
Cette page décrit les principaux composants de Dual Run. Bien que certaines parties de l'architecture soient partagées entre la comparaison par lot et la comparaison en ligne, d'autres sont spécifiques à l'une ou l'autre charge de travail.
Composants de Dual Run
Les composants de Dual Run s'exécutent en tant que conteneurs dans un cluster Google Kubernetes Engine (GKE). Dual Run s'appuie également sur d'autres Google Cloud produits, tels que BigQuery, Cloud Storage et d'autres composants spécialisés pour la comparaison par lot et la comparaison en ligne.
Les composants de cluster Dual Run partagés pour les charges de travail en ligne et par lot sont les suivants :
- Gestionnaire de configuration : interface utilisateur et tableaux de bord.
- Vérificateur d'environnement : moteur de vérification de l'installation.
Gestionnaire de configuration
Le gestionnaire de configuration est l'interface de l'application Dual Run. Vous utilisez ce composant pour gérer les autorisations des utilisateurs, configurer les charges de travail en ligne via des points de terminaison et modifier les tableaux de bord. Vous pouvez configurer l'authentification des utilisateurs à l'aide du système Identity and Access Management.
Le gestionnaire de configuration fournit également l'environnement de tableau de bord dans lequel vous pouvez examiner les résultats de la comparaison. Le tableau de bord vous permet d'afficher un résumé des résultats de la comparaison en fonction des filtres que vous appliquez, et d'examiner les détails des résultats pour chaque enregistrement individuel.
Le tableau de bord est basé sur Apache Superset, un logiciel Open Source de visualisation et d'exploration des données. Il vous permet également de créer des rapports et des requêtes personnalisés.
Vérificateur d'environnement
Le vérificateur d'environnement est le composant Dual Run qui vérifie que l'installation et le déploiement de Dual Run se sont bien déroulés. Il vérifie que tous les composants Dual Run nécessaires sont correctement configurés et en cours d'exécution, et signale les erreurs ou les configurations incorrectes.
Architecture pour la comparaison par lot
Le schéma suivant illustre l'architecture Dual Run pour la comparaison par lot, comme décrit dans les sections suivantes.
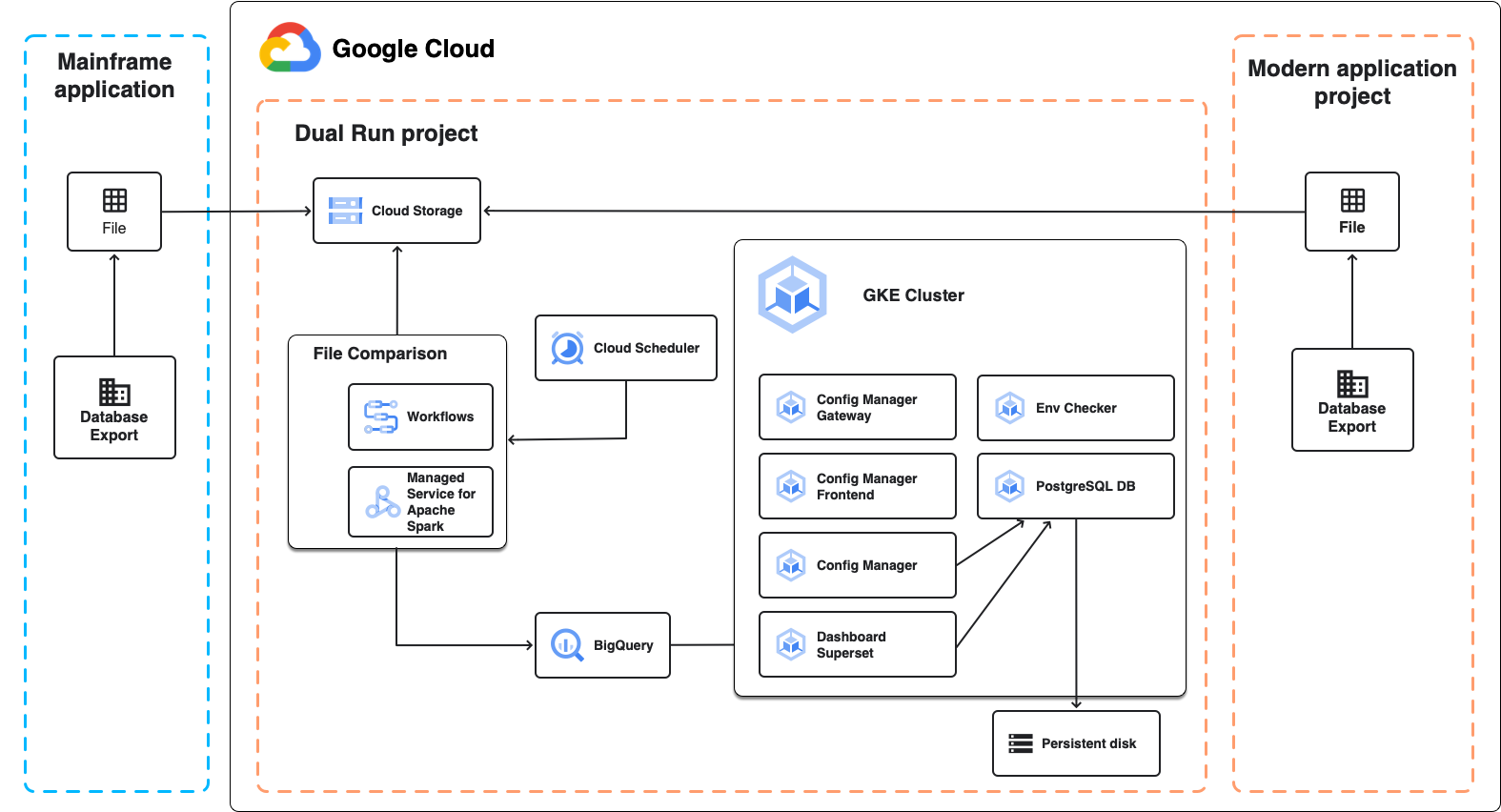
Comparaison de fichiers
La comparaison de fichiers est le composant Dual Run qui vous permet de comparer les sorties de fichiers attendues et réelles de votre configuration Dual Run. Lorsque vous effectuez une comparaison, vous pouvez définir le niveau de tolérance pour marquer les résultats comme équivalents.
La comparaison de fichiers utilise Managed Service pour Apache Spark, un cluster Apache Spark entièrement géré exécuté sur Google Cloud, pour effectuer la comparaison. En fonction de la taille des données que vous prévoyez de comparer et de vos exigences en matière d'infrastructure, vous pouvez choisir deux approches différentes :
- Un environnement géré sans serveur basé sur Spark exécuté sur Managed Service pour Apache Spark, créé dans le cadre du déploiement Dual Run. Il utilise une configuration fixe qui vous permet de comparer des fichiers de plusieurs Go. Il s'agit de l'approche par défaut.
- Un cluster Spark sur Managed Service pour Apache Spark que vous créez et configurez après le déploiement Dual Run. Cette approche est utile dans les cas suivants :
- Vous prévoyez d'utiliser des configurations de VM ou de disque personnalisées.
- Vous devez comparer des fichiers de plus de plusieurs Go.
- Vous souhaitez exécuter plusieurs tâches de comparaison en même temps.
Architecture pour la comparaison en ligne
Le schéma suivant illustre l'architecture Dual Run pour la comparaison en ligne, comme décrit dans les sections suivantes.
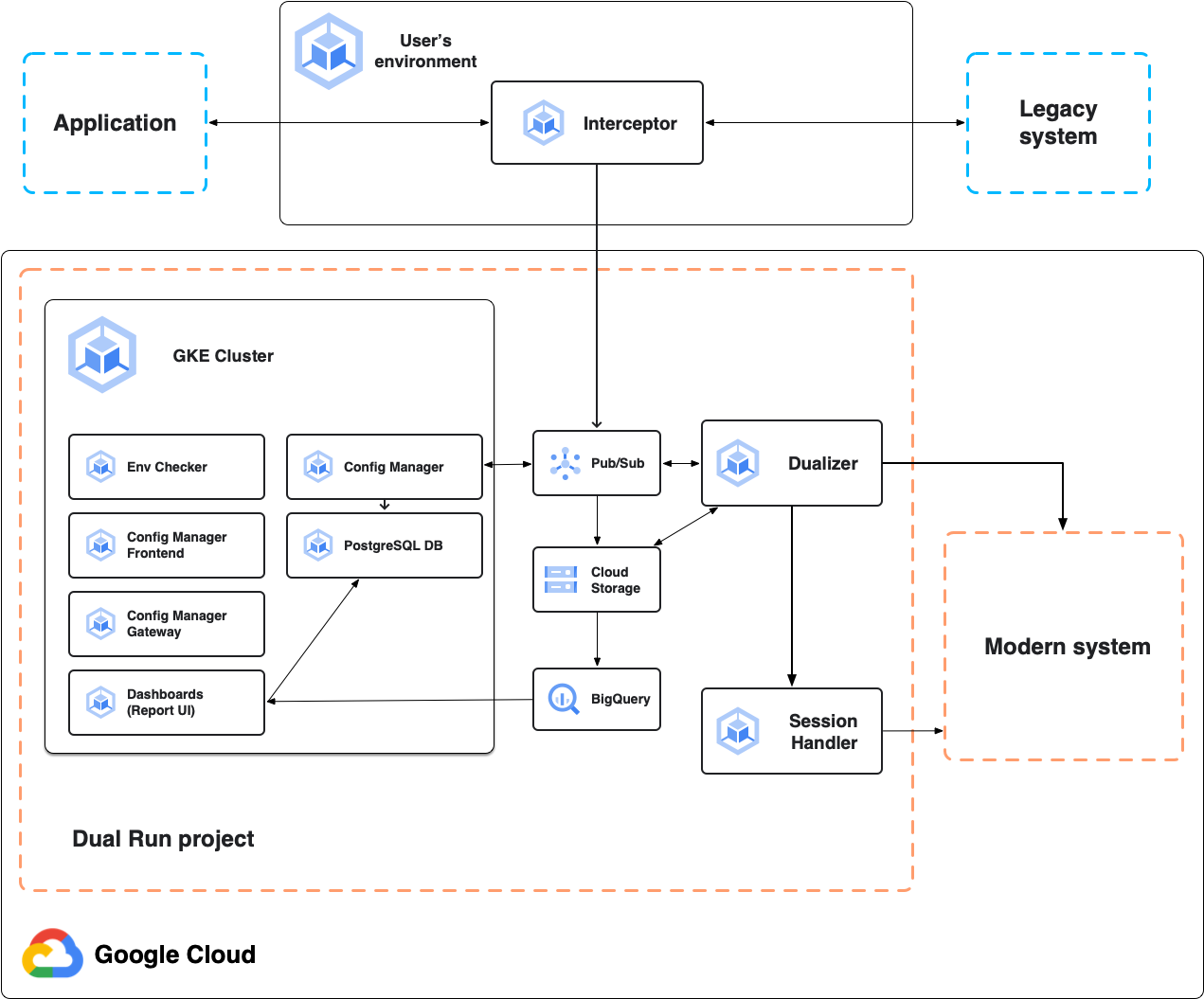
Interceptor
L'intercepteur agit comme un proxy hautement fiable et performant pour le système principal, l'application mainframe. Il écoute le trafic de l'application et transfère les requêtes au système principal avec une latence minimale. Il réplique toutes les requêtes et réponses pour la dualisation ultérieure. Vous pouvez déployer l'intercepteur dans n'importe quel environnement basé sur Kubernetes, y compris le projet Dual Run ou votre environnement sur site.
L'intercepteur fonctionne même lorsque la connexion aux Google Cloud services échoue, ce qui garantit une disponibilité maximale pour le système principal.
Dual Run est compatible avec les intercepteurs pour les messages HTTP, TN3270 et MQ.
Dualizer
Le dualizer relit les transactions en ligne capturées dans le système secondaire modernisé. Il consomme les transactions enregistrées à partir de la file d'attente de dualisation dans Pub/Sub, envoie des requêtes au système secondaire et récupère les réponses.
Les réponses principales et secondaires sont comparées à l'aide du même moteur de comparaison sous-jacent que celui utilisé par la comparaison de fichiers pour le traitement par lot. Les requêtes, les réponses et les résultats de la comparaison sont stockés dans Cloud Storage, tandis que les résultats de la comparaison sont diffusés en streaming vers BigQuery. Les fichiers de configuration sont gérés par le gestionnaire de configuration et sont lus à partir de Cloud Storage.
Gestionnaire de sessions
Le gestionnaire de sessions est chargé de maintenir les sessions actives avec le système secondaire. Le gestionnaire de sessions maintient un socket TCP ouvert par connexion client pour les protocoles de communication avec état, tels que TN3270. Pour chaque requête dualisée vers le système secondaire, le dualizer envoie la requête dualisée au gestionnaire de sessions. Le gestionnaire de sessions l'envoie ensuite au système secondaire à l'aide du socket ouvert, reçoit les réponses secondaires et les renvoie au dualizer pour traitement.
Google Cloud Dépendances
Dual Run s'appuie sur les Google Cloud produits suivants pour s'exécuter :
- Google Kubernetes Engine : Dual Run utilise GKE pour exécuter ses microservices dans des pods.
- Cloud Storage : Dual Run stocke les fichiers de configuration de votre environnement et les artefacts de comparaison que vous fournissez dans des buckets Cloud Storage.
- Artifact Registry : Dual Run stocke les images de conteneurs dans le registre pour une utilisation dans GKE.
- BigQuery : Dual Run stocke les résultats de la comparaison pour les transactions par lot et en ligne dans BigQuery.
- Pub/Sub : Dual Run utilise Pub/Sub comme système de messagerie interne pour transmettre les modifications de configuration entre ses différents pods.
- Cloud SQL : Dual Run crée une instance de base de données Cloud SQL pour assurer la compatibilité avec les futures mises à jour.
La comparaison par lot Dual Run s'appuie sur les produits supplémentaires suivants :
- Managed Service pour Apache Spark : Dual Run utilise un cluster Spark sans serveur dans Managed Service pour Apache Spark afin d'exécuter des comparaisons de fichiers.
- Workflows et Cloud Run Functions : Dual Run utilise Workflows pour gérer les fonctions Cloud Run qui exécutent les tâches de comparaison de fichiers.
- Identity and Access Management : Dual Run s'appuie sur Identity and Access Management pour l'authentification et la gestion des accès, ce qui vous permet d'utiliser des fournisseurs d'identité Google ou SAML pour authentifier et autoriser les rôles utilisateur.
La comparaison en ligne Dual Run s'appuie sur les produits supplémentaires suivants :
- Secret Manager : Dual Run utilise Secret Manager pour stocker des secrets, tels que les identifiants du gestionnaire de files d'attente que vous déployez pour Dual Run.
- Cloud Monitoring : Dual Run utilise Cloud Monitoring pour collecter et surveiller les métriques, les événements et les journaux de vos composants et Google Cloud ressources Dual Run.
- Cloud Trace : Dual Run utilise Cloud Trace pour fournir des fonctionnalités de surveillance et de débogage améliorées.
Étape suivante
En savoir plus sur la comparaison de fichiers Dual Run File Comparison.