
Parser
Parser sind Konfigurationseinheiten, die definieren, wie Nachrichten aus einer bestimmten Quellnachrichtenklasse geparst und in Datensätze eines bestimmten Zieltyps umgewandelt werden.
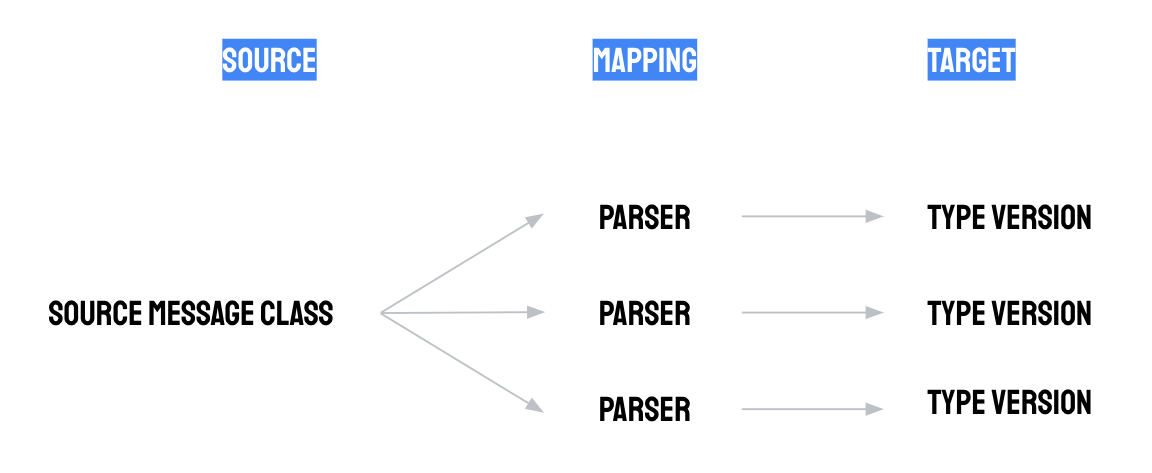
Eine Parserkonfiguration hat die folgenden drei Komponenten:
- Zuordnung von Quellnachrichtenkassen: Ein Parser verarbeitet Quellnachrichten aus einer einzelnen Quellnachrichtenkasse. Weitere Informationen finden Sie unter Quellnachrichtenklassen.
- Zuordnung von Typversionen: Ein Parser gibt Proto-Datensätze einer einzelnen Typversion aus. Die Typversionskonfiguration definiert, welche Felder im ausgegebenen Proto-Datensatz vorhanden sein müssen, und legt ihre Struktur (Schema) fest. Weitere Informationen finden Sie unter Typ.
- Whistle-Script: Whistle-Scripts definieren, wie Quellnachrichten mithilfe von Zuordnungs-, Parsing- und Transformationslogik in Proto-Datensätze transformiert werden. Whistle-Scripts werden von Nutzern geschrieben. Manufacturing Data Engine (MDE) bietet jedoch Konfigurationspakete für typische Anwendungsfälle. Weitere Informationen finden Sie im folgenden Abschnitt.
Definition von „Pfeifen“
Whistle ist eine Zuordnungssprache, mit der komplexe verschachtelte Daten von einem Schema in ein anderes konvertiert werden können. In der Fertigung können Datenmodelle komplex sein und viele verschachtelte und wiederholte Strukturen enthalten. Das macht es schwierig, die Zuordnungslogik in einem prozeduralen Format auszudrücken. Whistle löst dieses Problem, indem es eine deklarative Sprache bietet, mit der Sie Zuordnungs- und Transformationslogik auf natürliche Weise definieren können.
Mit Whistle können Sie beispielsweise mehrere Sensordatenmodelle aus verschiedenen Fabriken in einem einheitlichen MDE-Typmodell harmonisieren. Die Quelldaten können verschachtelte Strukturen enthalten, z. B. eine Liste von Komponenten oder eine Hierarchie von Features. Mit Whistle können Sie die Zuordnungslogik für diese verschachtelten Strukturen auf natürliche Weise ausdrücken, ohne prozeduralen Code schreiben zu müssen.
Whistle unterstützt auch Funktionen, mit denen Sie komplexe Zuordnungen mit wiederholten Strukturen in Funktionen aufteilen können. So lässt sich Ihr Mapping-Code leichter verstehen und verwalten und es ist einfacher, Code wiederzuverwenden.
Whistle bietet Vorteile gegenüber prozeduralen Ansätzen. Sehen Sie sich folgendes Beispiel an:
Angenommen, es liegt diese Beispielnutzlast vor:
{
"payload": {
"tag": "vibration-sensor"
},
"details": {
"value": 0.24,
"timestamp": "2023-06-26 12:19:20.046000 UTC"
}
}
Und das folgende Whistle-Skript:
package mde
[{
tagName: $root.payload.tag
timestamps: {
eventTimestamp: $root.details.timestamp
}
data: {
numeric: $root.details.value
}
}]
Wenn das vorherige Whistle-Skript angewendet wird, erzeugt der Parser einen Proto-Datensatz wie den folgenden:
[
{
"tagName": "vibration-sensor",
"timestamps": {
"eventTimestamp": "2023-06-26 12:19:20.046000 UTC"
},
"data": {
"value": 0.24
}
}
]
Weitere Informationen zur Whistle-Sprachsyntax und zu den verfügbaren Funktionen finden Sie in der Whistle-Dokumentation.
Laufzeitverhalten von Parsern
Zur Laufzeit empfängt der Parser alle Nachrichten der Quellnachrichtenklasse, mit der er verknüpft ist, wendet das konfigurierte Whistle-Skript auf jede Nachricht an und gibt einen oder mehrere Proto-Datensätze des konfigurierten Typs aus.
Die ausgegebenen Proto-Datensätze müssen der Typkonfiguration entsprechen. Wenn sie nicht eingehalten werden, werden die Nachrichten in die Dead-Letter-Warteschlange verschoben.
Assoziationsregeln
Ein Parser kann nur einer einzelnen Nachrichtenklasse und einer einzelnen Typversion zugeordnet werden. Ein Parser kann jedoch einen oder mehrere Datensätze ausgeben, sofern sie dem Typ der Version entsprechen, mit der der Parser verknüpft ist. Die Ausgabe eines Parsers ist ein Array von Proto-Datensatzobjekten.
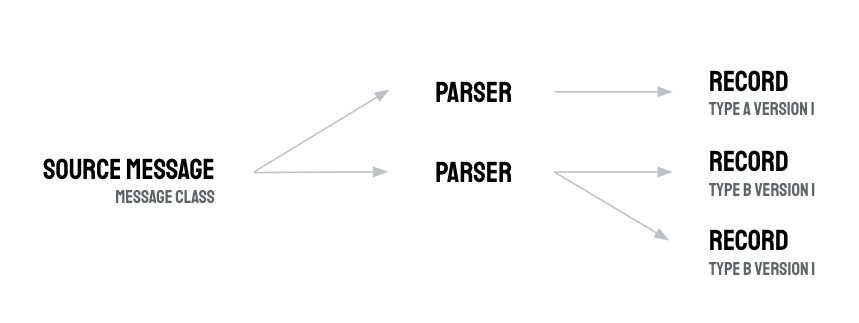
Mehr als einen Datensatz aus einem Parser auszugeben, ist in Szenarien nützlich, in denen eine Quellnachricht ein Array von Messwerten oder Ereignissen enthält, die Sie aufschlüsseln möchten. Mit Parsern können Sie die Quellnachricht in mehrere Proto-Datensätze aufteilen, sodass beispielsweise jeder Messwert zu einer Zeile in einer Datensatz-Tabelle in BigQuery wird.
Die ausgegebenen Proto-Datensätze können auf einen beliebigen Tag-Namen verweisen. Dieses Verhalten ist eine Änderung gegenüber v1.1 und v1.2, in denen Tagnamen auf den Typ beschränkt waren. Nach v1.3 können MDE-Proto-Datensätze, die von einem Parser ausgegeben werden,
Schema für Proto-Datensätze
Das JSON-Schema, dem die Proto-Datensätze entsprechen müssen, hängt von Folgendem ab:
- Archetype (Archetyp): Der spezifische Archetyp, der mit dem Typ verknüpft ist.
- Type Configuration (Typkonfiguration): Die für den Typ definierten Konfigurationseinstellungen.
Das Archetyp definiert das Basisschema für Datensätze. Für einen Typ in der Archetyp-Familie discrete ist beispielsweise erforderlich, dass Proto-Datensätze Werte für die folgenden Attribute enthalten:
tagNametimestamps.eventTimestampdata.complex
Der Typ kann weitere Einschränkungen für die Proto-Datensätze mit sich bringen. Sie können beispielsweise ein Schema für das Feld data definieren oder festlegen, dass in Proto-Datensätzen ein Verweis auf eine Metadateninstanz enthalten sein muss.
Weitere Informationen finden Sie in der Referenz zu Proto-Datensätzen.
Referenzdatensuche
MDE bietet eine benutzerdefinierte Whistle-Funktion, mit der ein Wert für einen angegebenen Schlüssel aus einem Lookup-Bucket abgerufen werden kann.
Sie können eine Bucket-Instanz anhand ihres natürlichen Schlüssels suchen, indem Sie die Funktion mde::lookupByKey in einem Whistle-Script aufrufen. Die Funktion verwendet die bucketName-, bucketVersion- und naturalKey-Werte der Instanz als Argumente und gibt die letzte Metadateninstanz für den angegebenen natürlichen Schlüssel zurück. Sie können die Instanz verwenden, um Felder in einem Proto-Datensatz im Parser zu füllen. Beispiel:
"data" : {
"complex" : {
"VIN" : mde::lookupByKey("vin-lookup-bucket", input.vinKey, 1).VIN,
"vin_registration_time" : mde::lookupByKey("vin-lookup-bucket", input.vinKey, 1).vin_registration_time,
"ResultValue" : 163.0482614,
}
}
Namensbeschränkungen für Parser
Ein Parsername kann Folgendes enthalten:
- Buchstaben (Groß- und Kleinbuchstaben), Ziffern und die Sonderzeichen
-und_. - Kann bis zu 255 Zeichen lang sein.
Sie können den folgenden regulären Ausdruck für die Validierung verwenden: ^[a-z][a-z0-9\\-_]{1,255}$.
Wenn Sie versuchen, eine Entität zu erstellen, die gegen die Namensbeschränkungen verstößt, erhalten Sie eine 400 error.
Mit der Funktion mde::sanitizeTagName() können Sie dafür sorgen, dass Ihr Name den Namensbeschränkungen entspricht. Weitere Informationen finden Sie unter Whistle-MDE-Funktionen.