
Questa pagina descrive il confronto dei file di esecuzione doppia, progettato per aiutarti a confrontare gli output dei carichi di lavoro batch. Con questa funzionalità, puoi assicurarti che i job batch in esecuzione sul mainframe e su Google Cloud generino output identici per gli stessi input.
Come funzionano i confronti dei file
La funzionalità di confronto dei file di esecuzione doppia ti consente di analizzare i file configurando prima le impostazioni di confronto, poi impostando i trigger per avviare il processo e infine esaminando i risultati.
Scopri come funziona il confronto dei file nelle sezioni seguenti.
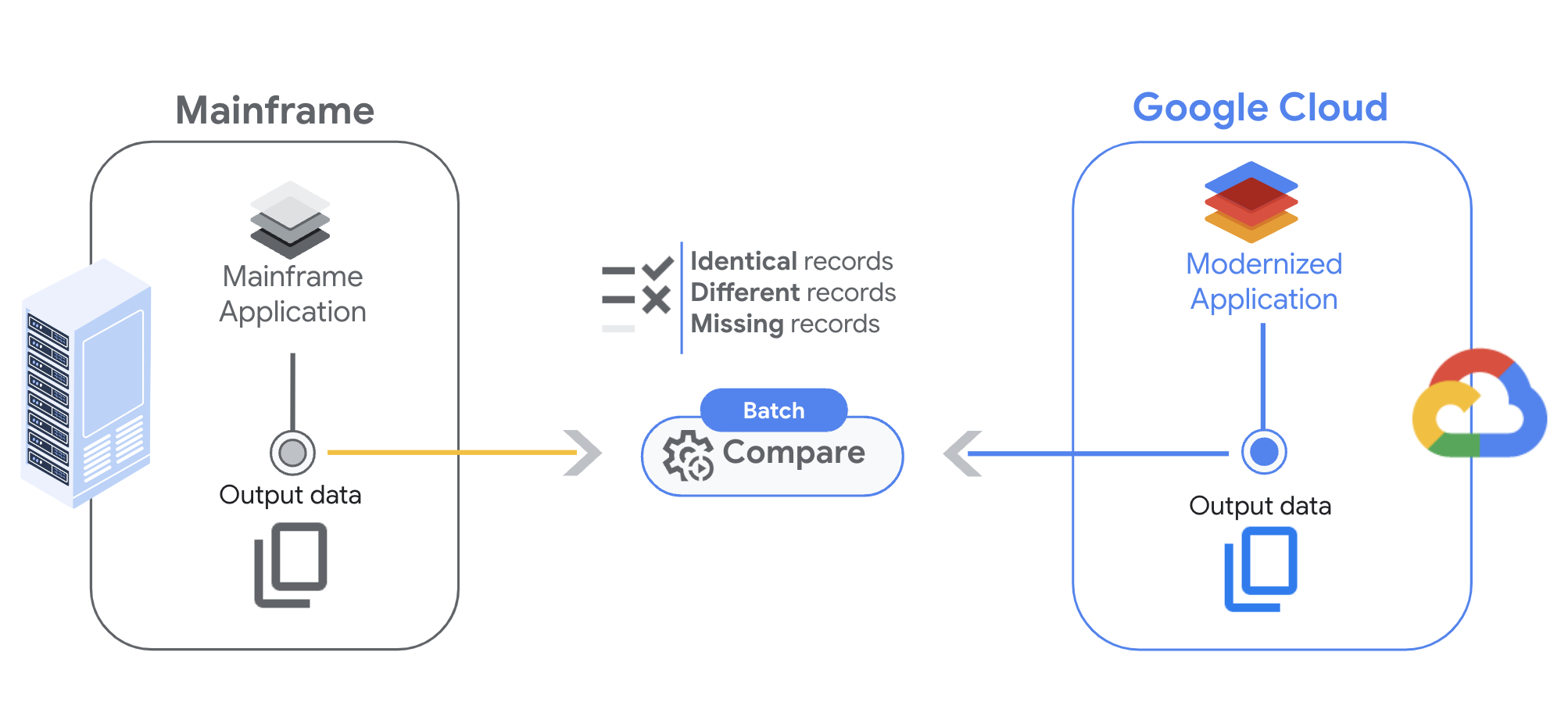
Trasferimento di file dal mainframe
Prima di poter eseguire un confronto dei file, il primo passo è trasferire i file dal mainframe a un bucket Cloud Storage in Google Cloud.
Puoi trasferire i file dal mainframe in due modi:
- Con i trasferimenti FTP/HTTPS
- Con el Mainframe Connector.
In entrambi i casi, l'esecuzione doppia può leggere i formati EBCDIC e supporta l'output UNLOAD senza la necessità di trasformazioni aggiuntive.
Configurazione del confronto
L'esecuzione doppia ti offre la massima flessibilità su come confrontare i file mainframe e modernizzati. Per ogni file, specifichi i campi da confrontare e i formati previsti.
Il confronto dei file di esecuzione doppia supporta opzioni configurabili avanzate, come l'offuscamento dei dati, le impostazioni di tolleranza, l'unione dei campi, le etichette personalizzate e il filtro per un'analisi dei file precisa e flessibile.
- Offusca campi specifici quando esegui il confronto dei file. Questa opzione è utile per nascondere i dati sensibili che non devono essere visualizzati nei report o nelle dashboard come contenuti chiaramente visibili.
- Consenti la tolleranza quando confronti i valori numerici di campi specifici. Questa opzione è utile quando confronti numeri in virgola mobile provenienti da sistemi diversi.
- Consenti la tolleranza quando confronti i valori timestamp di campi specifici. Questa opzione è utile quando confronti timestamp provenienti da sistemi diversi.
- Unisci più campi con una stringa di unione facoltativa e trattali come un singolo campo durante il confronto.
- Configura etichette personalizzate per classificare i job di confronto. Le etichette sono coppie chiave-valore che puoi utilizzare per taggare i job di confronto e differenziarli in base a obiettivi funzionali o aziendali diversi.
- Ignora gli spazi vuoti iniziali e finali in campi specifici.
- Ignora la distinzione tra maiuscole e minuscole nelle stringhe.
- Applica filtri per ignorare i record durante il confronto, consentendo di applicare più filtri contemporaneamente.
Generazione automatica della configurazione
L'esecuzione doppia ti fornisce strumenti automatici per configurare il confronto dei file. Questi strumenti creano i file di configurazione richiesti in base ai copybook del mainframe o ai file JSON e CSV di esempio che fornisci.
Risultati del confronto
Quando confronti due file, l'esecuzione doppia restituisce tre possibili risultati:
- Corrispondenza completa: il record è presente in entrambi i file e il contenuto dei campi corrisponde ai vincoli specificati.
- Corrispondenza parziale: il record è presente in entrambi i file, ma alcuni campi non corrispondono. Puoi controllare le differenze nell'output dei risultati.
- Record mancante: il record è presente solo nei file effettivi o previsti.
In caso di mancata corrispondenza tra i file confrontati, puoi configurare l'esecuzione doppia in modo che mostri tutti i record confrontati all'interno dei file, non solo i record non corrispondenti, per semplificare la risoluzione dei problemi.
L'esecuzione doppia offre una funzionalità chiamata confronti posticipati per risolvere le situazioni in cui i dati potrebbero essere temporaneamente mancanti. Questa opzione è particolarmente utile per i confronti iterativi, come quelli eseguiti sugli snapshot giornalieri del database. Se un campo è assente in un'iterazione ma viene visualizzato in quella successiva, l'esecuzione doppia lo memorizza e lo confronta in un secondo momento, assicurandosi che non vengano create discrepanze nei dati. Questo garantisce un processo di confronto più solido e accurato, soprattutto per i set di dati dinamici.
File supportati
L'esecuzione doppia supporta i seguenti file per il confronto:
- File sequenziali a blocchi fissi z/OS
- File di array JSON
- File JSON Lines (JSONL)
- File CSV
Tipi di dati z/OS supportati
L'esecuzione doppia supporta i seguenti tipi di dati z/OS, sia in EBCDIC che in ASCII:
- COMP1
- COMP2
- PACKED_DECIMAL
- COMP4
- COMP5
- ZONED_DECIMAL
- ALPHANUMERIC
File JSON supportati
L'esecuzione doppia supporta i seguenti formati JSON:
- JSONL: in questo file, ogni riga contiene un singolo oggetto JSON. Non sono presenti nuove righe all'interno dell'oggetto.
- Array JSON: in questo file sono supportati due tipi di file:
- Un array JSON in cui l'intero array e gli elementi si trovano in una singola riga. In questo file non sono presenti nuove righe.
- Un array JSON con una nuova riga che separa gli elementi dell'array. Ogni oggetto JSON può contenere anche nuove righe.
File CSV supportati
L'esecuzione doppia supporta i file CSV conformi allo standard RFC 4180. Puoi configurare la modalità di analisi del file da parte dell'esecuzione doppia, inclusi delimitatori, intestazioni, caratteri di escape e più righe.
Passaggi successivi
Scopri di più sul confronto online.