
Type
Manufacturing Data Engine (MDE) vous aide à transformer une classe de messages sources en enregistrements d'un type spécifique grâce à l'analyse.
Les types sont des entités de configuration qui représentent la cible de l'opération d'analyse. Ils décrivent un ensemble d'enregistrements structurellement et sémantiquement similaires avec un niveau de précision commun qui, éventuellement, partagent un contexte de métadonnées spécifique.
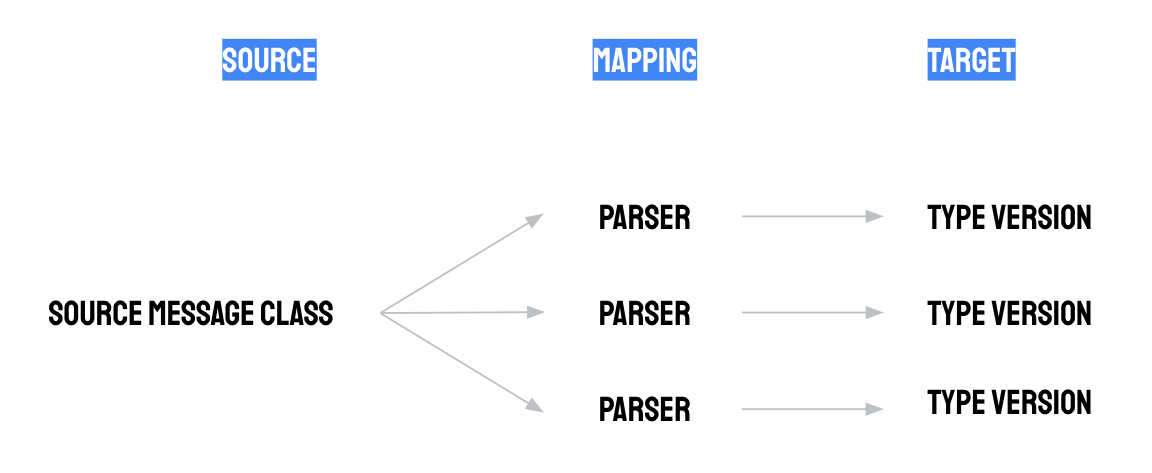
Par exemple, vous pouvez créer des types "état de la machine" et "lectures du capteur de vibrations". Le premier type peut être utilisé pour modéliser les événements de changement d'état de la machine, tels que "En cours d'exécution", "Inactif", "Maintenance planifiée" et "Maintenance non planifiée", tandis que le second peut être utilisé pour modéliser un flux de lectures numériques du capteur de vibrations.
MDE est fourni avec un ensemble de types par défaut, mais vous pouvez en créer d'autres. Les types sont définis par les caractéristiques suivantes :
- Nom : nom du type.
- Archétype : nom de l'archétype sur lequel un type est basé. Dans MDE, un type est toujours associé à un seul archétype.
- Spécifications de stockage : liste des paramètres par récepteur de données. Les spécifications de stockage permettent de configurer l'écriture des enregistrements dans un récepteur de données et de fournir d'autres paramètres spécifiques au récepteur.
- Paramètres de configuration facultatifs, y compris :
- Schéma JSON du champ data (ne s'applique qu'aux types d'archétypes discrets et continus).
- Associations de buckets de métadonnées : liste des buckets de métadonnées pour lesquels les enregistrements du type doivent fournir des références d'instance.
Types et récepteurs de données
Le flux d'enregistrements d'un type donné est traité par les récepteurs de données activés pour un type. Les récepteurs de données peuvent être activés (activés ou désactivés) pour les types. Par exemple, vous pouvez configurer les enregistrements d'un type pour qu'ils soient écrits dans BigQuery, mais pas dans Cloud Storage.
Récepteurs de données compatibles
MDE est compatible avec les récepteurs de données suivants :
- BigQuery
- API Bigtable/Federation
- Cloud Storage
- Pub/Sub (JSON et Protobuf)
Récepteur de données BigQuery
Lorsqu'un nouveau type est créé, MDE crée automatiquement une table de type correspondante dans BigQuery, dans l'ensemble de données mde_data.
Les enregistrements de chaque type sont écrits dans la table de type correspondante.
Récepteur de données Cloud Storage
Les enregistrements sont stockés dans un bucket Cloud Storage appelé <project_id>-gcs-ingestion dans des fichiers AVRO à l'aide du partitionnement Hive avec une fenêtre de 10 minutes et 10 partitions par fenêtre. Les enregistrements sont regroupés dans des dossiers par type.
Récepteur de données Pub/Sub
Le récepteur Pub/Sub publie les enregistrements dans un sujet dédié. Le schéma des messages Pub/Sub est décrit dans le schéma des messages du récepteur Pub/Sub.
Matérialisation des métadonnées
Chaque récepteur de données d'un type peut être configuré pour matérialiser les métadonnées dans les enregistrements. Si ce paramètre est activé, les références d'instance de métadonnées sont résolues en objets d'instance de métadonnées, et les objets sont inclus dans les enregistrements. La manière précise dont les métadonnées sont conservées ou générées dépend du récepteur de données.
Dans BigQuery, par exemple, les métadonnées matérialisées sont écrites dans materialized_metadata_field avec le schéma suivant :
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"additionalProperties": {
"type": "object",
"description": "Metadata instance"
}
}
Archétypes
Les archétypes représentent une superclasse de types. Chaque archétype est conçu pour fournir un modèle de traitement et de stockage optimal pour les enregistrements. Les archétypes définissent les champs obligatoires de base qui doivent être présents dans un enregistrement d'un type donné émis par un analyseur. MDE est fourni avec un ensemble de six archétypes standards et groupés définis par le système, regroupés dans trois familles d'archétypes :
- Série de données numériques (SDN)
- Séries de données discrètes (DDS)
- Séries de données continues (CDS)
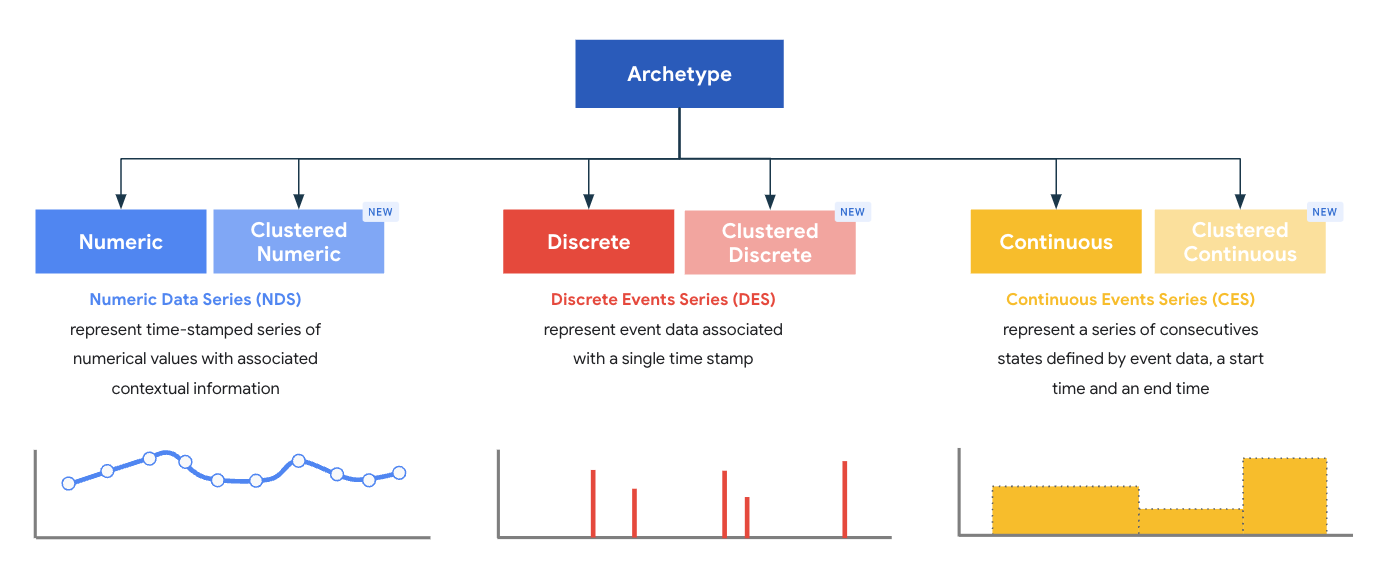
Dans MDE, un type est toujours associé à un seul archétype, et l'archétype d'un type est défini au moment de la création.
Vous pouvez utiliser des types pour définir d'autres contraintes sur les enregistrements proto émis par les analyseurs au-delà de celles imposées par les archétypes. Par exemple, vous pouvez spécifier la forme du champ data pour un type ou définir que les enregistrements d'un type doivent être contextualisés par des métadonnées spécifiques.
En résumé, le schéma d'enregistrement proto est une combinaison des éléments suivants :
- Schéma d'archétype
- Schéma de type
Familles d'archétypes
Chaque famille d'archétypes contient deux types d'archétypes :
- Standard
- En cluster
MDE v1.3 introduit le concept d'archétypes groupés, qui étendent la fonctionnalité des archétypes standards. Les archétypes regroupés fournissent quatre champs génériques qui peuvent être renseignés avec des valeurs dans l'analyseur. Chaque récepteur de données utilise ces quatre champs pour fournir des fonctionnalités supplémentaires d'accès aux requêtes et d'accès aux données :
- BigQuery : les tables de type "en cluster" dans BigQuery sont mises en cluster par les quatre champs génériques dans l'ordre. Cela vous permet de filtrer efficacement les données dans BigQuery sur les champs en cluster.
- API Bigtable Federation : l'API Federation utilise les champs regroupés pour construire des clés de ligne dans Bigtable, ce qui permet de nouveaux schémas d'accès aux données.
- Pub/Sub : les messages Pub/Sub transmettent les champs en tant que champs de premier niveau dans le message Pub/Sub.
Famille d'archétypes numériques
La famille d'archétypes numériques est conçue pour servir de base aux types qui modélisent une série de messages numériques horodatés, par exemple un capteur de température émettant un flux de lectures.
Les versions standard et groupée de l'archétype définissent les schémas d'enregistrement de base suivants :
Standard
| Champ | Type de données | Obligatoire |
|---|---|---|
tagName |
Chaîne | Oui |
value |
Numérique | Oui |
eventTimestamp |
Nombre entier (au format millisecondes depuis l'epoch) | Oui |
En cluster
| Champ | Type de données | Obligatoire |
|---|---|---|
tagName |
Chaîne | Oui |
value |
Numérique | Oui |
eventTimestamp |
Nombre entier (au format millisecondes depuis l'epoch) | Oui |
clustered_column_1 |
Chaîne | Non |
clustered_column_2 |
Chaîne | Non |
clustered_column_3 |
Chaîne | Non |
clustered_column_4 |
Chaîne | Non |
Famille d'archétypes discrets
La famille d'archétypes discrets est conçue pour servir de base aux types qui modélisent des événements horodatés, par exemple un changement de paramètre piloté par un opérateur dans une machine ou un processus spécifique.
Les versions standard et groupée de l'archétype définissent les schémas d'enregistrement de base suivants :
Standard
| Champ | Type de données | Obligatoire |
|---|---|---|
tagName |
Chaîne | Oui |
data |
Objet JSON | Oui |
eventTimestamp |
Nombre entier (au format millisecondes depuis l'epoch) | Oui |
En cluster
| Champ | Type de données | Obligatoire |
|---|---|---|
tagName |
Chaîne | Oui |
data |
Objet JSON | Oui |
eventTimestamp |
Nombre entier (au format millisecondes depuis l'epoch) | Oui |
clustered_column_1 |
Chaîne | Non |
clustered_column_2 |
Chaîne | Non |
clustered_column_3 |
Chaîne | Non |
clustered_column_4 |
Chaîne | Non |
Famille d'archétypes continus
La famille d'archétypes continus est conçue pour servir de base aux types qui modélisent des séries d'états consécutifs définis par un code temporel de début et de fin (par exemple, l'état de fonctionnement d'une machine pendant une période continue).
Les versions standard et groupée de l'archétype définissent les schémas d'enregistrement de base suivants :
Standard
| Champ | Type de données | Obligatoire |
|---|---|---|
tagName |
Chaîne | Oui |
data |
Objet JSON | Oui |
eventTimestampStart |
Nombre entier (au format millisecondes depuis l'epoch) | Oui |
eventTimestampEnd |
Nombre entier (au format millisecondes depuis l'epoch) | Oui |
En cluster
| Champ | Type de données | Obligatoire |
|---|---|---|
tagName |
Chaîne | Oui |
data |
Objet JSON | Oui |
eventTimestampStart |
Nombre entier (au format millisecondes depuis l'epoch) | Oui |
eventTimestampEnd |
Nombre entier (au format millisecondes depuis l'epoch) | Oui |
clustered_column_1 |
Chaîne | Non |
clustered_column_2 |
Chaîne | Non |
clustered_column_3 |
Chaîne | Non |
clustered_column_4 |
Chaîne | Non |
Champ de données
Les archétypes Série de données discrètes et Série de données continues acceptent un schéma JSON pour le champ data. Si un schéma JSON est défini pour le champ, la valeur du champ data contenu dans un enregistrement émis par un analyseur est validée par rapport au schéma au moment de l'exécution. Par exemple, imaginez que vous définissiez le schéma suivant pour un type de série temporelle discrète :
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"properties": {
"eventName": {
"type": "string"
}
},
"required": ["eventName"]
}
Avec le schéma précédent pour un type de série temporelle discrète, l'enregistrement (partiel) de ce type émis par un analyseur n'est pas valide :
{
"data": {
"complex": {
"machineName": "example"
}
}
}
Si la validation des données échoue, les enregistrements sont déplacés vers la file d'attente de lettres mortes. Les enregistrements de la file d'attente de lettres mortes peuvent être traités manuellement ultérieurement.
Buckets de métadonnées
Les types peuvent faire référence à des buckets de métadonnées. Une référence de bucket de métadonnées sur un type définit si les enregistrements peuvent ou doivent (selon la valeur de l'attribut required) fournir une référence à une instance de bucket de métadonnées.
Les références aux buckets de métadonnées d'un type définissent le contrat de métadonnées pour les enregistrements de ce type. Par exemple, vous pouvez définir que tous les enregistrements d'un type doivent être contextualisés avec des métadonnées d'appareil (fournir une référence à une instance de métadonnées dans un bucket de métadonnées appelé device).
Si un bucket de métadonnées est associé à un type et que l'indicateur required est défini sur true, les enregistrements de ce type émis par un analyseur qui ne fournissent pas de référence à une instance de bucket de métadonnées sont déplacés vers la file d'attente des messages non distribués. Pour en savoir plus, consultez Reprocesser des messages.
Gestion des versions de type
Il existe différents types de gestion des versions. Les sections suivantes décrivent chacun d'eux.
Création d'une version de type
Vous pouvez créer des versions pour un type spécifique. Chaque nouvelle version peut spécifier des associations de buckets de métadonnées supplémentaires ou modifier le schéma du champ de données. Toutefois, pour assurer la cohérence des données tout au long du cycle de vie d'un type, les nouvelles versions de type ne peuvent évoluer que vers l'avant et doivent respecter les règles de gestion des versions. Les nouvelles versions d'un type peuvent apporter les modifications suivantes :
Mai :
- Ajoutez de nouveaux champs facultatifs au schéma de données.
- Marquez un champ obligatoire comme facultatif dans le schéma de données.
- Ajoutez de nouvelles références de bucket de métadonnées.
Vous n'êtes pas autorisé à :
- Supprimez des champs du schéma de données.
- Modifiez le type de données des champs existants dans le schéma de données.
- Marquez un attribut facultatif comme obligatoire dans le schéma de données.
- Supprimez les références au bucket de métadonnées.
Modifier une version de type existante
Les spécifications de stockage et les transformations peuvent être mises à jour sur une version de type existante sans qu'il soit nécessaire de créer une nouvelle version de type.
Modifier le type
La plupart des opérations sur les types nécessitent de créer une version de type ou d'en modifier une. La seule opération qui peut être effectuée sur un type indépendamment de sa version est l'activation ou la désactivation. Lorsqu'un type est désactivé, toutes les versions de ce type cessent d'accepter les données.
Restrictions de dénomination pour les types
Un nom de type peut contenir les éléments suivants :
- Lettres (majuscules et minuscules), chiffres et caractères spéciaux
-et_. - Il peut comporter jusqu'à 255 caractères.
Vous pouvez utiliser l'expression régulière suivante pour la validation : ^[a-z][a-z0-9\\-_]{1,255}$.
Si vous essayez de créer une entité qui ne respecte pas les restrictions d'attribution de noms, vous recevrez un message 400 error.