
Questa pagina descrive i componenti principali di Dual Run. Mentre alcune parti dell'architettura sono condivise tra il confronto batch e online, altre sono specifiche per un carico di lavoro.
Componenti Dual Run
I componenti di Dual Run vengono eseguiti come container in un cluster Google Kubernetes Engine (GKE). Dual Run si basa anche su altri Google Cloud prodotti, come BigQuery, Cloud Storage e altri componenti specializzati per il confronto batch e il confronto online.
I componenti del cluster Dual Run condivisi per i workload online e batch sono i seguenti:
- Config Manager: l'interfaccia utente e i dashboard.
- Env Checker: il motore di verifica dell'installazione.
Config Manager
Config Manager è il frontend dell'applicazione Dual Run. Utilizzi questo componente per gestire le autorizzazioni utente, configurare i carichi di lavoro online tramite gli endpoint e modificare i dashboard. Puoi configurare l'autenticazione degli utenti utilizzando il sistema Identity and Access Management.
Config Manager fornisce anche l'ambiente della dashboard in cui puoi esaminare i risultati del confronto. La dashboard consente di visualizzare un riepilogo dei risultati del confronto in base ai filtri applicati e di esaminare i dettagli dei risultati per ogni singolo record.
La dashboard si basa su Apache Superset, un software open source per la visualizzazione e l'esplorazione dei dati. Ti consente inoltre di creare report e query personalizzati.
Env Checker
Env Checker è il componente di Dual Run che verifica che l'installazione e il deployment di Dual Run siano stati completati correttamente. Verifica che tutti i componenti Dual Run necessari siano configurati e in esecuzione correttamente, altrimenti segnala eventuali errori o configurazioni errate.
Architettura per il confronto batch
Il seguente diagramma mostra l'architettura Dual Run per il confronto batch, come descritto nelle sezioni seguenti.
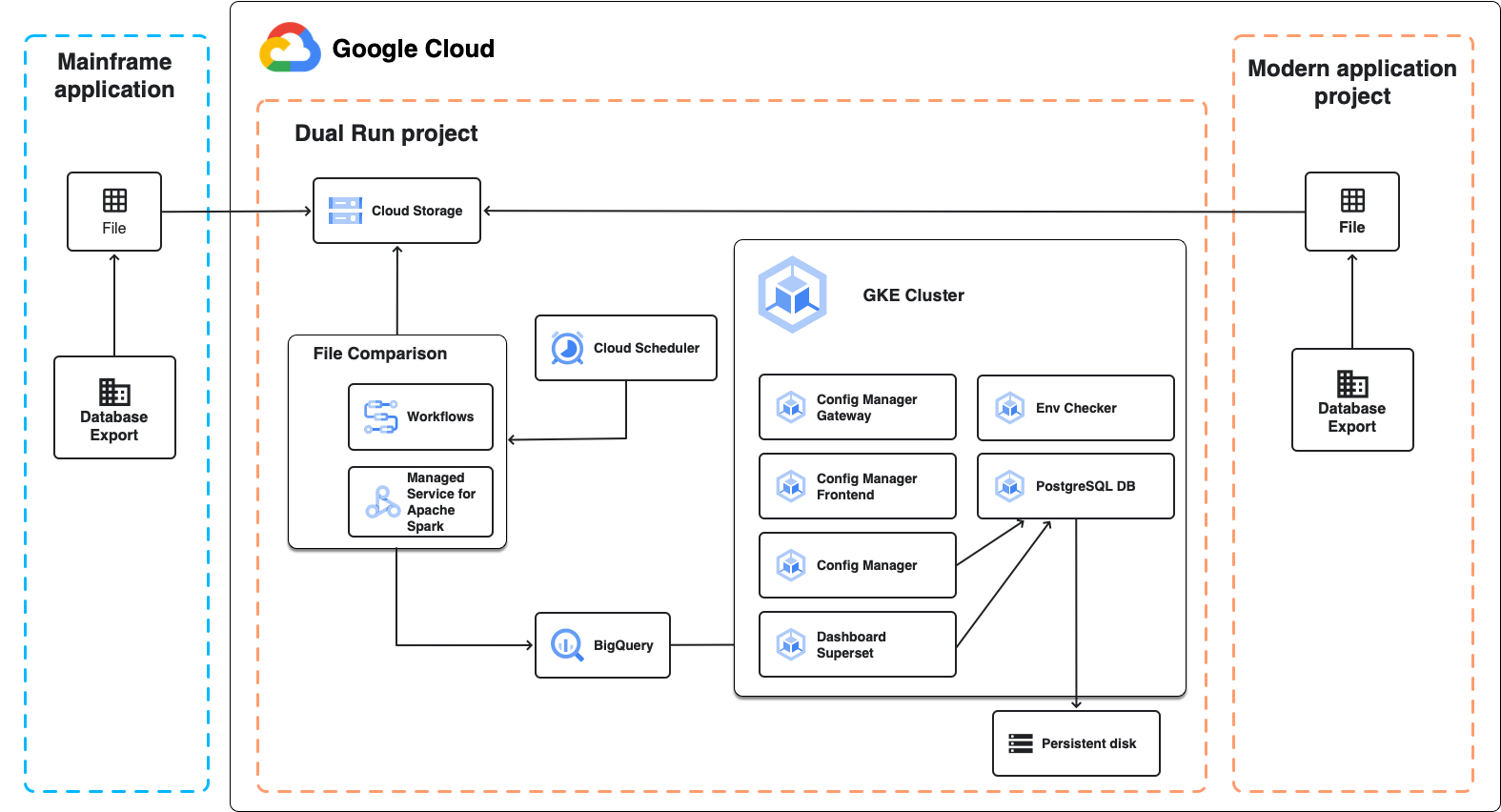
Confronto file
Il confronto dei file è il componente di Dual Run che ti consente di confrontare gli output dei file previsti e effettivi della configurazione di Dual Run. Quando esegui un confronto, puoi impostare il livello di tolleranza per contrassegnare i risultati come equivalenti.
Il confronto dei file utilizza Managed Service for Apache Spark, un cluster Apache Spark completamente gestito in esecuzione su Google Cloud, per eseguire il confronto. A seconda delle dimensioni dei dati che prevedi di confrontare e dei requisiti dell'infrastruttura, puoi scegliere due approcci diversi:
- Un ambiente serverless gestito basato su Spark in esecuzione su Managed Service for Apache Spark che viene creato nell'ambito del deployment Dual Run. Utilizza una configurazione fissa che consente di confrontare file fino a diversi GB. Questo è l'approccio predefinito.
- Un cluster Spark su Managed Service for Apache Spark che crei e configuri dopo
il deployment di Dual Run. Questa opzione è utile nei seguenti casi:
- Intendi utilizzare configurazioni personalizzate di VM o dischi.
- Devi confrontare file di dimensioni superiori a diversi GB.
- Vuoi eseguire più job di confronto contemporaneamente.
Architettura per il confronto online
Il seguente diagramma mostra l'architettura Dual Run per il confronto online, come descritto nelle sezioni seguenti.
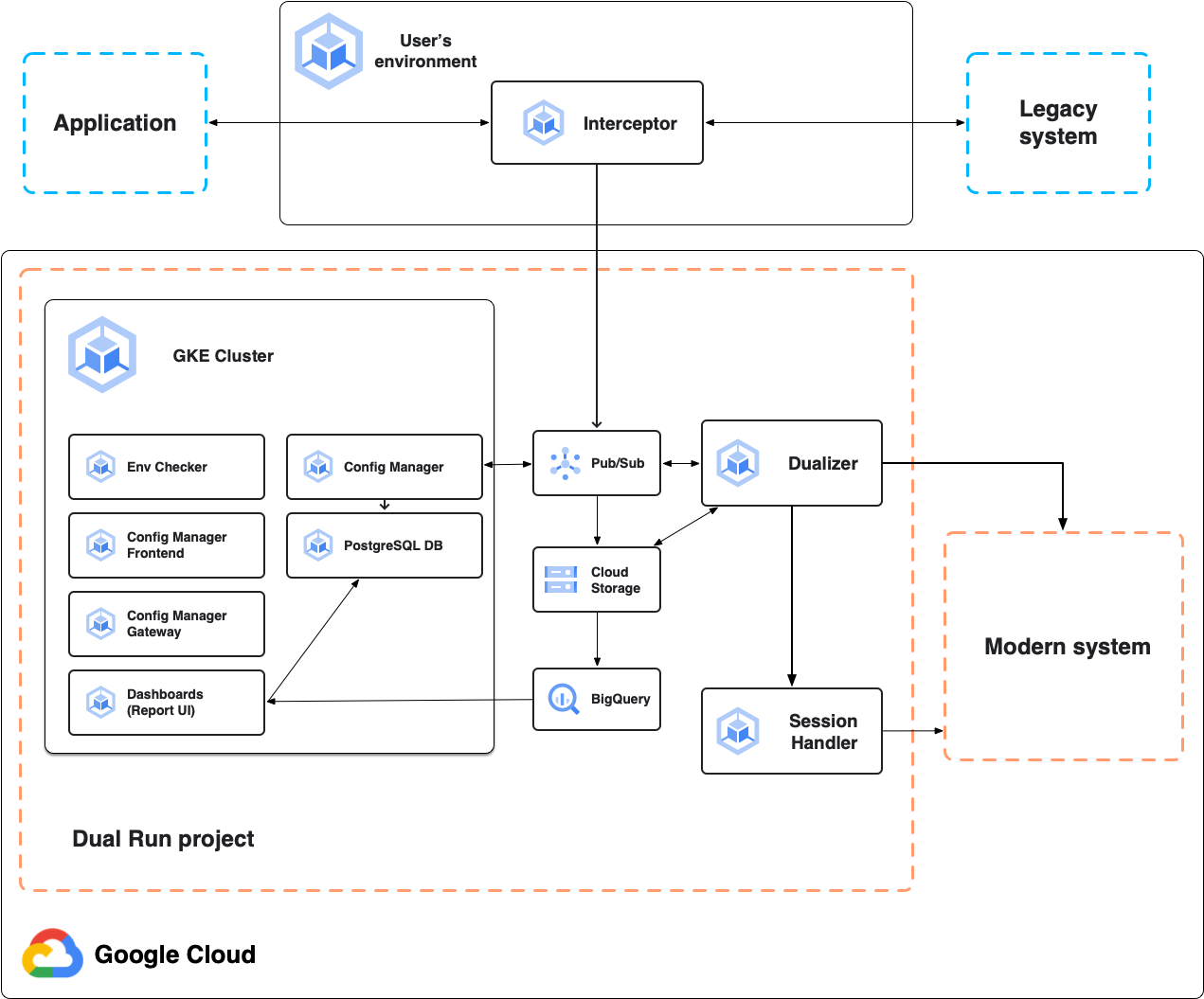
Interceptor
L'intercettatore funge da proxy altamente affidabile e performante per il sistema principale, l'applicazione mainframe. Ascolta il traffico delle applicazioni e inoltra le richieste al sistema principale con una latenza minima. Replica tutte le richieste e le risposte per la successiva dualizzazione. Puoi eseguire il deployment dell'intercettore in qualsiasi ambiente basato su Kubernetes, incluso il progetto Dual Run o il tuo ambiente on-premise.
L'intercettore funziona anche quando la connessione ai servizi Google Cloud non riesce, garantendo la massima disponibilità per il sistema principale.
Dual Run supporta gli intercettori per i messaggi HTTP, TN3270 e MQ.
Dualizer
Il dualizzatore riproduce le transazioni online acquisite nel sistema secondario modernizzato. Consuma le transazioni registrate dalla coda di duplicazione in Pub/Sub, invia richieste al sistema secondario e recupera le risposte.
Le risposte primaria e secondaria vengono confrontate utilizzando lo stesso motore di confronto sottostante utilizzato dal confronto dei file per il batch. Richieste, risposte e risultati del confronto vengono archiviati in Cloud Storage, mentre i risultati del confronto vengono trasmessi in streaming a BigQuery. I file di configurazione sono gestiti da Config Manager e vengono letti da Cloud Storage.
Session Handler
Il gestore delle sessioni è responsabile della gestione delle sessioni attive con il sistema secondario. Il gestore di sessione mantiene un socket TCP aperto per ogni connessione client, per i protocolli di comunicazione stateful, come TN3270. Per ogni richiesta dualizzata al sistema secondario, il dualizzatore invia la richiesta dualizzata al gestore delle sessioni. Il gestore di sessione lo invia quindi al sistema secondario utilizzando il socket aperto, riceve le risposte secondarie e le invia di nuovo al dualizzatore per l'elaborazione.
Dipendenze diGoogle Cloud
Dual Run si basa sui seguenti Google Cloud prodotti:
- Google Kubernetes Engine: Dual Run utilizza GKE per eseguire i microservizi nei pod.
- Cloud Storage: Dual Run archivia i file di configurazione per il tuo ambiente e gli artefatti di confronto che fornisci nei bucket Cloud Storage.
- Artifact Registry:Dual Run archivia le immagini container nel registry per l'utilizzo di GKE.
- BigQuery: Dual Run archivia i risultati dell'output di confronto per le transazioni batch e online in BigQuery.
- Pub/Sub: Dual Run utilizza Pub/Sub come sistema di messaggistica interno per trasferire le modifiche alla configurazione tra i diversi pod.
- Cloud SQL: Dual Run crea un'istanza di database Cloud SQL per garantire la compatibilità con gli aggiornamenti futuri.
Il confronto batch Dual Run si basa sui seguenti prodotti aggiuntivi:
- Managed Service for Apache Spark: Dual Run utilizza un cluster Spark serverless in Managed Service for Apache Spark per eseguire i confronti dei file.
- Workflows e Cloud Run Functions: Dual Run utilizza Workflows per gestire le Cloud Run Functions che eseguono i job di confronto dei file.
- Identity and Access Management: Dual Run si basa su Identity and Access Management per l'autenticazione e la gestione degli accessi, che ti consente di utilizzare i provider di identità Google o SAML per autenticare e autorizzare i ruoli utente.
Il confronto online Dual Run si basa sui seguenti prodotti aggiuntivi:
- Secret Manager:Dual Run utilizza Secret Manager per archiviare i secret, ad esempio le credenziali per il gestore delle code che esegui il deployment per Dual Run.
- Cloud Monitoring: Dual Run utilizza Cloud Monitoring per raccogliere e monitorare metriche, eventi e log dai tuoi componenti e risorse di Dual Run. Google Cloud
- Cloud Trace: Dual Run utilizza Cloud Trace per fornire funzionalità avanzate di monitoraggio e debug.
Passaggi successivi
Scopri di più sul confronto dei file di Dual Run.