
Esta página descreve a comparação de execução dupla em lote, que foi projetada para ajudar você a comparar as saídas de cargas de trabalho em lote. Com esse recurso, é possível garantir que os jobs em lote executados no mainframe e no Google Cloud gerem saídas idênticas para as mesmas entradas.
Como as comparações em lote funcionam
Com o recurso de comparação em lote da execução dupla, é possível analisar arquivos primeiro configurando as opções de comparação, depois definindo os gatilhos para iniciar o processo e, por fim, revisando os resultados.
Saiba como a comparação de abtch funciona nas seções a seguir.
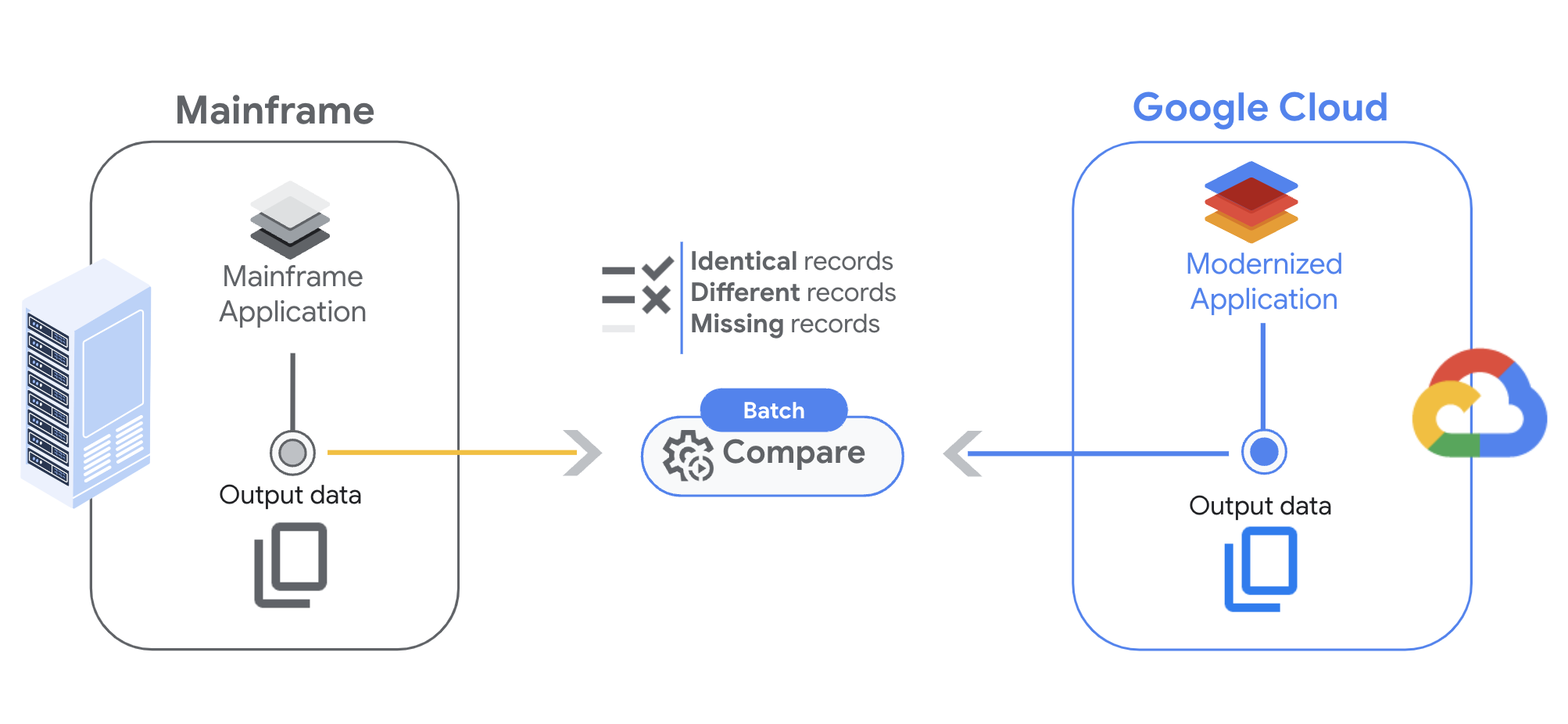
Transferência de arquivos do mainframe
Antes de executar uma comparação de arquivos, a primeira etapa é transferir os arquivos do mainframe para um bucket do Cloud Storage em Google Cloud.
É possível transferir arquivos do mainframe de duas maneiras:
- com transferências FTP/HTTPS
- com o Mainframe Connector.
Em ambos os casos, o Dual Run pode ler formatos EBCDIC e é compatível com a saída UNLOAD sem a necessidade de transformação adicional.
Configuração de comparação
A execução dupla oferece flexibilidade total na hora de comparar seus arquivos de mainframe e modernizados. Para cada arquivo, especifique quais campos comparar e os formatos esperados.
A comparação de arquivos de execução dupla oferece suporte a opções configuráveis avançadas, como ofuscação de dados, configurações de tolerância, fusão de campos, rótulos personalizados e filtragem para uma análise de arquivos precisa e flexível.
- Ofusque campos específicos ao fazer a comparação de arquivos. Isso é útil para ocultar dados sensíveis que não devem aparecer nos relatórios ou painéis como conteúdo claramente visível.
- Permita tolerância ao comparar valores numéricos de campos específicos. Isso é útil ao comparar números de ponto flutuante originados de sistemas diferentes.
- Permitir tolerância ao comparar valores de carimbo de data/hora de campos específicos. Isso é útil ao comparar carimbos de data/hora originados de sistemas diferentes.
- Mesclar vários campos com uma string de junção opcional e tratá-los como um único campo durante a comparação.
- Configure rótulos personalizados para categorizar seus jobs de comparação. Os rótulos são pares de chave-valor que podem ser usados para marcar seus jobs de comparação e diferenciá-los entre diferentes objetivos funcionais ou de negócios.
- Ignorar espaços em branco à esquerda e à direita em campos específicos.
- Ignorar maiúsculas e minúsculas em strings.
- Aplique filtros para ignorar registros durante a comparação, permitindo que vários filtros sejam aplicados ao mesmo tempo.
Geração automatizada de configuração
O Dual Run oferece ferramentas automatizadas para ajudar a configurar a comparação de arquivos. Essas ferramentas criam os arquivos de configuração necessários com base nos copybooks do mainframe ou em arquivos JSON e CSV de amostra que você fornece.
Comparar resultados
Ao comparar dois arquivos, a execução dupla retorna três resultados possíveis:
- Correspondência exata:o registro está presente nos dois arquivos, e o conteúdo dos campos corresponde às restrições especificadas.
- Correspondência parcial:o registro está presente nos dois arquivos, mas alguns dos campos não correspondem. Você pode verificar as diferenças na saída dos resultados.
- Registro ausente:o registro está presente apenas nos arquivos reais ou esperados.
Em caso de incompatibilidade entre os arquivos comparados, é possível configurar a execução dupla para mostrar todos os registros comparados nos arquivos, e não apenas os registros incompatíveis, para facilitar a solução de problemas.
A execução dupla oferece um recurso chamado comparações adiadas para lidar com situações em que os dados podem estar temporariamente ausentes. Isso é especialmente útil para comparações iterativas, como as realizadas em snapshots diários do banco de dados. Se um campo estiver ausente em uma iteração, mas aparecer na próxima, a execução dupla vai armazená-lo e compará-lo mais tarde, garantindo que não haja discrepâncias nos dados. Isso oferece um processo de comparação mais robusto e preciso, especialmente para conjuntos de dados dinâmicos.
Arquivos compatíveis
A execução dupla é compatível com os seguintes arquivos para comparação:
- Arquivos sequenciais de bloco fixo do z/OS
- Arquivos de matriz JSON
- Arquivos JSON Lines (JSONL)
- Arquivos CSV
Tipos de dados do z/OS compatíveis
O Dual Run é compatível com os seguintes tipos de dados z/OS, em EBCDIC e ASCII:
- COMP1
- COMP2
- PACKED_DECIMAL
- COMP4
- COMP5
- ZONED_DECIMAL
- ALPHANUMERIC
Arquivos JSON compatíveis
A execução dupla é compatível com os seguintes formatos JSON:
- JSONL: neste arquivo, cada linha contém um único objeto JSON. Não há quebras de linha no objeto.
- Matriz JSON: neste arquivo, dois tipos de arquivos são compatíveis:
- Uma matriz JSON em que toda a matriz e os elementos estão em uma única linha. Não há quebras de linha neste arquivo.
- Uma matriz JSON com uma nova linha separando os elementos na matriz. Cada objeto JSON também pode conter novas linhas.
Arquivos CSV compatíveis
A execução dupla é compatível com arquivos CSV que seguem o padrão RFC 4180. É possível configurar como o Dual Run analisa o arquivo, incluindo delimitadores, cabeçalhos, caracteres de escape e várias linhas.
A seguir
Saiba mais sobre a comparação on-line.