
データベース スキーマ
このページのクエリと実行プランは、次のデータベース スキーマに基づいています。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
次のデータ操作言語(DML)ステートメントを使用して、これらのテーブルにデータを追加できます。
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
構造体コンストラクタは、構造体またはフィールドの集合体を作成します。計算オペレーションで生成された行に構造体を作成します。構造体コンストラクタは、独立した演算子ではありません。常に構造体計算演算子または結果のシリアル化演算子の中で使用されます。
構造体計算の場合、構造体コンストラクタが構造体を作成し、計算された行の列が 1 つの変数で構造体を参照できます。
結果のシリアル化の場合、構造体コンストラクタが結果のシリアル化に使用する構造体を作成します。
次のクエリは、この演算子を示しています。
SELECT IF(TRUE, struct(1 AS A, 1 AS B), struct(2 AS A , 2 AS B)).A;
/*---+
| A |
+---+
| 1 |
+---*/
実行プランは次のように表示されます。
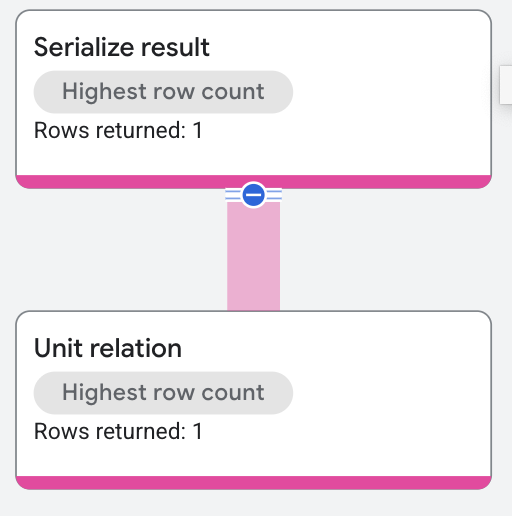
この実行プランでは、構造体コンストラクタが結果のシリアル化演算子の中で使用されています。
プロパティと実行統計情報
演算子のプロパティは、演算子の実行時に使用される特性を表します。実行統計情報は、クエリ実行中に収集される値で、オペレーターのパフォーマンスを評価するのに役立ちます。
プロパティ
| 名前 | 説明 |
|---|---|
| 実行メソッド | 行実行では、演算子は一度に 1 行を処理します。バッチ実行では、演算子は一度に複数の行を処理します。 |
実行統計情報
| 名前 | 説明 |
|---|---|
| レイテンシ | 演算子で実行されたすべての実行の経過時間。 |
| 累積レイテンシ | 現在の演算子とその子孫の合計時間。 |
| CPU 時間 | 演算子の実行に費やされた CPU 時間の合計。 |
| 累積 CPU 時間 | オペレーターとその子孫の実行に費やされた合計 CPU 時間。 |
| 実行時間 | クエリの実行と結果の処理にかかった合計時間。 |
| 返された行数 | この演算子によって出力された行数 |
| 実行数 | 演算子が実行された回数。一部の実行は並行して実行できます。 |