
קידוד מחדש של נתונים באופן מקומי במחשב מרכזי הוא תהליך שדורש הרבה משאבי CPU, וכתוצאה מכך צריכה גבוהה של מיליוני הוראות לשנייה (MIPS). כדי להימנע מכך, אפשר להשתמש ב-Cloud Run כדי להעביר נתונים ממחשב מרכזי ולשנות את הקידוד שלהם מרחוק ב-Google Cloud. כך המחשב המרכזי מתפנה למשימות קריטיות לעסק, וגם צריכת ה-MIPS יורדת.
אם רוצים להעביר כמויות גדולות מאוד של נתונים (בערך 500GB ביום או יותר) מהמחשב המרכזי אל Google Cloud, ולא רוצים להשתמש במחשב המרכזי לצורך הזה, אפשר להשתמש בפתרון ספריית סרטים וירטואלית (VTL) שמופעלת בענן כדי להעביר את הנתונים לקטגוריה ב-Cloud Storage. לאחר מכן תוכלו להשתמש ב-Cloud Run כדי לבצע טרנסקוד לנתונים שקיימים בדלי ולהעביר אותם ל-BigQuery.
בדף הזה מוסבר איך לקרוא נתונים ממחשב מרכזי שהועתקו לקטגוריה של Cloud Storage, לבצע טרנסקוד של הנתונים מסט הנתונים של קוד החלפה עשרוני בינארי מורחב (EBCDIC) לפורמט ORC ב-UTF-8, ולטעון את סט הנתונים לטבלה ב-BigQuery.
בתרשים הבא מוצג תהליך העברת נתונים ממחשב מרכזי לקטגוריה של Cloud Storage באמצעות פתרון VTL, קידוד מחדש של הנתונים לפורמט ORC באמצעות Cloud Run, והעברת התוכן ל-BigQuery.
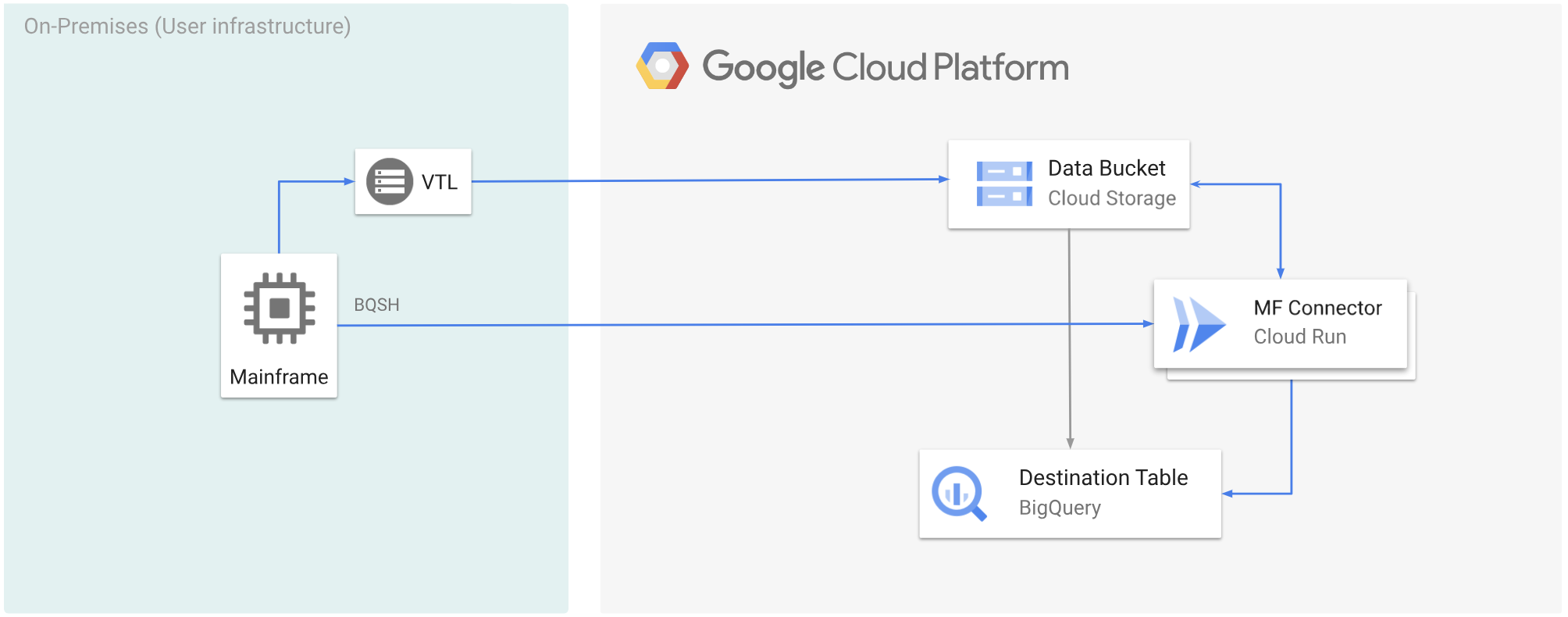
לפני שמתחילים
- בוחרים פתרון VTL שמתאים לדרישות שלכם, מעבירים את הנתונים של המיינפריים לקטגוריה של Cloud Storage ושומרים אותם כ-
.dat. חשוב לוודא שמוסיפים מפתח מטא-נתונים בשםx-goog-meta-lreclלקובץ.datשהועלה, ושאורך מפתח המטא-נתונים שווה לאורך הרשומה של הקובץ המקורי, למשל 80. - פריסת Mainframe Connector ב-Cloud Run.
- במחשב המרכזי, מגדירים את משתנה הסביבה
GCSDSNURIלקידומת שבה השתמשתם לנתוני המחשב המרכזי בקטגוריית Cloud Storage.export GCSDSNURI="gs://BUCKET/PREFIX"
- BUCKET: השם של הקטגוריה ב-Cloud Storage.
- PREFIX: התחילית שרוצים להשתמש בה בקטגוריה.
- יוצרים חשבון שירות או מזהים חשבון שירות קיים לשימוש עם Mainframe Connector. לחשבון השירות הזה צריכות להיות הרשאות גישה למאגרי Cloud Storage, למערכי נתונים של BigQuery ולכל משאב אחר שרוצים להשתמש בו. Google Cloud
- מוודאים שלחשבון השירות שיצרתם מוקצה התפקיד Cloud Run Invoker.
המרת קידוד של נתוני מחשב מרכזי שהועלו לקטגוריה של Cloud Storage
כדי להעביר נתונים ממחשב מרכזי אל Google Cloud באמצעות VTL וקידוד טרנסקוד מרחוק, צריך לבצע את המשימות הבאות:
- לקרוא ולתמלל את הנתונים שקיימים בקטגוריה של Cloud Storage לפורמט ORC. פעולת הקידוד מחדש ממירה מערך נתונים של EBCDIC במחשב מרכזי לפורמט ORC ב-UTF-8.
- טוענים את מערך הנתונים לטבלה ב-BigQuery.
- (אופציונלי) מריצים שאילתת SQL בטבלת BigQuery.
- (אופציונלי) מייצאים נתונים מ-BigQuery לקובץ בינארי ב-Cloud Storage.
כדי לבצע את המשימות האלה, פועלים לפי השלבים הבאים:
במחשב המרכזי, יוצרים משימה לקריאת הנתונים מקובץ
.datבקטגוריה של Cloud Storage, ומשנים את הקידוד לפורמט ORC, באופן הבא.רשימה מלאה של משתני הסביבה שנתמכים על ידי Mainframe Connector מופיעה במאמר משתני סביבה.
//STEP01 EXEC BQSH //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc \ --inDsn INPUT_FILENAME \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 \ --project_id PROJECT_NAME /*מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_NAME: שם הפרויקט שבו רוצים להריץ את השאילתה. -
INPUT_FILENAME: השם של.datהקובץ שהעליתם לקטגוריה של Cloud Storage.
אם רוצים לתעד את הפקודות שהופעלו במהלך התהליך הזה, אפשר להפעיל את סטטיסטיקת הטעינה.
-
(אופציונלי) יוצרים ומגישים עבודת שאילתה ב-BigQuery שמבצעת קריאת SQL מקובץ ה-DD של השאילתה. בדרך כלל השאילתה תהיה הצהרת
MERGEאוSELECT INTO DMLשתגרום לשינוי של טבלה ב-BigQuery. הערה: Mainframe Connector מתעד מדדי עבודה ביומן, אבל לא כותב את תוצאות השאילתה לקובץ.אפשר להריץ שאילתות ב-BigQuery בכמה דרכים – בשורה, עם מערך נתונים נפרד באמצעות DD, או עם מערך נתונים נפרד באמצעות DSN.
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION/* /*מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_NAME: שם הפרויקט שבו רוצים להריץ את השאילתה. -
LOCATION: המיקום שבו השאילתה תופעל. מומלץ להריץ את השאילתה במיקום שקרוב לנתונים.
-
(אופציונלי) יוצרים ושולחים משימת ייצוא שמבצעת קריאת SQL מקובץ ה-DD של השאילתה, ומייצאת את מערך הנתונים שמתקבל ל-Cloud Storage כקובץ בינארי.
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_NAME: שם הפרויקט שבו רוצים להריץ את השאילתה. -
DATASET_ID: מזהה מערך הנתונים ב-BigQuery שמכיל את הטבלה שרוצים לייצא. -
DESTINATION_TABLE: הטבלה ב-BigQuery שרוצים לייצא. -
BUCKET: קטגוריית Cloud Storage שתכיל את קובץ הפלט הבינארי.
-