
배열 서브 쿼리는 스칼라 서브 쿼리와 비슷하지만 서브 쿼리가 입력 행을 2개 이상 사용할 수 있다는 점이 다릅니다. Spanner는 사용된 행을 사용된 입력 행당 요소 하나를 포함하는 단일 스칼라 출력 배열로 변환합니다.
데이터베이스 스키마
이 페이지의 쿼리 및 실행 계획은 다음 데이터베이스 스키마를 기반으로 합니다.
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
다음과 같은 데이터 조작 언어(DML) 문을 사용하여 이러한 테이블에 데이터를 추가할 수 있습니다.
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
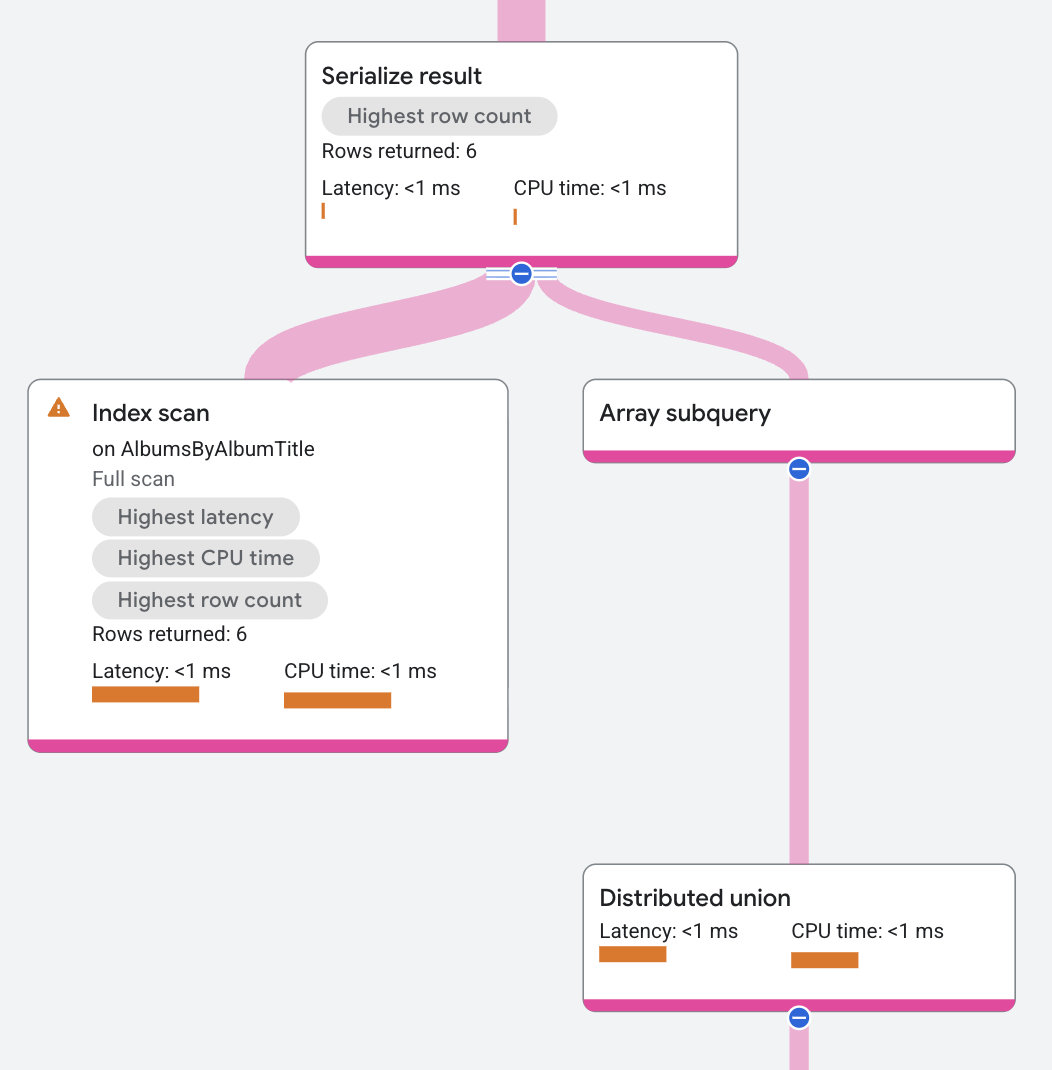
다음 쿼리는 배열 하위 쿼리 연산자를 보여줍니다.
SELECT a.albumid,
array
(
select concertdate
FROM concerts
WHERE concerts.singerid = a.singerid)
FROM albums AS a;
서브 쿼리는 다음과 같습니다.
SELECT concertdate
FROM concerts
WHERE concerts.singerid = a.singerid;
Spanner는 각 AlbumId에 대한 서브 쿼리 결과를 해당 AlbumId에 대응한 ConcertDate 행 배열로 변환합니다. 실행 계획에는 분산 통합 연산자 위에 Array Subquery라는 라벨이 지정된 배열 서브 쿼리가 표시됩니다.
속성 및 실행 통계
연산자의 속성은 연산자가 실행될 때 사용되는 특성을 설명합니다. 실행 통계는 쿼리 실행 중에 수집되는 값으로, 연산자의 성능을 평가하는 데 도움이 됩니다.
속성
| 이름 | 설명 |
|---|---|
| 실행 메소드입니다. | 행 실행에서 연산자는 한 번에 한 행을 처리합니다. 일괄 실행에서 연산자는 한 번에 행 배치를 처리합니다. |
실행 통계
| 이름 | 설명 |
|---|---|
| 지연 시간 | 연산자에서 실행된 모든 실행의 경과 시간입니다. |
| 누적 지연 시간 | 현재 연산자와 그 하위 요소의 총 시간입니다. |
| CPU 시간 | 연산자를 실행하는 데 사용된 CPU 시간의 합계입니다. |
| 누적 CPU 시간 | 연산자와 그 하위 요소를 실행하는 데 소요된 총 CPU 시간입니다. |
| 실행 시간 | 쿼리를 실행하고 결과를 처리하는 데 걸린 총시간입니다. |
| 반환된 행 | 이 연산자가 출력한 행 수 |
| 실행 횟수 | 연산자가 실행된 횟수입니다. 일부 실행은 동시에 실행할 수 있습니다. |