
בדף הזה מתוארים הרכיבים העיקריים של Dual Run. חלק מהרכיבים בארכיטקטורה משותפים להשוואה בין נתונים מצטברים לבין נתונים בזמן אמת, אבל חלק מהרכיבים ספציפיים לסוג העומס.
רכיבים של Dual Run
רכיבי Dual Run פועלים כקונטיינרים באשכול Google Kubernetes Engine (GKE). בנוסף, Dual Run מסתמך על מוצרים אחרים של Google Cloud , כמו BigQuery, Cloud Storage ורכיבים מיוחדים אחרים להשוואה של אצוות ולהשוואה אונליין.
רכיבי האשכול של Dual Run שמשותפים לעומסי עבודה אונליין ולעומסי עבודה של אצווה הם:
- Config Manager: ממשק המשתמש ולוחות הבקרה.
- Env Checker: מנוע לאימות ההתקנה.
Config Manager
Config Manager הוא הקצה הקדמי של אפליקציית Dual Run. רכיב זה משמש לניהול הרשאות משתמשים, להגדרת עומסי עבודה אונליין באמצעות נקודות קצה ולעריכת לוחות בקרה. אתם יכולים להגדיר אימות משתמשים באמצעות מערכת ניהול הזהויות והרשאות הגישה (IAM).
בנוסף, ב-Config Manager יש סביבת מרכז בקרה שבה אפשר לבדוק את תוצאות ההשוואה. במרכז השליטה אפשר לראות סיכום של תוצאות ההשוואה על סמך המסננים שהגדרתם, ולעיין בפרטים של התוצאות של כל רשומה בנפרד.
לוח הבקרה מבוסס על Apache Superset, תוכנה בקוד פתוח להדמיה של נתונים ולניתוח נתונים. אפשר גם ליצור דוחות ושאילתות בהתאמה אישית.
Env Checker
בודק הסביבה הוא רכיב של Dual Run שמאמת שההתקנה והפריסה של Dual Run הושלמו בהצלחה. הכלי בודק שכל הרכיבים הנדרשים של ההפעלה הכפולה מוגדרים ופועלים בצורה נכונה, ואם לא, הוא מדווח על שגיאות או על הגדרות שגויות.
ארכיטקטורה להשוואה של קבוצות
בתרשים הבא מוצגת ארכיטקטורת ההפעלה הכפולה להשוואה של נתונים מצטברים, כפי שמתואר בקטעים הבאים.
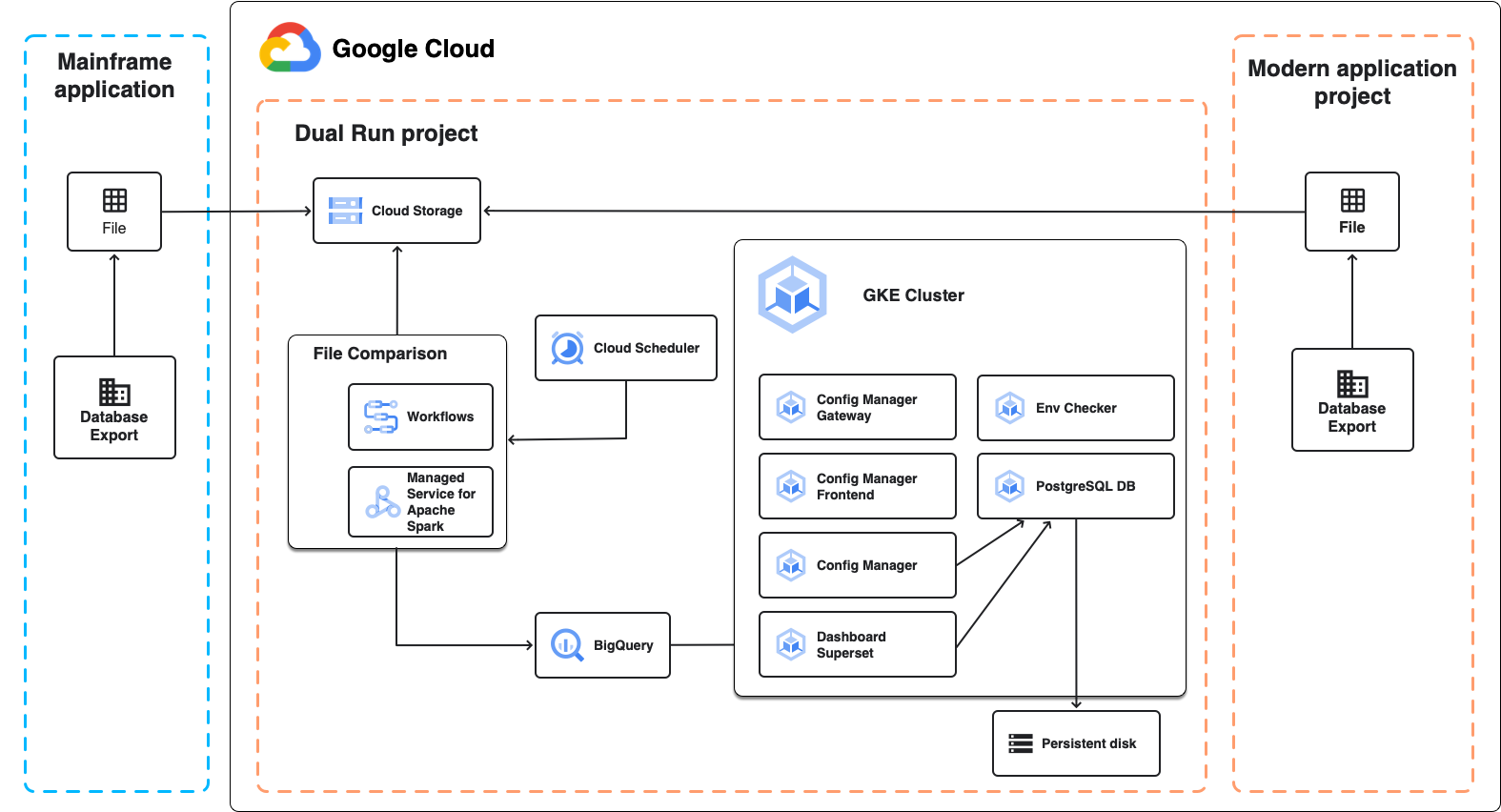
השוואת קבצים
השוואת קבצים היא רכיב של הפעלת כפולה שמאפשר להשוות בין פלט הקבצים הצפוי לבין פלט הקבצים בפועל של ההגדרה של הפעלת כפולה. כשמבצעים השוואה, אפשר להגדיר את רמת הסבילות כדי לסמן את התוצאות כשוות.
השירות 'השוואת קבצים' משתמש ב-Managed Service for Apache Spark, אשכול Apache Spark מנוהל במלואו שפועל ב- Google Cloud, כדי לבצע את ההשוואה. בהתאם לגודל הנתונים שאתם מתכננים להשוות ולדרישות התשתית שלכם, אתם יכולים לבחור בין שתי גישות שונות:
- סביבה מנוהלת בלי שרת (serverless) שמבוססת על Spark ופועלת ב-Managed Service for Apache Spark, שנוצרת כחלק מהפריסה של Dual Run. הוא משתמש בהגדרה קבועה שמאפשרת להשוות קבצים בגודל של כמה גיגה-בייט. זו הגישה שמוגדרת כברירת מחדל.
- אשכול Spark ב-Managed Service for Apache Spark שיוצרים ומגדירים אחרי הפריסה של Dual Run. האפשרות הזו שימושית במקרים הבאים:
- אתם מתכננים להשתמש בהגדרות מותאמות אישית של מכונות וירטואליות או דיסקים.
- אתם צריכים להשוות קבצים גדולים מכמה GB.
- רוצים להריץ כמה משימות השוואה בו-זמנית.
ארכיטקטורה להשוואה אונליין
בתרשים הבא מוצגת ארכיטקטורת ההפעלה הכפולה להשוואה אונליין, כפי שמתואר בקטעים הבאים.
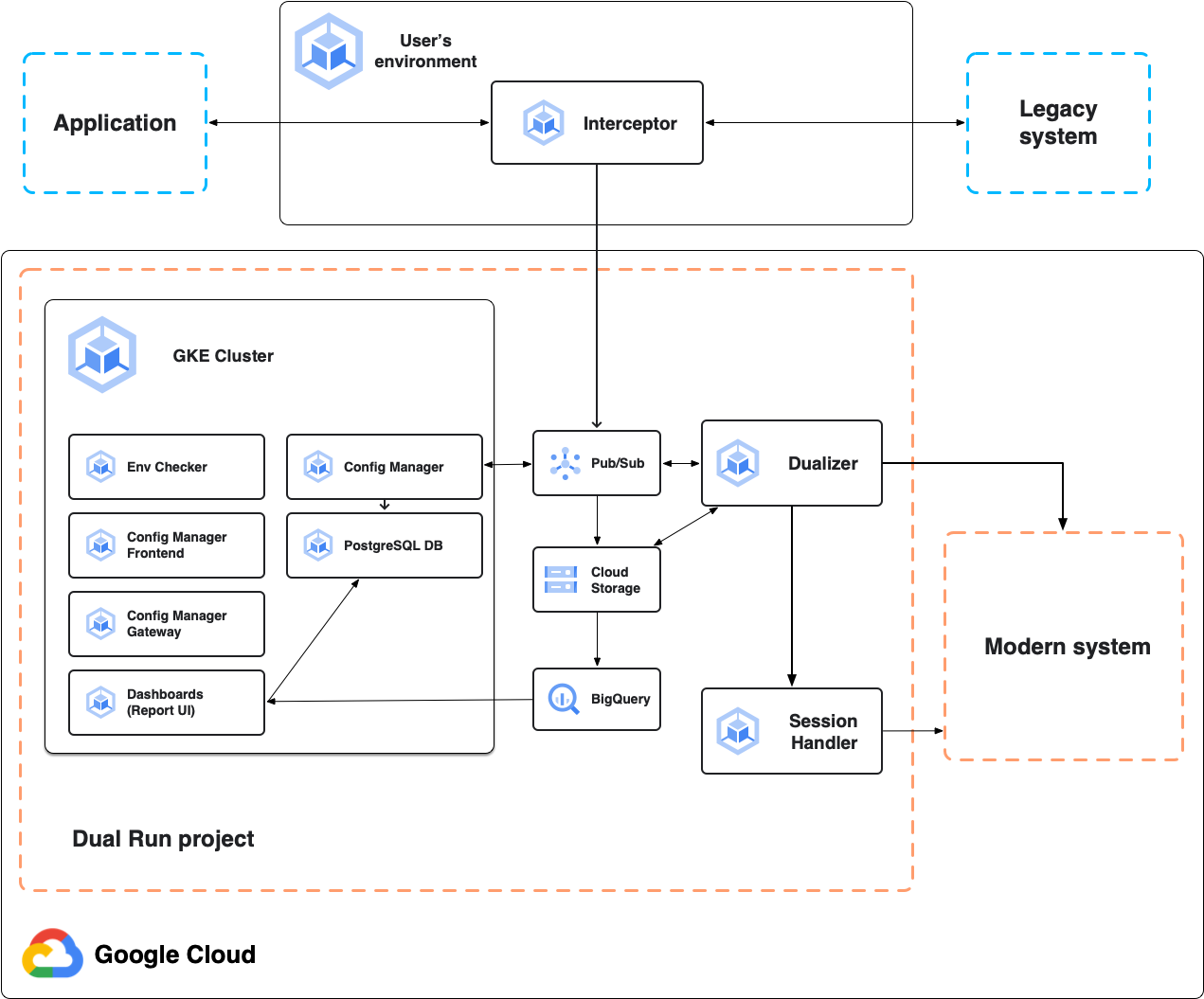
Interceptor
ה-interceptor פועל כפרוקסי אמין ויעיל למערכת הראשית, אפליקציית המיינפריים. הוא מאזין לתעבורת נתונים של האפליקציה ומעביר בקשות למערכת הראשית עם זמן אחזור מינימלי. הוא משכפל את כל הבקשות והתשובות לצורך יצירת כפילות בהמשך. אפשר לפרוס את ה-interceptor בכל סביבה מבוססת Kubernetes, כולל פרויקט Dual Run או הסביבה המקומית שלכם.
ה-interceptor פועל גם כשהחיבור לשירותי Google Cloud נכשל, וכך הוא מבטיח זמינות מקסימלית למערכת הראשית.
הכלי Dual Run תומך ב-interceptors להודעות HTTP, TN3270 ו-MQ.
Dualizer
הכלי Dualizer מפעיל מחדש עסקאות אונליין שתועדו במערכת המשנית המודרנית. היא צורכת עסקאות מתועדות מתור הכפילות ב-Pub/Sub, שולחת בקשות למערכת המשנית ומאחזרת תשובות.
התשובות העיקריות והמשניות מושווות באמצעות אותו מנוע השוואה בסיסי שמשמש להשוואת קבצים באצווה. הבקשות, התגובות ותוצאות ההשוואה מאוחסנות ב-Cloud Storage, ותוצאות ההשוואה מועברות בסטרימינג ל-BigQuery. קובצי התצורה מנוהלים על ידי Config Manager ונשלפים מ-Cloud Storage.
Session Handler
האחריות של המטפל בסשנים היא לתחזק את הסשנים הפעילים עם המערכת המשנית. גורם ה-handler של הסשן שומר על שקע TCP פתוח לכל חיבור לקוח, עבור פרוטוקולי תקשורת שהם stateful, כמו TN3270. לכל בקשה שמועברת למערכת המשנית, הממיר שולח את הבקשה המועברת ל-session handler. לאחר מכן, המטפל בסשן שולח את הבקשה למערכת המשנית באמצעות השקע הפתוח, מקבל את התשובות המשניות ושולח אותן בחזרה למערכת הכפולה לעיבוד.
Google Cloud dependencies
הפעלת Dual Run מסתמכת על המוצרים הבאים Google Cloud :
- Google Kubernetes Engine: Dual Run משתמש ב-GKE כדי להריץ את המיקרו-שירותים שלו ב-Pods.
- Cloud Storage: Dual Run מאחסן קבצי הגדרות של הסביבה ופריטי השוואה שאתם מספקים בקטגוריות של Cloud Storage.
- Artifact Registry: Dual Run מאחסן קובצי אימג' של קונטיינרים במאגר לשימוש ב-GKE.
- BigQuery: התכונה 'הפעלה כפולה' מאחסנת ב-BigQuery את תוצאות הפלט של ההשוואה בין עסקאות באצווה לבין עסקאות אונליין.
- Pub/Sub: ב-Dual Run נעשה שימוש ב-Pub/Sub כמערכת פנימית להעברת הודעות, כדי להעביר שינויים בהגדרות בין הפודים השונים.
- Cloud SQL: Dual Run יוצר מכונת מסד נתונים ב-Cloud SQL כדי להבטיח תאימות לעדכונים עתידיים.
השוואה בין אצווה של הפעלה כפולה מסתמכת על המוצרים הנוספים הבאים:
- Managed Service for Apache Spark: ב-Dual Run נעשה שימוש באשכול Spark ללא שרת ב-Managed Service for Apache Spark כדי להריץ השוואות בין קבצים.
- Workflows ופונקציות Cloud Run: Dual Run משתמש ב-Workflows כדי לנהל את פונקציות Cloud Run שמבצעות את משימות השוואת הקבצים.
- ניהול זהויות והרשאות גישה: הפעלת Dual Run מסתמכת על ניהול זהויות והרשאות גישה לאימות ולניהול הרשאות גישה, שמאפשר לכם להשתמש בספקי זהויות של Google או SAML כדי לאמת ולאשר תפקידי משתמש.
השוואה אונליין של הפעלה כפולה מסתמכת על המוצרים הנוספים הבאים:
- Secret Manager: ב-Dual Run נעשה שימוש ב-Secret Manager כדי לאחסן סודות, כמו פרטי הכניסה של מנהל התורים שאתם פורסים עבור Dual Run.
- Cloud Monitoring: Dual Run משתמש ב-Cloud Monitoring כדי לאסוף ולנטר מדדים, אירועים ויומנים מרכיבי Dual Run וממשאבי Google Cloud .
- Cloud Trace: ב-Dual Run נעשה שימוש ב-Cloud Trace כדי לספק יכולות משופרות של מעקב וניפוי באגים.
המאמרים הבאים
מידע נוסף על השוואת קבצים ב-Dual Run