
Utilizza un modello di Speech-to-Text personalizzato addestrato nell'applicazione di produzione o nei flussi di lavoro di benchmarking. Devi eseguire il deployment del modello ed esporlo tramite un endpoint dedicato, creato in parte per eseguire il deployment del modello nella regione scelta. Ottieni automaticamente l'accesso programmatico tramite un oggetto di riconoscimento. Viene utilizzato direttamente tramite l'API V2 o nella Google Cloud console. Puoi eseguire il deployment del modello in una regione diversa da quella in cui è stato addestrato, ma viene creata una copia del modello nella regione specificata dall'endpoint.
Per utilizzare un modello vocale personalizzato, devi eseguirne il deployment ed esporlo tramite un endpoint dedicato. Quando crei un endpoint, esegui il deployment del modello nella regione che preferisci. Ti viene concesso automaticamente l'accesso programmatico tramite un oggetto di riconoscimento da utilizzare direttamente tramite l'API V2 per l'inferenza o in the Google Cloud console.
Prima di iniziare
Assicurati di aver registrato un Google Cloud account, creato un progetto e addestrato un modello vocale personalizzato.
- Vai a Speech nella Google Cloud console e poi a Cloud Speech-to-Text.
- Vai alla sezione Modelli personalizzati della barra di navigazione a sinistra.
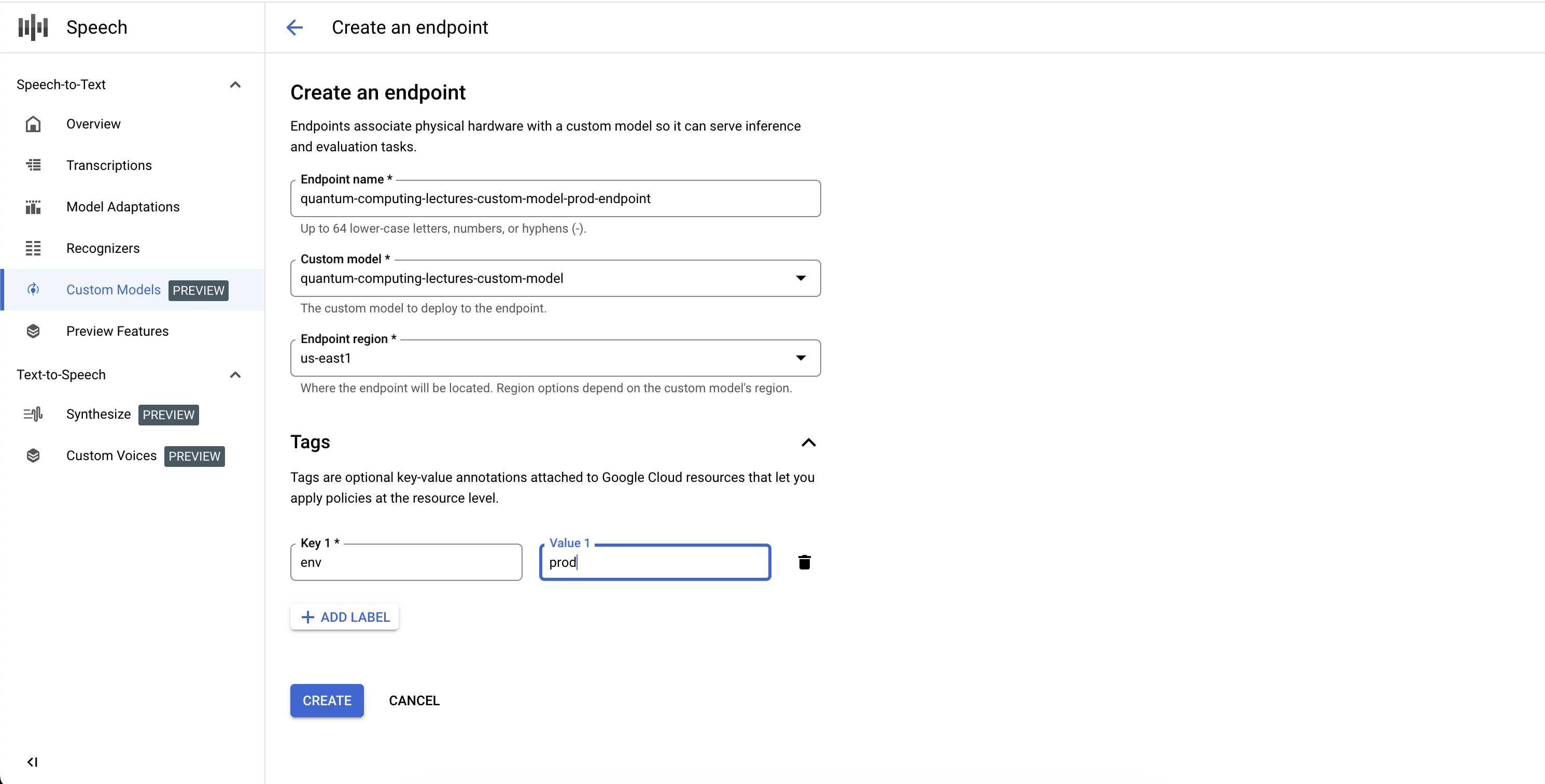
Creazione di un endpoint
- Vai alla scheda Endpoint della sezione Modelli personalizzati.
- Fai clic su Nuovo endpoint.
- Definisci un nome per l'endpoint. Questo nome funge da identificatore univoco per la risorsa endpoint e viene utilizzato per richiamare il modello vocale personalizzato per l'inferenza.
- Definisci la regione in cui vuoi eseguire il deployment del modello vocale personalizzato. Se il modello è stato addestrato in una regione diversa da quella definita nella configurazione dell'endpoint, viene creata automaticamente una nuova copia del modello.
- Seleziona il modello vocale personalizzato addestrato dall'elenco che vuoi esporre tramite l'endpoint.
- Fai clic su Crea e dopo qualche istante il modello vocale personalizzato viene sottoposto a deployment nell'endpoint ed è pronto per essere utilizzato per l'inferenza e il benchmarking.
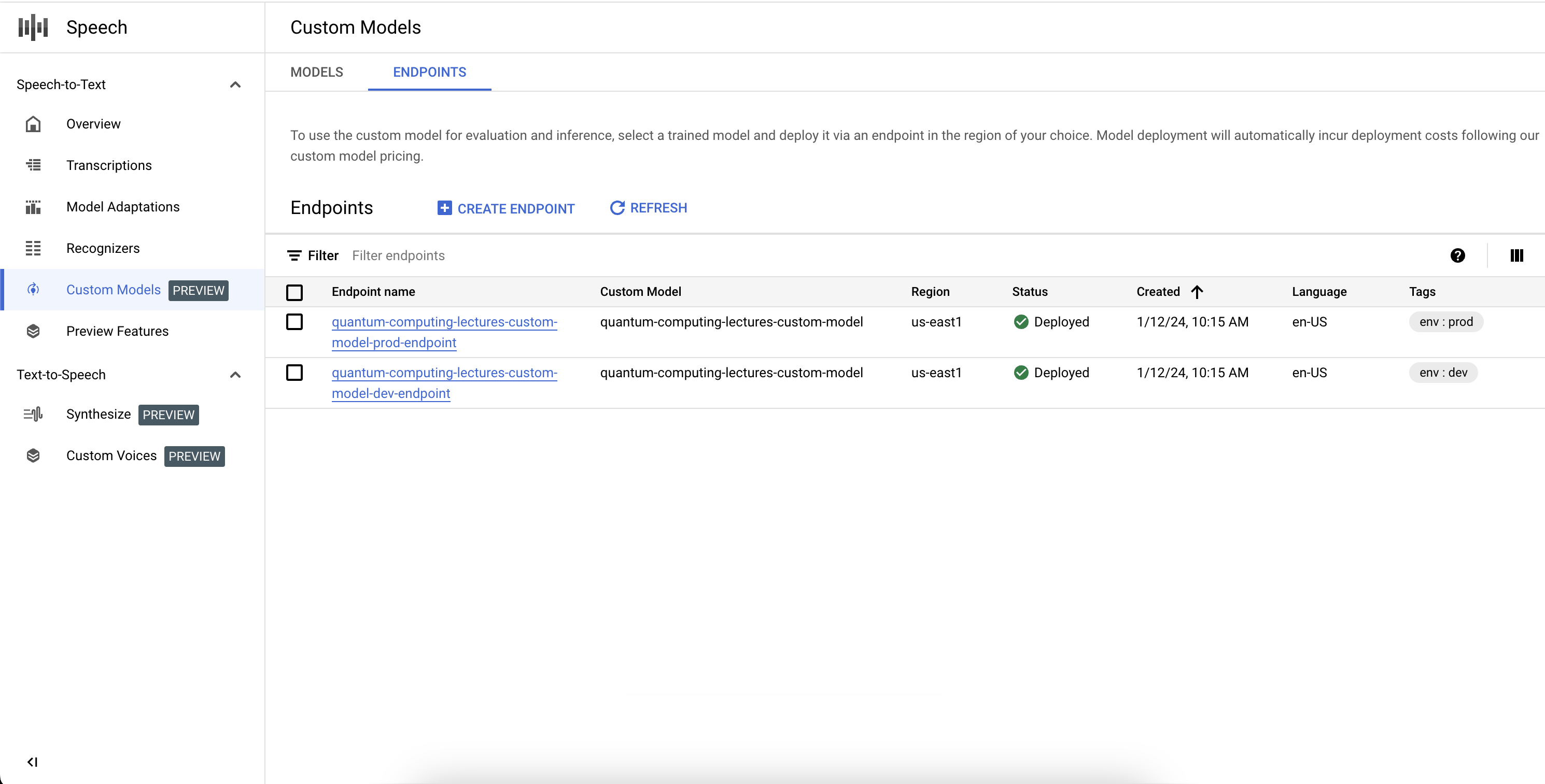
Elenco degli endpoint
Puoi gestire gli endpoint associati nella console selezionando la scheda Endpoint nella sezione Modelli personalizzati. Puoi anche elencare gli endpoint che hai creato nella console, insieme al loro stato attuale e al modello di Cloud Speech-to-Text personalizzato associato.
Eliminazione di un endpoint
Prima di iniziare, assicurati che non ci sia traffico instradato tramite l'endpoint, perché l'eliminazione impedirà di gestire le richieste.
- Vai alla scheda Endpoint della sezione Modelli personalizzati.
- Nella scheda Endpoint, fai clic per espandere le opzioni e poi su Elimina. Dopo qualche istante, l'endpoint viene eliminato e non gestisce più il traffico.
Benchmark del modello
Per valutare l'accuratezza del modello utilizzando il modello di Speech-to-Text personalizzato e il set di dati di benchmarking, segui la guida Misurare e migliorare l'accuratezza.