
Questa pagina fornisce una panoramica della replica tra regioni per Memorystore for Redis Cluster.
Per istruzioni sulla gestione della replica tra regioni, vedi Utilizzare la replica tra regioni.
La replica tra regioni consente di creare cluster secondari da un cluster primario per rendere il cluster disponibile per le letture in regioni diverse. I cluster secondari forniscono anche ridondanza per gli scenari di ripristino di emergenza in caso di interruzioni regionali.
I concetti chiave in questa pagina includono i seguenti:
- Cluster primario. Un cluster di lettura e scrittura in una singola regione.
- Cluster secondario. Un cluster di sola lettura che esegue la replica dal cluster primario in modo asincrono. Per informazioni sulla promozione e sul distacco dei cluster secondari, vedi le attività detach e switchover che vengono visualizzate in Come gestire la replica tra regioni.
- Nodo replicatore: un nodo nello shard del cluster primario che esegue la replica su un nodo follower nel cluster secondario. Qualsiasi nodo primario o di replica nello shard può svolgere il ruolo di replicatore.
- Nodi follower: nodi nel cluster secondario che eseguono la replica da un nodo replicatore nel cluster primario. Solo i nodi primari nel cluster secondario possono avere il ruolo di follower.
- Conteggio shard e assegnazione slot: i cluster primari e secondari hanno lo stesso numero di shard e assegnazioni di slot.
Vantaggi
I vantaggi della replica tra regioni su Memorystore for Redis Cluster includono i seguenti:
- Disaster recovery: se la regione del cluster primario non è disponibile, puoi scollegare o eseguire il cambio a un cluster secondario in un'altra regione per gestire le richieste di lettura e scrittura. I cluster secondari gestiscono le richieste di lettura senza emettere un comando di cambio o distacco.
- Dati distribuiti geograficamente: la distribuzione geografica dei dati li avvicina a te e riduce la latenza di lettura.
- Bilanciamento del carico geografico per il traffico di lettura: se si verificano connessioni lente o sovraccariche in una regione, puoi instradare il traffico a un'altra regione.
Comportamento delle funzionalità
Questa sezione spiega il comportamento importante della funzionalità di replica tra regioni.
- Scalare la capacità del cluster: quando aumenti la capacità del cluster primario, Memorystore for Redis Cluster scala automaticamente i cluster secondari in modo che corrispondano al cluster primario.
- Scalare il numero di repliche: puoi scalare il numero di repliche per i cluster primari e secondari in modo indipendente in base alle esigenze del tuo workload. Gli aggiornamenti al numero di repliche sono solo locali e non vengono propagati ad altri cluster all'interno della raccolta di cluster di replica tra regioni.
- Eseguire il cambio durante una potenziale interruzione: puoi eseguire un cambio per promuovere un cluster secondario, anche se il cluster primario non è disponibile a causa di un'interruzione. Quando l'interruzione viene risolta, il cluster primario non disponibile diventa un cluster secondario.
- Creare cluster secondari online: quando aggiungi un cluster secondario a un cluster primario, il cluster primario rimane online. Mentre Memorystore for Redis Cluster crea il cluster secondario, il cluster primario gestisce le richieste e replica i dati.
- Creare cluster secondari: puoi avere fino a due cluster secondari. Possono trovarsi nella stessa regione o in regioni diverse tra loro. Non puoi trasformare un cluster esistente in un cluster secondario. Puoi aggiungere solo nuovi cluster come cluster secondari.
- Sincronizzare le impostazioni: Memorystore for Redis Cluster sincronizza automaticamente la maggior parte delle impostazioni del cluster tra i cluster primari e secondari. Per saperne di più su queste impostazioni, vedi Impostazioni cluster.
- Prezzi: Memorystore for Redis Cluster addebita ai clienti che utilizzano la replica tra regioni i costi di tutti i cluster secondari di cui Memorystore for Redis Cluster esegue il provisioning per la replica tra regioni. Per ogni nodo e replica di cui Memorystore for Redis Cluster esegue il deployment sul cluster secondario, ti viene addebitato il costo come per qualsiasi altro cluster primario. Inoltre, ti vengono addebitati i costi di rete per il trasferimento dei dati tra i cluster in regioni diverse.
- Eseguire aggiornamenti di manutenzione: per garantire la compatibilità con la replica tra regioni, durante la creazione del cluster secondario, il cluster primario potrebbe essere sottoposto a un aggiornamento di manutenzione. Questo aggiornamento viene eseguito se il cluster primario non esegue la versione software richiesta. La procedura di aggiornamento potrebbe introdurre una latenza aggiuntiva durante la creazione del cluster secondario. Per saperne di più, vedi Informazioni sulla manutenzione.
Come gestire la replica tra regioni
La replica tra regioni prevede le seguenti attività:
- Creare un cluster secondario: crea un cluster secondario che replichi continuamente i dati dal cluster primario.
- Visualizzare il cluster secondario: visualizza le informazioni sul cluster secondario, inclusi il nome del cluster primario e l'altro cluster secondario nel gruppo di replica.
Scollegare i cluster secondari: il distacco dei cluster secondari è un'operazione in cui scolleghi i cluster secondari dal cluster primario. In questo modo, diventano cluster indipendenti completamente funzionali che consentono sia le letture che le scritture. Dopo un'operazione di distacco, i cluster secondari non replicano più i dati dal cluster primario a cui erano precedentemente associati. Sia il cluster primario originale sia i cluster appena scollegati (ex secondari) funzionano come cluster indipendenti senza alcuna relazione tra loro.
Scollega i cluster secondari per i seguenti motivi:
- Migrazione regionale: esegui una migrazione pianificata delle risorse di Memorystore for Redis Cluster dalla regione primaria a un'altra regione.
- Disaster recovery: attiva rapidamente le risorse di Memorystore for Redis Cluster in una regione secondaria se le risorse nella regione primaria non sono disponibili. Se i cluster secondari non sono completamente sincronizzati con il cluster primario, potrebbe verificarsi una perdita di dati.
Eseguire il cambio dei cluster: esegui un cambio per invertire i ruoli dei cluster primari e secondari. Puoi eseguire un cambio per i seguenti motivi:
- Testare la configurazione di ripristino di emergenza
- Eseguire il cambio durante uno scenario di ripristino di emergenza effettivo
- Eseguire la migrazione del workload
Al termine del cambio, Memorystore for Redis Cluster inverte la direzione della replica. Il cluster secondario precedente ora può accettare sia le letture che le scritture, mentre il cluster primario precedente passa alla modalità di sola lettura.
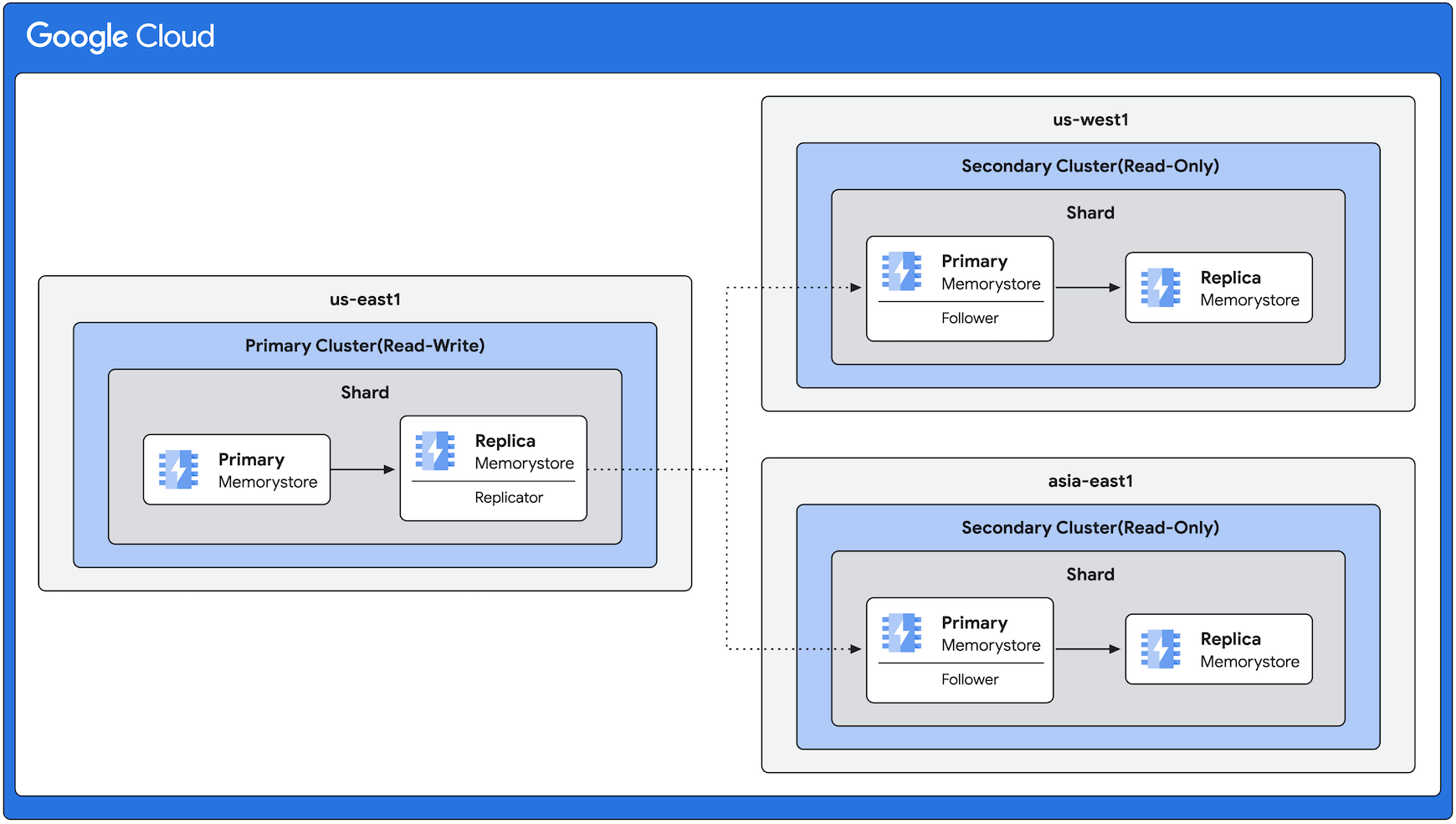
Esempio di architettura per la replica tra regioni
Questo diagramma mostra un cluster primario nella regione us-east1 e cluster secondari nelle regioni us-west1 e asia-east1. La direzione della replica è sempre dal cluster primario ai cluster secondari (in questo esempio, dalla regione us-east1 alle altre regioni).
Anche se questo diagramma mostra lo stesso numero di repliche in tutte le regioni, la replica tra regioni ti consente di avere un numero variabile di repliche in base alle tue esigenze.
Impostazioni cluster
Questa sezione spiega le impostazioni richieste, copiate e sostituite per i cluster primari e secondari che utilizzano la replica tra regioni. Spiega anche le impostazioni che configuri sul cluster primario e quelle che configuri localmente.
Parametri obbligatori per creare un cluster secondario
Per creare un cluster secondario, devi impostare i valori per i seguenti parametri:
- Google Cloud **project**: il progetto in cui si trova il cluster primario e in cui crei il cluster secondario.
- Regione: la regione in cui vuoi che si trovi il cluster secondario.
- Configurazione di Private Service Connect: la configurazione di rete per il cluster secondario.
- Cluster primario: quando crei il cluster secondario, devi indicare un cluster primario. Puoi utilizzare qualsiasi cluster diverso da un cluster secondario come cluster primario. Se non hai un cluster primario, allora crealo.
Impostazioni che un cluster secondario copia dal cluster primario
Quando crei un cluster secondario, questo cluster copia le seguenti impostazioni dal cluster primario:
- Numero di shard
- Modalità di autenticazione IAM
- Modalità di crittografia dei dati in transito
- Configurazioni del cluster
- Versione Redis
- Tipo di nodo
- Modalità di persistenza
Sostituire le impostazioni predefinite
Quando crei un cluster secondario, puoi utilizzare le seguenti impostazioni per sostituire le impostazioni predefinite:
- Configurazione della distribuzione delle zone
- Numero di repliche
- Periodi di manutenzione
- Protezione da eliminazione
- Backup automatici
Aggiornare le impostazioni del cluster
Quando aggiorni le impostazioni del cluster in Memorystore for Redis Cluster, puoi modificare alcune impostazioni solo sul cluster primario. Memorystore for Redis Cluster sincronizza automaticamente queste modifiche con i cluster secondari.
Puoi modificare altre impostazioni sui cluster primari e secondari in modo indipendente. Memorystore for Redis Cluster applica queste modifiche solo localmente e non le sincronizza con gli altri cluster.
Configurare le impostazioni sul cluster primario
Devi modificare le seguenti impostazioni sul cluster primario. Memorystore for Redis Cluster sincronizza automaticamente queste modifiche con i cluster secondari.
Configurare le impostazioni locali
Configura le seguenti impostazioni localmente:
- Protezione da eliminazione
- Numero di repliche
- Periodi di manutenzione
- Endpoint del cluster
- Backup automatici
Best practice per il cambio dei cluster primari e secondari
Quando esegui un cambio, ti consigliamo che segui le istruzioni riportate in questa sezione. In questo modo, l'applicazione può tenere traccia delle scritture e inviarle al cluster appropriato.
- Impedisci all'applicazione di scrivere sul cluster primario.
Se devi promuovere più cluster secondari, determina il cluster secondario che vuoi promuovere a cluster primario. I seguenti fattori possono aiutarti a determinare quale cluster secondario promuovere:
- La vicinanza dell'applicazione al cluster. Questo può influire sulla latenza di scrittura.
- Il cluster secondario più aggiornato, in termini di dati.
- Il cluster secondario più vicino al cluster primario, in termini di impostazioni.
Attendi il completamento dell'operazione di cambio.
Aggiorna l'applicazione in modo che invii tutte le scritture al cluster appena promosso selezionato nel passaggio 2.