
Typ
Mit der Manufacturing Data Engine (MDE) können Sie eine Klasse von Quellnachrichten durch Parsing in Datensätze eines bestimmten Typs umwandeln.
Typen sind Konfigurationseinheiten, die das Ziel des Parsingvorgangs darstellen. Sie beschreiben eine Reihe von strukturell und semantisch ähnlichen Datensätzen mit einem gemeinsamen Granularitätsgrad, die optional einen bestimmten Metadatenkontext gemeinsam nutzen.
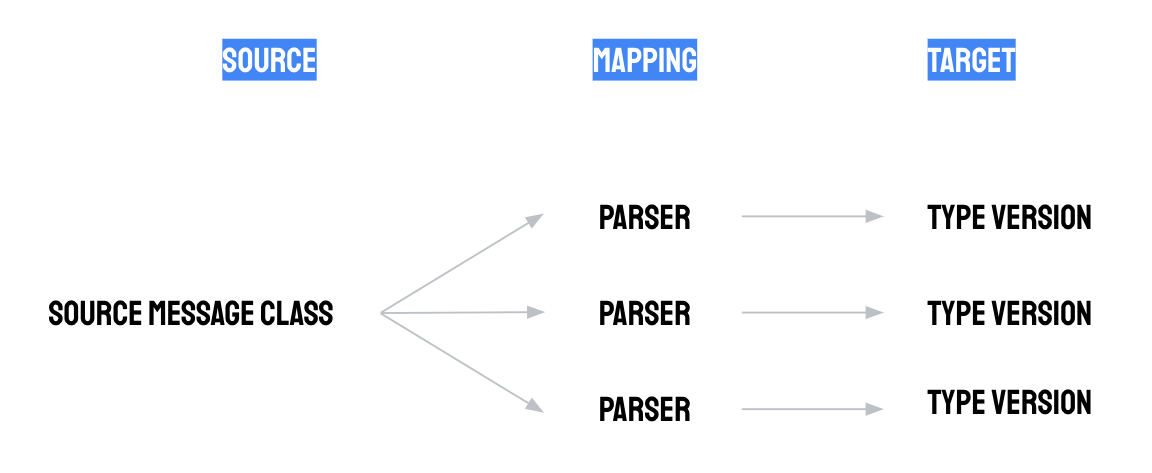
Sie können beispielsweise die Typen „Maschinenzustand“ und „Vibrationsmesswerte“ erstellen. Der erste Typ kann verwendet werden, um Ereignisse für Änderungen des Maschinenstatus zu modellieren, z. B. „Wird ausgeführt“, „Inaktiv“, „Geplante Wartung“ und „Nicht geplante Wartung“. Der zweite Typ kann verwendet werden, um einen Stream numerischer Messwerte des Vibrationssensors zu modellieren.
MDE wird mit einer Reihe von Standardtypen ausgeliefert, Sie können aber auch neue erstellen. Typen werden durch die folgenden Merkmale definiert:
- Name: Der Name des Typs.
- Archetyp: Der Name des Archetyps, auf dem ein Typ basiert. Ein Typ in MDE ist immer genau einem Archetyp zugeordnet.
- Speicherspezifikationen: Eine Liste der Einstellungen pro Datensenke. Mit Speicherspezifikationen können Sie konfigurieren, ob Datensätze in eine Datensenke geschrieben werden, und weitere senkenspezifische Einstellungen angeben.
- Optionale Konfigurationsparameter, darunter:
- Das JSON-Schema des Felds data (gilt nur für Typen von diskreten und kontinuierlichen Archetypen).
- Zuweisungen von Metadaten-Buckets: Eine Liste von Metadaten-Buckets, für die Datensätze des Typs Instanzreferenzen enthalten müssen.
Typen und Datensenken
Der Stream von Datensätzen eines bestimmten Typs wird von Datensenken verarbeitet, die für einen Typ aktiviert sind. Datensenken können für Typen aktiviert (aktiviert oder deaktiviert) werden. So können die Datensätze eines Typs beispielsweise so konfiguriert werden, dass sie in BigQuery, aber nicht in Cloud Storage geschrieben werden.
Unterstützte Datensenken
MDE unterstützt die folgenden Datensenken:
- BigQuery
- Bigtable/Federation API
- Cloud Storage
- Pub/Sub (JSON und Protobuf)
BigQuery-Datensenke
Wenn ein neuer Typ erstellt wird, wird von MDE automatisch eine entsprechende Typentabelle in BigQuery im Dataset mde_data erstellt.
Die Datensätze der einzelnen Typen werden in die entsprechende Typentabelle geschrieben.
Cloud Storage-Datensenke
Datensätze werden in einem Cloud Storage-Bucket namens <project_id>-gcs-ingestion in AVRO-Dateien mit Hive-Partitionierung in einem 10-Minuten-Fenster und 10 Partitionen pro Fenster gespeichert. Einträge werden nach Typ in Ordnern gruppiert.
Pub/Sub-Datensenke
Die Pub/Sub-Senke veröffentlicht Datensätze in einem dedizierten Thema. Das Pub/Sub-Nachrichtenschema wird im Pub/Sub-Senken-Nachrichtenschema beschrieben.
Materialisierung von Metadaten
Jede Datensenke für einen Typ kann so konfiguriert werden, dass Metadaten in Datensätzen materialisiert werden. Wenn diese Einstellung aktiviert ist, werden Metadateninstanzreferenzen in Metadateninstanzobjekte aufgelöst und die Objekte sind in den Datensätzen enthalten. Die genaue Art und Weise, wie Metadaten gespeichert oder ausgegeben werden, hängt vom Datensenken ab.
In BigQuery werden materialisierte Metadaten beispielsweise mit dem folgenden Schema in die Tabelle materialized_metadata_field geschrieben:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"additionalProperties": {
"type": "object",
"description": "Metadata instance"
}
}
Archetypen
Archetypen stellen eine Oberklasse von Typen dar. Jeder Archetyp ist so konzipiert, dass er ein optimales Verarbeitungs- und Speichermodell für Datensätze bietet. Archetypen definieren die obligatorischen Kernfelder, die in einem Datensatz eines bestimmten Typs vorhanden sein müssen, der von einem Parser ausgegeben wird. MDE wird mit sechs systemdefinierten Standard- und gruppierten Archetypen ausgeliefert, die in drei Archetypfamilien gruppiert sind:
- Numerische Datenreihen (NDS)
- Diskrete Datenreihen (DDS)
- Kontinuierliche Datenreihen (Continuous Data Series, CDS)
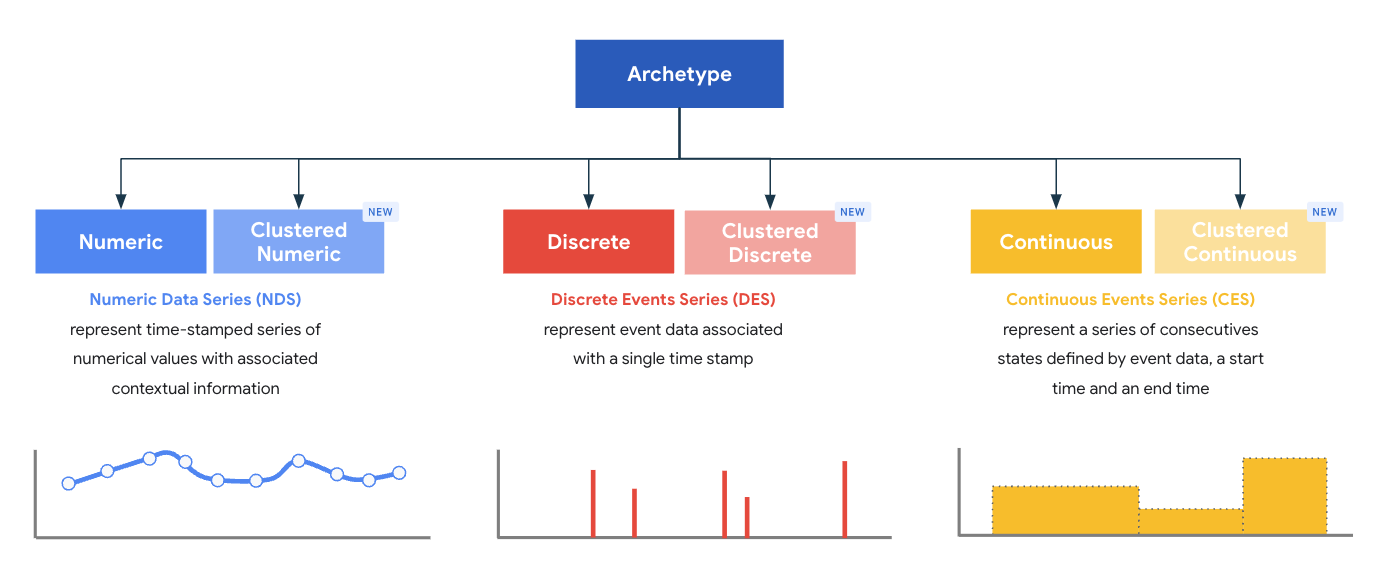
Ein Typ in MDE ist immer genau einem Archetyp zugeordnet und der Archetyp eines Typs wird bei der Erstellung definiert.
Sie können Typen verwenden, um über die durch Archetypen auferlegten Einschränkungen hinaus weitere Einschränkungen für Proto-Datensätze zu definieren, die von Parsern ausgegeben werden. Sie können beispielsweise die Form des Felds data für einen Typ angeben oder definieren, dass Datensätze eines Typs durch bestimmte Metadaten kontextualisiert werden müssen.
Zusammenfassend lässt sich sagen, dass das Proto-Datensatzschema eine Kombination aus Folgendem ist:
- Archetypschema
- Typschema
Archetypfamilien
Jede Archetypfamilie enthält zwei Arten von Archetypen:
- Standard
- Geclustert
Mit MDE v1.3 wird das Konzept der clustered archetypes eingeführt, die die Funktionalität der Standard-Archetypen erweitern. Für geclusterte Archetypen stehen vier generische Felder zur Verfügung, die mit Werten im Parser gefüllt werden können. Jede Datensenke verwendet diese vier Felder, um zusätzliche Abfrage- und Datenzugriffsfunktionen bereitzustellen:
- BigQuery: Tabellen vom Typ „Geclustert“ in BigQuery werden in der folgenden Reihenfolge nach den vier generischen Feldern geclustert: So können Sie Daten in BigQuery effizient nach den geclusterten Feldern filtern.
- Bigtable Federation API: Die Federation API hat die gruppierten Felder verwendet, um Zeilenschlüssel in Bigtable zu erstellen und so neue Datenzugriffsmuster zu ermöglichen.
- Pub/Sub: Pub/Sub-Nachrichten übergeben die Felder als Felder der ersten Ebene in der Pub/Sub-Nachricht.
Numerische Archetyp-Familie
Die numerische Archetyp-Familie dient als Grundlage für Typen, die eine Reihe von zeitgestempelten numerischen Nachrichten modellieren, z. B. ein Temperatursensor, der einen Stream von Messwerten ausgibt.
In der Standard- und der Clusterversion des Archetyps werden die folgenden Basisschemas für Datensätze definiert:
Standard
| Feld | Datentyp | Erforderlich |
|---|---|---|
tagName |
String | Ja |
value |
Numerisch | Ja |
eventTimestamp |
Ganzzahl (als Epochen-Millisekunden formatiert) | Ja |
Geclustert
| Feld | Datentyp | Erforderlich |
|---|---|---|
tagName |
String | Ja |
value |
Numerisch | Ja |
eventTimestamp |
Ganzzahl (als Epochen-Millisekunden formatiert) | Ja |
clustered_column_1 |
String | Nein |
clustered_column_2 |
String | Nein |
clustered_column_3 |
String | Nein |
clustered_column_4 |
String | Nein |
Diskrete Archetyp-Familie
Die Archetyp-Familie „Diskret“ dient als Grundlage für Typen, die Zeitstempel-Ereignisse modellieren, z. B. eine vom Bediener vorgenommene Parameteränderung in einer bestimmten Maschine oder einem bestimmten Prozess.
In der Standard- und der Clusterversion des Archetyps werden die folgenden Basisschemas für Datensätze definiert:
Standard
| Feld | Datentyp | Erforderlich |
|---|---|---|
tagName |
String | Ja |
data |
JSON-Objekt | Ja |
eventTimestamp |
Ganzzahl (als Epochen-Millisekunden formatiert) | Ja |
Geclustert
| Feld | Datentyp | Erforderlich |
|---|---|---|
tagName |
String | Ja |
data |
JSON-Objekt | Ja |
eventTimestamp |
Ganzzahl (als Epochen-Millisekunden formatiert) | Ja |
clustered_column_1 |
String | Nein |
clustered_column_2 |
String | Nein |
clustered_column_3 |
String | Nein |
clustered_column_4 |
String | Nein |
Kontinuierliche Archetypfamilie
Die Archetyp-Familie „continuous“ dient als Grundlage für Typen, die Reihen von aufeinanderfolgenden Zuständen modellieren, die durch einen Start- und Endzeitstempel definiert werden, z. B. den Betriebsstatus einer Maschine für einen kontinuierlichen Zeitraum.
In der Standard- und der Clusterversion des Archetyps werden die folgenden Basisschemas für Datensätze definiert:
Standard
| Feld | Datentyp | Erforderlich |
|---|---|---|
tagName |
String | Ja |
data |
JSON-Objekt | Ja |
eventTimestampStart |
Ganzzahl (als Epochen-Millisekunden formatiert) | Ja |
eventTimestampEnd |
Ganzzahl (als Epochen-Millisekunden formatiert) | Ja |
Geclustert
| Feld | Datentyp | Erforderlich |
|---|---|---|
tagName |
String | Ja |
data |
JSON-Objekt | Ja |
eventTimestampStart |
Ganzzahl (als Epochen-Millisekunden formatiert) | Ja |
eventTimestampEnd |
Ganzzahl (als Epochen-Millisekunden formatiert) | Ja |
clustered_column_1 |
String | Nein |
clustered_column_2 |
String | Nein |
clustered_column_3 |
String | Nein |
clustered_column_4 |
String | Nein |
Datenfeld
Die Archetypen diskrete Datenreihe und kontinuierliche Datenreihe akzeptieren ein JSON-Schema für das Feld data. Wenn ein JSON-Schema für das Feld definiert ist, wird der Wert des Felds data, das in einem von einem Parser ausgegebenen Datensatz enthalten ist, zur Laufzeit anhand des Schemas validiert. Angenommen, Sie definieren das folgende Schema für einen diskreten Zeitachsentyp:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"properties": {
"eventName": {
"type": "string"
}
},
"required": ["eventName"]
}
Mit dem vorherigen Schema für einen diskreten Zeitreihentyp ist der folgende (Teil-)Datensatz dieses Typs, der von einem Parser ausgegeben wird, ungültig:
{
"data": {
"complex": {
"machineName": "example"
}
}
}
Wenn die Datenvalidierung fehlschlägt, werden Datensätze in die Warteschlange für unzustellbare Nachrichten verschoben. Einträge in der Dead-Letter-Warteschlange können später manuell verarbeitet werden.
Metadaten-Buckets
Typen können auf Metadaten-Buckets verweisen. Eine Metadaten-Bucket-Referenz für einen Typ definiert, ob Datensätze eine Referenz zu einer Metadaten-Bucket-Instanz enthalten dürfen oder müssen (abhängig vom Wert des Attributs required).
Metadaten-Bucket-Verweise für einen Typ definieren den Metadatenvertrag für Datensätze dieses Typs. Sie können beispielsweise festlegen, dass alle Datensätze eines Typs mit Gerätemetadaten kontextualisiert werden müssen. Dazu müssen Sie in einem Metadaten-Bucket namens device einen Verweis auf eine Metadateninstanz angeben.
Wenn einem Typ ein Metadaten-Bucket zugeordnet ist und das Flag required auf true gesetzt ist, werden Datensätze dieses Typs, die von einem Parser ausgegeben werden und keinen Verweis auf eine Metadaten-Bucket-Instanz enthalten, in die Dead-Letter-Warteschlange verschoben. Weitere Informationen finden Sie unter Nachrichten noch einmal verarbeiten.
Versionsverwaltung für Typen
Es gibt verschiedene Versionsverwaltungstypen, die in den folgenden Abschnitten beschrieben werden.
Neue Typversion erstellen
Sie können neue Versionen für einen bestimmten Typ erstellen. In jeder neuen Version können zusätzliche Metadaten-Bucket-Zuordnungen angegeben oder das Schema des Datenfelds geändert werden. Um die Datenkonsistenz über den gesamten Lebenszyklus eines Typs hinweg zu gewährleisten, dürfen sich neue Typversionen jedoch nur weiterentwickeln und müssen den Versionsverwaltungsregeln entsprechen. Bei neuen Versionen eines Typs können folgende Änderungen vorgenommen werden:
Mai:
- Fügen Sie dem Datenschema neue optionale Felder hinzu.
- Ein Pflichtfeld im Datenschema als optional markieren
- Fügen Sie neue Metadaten-Bucket-Referenzen hinzu.
Nicht erlaubt:
- Felder aus dem Datenschema entfernen
- Datentyp vorhandener Felder im Datenschema ändern.
- Markieren Sie ein optionales Attribut im Datenschema als erforderlich.
- Entfernen Sie Verweise auf Metadaten-Buckets.
Vorhandene Typversion bearbeiten
Speicherspezifikationen und Transformationen können für eine vorhandene Typversion aktualisiert werden, ohne dass eine neue Typversion erstellt werden muss.
Typ bearbeiten
Für die meisten Vorgänge für Typen ist es erforderlich, entweder eine neue Typversion zu erstellen oder eine vorhandene Typversion zu bearbeiten. Die einzige Operation, die unabhängig von der Version für einen Typ ausgeführt werden kann, ist das Aktivieren oder Deaktivieren. Wenn ein Typ deaktiviert ist, werden für alle Versionen dieses Typs keine Daten mehr akzeptiert.
Namensbeschränkungen für Typen
Ein Typname kann Folgendes enthalten:
- Buchstaben (Groß- und Kleinbuchstaben), Ziffern und die Sonderzeichen
-und_. - Kann bis zu 255 Zeichen lang sein.
Sie können den folgenden regulären Ausdruck für die Validierung verwenden: ^[a-z][a-z0-9\\-_]{1,255}$.
Wenn Sie versuchen, eine Entität zu erstellen, die gegen die Namensbeschränkungen verstößt, erhalten Sie eine 400 error.