 | Speech.StreamingRecognize (cocok untuk streaming dan audio real-time) | Didukung |
| V2 | Speech.Recognize (cocok untuk audio yang berdurasi kurang dari satu menit) | Didukung |
| V2 | Speech.BatchRecognize (cocok untuk audio berdurasi panjang 1 menit hingga 1 jam secara umum, tetapi hingga 20 menit jika stempel waktu tingkat kata diaktifkan) | Didukung |
Ketersediaan regional
Chirp 3 tersedia di region Google Cloud berikut, dan akan tersedia di lebih banyak region lainnya:
| Google Cloud Zona | Kesiapan Peluncuran |
|---|---|
us (multi-region) |
GA |
eu (multi-region) |
GA |
Dengan menggunakan API lokasi seperti yang dijelaskan di sini, Anda dapat menemukan daftar terbaru Google Cloud wilayah, bahasa, dan lokalitas, serta fitur yang didukung untuk setiap model transkripsi.
Ketersediaan bahasa untuk transkripsi
Chirp 3 mendukung transkripsi dalam StreamingRecognize, Recognize, dan BatchRecognize dalam
bahasa berikut:
| Bahasa | BCP-47 Code |
Kesiapan Peluncuran |
| Katala (Spanyol) | ca-ES | GA |
| China (Aksara Sederhana, China) | cmn-Hans-CN | GA |
| Kroasia (Kroasia) | hr-HR | GA |
| Denmark (Denmark) | da-DK | GA |
| Belanda (Belanda) | nl-NL | GA |
| Inggris (Australia) | en-AU | GA |
| Inggris (India) | en-IN | GA |
| Inggris (Inggris Raya) | en-GB | GA |
| Inggris (Amerika Serikat) | en-US | GA |
| Finlandia (Finlandia) | fi-FI | GA |
| Prancis (Kanada) | fr-CA | GA |
| Prancis (Prancis) | fr-FR | GA |
| Jerman (Jerman) | de-DE | GA |
| Yunani (Yunani) | el-GR | GA |
| Hindi (India) | hi-IN | GA |
| Italia (Italia) | it-IT | GA |
| Jepang (Jepang) | ja-JP | GA |
| Korea (Korea) | ko-KR | GA |
| Polandia (Polandia) | pl-PL | GA |
| Portugis (Brasil) | pt-BR | GA |
| Portugis (Portugal) | pt-PT | GA |
| Rumania (Rumania) | ro-RO | GA |
| Rusia (Rusia) | ru-RU | GA |
| Spanyol (Spanyol) | es-ES | GA |
| Spanyol (Amerika Serikat) | es-US | GA |
| Swedia (Swedia) | sv-SE | GA |
| Turki (Turki) | tr-TR | GA |
| Ukraina (Ukraina) | uk-UA | GA |
| Vietnam (Vietnam) | vi-VN | GA |
| Afrikaans (Afrika Selatan) | af-ZA | Pratinjau |
| Albania (Albania) | sq-AL | Pratinjau |
| Amhar (Etiopia) | am-ET | Pratinjau |
| Arab (Aljazair) | ar-DZ | Pratinjau |
| Arab (Bahrain) | ar-BH | Pratinjau |
| Arab (Mesir) | ar-EG | Pratinjau |
| Arab (Israel) | ar-IL | Pratinjau |
| Arab (Yordania) | ar-JO | Pratinjau |
| Arab (Kuwait) | ar-KW | Pratinjau |
| Arab (Lebanon) | ar-LB | Pratinjau |
| Arab (Mauritania) | ar-MR | Pratinjau |
| Arab (Maroko) | ar-MA | Pratinjau |
| Arab (Oman) | ar-OM | Pratinjau |
| Arab (Qatar) | ar-QA | Pratinjau |
| Arab (Arab Saudi) | ar-SA | Pratinjau |
| Arab (Palestina) | ar-PS | Pratinjau |
| Arab (Suriah) | ar-SY | Pratinjau |
| Arab (Tunisia) | ar-TN | Pratinjau |
| Arab (Uni Emirat Arab) | ar-AE | Pratinjau |
| Arab (Yaman) | ar-YE | Pratinjau |
| Arab | ar-XA | Pratinjau |
| Armenia (Armenia) | hy-AM | Pratinjau |
| Assam (India) | as-IN | Pratinjau |
| Asturian (Spanyol) | ast-ES | Pratinjau |
| Azerbaijan (Azerbaijan) | az-AZ | Pratinjau |
| Basque (Spanyol) | eu-ES | Pratinjau |
| Bengali (Bangladesh) | bn-BD | Pratinjau |
| Bengali (India) | bn-IN | Pratinjau |
| Bulgaria (Bulgaria) | bg-BG | Pratinjau |
| Burma (Myanmar) | my-MM | Pratinjau |
| Kurdi Tengah (Irak) | ar-IQ | Pratinjau |
| China, Kanton (Hong Kong Tradisional) | yue-Hant-HK | Pratinjau |
| China, Mandarin (Tradisional, Taiwan) | cmn-Hant-TW | Pratinjau |
| Ceko (Republik Ceko) | cs-CZ | Pratinjau |
| Inggris (Filipina) | en-PH | Pratinjau |
| Estonia (Estonia) | et-EE | Pratinjau |
| Filipino (Filipina) | fil-PH | Pratinjau |
| Galisia (Spanyol) | gl-ES | Pratinjau |
| Georgia (Georgia) | ka-GE | Pratinjau |
| Gujarati (India) | gu-IN | Pratinjau |
| Hausa (Nigeria) | ha-NG | Pratinjau |
| Ibrani (Israel) | iw-IL | Pratinjau |
| Hungaria (Hungaria) | hu-HU | Pratinjau |
| Islandia (Islandia) | is-IS | Pratinjau |
| Indonesia (Indonesia) | id-ID | Pratinjau |
| Jawa (Indonesia) | jv-ID | Pratinjau |
| Kannada (India) | kn-IN | Pratinjau |
| Kazakh (Kazakhstan) | kk-KZ | Pratinjau |
| Khmer (Kamboja) | km-KH | Pratinjau |
| Kirgiz (Kirgizstan) | ky-KG | Pratinjau |
| Lao (Laos) | lo-LA | Pratinjau |
| Latvia (Latvia) | lv-LV | Pratinjau |
| Lituania (Lituania) | lt-LT | Pratinjau |
| Luksemburg (Luksemburg) | lb-LU | Pratinjau |
| Makedonia (Makedonia Utara) | mk-MK | Pratinjau |
| Melayu (Malaysia) | ms-MY | Pratinjau |
| Malayalam (India) | ml-IN | Pratinjau |
| Malta (Malta) | mt-MT | Pratinjau |
| Maori (Selandia Baru) | mi-NZ | Pratinjau |
| Marathi (India) | mr-IN | Pratinjau |
| Mongolia (Mongolia) | mn-MN | Pratinjau |
| Nepali (Nepal) | ne-NP | Pratinjau |
| Sotho Utara (Afrika Selatan) | nso-ZA | Pratinjau |
| Norwegia (Norwegia) | no-NO | Pratinjau |
| Oriya (India) | or-IN | Pratinjau |
| Farsi (Iran) | fa-IR | Pratinjau |
| Punjabi (Gurmukhi India) | pa-Guru-IN | Pratinjau |
| Serbia (Serbia) | sr-RS | Pratinjau |
| Slovak (Slovakia) | sk-SK | Pratinjau |
| Slovenia (Slovenia) | sl-SI | Pratinjau |
| Spanyol (Meksiko) | es-MX | Pratinjau |
| Swahili (Kenya) | sw-KE | Pratinjau |
| Swahili | sw | Pratinjau |
| Tamil (India) | ta-IN | Pratinjau |
| Telugu (India) | te-IN | Pratinjau |
| Thai (Thailand) | th-TH | Pratinjau |
| Uzbek (Uzbekistan) | uz-UZ | Pratinjau |
| Wales (Inggris Raya) | cy-GB | Pratinjau |
| Wolof (Senegal) | wo-SN | Pratinjau |
| Xhosa (Afrika Selatan) | xh-ZA | Pratinjau |
| Yoruba (Nigeria) | yo-NG | Pratinjau |
| Zulu (Afrika Selatan) | zu-ZA | Pratinjau |
Ketersediaan bahasa untuk pemisahan pembicara
Chirp 3 mendukung transkripsi dan diarisasi hanya dalam BatchRecognize dan Recognize dalam bahasa berikut:
| Bahasa | Kode BCP-47 |
| China (Aksara Sederhana, China) | cmn-Hans-CN |
| Jerman (Jerman) | de-DE |
| Inggris (Inggris Raya) | en-GB |
| Inggris (India) | en-IN |
| Inggris (Amerika Serikat) | en-US |
| Spanyol (Spanyol) | es-ES |
| Spanyol (Amerika Serikat) | es-US |
| Prancis (Kanada) | fr-CA |
| Prancis (Prancis) | fr-FR |
| Hindi (India) | hi-IN |
| Italia (Italia) | it-IT |
| Jepang (Jepang) | ja-JP |
| Korea (Korea) | ko-KR |
| Portugis (Brasil) | pt-BR |
Dukungan dan batasan fitur
Chirp 3 mendukung fitur berikut:
| Fitur | Deskripsi | Tahap peluncuran |
|---|---|---|
| Tanda baca otomatis | Dibuat secara otomatis oleh model dan dapat dinonaktifkan secara opsional. | GA |
| Kapitalisasi otomatis | Dibuat secara otomatis oleh model dan dapat dinonaktifkan secara opsional. | GA |
| Stempel waktu tingkat ucapan | Dibuat secara otomatis oleh model. Hanya tersedia di Speech.StreamingRecognize |
GA |
| Diarisasi Speaker | Otomatis mengidentifikasi pembicara yang berbeda dalam sampel audio satu saluran. Hanya tersedia di Speech.BatchRecognize |
GA |
| Adaptasi ucapan (Penyesuaian) | Memberikan petunjuk kepada model dalam bentuk frasa atau kata untuk meningkatkan akurasi pengenalan istilah atau nama diri tertentu. | GA |
| Transkripsi audio tanpa bahasa | Secara otomatis menyimpulkan dan mentranskripsikan dalam bahasa yang paling umum. | GA |
| Perintah khusus | Memberikan petunjuk pemformatan transkripsi yang disesuaikan ke model. | Pratinjau |
Chirp 3 tidak mendukung fitur berikut:
| Fitur | Deskripsi |
|---|---|
| Stempel waktu tingkat kata | Dibuat secara otomatis oleh model dan dapat diaktifkan secara opsional, yang menyebabkan penurunan kualitas transkripsi. Hanya tersedia di Speech.Recognize dan Speech.BatchRecognize |
| Skor keyakinan tingkat kata | API menampilkan nilai, tetapi bukan sepenuhnya skor keyakinan. |
Mentranskripsikan menggunakan Chirp 3
Pelajari cara menggunakan Chirp 3 untuk tugas transkripsi.
Menjalankan pengenalan ucapan streaming
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_streaming_chirp3(
audio_file: str
) -> cloud_speech.StreamingRecognizeResponse:
"""Transcribes audio from audio file stream using the Chirp 3 model of Google Cloud Speech-to-Text v2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API V2 containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
content = f.read()
# In practice, stream should be a generator yielding chunks of audio data
chunk_length = len(content) // 5
stream = [
content[start : start + chunk_length]
for start in range(0, len(content), chunk_length)
]
audio_requests = (
cloud_speech.StreamingRecognizeRequest(audio=audio) for audio in stream
)
recognition_config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
streaming_config = cloud_speech.StreamingRecognitionConfig(
config=recognition_config
)
config_request = cloud_speech.StreamingRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
streaming_config=streaming_config,
)
def requests(config: cloud_speech.RecognitionConfig, audio: list) -> list:
yield config
yield from audio
# Transcribes the audio into text
responses_iterator = client.streaming_recognize(
requests=requests(config_request, audio_requests)
)
responses = []
for response in responses_iterator:
responses.append(response)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return responses
Melakukan pengenalan ucapan sinkron
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Menjalankan pengenalan ucapan batch
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_batch_3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text v2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input audio file.
E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response.results[audio_uri].transcript
Menggunakan fitur Chirp 3
Pelajari cara menggunakan fitur terbaru, dengan contoh kode:
Melakukan transkripsi tanpa bahasa
Chirp 3 dapat mengidentifikasi dan mentranskripsikan secara otomatis dalam bahasa dominan yang digunakan dalam audio, yang penting untuk aplikasi multibahasa. Untuk mencapainya, tetapkan language_codes=["auto"] seperti yang ditunjukkan dalam contoh kode:
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 3.
Please see https://cloud.google.com/speech-to-text/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["auto"], # Set language code to auto to detect language.
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Melakukan transkripsi yang dibatasi bahasa
Chirp 3 dapat otomatis mengidentifikasi dan mentranskripsikan bahasa dominan dalam file audio. Anda juga dapat mengondisikannya pada lokalitas tertentu yang Anda harapkan, misalnya: ["en-US", "fr-FR"], yang akan memfokuskan resource model pada bahasa yang paling mungkin untuk hasil yang lebih andal, seperti yang ditunjukkan dalam contoh kode:
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_3_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 3.
Please see https://cloud.google.com/speech-to-text/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US", "fr-FR"], # Set language codes of the expected spoken locales
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Melakukan transkripsi dan diarisasi pembicara
Gunakan Chirp 3 untuk tugas transkripsi dan diarization.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_batch_chirp3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input
audio file. E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the
Speech-to-Text API containing the transcription results.
"""
# Instantiates a client.
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"], # Use "auto" to detect language.
model="chirp_3",
features=cloud_speech.RecognitionFeatures(
# Enable diarization by setting empty diarization configuration.
diarization_config=cloud_speech.SpeakerDiarizationConfig(),
),
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Creates audio transcription job.
operation = client.batch_recognize(request=request)
print("Waiting for transcription job to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
print(f"Speakers per word: {result.alternatives[0].words}")
return response.results[audio_uri].transcript
Meningkatkan akurasi dengan adaptasi model
Chirp 3 dapat meningkatkan akurasi transkripsi untuk audio spesifik Anda menggunakan adaptasi model. Dengan begitu, Anda dapat memberikan daftar kata dan frasa tertentu, sehingga meningkatkan kemungkinan model akan mengenalinya. Fitur ini sangat berguna untuk istilah khusus domain, kata benda, atau kosakata unik.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_model_adaptation(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model with adaptation, improving accuracy for specific audio characteristics or vocabulary.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
# Use model adaptation
adaptation=cloud_speech.SpeechAdaptation(
phrase_sets=[
cloud_speech.SpeechAdaptation.AdaptationPhraseSet(
inline_phrase_set=cloud_speech.PhraseSet(phrases=[
{
"value": "alphabet",
},
{
"value": "cell phone service",
}
])
)
]
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Menggunakan perintah kustom untuk memformat transkripsi
Chirp 3 menerima perintah kustom sebagai petunjuk pemformatan untuk model.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_custom_prompt(
audio_file: str,
custom_prompt: str,
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 3.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
custom_prompt: the customized formatting instructions.
Example: "Capitalize the following special words: GOOGLE, CHIRP."
Example: "For dates don't use the 'December 23rd, 1939' format!
But strictly use the '12/23/1939' format."
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
features=cloud_speech.RecognitionFeatures(
custom_prompt_config=cloud_speech.CustomPromptConfig(
custom_prompt= custom_prompt,
)
),
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
print(f"Prompt used: {response.metadata.prompt}")
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Mengaktifkan penghilang kebisingan
Chirp 3 dapat meningkatkan kualitas audio dengan mengurangi suara bising di latar belakang. Anda dapat meningkatkan hasil dari lingkungan yang bising dengan mengaktifkan peredam bising bawaan.
Setelan denoiser_audio=true dapat secara efektif membantu Anda mengurangi musik atau suara bising di latar belakang, seperti suara hujan dan lalu lintas jalan.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model of Google Cloud Speech-to-Text v2 API, which provides word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
denoiser_config={
denoise_audio: True,
snr_threshold: 0.0, # snr_threshold is deprecated in Chirp3; set to 0.0 to maintain compatibility.
}
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Menyesuaikan sensitivitas pengakhiran
Cloud Speech-to-Text API memungkinkan Anda mengontrol kompromi antara latensi dan akurasi untuk aplikasi streaming dan real-time untuk Chirp 3. Secara default, model pengenalan menunggu jeda singkat setelah ucapan terdeteksi untuk memastikan pengguna telah menyelesaikan kalimat atau frasa lengkap. Hal ini membantu memastikan akurasi tertinggi, tetapi menyebabkan sedikit penundaan dalam respons akhir.
endpointing_sensitivity dapat disesuaikan untuk aplikasi yang sensitif terhadap waktu seperti perintah suara atau bot suara untuk menyelesaikan hasil dengan lebih cepat.
Tingkat sensitivitas
Sensitivitas pengakhiran dapat dikonfigurasi ke salah satu tingkat berikut berdasarkan kasus penggunaan:
ENDPOINTING_SENSITIVITY_STANDARD(default): Setelan standar yang menyeimbangkan latensi dan akurasi. Model ini dioptimalkan untuk sebagian besar kasus penggunaan, termasuk dikte panjang dan percakapan alami. Model menunggu untuk membantu memastikan ucapan selesai sebelum memfinalisasi hasilnya.ENDPOINTING_SENSITIVITY_SHORT: Dioptimalkan untuk ucapan singkat, seperti satu kalimat atau perintah, seperti "Ingatkan saya untuk menelepon dokter gigi besok". Setelan ini mengurangi waktu tunggu setelah ucapan terdeteksi, yang memberikan respons lebih cepat daripada setelan standar sekaligus mempertahankan akurasi tingkat kalimat yang wajar.ENDPOINTING_SENSITIVITY_SUPERSHORT: Dioptimalkan untuk perintah yang sangat singkat atau satu kata, seperti "Ya", "Tidak", atau "Berhenti". Setelan ini menawarkan latensi terendah dan memfinalisasi hasil segera setelah mendeteksi akhir ucapan. Model ini hanya direkomendasikan untuk aplikasi yang memerlukan kecepatan dan ucapan yang singkat.
Python
import time
from google.api_core.client_options import ClientOptions
from google.cloud import speech_v2
RATE = 16000
def transcribe_streaming(
project_id: str,
audio_file: str,
# 'us' is a multi-region that currently supports the 'chirp_3' model.
# Other valid regions include 'eu' or specific regions like 'asia-southeast1'.
region: str = "us"
):
recognizer_path = f"projects/{project_id}/locations/{region}/recognizers/_"
# Setup client with the correct regional endpoint
client = speech_v2.SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{region}-speech.googleapis.com",
quota_project_id=project_id
)
)
recognition_config_obj = speech_v2.RecognitionConfig(
explicit_decoding_config=speech_v2.ExplicitDecodingConfig(
encoding=speech_v2.ExplicitDecodingConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=RATE,
audio_channel_count=1,
),
language_codes=["en-US"],
model="chirp_3",
features=speech_v2.RecognitionFeatures(
enable_automatic_punctuation=True,
),
)
config_request = speech_v2.StreamingRecognizeRequest(
recognizer=recognizer_path,
streaming_config=speech_v2.StreamingRecognitionConfig(
config=recognition_config_obj,
streaming_features=speech_v2.StreamingRecognitionFeatures(
interim_results=False,
enable_voice_activity_events=True,
# Set sensitivity to SUPERSHORT (Low Latency)
endpointing_sensitivity=speech_v2.StreamingRecognitionFeatures.EndpointingSensitivity.ENDPOINTING_SENSITIVITY_SUPERSHORT,
),
)
)
def request_generator():
yield config_request
with open(audio_file, "rb") as f:
while chunk := f.read(4096):
yield speech_v2.StreamingRecognizeRequest(audio=chunk)
start_time = time.time()
print(f"Streaming audio to {region}-speech.googleapis.com...")
for response in client.streaming_recognize(requests=request_generator()):
if response.results:
for result in response.results:
if result.is_final:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Time taken: {time.time() - start_time:.3f}s")
def main() -> None:
# TODO: Replace with your Project ID and File Path
PROJECT_ID = "your-project-id"
AUDIO_FILE_PATH = "path/to/your/audio.wav"
transcribe_streaming(
project_id=PROJECT_ID,
audio_file=AUDIO_FILE_PATH
)
if __name__ == "__main__":
main()
Menggunakan Chirp 3 di konsol Google Cloud
- Daftar ke akun Google Cloud , dan buat project.
- Buka Speech di konsol Google Cloud .
- Jika API belum diaktifkan, aktifkan API.
Pastikan Anda memiliki Workspace konsol STT. Jika tidak memiliki ruang kerja, Anda harus membuat ruang kerja.
Buka halaman transkripsi, lalu klik Transkripsi Baru.
Buka drop-down Workspace, lalu klik New Workspace untuk membuat ruang kerja untuk transkripsi.
Dari sidebar navigasi Buat workspace baru, klik Jelajahi.
Klik untuk membuat bucket baru.
Masukkan nama untuk bucket Anda, lalu klik Continue.
Klik Buat untuk membuat bucket Cloud Storage.
Setelah bucket dibuat, klik Select untuk memilih bucket yang akan digunakan.
Klik Create guna menyelesaikan pembuatan ruang kerja Anda untuk konsol Speech-to-Text API V2.
Lakukan transkripsi pada audio Anda yang sebenarnya.
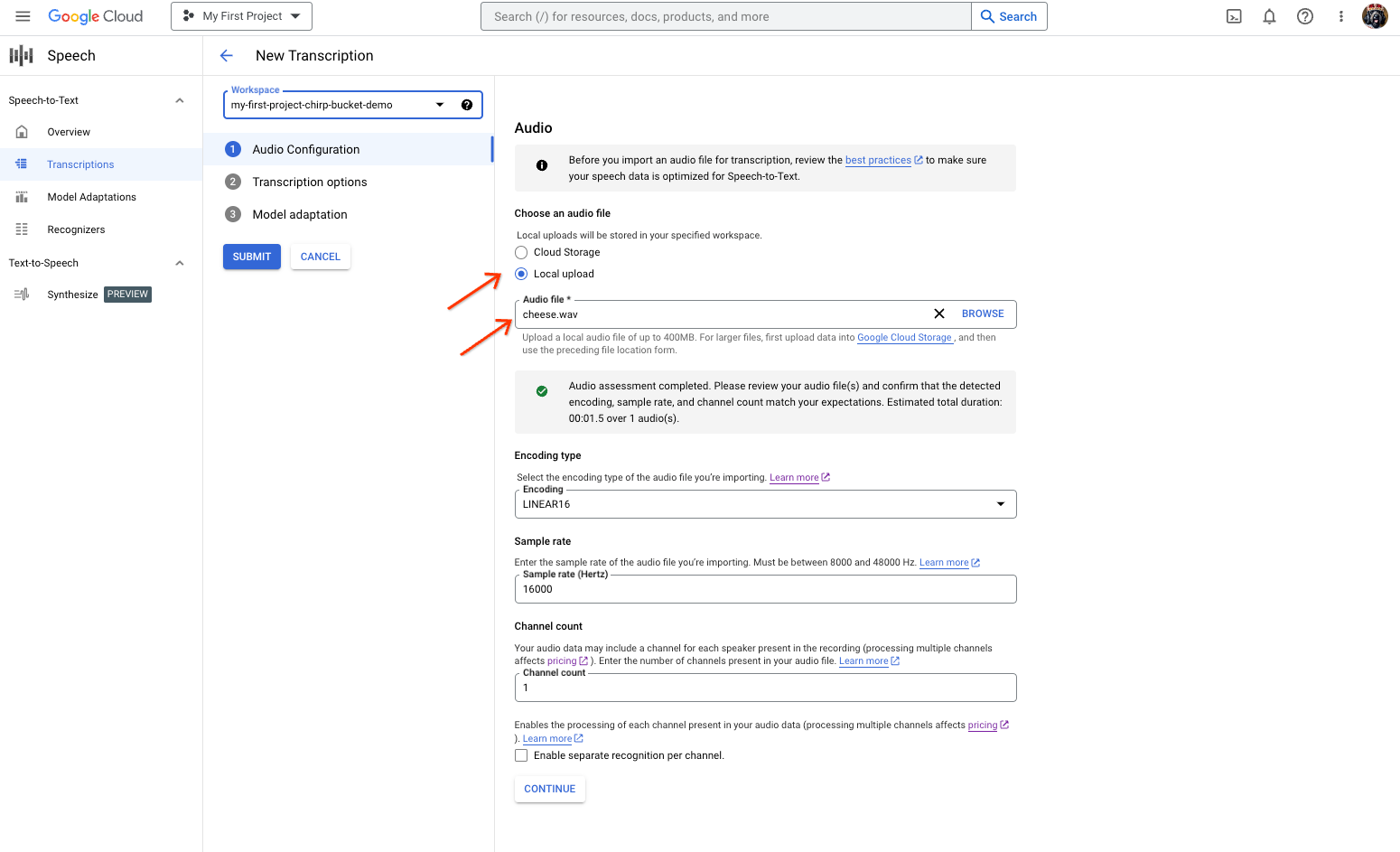
Halaman pembuatan transkripsi Speech-to-Text, yang menampilkan pemilihan atau upload file. Dari halaman Transkripsi Baru, pilih file audio Anda melalui upload (Upload lokal) atau tentukan file Cloud Storage yang sudah ada (Penyimpanan Cloud).
Klik Lanjutkan untuk berpindah ke Opsi transkripsi.
Pilih Bahasa lisan yang akan Anda gunakan untuk pengenalan dengan Chirp dari pengenal yang dibuat sebelumnya.
Di menu drop-down model, pilih chirp_3.
Di drop-down Pengenal, pilih pengenal yang baru Anda buat.
Klik Kirim untuk menjalankan permintaan pengenalan pertama Anda menggunakan
chirp_3.
Lihat hasil transkripsi Chirp 3 Anda.
Dari halaman Transkripsi, klik nama transkripsi untuk melihat hasilnya.
Di halaman Detail transkripsi, lihat hasil transkripsi dan jika perlu, putar audio di browser.