
바이너리 연산자에는 두 개의 관계형 하위 요소가 있습니다. 다음 연산자는 바이너리 연산자입니다.
- 참여 신청
- 교차 적용
- 외부 적용
- Semi apply(세미 적용)
- Anti-Semi apply
- 해시 조인
- 병합 조인
- 재귀적 통합
데이터베이스 스키마
이 페이지의 쿼리 및 실행 계획은 다음 데이터베이스 스키마를 기반으로 합니다.
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
다음과 같은 데이터 조작 언어(DML) 문을 사용하여 이러한 테이블에 데이터를 추가할 수 있습니다.
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
조인 적용
적용 조인은 Spanner에서 사용되는 기본 조인 연산자입니다. 적용 조인 연산자는 해시 조인과 같이 집합 기반 처리를 실행하는 연산자와 달리 행 기반 처리를 실행합니다. 적용 연산자에는 입력 (왼쪽 하위 요소)과 맵 (오른쪽 하위 요소) 등 2가지 입력이 있습니다. 적용 연산자는 적용 메서드(cross, outer, semi, anti-semi)를 사용하여 입력 측의 각 행을 맵 측에 적용합니다. 또한 apply join의 변형이 Distributed apply의 지도 측에도 표시됩니다.
Apply join 연산자는 다음과 같은 경우에 가장 효율적입니다.
- 입력의 카디널리티가 낮습니다.
- 조인 키는 맵 측 기본 키의 접두사입니다.
- 쿼리는 인터리브 처리된 두 테이블을 조인합니다.
속성 및 실행 통계
연산자의 속성은 연산자가 실행될 때 사용되는 특성을 설명합니다. 실행 통계는 쿼리 실행 중에 수집되는 값으로, 연산자의 성능을 평가하는 데 도움이 됩니다.
속성
| 이름 | 설명 |
|---|---|
| 실행 메소드입니다. | 행 실행에서 연산자는 한 번에 한 행을 처리합니다. 일괄 실행에서 연산자는 한 번에 행 배치를 처리합니다. |
실행 통계
| 이름 | 설명 |
|---|---|
| 지연 시간 | 연산자에서 실행된 모든 실행의 경과 시간입니다. |
| 누적 지연 시간 | 현재 연산자와 그 하위 요소의 총 시간입니다. |
| CPU 시간 | 연산자를 실행하는 데 사용된 CPU 시간의 합계입니다. |
| 누적 CPU 시간 | 연산자와 그 하위 요소를 실행하는 데 소요된 총 CPU 시간입니다. |
| 실행 시간 | 쿼리를 실행하고 결과를 처리하는 데 걸린 총시간입니다. |
| 반환된 행 | 이 연산자가 출력한 행 수 |
| 실행 횟수 | 연산자가 실행된 횟수입니다. 일부 실행은 동시에 실행할 수 있습니다. |
교차 적용
교차 적용은 일치하는 행만 반환되는 내부 조인을 실행합니다.
다음 쿼리는 이 연산자를 보여줍니다.
쿼리는 각 가수의 성과 가수의 곡 중 한 곡 이름만 요청합니다.
SELECT si.firstname,
(SELECT so.songname
FROM songs AS so
WHERE so.singerid = si.singerid
LIMIT 1)
FROM singers AS si;
/*-----------+--------------------------+
| FirstName | Unspecified |
+-----------+--------------------------+
| Alice | Not About The Guitar |
| Catalina | Let's Get Back Together |
| David | NULL |
| Lea | NULL |
| Marc | NULL |
+-----------+--------------------------*/
이 쿼리는 첫 번째 열을 Singers 테이블에서 가져오고 두 번째 열을 Songs 테이블에서 가져옵니다. Singers 테이블에 SingerId 1개가 있지만 Songs 테이블에 일치하는 SingerId가 없으면 두 번째 열에 NULL이 포함됩니다.
실행 계획은 다음과 같이 시작됩니다.
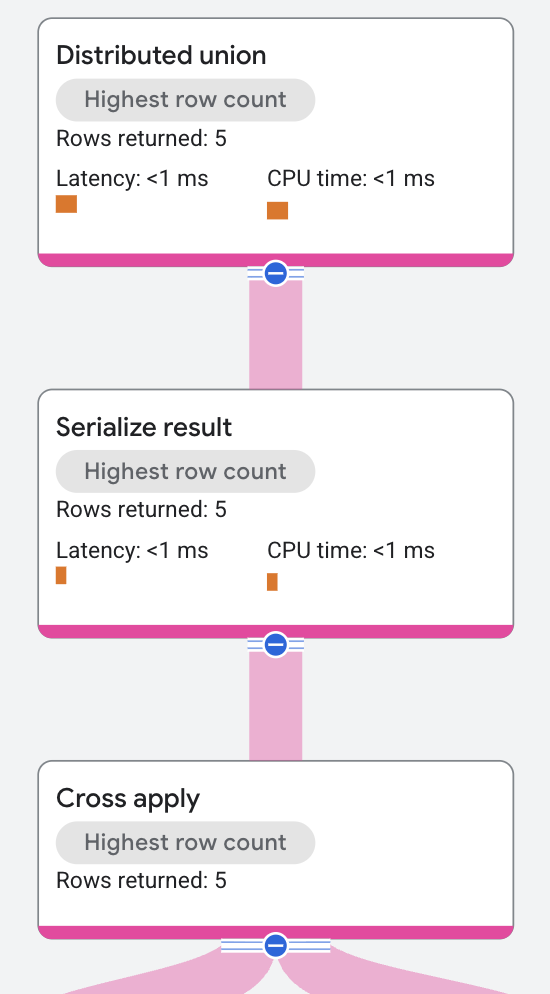
최상위 노드는 분산 통합 연산자입니다. 분산 통합 연산자는 원격 서버에 하위 계획을 분배합니다. 이 하위 계획에는 가수의 성과 가수의 곡 중 한 곡의 이름을 컴퓨팅하고 출력의 각 행을 직렬화하는 결과 직렬화 연산자가 포함되어 있습니다.
결과 직렬화 연산자는 교차 적용 연산자에서 입력을 받습니다.
교차 적용 연산자의 입력 측은 Singers 테이블에 대한 테이블 스캔입니다.
실행 계획은 다음과 같이 계속됩니다.
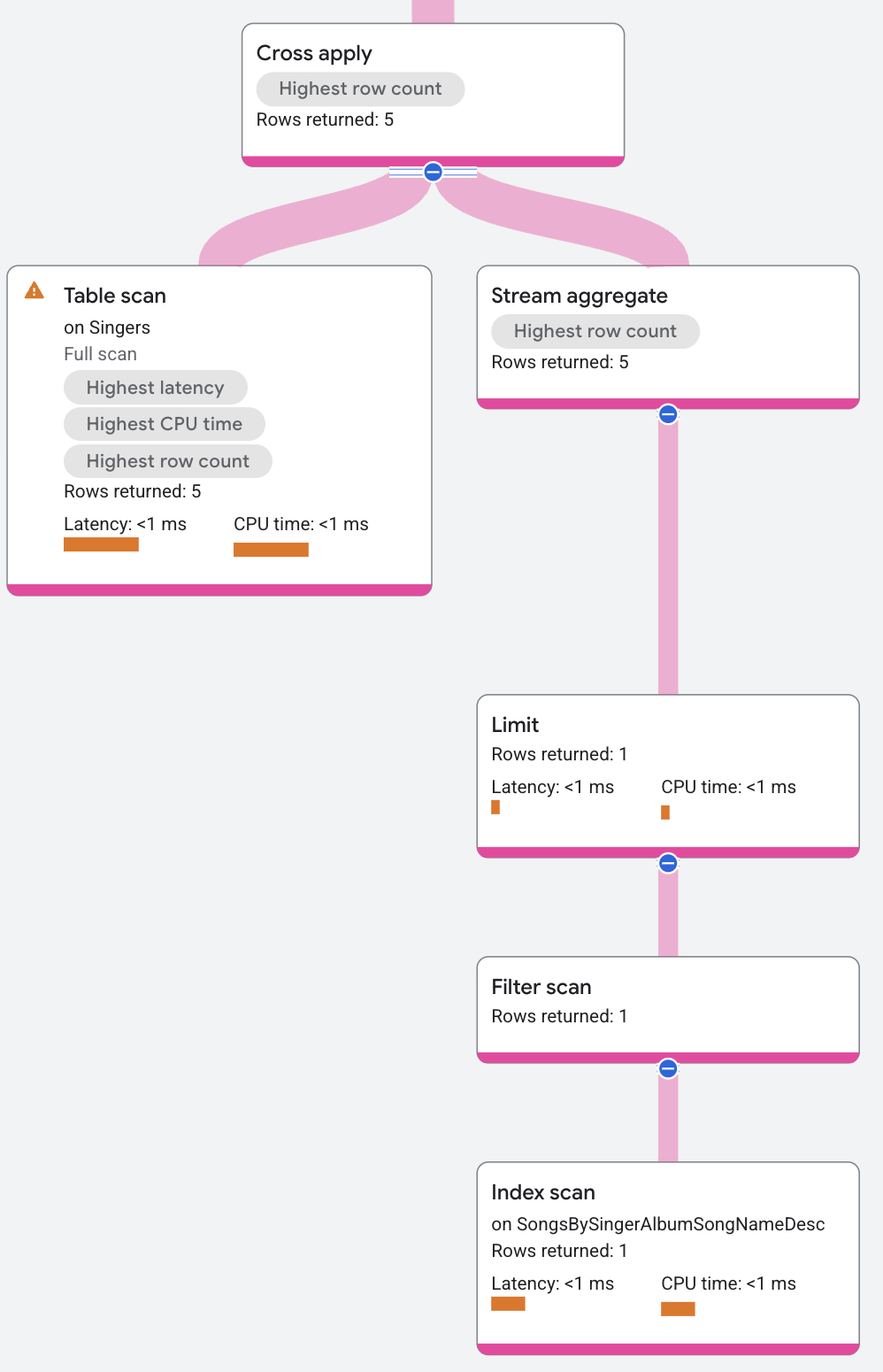
교차 적용 연산의 맵 측에는 다음이 포함됩니다(위에서 아래로).
Songs.SongName을 반환하는 집계 연산자- 가수 1명당 반환되는 곡 수를 제한하는 제한 연산자
SongsBySingerAlbumSongNameDesc색인에 대한 색인 스캔
교차 적용 연산자는 입력 측의 각 행을 동일한 SingerId를 가진 맵 측의 행에 매핑합니다. 교차 적용 연산자 출력은 입력 행의 FirstName 값과 맵 행의 SongName 값입니다.
(SingerId에 일치하는 맵 행이 없는 경우 SongName 값은 NULL입니다.) 그런 다음 실행 계획 맨 위에 있는 분산 통합 연산자가 원격 서버의 모든 출력 행을 결합하여 쿼리 결과로 반환합니다.
외부 적용
외부 적용은 왼쪽 외부 조인 시맨틱스를 제공합니다. 필요한 경우 NULL 패딩을 추가하여 맵 측의 각 실행이 행을 하나 이상 반환하도록 합니다.
세미 적용
semi apply 연산자는 맵 측에서 일치가 발생하는 경우에만 입력 열을 반환합니다.
다음 쿼리는 세미 조인을 사용하여 앨범이 있는 가수를 찾습니다.
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| Marc | Richards |
| Catalina | Smith |
| Alice | Trentor |
| Lea | Martin |
+-----------+----------*/
요금제 세그먼트는 다음과 같이 표시됩니다.
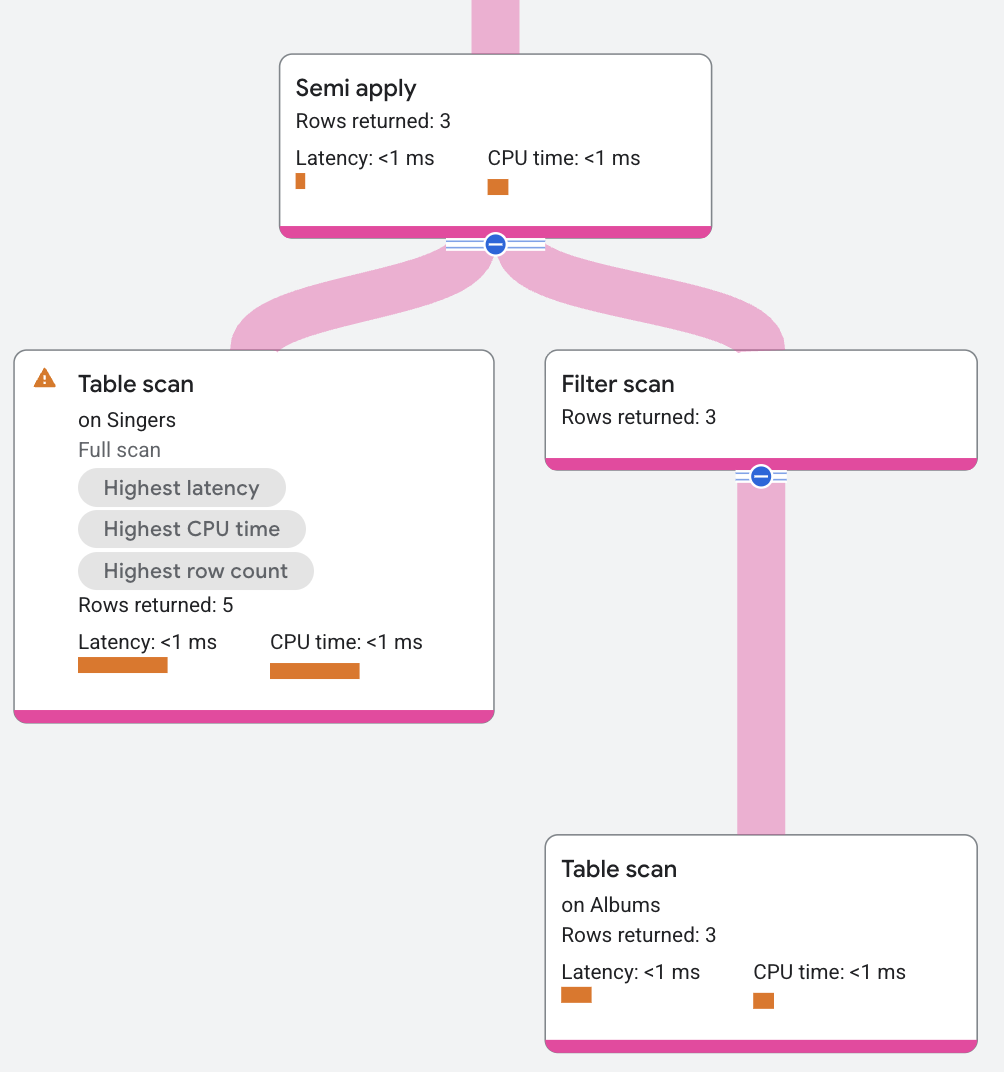
안티 세미 적용
Anti-semi apply 연산자는 맵 측에서 일치하는 항목이 없을 때만 입력 테이블 열을 반환한다는 점을 제외하고는 semi apply 연산자와 유사합니다.
다음 쿼리는 안티 세미 조인을 사용하여 앨범이 없는 가수를 찾습니다.
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId NOT IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| David | Lomond |
+-----------+----------*/
요금제 세그먼트는 다음과 같이 표시됩니다.
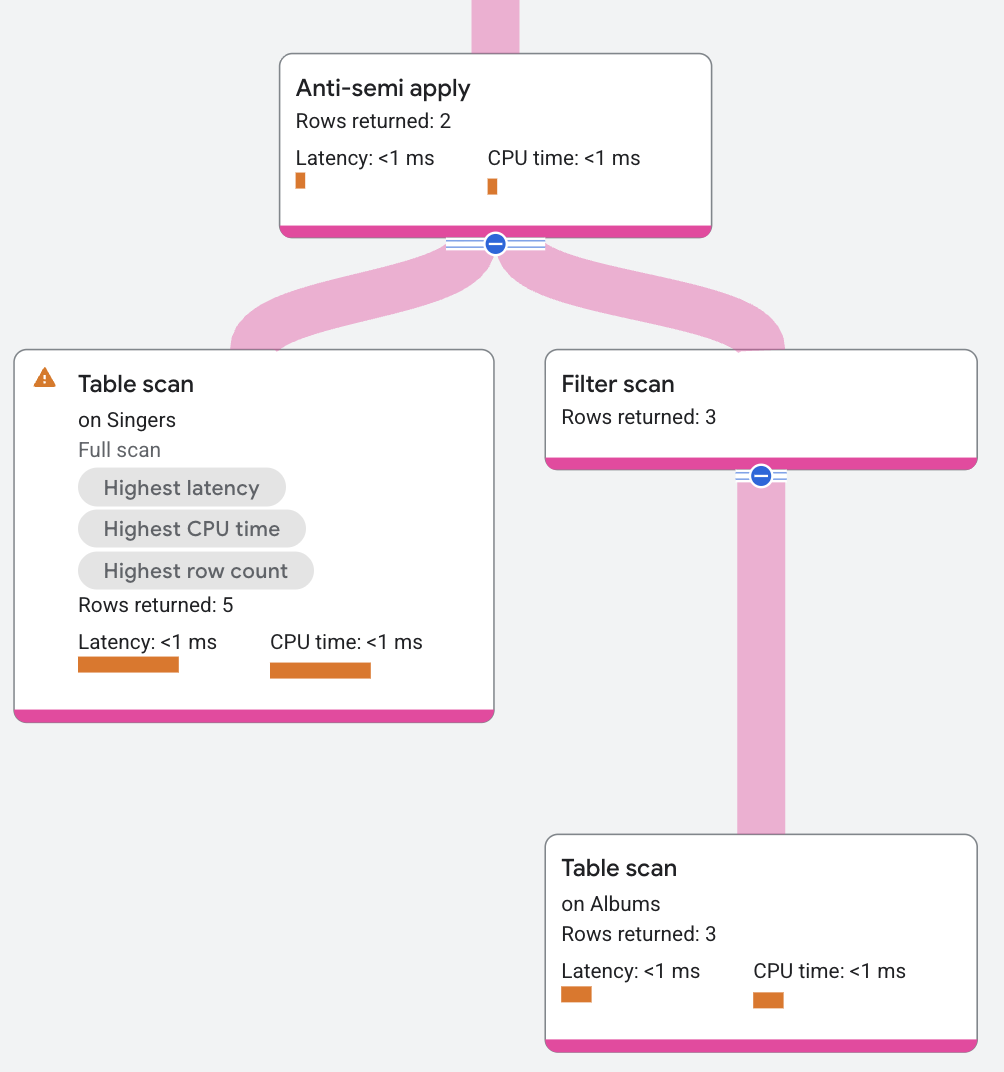
해시 조인
해시 조인 연산자는 해시에 기반해 SQL 조인을 구현한 것입니다. 해시 조인은 집합 기반 프로세싱을 실행합니다. 해시 조인 연산자는 빌드 (왼쪽 하위 요소)로 표시된 입력에서 행을 읽고 이를 조인 조건에 따라 해시 테이블에 삽입합니다. 그런 다음 해시 조인 연산자는 프로브 (오른쪽 하위 요소)로 표시된 입력에서 행을 읽습니다. 프로브 입력에서 읽는 각 행에 대해 해시 조인 연산자는 해시 테이블에서 일치하는 행을 찾습니다. 해시 조인 연산자는 일치하는 행을 결과로 반환합니다.
해시 조인에는 다음과 같은 장점이 있습니다.
- 입력을 정렬할 필요가 없습니다.
- 해시 테이블을 빌드할 때 블룸 필터를 계산합니다. 연산자는 필터를 사용하여 일치하는 항목이 없는 프로브 측의 행을 제외합니다. 이는 탐색 필터가 아닌 잔여 필터입니다.
다음 쿼리는 이 연산자를 보여줍니다.
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
실행 계획 세그먼트는 다음과 같이 표시됩니다.
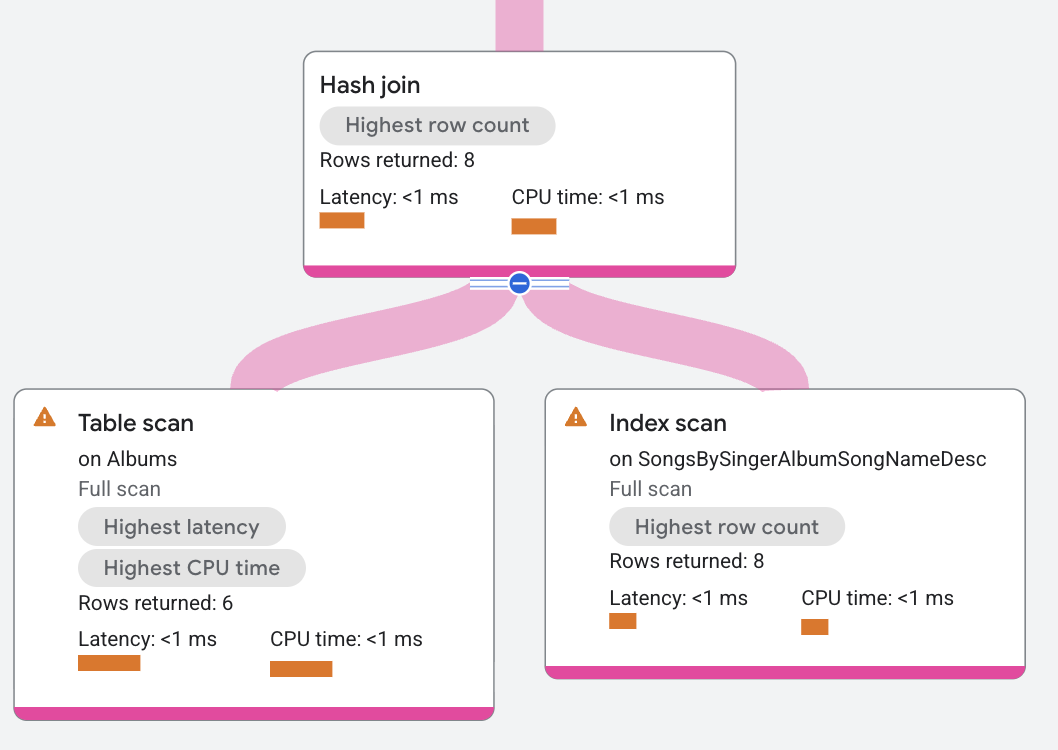
실행 계획에서 빌드는 Albums 테이블에 대한 스캔을 분산하는 분산 통합입니다. 프로브는 SongsBySingerAlbumSongNameDesc 색인에 대한 스캔을 분산하는 분산 통합 연산자입니다.
해시 조인 연산자는 빌드 측의 모든 행을 읽습니다. 각 빌드 행은 조건 a.SingerId =
s.SingerId AND a.AlbumId = s.AlbumId의 열을 기반으로 해시 테이블에 배치됩니다. 그런 다음 해시 조인 연산자는 프로브 측의 모든 행을 읽습니다. 각 스캔 행에 대해 해시 조인 연산자는 해시 테이블에서 일치하는 항목을 찾습니다. 일치 항목은 해시 조인 연산자에 의해 반환됩니다.
해시 테이블에서의 일치 결과는 반환되기 전에 나머지 조건으로 필터링될 수도 있습니다. (나머지 조건이 나타나는 부분의 예시는 비동등 조인에 있습니다.) 해시 조인 실행 계획은 메모리 관리 및 조인 변형으로 인해 복잡할 수 있습니다. 메인 해시 조인 알고리즘은 내부, 반, 반대, 외부 조인 변형을 처리하도록 조정됩니다.
속성 및 실행 통계
연산자의 속성은 연산자가 실행될 때 사용되는 특성을 설명합니다. 실행 통계는 쿼리 실행 중에 수집되는 값으로, 연산자의 성능을 평가하는 데 도움이 됩니다.
속성
| 이름 | 설명 |
|---|---|
| 실행 메소드입니다. | 행 실행에서 연산자는 한 번에 한 행을 처리합니다. 일괄 실행에서 연산자는 한 번에 행 배치를 처리합니다. |
실행 통계
| 이름 | 설명 |
|---|---|
| 지연 시간 | 연산자에서 실행된 모든 실행의 경과 시간입니다. |
| 누적 지연 시간 | 현재 연산자와 그 하위 요소의 총 시간입니다. |
| CPU 시간 | 연산자를 실행하는 데 사용된 CPU 시간의 합계입니다. |
| 누적 CPU 시간 | 연산자와 그 하위 요소를 실행하는 데 소요된 총 CPU 시간입니다. |
| 실행 시간 | 쿼리를 실행하고 결과를 처리하는 데 걸린 총시간입니다. |
| 반환된 행 | 이 연산자가 출력한 행 수 |
| 실행 횟수 | 연산자가 실행된 횟수입니다. 일부 실행은 동시에 실행할 수 있습니다. |
병합 조인
병합 조인 연산자는 병합을 기반으로 구현한 SQL 조인입니다. 조인의 양측 모두 조인 조건에 사용된 열로 정렬된 행을 생성합니다. 병합 조인은 두 입력 스트림을 동시에 사용하고 조인 조건이 충족되었을 때 행을 출력합니다. 입력이 정렬되지 않은 경우 옵티마이저가 계획에 명시적인 Sort 연산자를 추가합니다.
병합 조인에는 다음과 같은 장점이 있습니다.
- 데이터가 이미 정렬되어 있으면 메모리가 필요하지 않습니다.
- 데이터가 정렬되지 않은 경우에도 분산 조인의 경우 루트에 큰 해시 테이블을 만드는 대신 각 개별 분할에서 정렬을 실행할 수 있습니다.
병합 조인은 최적화 도구에서 자동으로 선택되지 않습니다. 이 연산자를 사용하려면 다음 예시에 표시된 것처럼 쿼리 힌트에서 조인 메서드를 MERGE_JOIN에 설정합니다.
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
실행 계획은 다음과 같이 표시됩니다.
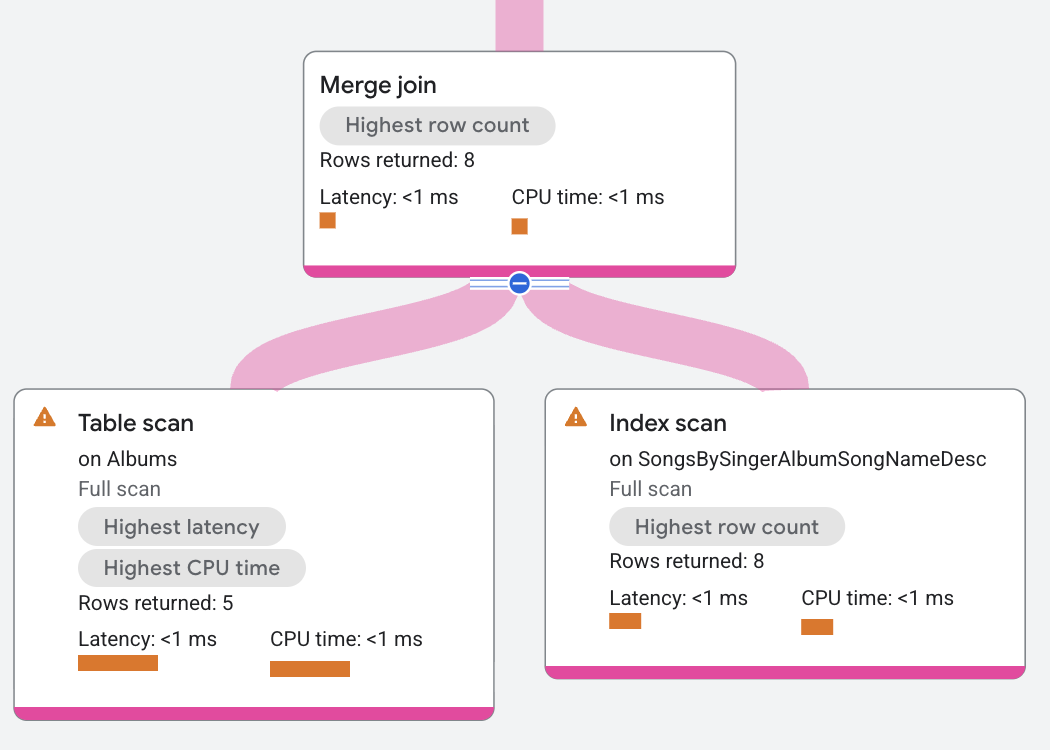
이 실행 계획에서 병합 조인은 데이터가 있는 위치에서 조인이 실행되도록 분산됩니다. 또한 이 예시에서는 두 테이블 스캔이 조인 조건인 SingerId, AlbumId를 기준으로 이미 정렬되어 있으므로 추가 정렬 연산자 없이 이 예시에서 병합 조인을 사용할 수 있습니다. 이 계획에서는 Albums 테이블의 왼쪽 스캔은 SingerId, AlbumId가 오른쪽 스캔의 SingerId_1, AlbumId_1 값보다 작을 때 진행됩니다. 마찬가지로 오른쪽 스캔은 값이 왼쪽 스캔의 값보다 작을 때마다 진행됩니다. 이 병합 진행은 일치하는 행을 반환하기 위해 등가를 계속 검색합니다.
다음 쿼리를 사용하는 또 다른 병합 조인 예시를 살펴보세요.
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Total Junk | The Second Time |
| Total Junk | Starting Again |
| Total Junk | Nothing Is The Same |
| Total Junk | Let's Get Back Together |
| Total Junk | I Knew You Were Magic |
| Total Junk | Blue |
| Total Junk | 42 |
| Total Junk | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Green | Not About The Guitar |
| Nothing To Do With Me | The Second Time |
| Nothing To Do With Me | Starting Again |
| Nothing To Do With Me | Nothing Is The Same |
| Nothing To Do With Me | Let's Get Back Together |
| Nothing To Do With Me | I Knew You Were Magic |
| Nothing To Do With Me | Blue |
| Nothing To Do With Me | 42 |
| Nothing To Do With Me | Not About The Guitar |
| Play | The Second Time |
| Play | Starting Again |
| Play | Nothing Is The Same |
| Play | Let's Get Back Together |
| Play | I Knew You Were Magic |
| Play | Blue |
| Play | 42 |
| Play | Not About The Guitar |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
실행 계획은 다음과 같이 표시됩니다.
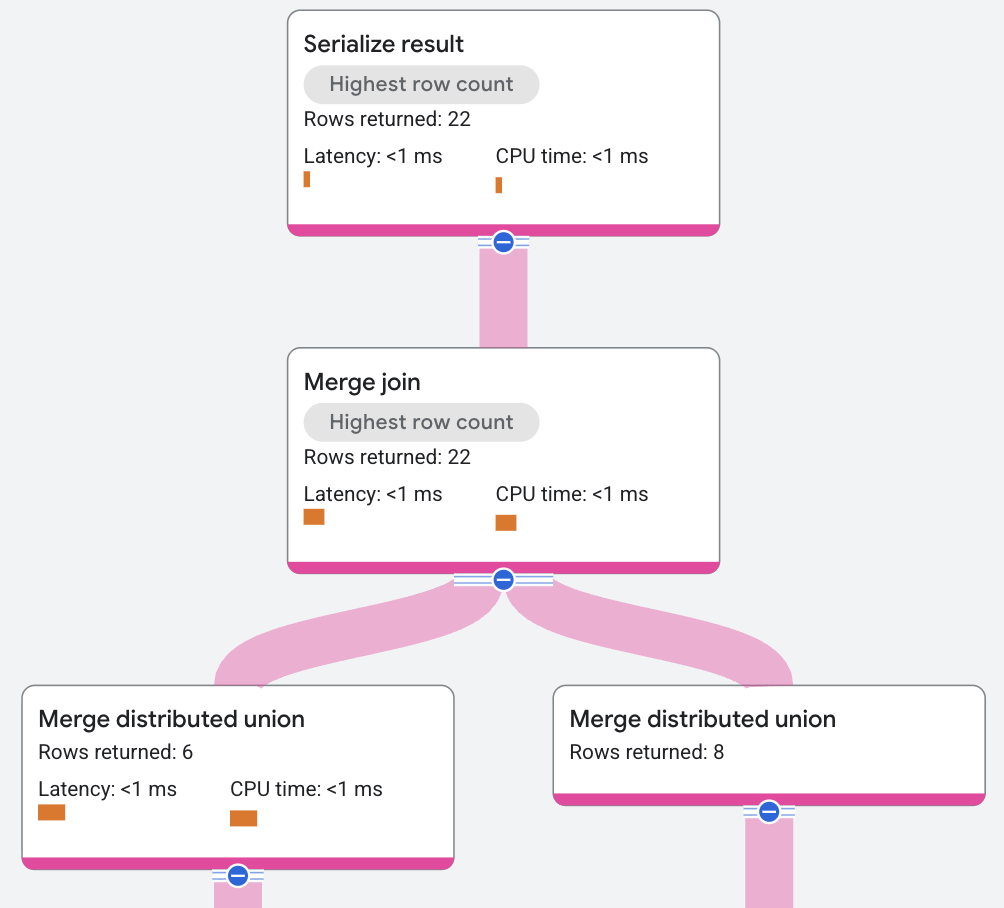
앞의 실행 계획에서 쿼리 최적화 도구는 병합 조인을 실행하기 위해 추가 정렬 연산자를 도입했습니다. 이 예시 쿼리에서 JOIN 조건은 AlbumId에만 있으며, 이것은 데이터 저장 방식이 아니므로, 정렬을 추가해야 합니다. 쿼리 엔진은 전역 대신 로컬로 정렬할 수 있게 해주는 분산 병합 알고리즘을 지원하여, CPU 비용을 분산 및 병렬화합니다.
일치 결과는 나머지 조건으로 필터링될 수도 있습니다. 예를 들어 잔여 조건은 비동등 조인에 표시됩니다. 추가 정렬 요구사항으로 인해 병합 조인 실행 계획이 복잡해질 수 있습니다. 메인 병합 조인 알고리즘은 내부, 반, 반대, 외부 조인 변형을 처리합니다.
속성 및 실행 통계
연산자의 속성은 연산자가 실행될 때 사용되는 특성을 설명합니다. 실행 통계는 쿼리 실행 중에 수집되는 값으로, 연산자의 성능을 평가하는 데 도움이 됩니다.
속성
| 이름 | 설명 |
|---|---|
| 실행 메소드입니다. | 행 실행에서 연산자는 한 번에 한 행을 처리합니다. 일괄 실행에서 연산자는 한 번에 행 배치를 처리합니다. |
실행 통계
| 이름 | 설명 |
|---|---|
| 지연 시간 | 연산자에서 실행된 모든 실행의 경과 시간입니다. |
| 누적 지연 시간 | 현재 연산자와 그 하위 요소의 총 시간입니다. |
| CPU 시간 | 연산자를 실행하는 데 사용된 CPU 시간의 합계입니다. |
| 누적 CPU 시간 | 연산자와 그 하위 요소를 실행하는 데 소요된 총 CPU 시간입니다. |
| 실행 시간 | 쿼리를 실행하고 결과를 처리하는 데 걸린 총시간입니다. |
| 반환된 행 | 이 연산자가 출력한 행 수 |
| 실행 횟수 | 연산자가 실행된 횟수입니다. 일부 실행은 동시에 실행할 수 있습니다. |
재귀적 통합
재귀적 통합 연산자는 base 케이스를 나타내는 입력과 recursive 케이스를 나타내는 입력, 두 개의 입력의 통합을 수행합니다. 정량화된 경로 순회가 있는 그래프 쿼리에서 사용됩니다. 기본 입력은 정확히 한 번만 먼저 처리됩니다. 재귀 입력은 재귀가 종료될 때까지 처리됩니다. 재귀는 지정된 경우 상한에 도달하거나 재귀로 새 결과가 생성되지 않으면 종료됩니다. 다음 예시에서는 Collaborations 테이블이 스키마에 추가되고 MusicGraph라는 속성 그래프가 생성됩니다.
CREATE TABLE Collaborations (
SingerId INT64 NOT NULL,
FeaturingSingerId INT64 NOT NULL,
AlbumTitle STRING(MAX) NOT NULL,
) PRIMARY KEY(SingerId, FeaturingSingerId, AlbumTitle);
CREATE OR REPLACE PROPERTY GRAPH MusicGraph
NODE TABLES(
Singers
KEY(SingerId)
LABEL Singers PROPERTIES(
BirthDate,
FirstName,
LastName,
SingerId,
SingerInfo)
)
EDGE TABLES(
Collaborations AS CollabWith
KEY(SingerId, FeaturingSingerId, AlbumTitle)
SOURCE KEY(SingerId) REFERENCES Singers(SingerId)
DESTINATION KEY(FeaturingSingerId) REFERENCES Singers(SingerId)
LABEL CollabWith PROPERTIES(
AlbumTitle,
FeaturingSingerId,
SingerId),
);
다음 그래프 쿼리는 지정된 가수와 공동작업했거나 해당 공동작업자와 공동작업한 가수를 찾습니다.
GRAPH MusicGraph
MATCH (singer:Singers {singerId:42})-[c:CollabWith]->{1,2}(featured:Singers)
RETURN singer.SingerId AS singer, featured.SingerId AS featured
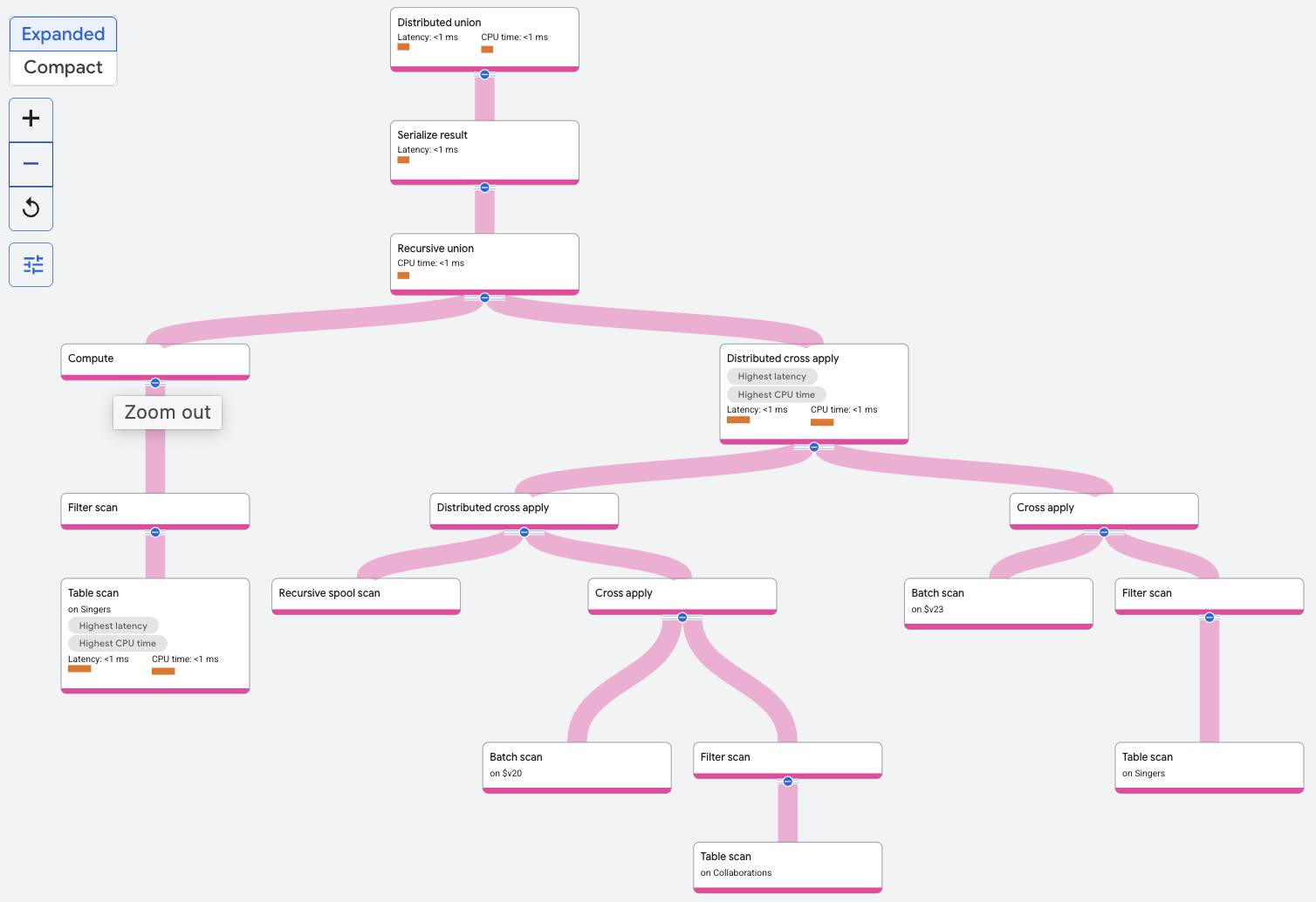
재귀적 통합 연산자는 Singers 테이블을 필터링하여 지정된 SingerId가 있는 가수를 찾습니다. 이는 재귀적 통합의 기본 입력입니다. 재귀적 통합에 대한 재귀적 입력은 다른 쿼리에 대한 분산 교차 적용 또는 기타 조인 연산자로 구성되어 이전 조인 반복의 결과와 Collaborations 테이블을 반복적으로 조인합니다. 기본 입력의 행이 0번째 반복을 구성합니다.
각 반복에서 반복의 출력은 재귀 스풀 스캔에 의해 저장됩니다. 재귀 스풀 스캔의 행은 spoolscan.featuredSingerId = Collaborations.SingerId의 Collaborations 테이블과 조인됩니다. 재귀는 두 번의 반복이 완료되면 종료되는데, 이는 쿼리에서 지정된 상한값이기 때문입니다.
속성 및 실행 통계
연산자의 속성은 연산자가 실행될 때 사용되는 특성을 설명합니다. 실행 통계는 쿼리 실행 중에 수집되는 값으로, 연산자의 성능을 평가하는 데 도움이 됩니다.
속성
| 이름 | 설명 |
|---|---|
| 실행 메소드입니다. | 행 실행에서 연산자는 한 번에 한 행을 처리합니다. 일괄 실행에서 연산자는 한 번에 행 배치를 처리합니다. |
실행 통계
| 이름 | 설명 |
|---|---|
| 지연 시간 | 연산자에서 실행된 모든 실행의 경과 시간입니다. |
| 누적 지연 시간 | 현재 연산자와 그 하위 요소의 총 시간입니다. |
| CPU 시간 | 연산자를 실행하는 데 사용된 CPU 시간의 합계입니다. |
| 누적 CPU 시간 | 연산자와 그 하위 요소를 실행하는 데 소요된 총 CPU 시간입니다. |
| 실행 시간 | 쿼리를 실행하고 결과를 처리하는 데 걸린 총시간입니다. |
| 반환된 행 | 이 연산자가 출력한 행 수 |
| 실행 횟수 | 연산자가 실행된 횟수입니다. 일부 실행은 동시에 실행할 수 있습니다. |