
רמת השירות Standard של Memorystore for Redis מאפשרת להרחיב את השאילתות לקריאה של האפליקציה באמצעות רפליקות לקריאה. בדף הזה מניחים שאתם מכירים את היכולות של רמות השירות השונות של Memorystore Redis.
רפליקות לקריאה מאפשרות לכם להרחיב את עומס העבודה של הקריאה על ידי שליחת שאילתות לרפליקות. נקודת קצה לקריאה מסופקת כדי להקל על האפליקציות להפיץ שאילתות בין העותקים. מידע נוסף זמין במאמר הגדלת קריאות באמצעות נקודת קצה לקריאה.
הוראות לניהול מופע Redis עם רפליקות לקריאה מפורטות במאמר ניהול רפליקות לקריאה.
תרחישי שימוש בעותקים לקריאה
מאגר נתוני סשנים, טבלת הישגים, מנוע המלצות ותרחישי שימוש אחרים מחייבים זמינות גבוהה של המופע. בתרחישי השימוש האלה יש הרבה יותר פעולות קריאה מפעולות כתיבה, ובדרך כלל אפשר לסבול קריאות לא עדכניות. במקרים כאלה, כדאי להשתמש בעותקים לקריאה כדי להגדיל את הזמינות והמדרגיות של המופע.
איך פועלת רפליקה לקריאה
- כברירת מחדל, העותקים לקריאה לא מופעלים במופעים במסלול הרגיל.
- אחרי שמפעילים רפליקות לקריאה במכונה, אי אפשר להשבית אותן יותר במכונה הזו.
- במופעים ברמת Standard אפשר להגדיר 1 עד 5 עותקים לקריאה.
- נקודת הקצה לקריאה מספקת נקודת קצה אחת להפצת שאילתות בין צמתי העתקה.
- העתקים לקריאה נשמרים באמצעות שכפול אסינכרוני של Redis.
הערות ומגבלות
- שכפולים לקריאה נתמכים רק בגדלים של מופעים עם צמתים בגודל של 5 GB ומעלה.
- אפשר להפעיל העתקים לקריאה רק במופעים שמשתמשים ב-Redis בגרסה 5.0 ומעלה.
- אם מציינים אזור ואזור חלופי להקצאת צמתים, Memorystore משתמש באזורים האלה לצומת הראשון ולצומת השני במופע. לאחר מכן, Memorystore בוחר את האזורים לכל הצמתים הנותרים שהוקצו למופע.
- צריך להקצות למכונה טווח כתובות IP בפורמט CIDR של
/28או יותר. גדלים גדולים יותר של טווחים, כמו/27ו-/26, הם תקינים. התכונה הזו לא תומכת בטווחים קטנים יותר כמו/29.
ארכיטקטורה
כשמפעילים רפליקות לקריאה, מציינים את מספר הרפליקות שרוצים במופע. Memorystore מחלק באופן אוטומטי את הצמתים הראשיים ואת הצמתים של הרפליקות לקריאה בין האזורים הזמינים באזור.
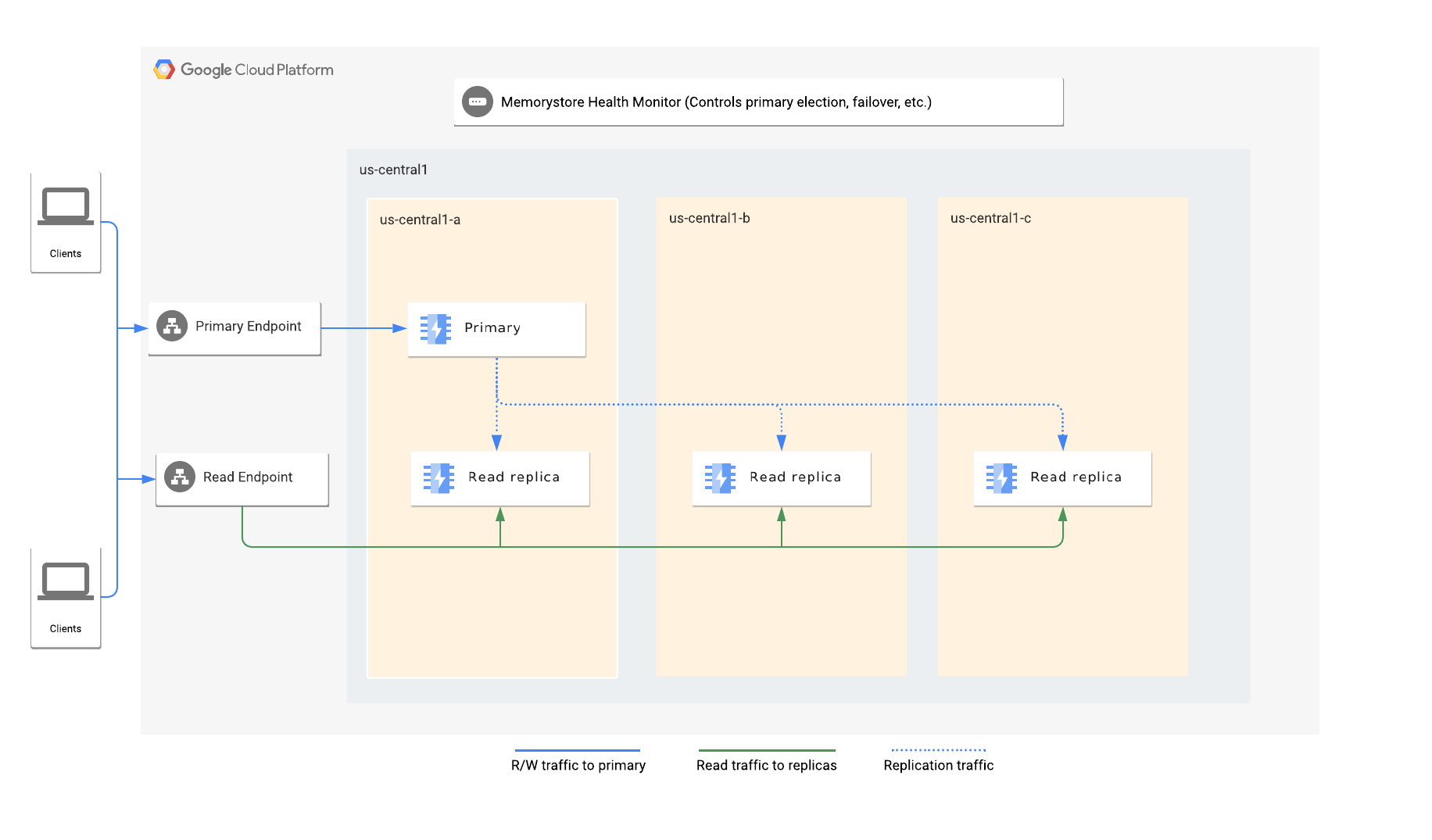
לכל מופע יש נקודת קצה ראשית ונקודת קצה לקריאה. נקודת הקצה הראשית תמיד מפנה את התנועה לצומת הראשי, בעוד שנקודת הקצה לקריאה מבצעת איזון עומסים אוטומטי של שאילתות קריאה בין העותקים הזמינים.
שירות ניטור תקינות של Memorystore for Redis מנטר את המופע ואחראי לזיהוי כשל בצומת הראשי. הוא בוחר רפליקה כצומת הראשי החדש ומתחיל מעבר אוטומטי לגיבוי ולשיקום (failover) לצומת הראשי החדש.
מעבר לגיבוי במקרה של כשל במכונות עם רפליקות לקריאה
אם השרת הראשי נכשל, שירות ניטור תקינות של Memorystore מתחיל את המעבר לגיבוי, והשרת הראשי החדש זמין לקריאה ולכתיבה. המעבר לגיבוי מסתיים בדרך כלל תוך פחות מ-30 שניות.
כשמתרחש מעבר לגיבוי, נקודת הקצה הראשית מפנה אוטומטית את התנועה לנקודת הקצה הראשית החדשה. עם זאת, כל חיבורי הלקוח לנקודת הקצה הראשית מתנתקים במהלך מעבר לגיבוי. אפליקציות עם לוגיקה של ניסיון חוזר להתחברות יתחברו מחדש באופן אוטומטי ברגע שהשרת הראשי החדש יהיה אונליין. חלק מהחיבורים של הלקוח לנקודת הקצה לקריאה גם עוברים ניתוקים מהרפליקה לקריאה שקודמה לראשי במהלך יתירות כשל. החיבורים לרפליקות שנותרו ממשיכים לפעול במהלך מעבר לגיבוי. בניסיון חוזר, החיבורים מופנים לרפליקות החדשות.
כשמתרחש מעבר לגיבוי, בגלל האופי האסינכרוני של השכפול, יכול להיות שיהיה הבדל בין העותקים המשוכפלים בפיגור השכפול. עם זאת, תהליך המעבר לגיבוי פועל כמיטב יכולתו כדי לעבור לגיבוי עם ההשהיה הקצרה ביותר. כך אפשר לצמצם את כמות הנתונים שאובדים ואת הירידה בתפוקת הקריאה במהלך מעבר לגיבוי. השרת הראשי החדש יכול להיות באותו אזור או באזור אחר כמו השרת הראשי הקודם. אם העותק נמצא באותו אזור כמו השרת הראשי הקודם, והוא בעל ההשהיה הנמוכה ביותר, הוא נבחר להיות השרת הראשי החדש. אם לא, עותק משוכפל מאזור אחר יכול להפוך לראשי החדש.
מכיוון שהשכפול הוא אסינכרוני, תמיד יש סיכוי לקרוא נתונים לא עדכניים במהלך מעבר לגיבוי. בנוסף, בזמן שהשרת הראשי החדש מקודם, יכול להיות שחלק מהפעולות שבוצעו במופע יאבדו. האפליקציות צריכות להיות מסוגלות להתמודד עם התנהגות כזו.
Redis עושה כל מאמץ כדי למנוע מצב שבו הרפליקות האחרות דורשות סנכרון מלא במהלך יתירות כשל, אבל זה יכול לקרות בתרחישים נדירים. סינכרון מלא יכול להימשך כמה דקות עד שעה, בהתאם לקצב הכתיבה ולגודל מערך הנתונים שמשוכפל. במהלך הזמן הזה, רפליקות שעוברות סנכרון מלא לא זמינות לקריאה. אחרי שהסנכרון יסתיים, אפשר יהיה לגשת לרפליקות כדי לקרוא אותן.
מצבי כשל של עותקים לקריאה
במקרים שבהם יש מופעים עם עותקים לקריאה בלבד, יכולות להתרחש תקלות שונות ובעיות שמשפיעות על האפליקציה. ההתנהגות משתנה בהתאם למספר העותקים שיש למופע – עותק אחד או שניים או יותר. בקטע הזה מפורטים כמה מצבי כשל נפוצים ומתוארת התנהגות המופע במצבים האלה.
רפליקה לא זמינה
אם רפליקה נכשלת מסיבה כלשהי, היא מסומנת כלא זמינה וכל החיבורים אליה מסתיימים אחרי פסק זמן מסוים. אחרי שהעותק המשוכפל ישוחזר, חיבורים חדשים ינותבו לעותק המשוכפל המשוחזר. הזמן לשחזור העותק משתנה בהתאם למצב הכשל.
אם מתרחש כשל באזור, מערכת Memorystore for Redis לא משחזרת את העותק עד שהאזור הופך לזמין.
כשל באזור
אם האזור שבו נמצאת השרת הראשי נכשל, השרת הראשי עובר אוטומטית לגיבוי (failover) לעותק משוכפל באזור אחר. אם למופע יש רק עותק משוכפל אחד, נקודת הקצה לקריאה לא זמינה למשך ההשבתה של האזור. אם למופע יש יותר מעותק משוכפל אחד, העותקים המשוכפלים מחוץ לאזור המושפע זמינים לקריאה.
אם יש כשל באזור שבו נמצאת רפליקה אחת או יותר, הרפליקות האלה לא יהיו זמינות למשך הכשל באזור. אם יש כשל בשני אזורים ויש שני עותקים או יותר, העותק עם הפיגור הכי קטן באזורים שנותרו מקודם לסטטוס primary. כל העותקים שנותרו באזורים שלא הושפעו זמינים לקריאה.
מחיצת רשת
חלוקת רשת היא תרחיש שבו הצמתים ממשיכים לפעול אבל לא יכולים להגיע לכל הלקוחות, האזורים או צמתי ה-peer. ב-Memorystore נעשה שימוש במערכת מבוססת-קוורום כדי למנוע מצמתים מבודדים לשרת פעולות כתיבה. במקרה של חלוקת רשת, כל שרת ראשי במחיצה של מיעוט מוריד את עצמו בדרגה. אם קיים רוב במחיצה, היא בוחרת ראשית חדשה אם עדיין אין לה כזו. רפליקות מבודדות ממשיכות להציג קריאות. עם זאת, יכול להיות שהם יהפכו ללא רלוונטיים אם הם לא יוכלו להסתנכרן מהשרת הראשי.
כדי לבדוק אם הקישור שבור, עוקבים אחרי המדדים master_link_down_since_seconds ו-offset_diff כדי לזהות צמתים מבודדים.
סנכרון מלא
אם העותק מתרחק מדי מהמקור, מתבצע סנכרון מלא שמעתיק תמונה מלאה מהמקור לעותק. הפעולה הזו יכולה להימשך בין דקות לשעה במקרה הגרוע. סנכרון מלא לא גורם לכשל במופע, אבל במהלך הסנכרון המלא העותק לא זמין לקריאה, והמקור חווה ניצול גבוה יותר של CPU וזיכרון.
נקודת הקצה הראשית מחזירה READONLY
יכול להיות שפעולות הכתיבה שלכם לנקודת הקצה הראשית של מכונת Memorystore for Redis עם רפליקות לקריאה יקבלו באופן לא צפוי שגיאות -READONLY You can't write against a read
only replica.. מומלץ לסגור את החיבורים למופע וליצור אותם מחדש. ברוב המקרים, הפעלה מחדש של אפליקציית הלקוח יכולה לפתור את הבעיה. אם האפשרויות האלה לא מתאימות או שהבעיה נמשכת, אפשר לפנות לצוות התמיכה של Google Cloud .
הגדלת מספר הקריאות באמצעות נקודת הקצה לקריאה
עותקים לקריאה מאפשרים לאפליקציות להרחיב את הקריאות שלהן על ידי קריאה מהעותקים. אפליקציות יכולות להתחבר ל-read replicas דרך נקודת הקצה לקריאה.
קריאת נקודת קצה
נקודת הקצה לקריאה היא כתובת IP שהאפליקציה מתחברת אליה. הוא מבצע איזון עומסים שווה בין החיבורים בכל העותקים המשוכפלים במכונה. חיבורים לרפליקה לקריאה יכולים לשלוח שאילתות קריאה, אבל לא שאילתות כתיבה. לכל מופע במסלול הרגיל שמופעלות בו רפליקות לקריאה יש נקודת קצה לקריאה. הוראות להצגת נקודת הקצה לקריאה של המופע מופיעות במאמר הצגת מידע על העתק לקריאה של המופע.
התנהגות של נקודת הקצה לקריאה
- נקודת הקצה לקריאה מחלקת אוטומטית את החיבורים בין כל העותקים הזמינים. החיבורים לא מופנים אל השרת הראשי.
- עותק נחשב לזמין כל עוד הוא יכול להציג תנועה של לקוחות. הנתון לא כולל מקרים שבהם מתבצע סנכרון מלא של העותק עם השרת הראשי.
- רפליקה עם השהיית שכפול גבוהה ממשיכה להעביר תנועה. אפליקציות עם נפח כתיבה גבוה יכולות לקרוא נתונים לא עדכניים מרפליקה שמבצעת כתיבות רבות.
- אם צומת משוכפל הופך לצומת הראשי, החיבורים לצומת הזה מסתיימים והחיבורים החדשים מנותבים מחדש לצומת משוכפל חדש.
- חיבורים נפרדים לנקודת הקצה לקריאה מכוונים לאותה רפליקה למשך החיים של החיבור. אין ערובה לכך שחיבורים שונים מאותו מארח לקוח יפנו לאותו צומת משוכפל.
קריאה של נתוני העקביות
השמירה על העותקים לקריאה מתבצעת באמצעות שכפול אסינכרוני של Redis OSS מקורי. בגלל האופי של השכפול האסינכרוני, יכול להיות שהעותק יהיה מאחורי המקור. אפליקציות עם כתיבות קבועות שקוראות גם מהעותק צריכות להיות מסוגלות לסבול קריאות לא עקביות.
אם האפליקציה דורשת עקביות של 'קריאה אחרי כתיבה', מומלץ להשתמש בנקודת הקצה הראשית גם לכתיבה וגם לקריאה. השימוש בנקודת הקצה הראשית מבטיח שהקריאות תמיד יופנו אל השרת הראשי. גם במקרה הזה, יכול להיות שיהיו קריאות לא עדכניות אחרי מעבר לגיבוי.
הגדרת ערכי TTL במפתחות בשרת הראשי מבטיחה שלא תהיה אפשרות לקרוא מפתחות שתוקף פג, לא מהשרת הראשי ולא מהרפליקה. הסיבה לכך היא ש-Redis מוודא שלא תהיה אפשרות לקרוא מפתח שתוקף פג מהרפליקה.
התנהגות של הפעלת רפליקות לקריאה במופע קיים
הפעלת רפליקות לקריאה היא פעולה בלעדית, כלומר אי אפשר לבצע שינויים אחרים במופע של פעולת עדכון כחלק מאותה פעולה שמפעילה רפליקות לקריאה.
כדי להפעיל רפליקות לקריאה במופע Redis קיים, צריך להקצות טווח כתובות IP משני תקין למיקום הצומת. הטווח הזה חייב להיות טווח Classless Inter-Domain Routing (CIDR) בגודל
/28, ללא קשר לגודל של טווח כתובות ה-IP הקיים שהוקצה ל-Memorystore for Redis.- כשמפעילים רפליקות לקריאה עבור מופע Redis, צריך לספק את טווח כתובות ה-IP הנוסף. אתם יכולים לבחור טווח ספציפי או לאפשר ל-Memorystore לבחור טווח בשבילכם.
כתובת ה-IP לקריאה/כתיבה של המופע לא משתנה כשמפעילים העתקים לקריאה. כתובת ה-IP של נקודת הקצה לקריאה נמצאת בטווח המקורי שהוקצה למופע Memorystore, ולא בטווח הנוסף שסיפקתם כשמפעילים רפליקות לקריאה.
כדי למצוא את נקודת הקצה החדשה לקריאה, צריך להציג את המידע על העותק לקריאה של המופע אחרי שהפעולה להפעלת העותקים לקריאה מסתיימת.
שינוי הגודל של מכונה
אפשר לשנות את מספר העותקים לקריאה של המופע, וגם לשנות את גודל הצומת:
הוראות להוספה ולהסרה של צמתים מופיעות במאמר הוספה או הסרה של צמתים משוכפלים ממופע Redis.
הוראות לשינוי הגודל של צמתי Redis מופיעות במאמר שינוי הגודל של צמתי Redis.
מומלץ להתאים את המכונה לעומס בתקופה של תעבורת נתונים נמוכה של קריאה וכתיבה, כדי למזער את ההשפעה על האפליקציה.
הוספת רפליקה חדשה גורמת לעומס נוסף על השרת הראשי בזמן שהרפליקה מבצעת סנכרון מלא. כשמוסיפים צמתים, החיבורים הקיימים לא מושפעים ולא מועברים. אחרי שהרפליקה החדשה זמינה, היא מתחילה לקבל חיבורים מנקודת הקצה ומשרתת קריאות. הסרת רפליקה סוגרת את כל החיבורים הפעילים שמופנים לרפליקה הזו. צריך להגדיר את אפליקציית הלקוח כך שתתחבר מחדש באופן אוטומטי לנקודת הקצה לקריאה כדי ליצור מחדש חיבורים לרפליקות שנותרו.
שיטות מומלצות
ניהול זיכרון
Redis לא מאפשר ללקוחות לכתוב מעבר למגבלה של maxmemory במופע. עם זאת, תקורה כמו פיצול, מאגרי שכפול ופקודות יקרות כמו EVAL יכולות להגדיל את ניצול הזיכרון מעבר למגבלה הזו. במקרים כאלה, Memorystore לא מאפשר כתיבה עד שהעומס על הזיכרון יורד. לפרטים נוספים, אפשר לעיין במאמר שיטות מומלצות לניהול זיכרון.
אם מתבצעת פעולת BGSAVE ב-Memorystore בגלל ייצוא או שכפול של סנכרון מלא, ומתרחש מצב OOM, תהליך הצאצא מופסק. במקרה כזה, הפעולה BGSAVE נכשלת ושרת הצומת של Redis נשאר זמין.
כדי להבטיח שכפול ויצירת תמונת מצב בכל הנסיבות, מומלץ לשמור על ניצול זיכרון של פחות מ-50% במהלך פעולות חשובות כמו ייצוא, שינוי קנה מידה וכו'. אפשר להפעיל ייצוא או מעבר לגיבוי בשעת כשל באופן ידני כדי לראות את ההשפעה של הפעולות האלה על הביצועים.
ניהול המעבד (CPU)
Memorystore מספק מדדים לגבי השימוש במעבד ומספר החיבורים לכל צומת. מומלץ להקצות מספיק תקורה כדי שתוכלו להתמודד עם אובדן של אזור זמינות יחיד. היעד האידיאלי עשוי להשתנות בהתאם למספר העותקים המשוכפלים ולדפוסי השימוש, אבל נקודת התחלה טובה היא לשמור על שימוש במעבד של העותקים המשוכפלים מתחת ל-50%.
יכול להיות שיהיה שימוש גבוה בצמתים מסוימים אם דפוסי השימוש של הלקוחות לא מאוזנים, או אם פעולות מעבר לגיבוי (failover) גורמות לחוסר איזון בחלוקת החיבורים. במקרה כזה, מומלץ לסגור מעת לעת את החיבורים כדי לאפשר ל-Memorystore לאזן מחדש את החיבורים באופן אוטומטי. ב-Memorystore לא מתבצע איזון מחדש של חיבורים פתוחים.
ניהול היתרה בחיבור
בכל פעם שהחיבורים של צומת נסגרים, הלקוחות צריכים להתחבר מחדש, בדרך כלל על ידי הפעלת חיבור מחדש אוטומטי בספריית הלקוח לפי בחירתכם. כשמציגים מחדש את הצומת, החיבורים הקיימים לא מנותבים מחדש, אבל חיבורים חדשים מנותבים לצומת החדש. לקוחות יכולים להפסיק מדי פעם את החיבורים כדי לוודא שהם מאוזנים בין הצמתים הזמינים.
ניהול של פער הזמן בין הרפליקציות
יכול להיות שיהיה פער בין העותקים, במיוחד אם קצב הכתיבה גבוה מאוד. בתרחישים כאלה, העותק ממשיך להיות זמין לקריאה. במקרה כזה, יכול להיות שהקריאות מהרפליקה יהיו לא עדכניות, והאפליקציה צריכה להיות מסוגלת להתמודד עם זה, או שצריך לטפל בקצב הכתיבה הגבוה.
הפעלת רפליקות לקריאה במופע קיים
לפני שמפעילים רפליקות לקריאה במופע קיים של Memorystore for Redis, מומלץ מאוד לצמצם את תעבורת הכתיבה לצומת הראשי. כך הצומת הראשי יכול לסנכרן את הנתונים עם העותקים באופן מלא. אם לא תצמצמו את תעבורת הכתיבה, יכול להיות שלא תוכלו להפעיל את הרפליקות לקריאה.
המאמרים הבאים
- איך מנהלים עותקים לקריאה
- מידע על ייצוא נתונים ממופע Redis
- מידע נוסף על זמינות גבוהה ב-Memorystore for Redis