
Utilizzo
explore: explore_name {
join: view_name { ... }
}
|
Gerarchia
join |
Valore predefinito
Nessuno
Accetta
Il nome di una vista esistente
Regole speciali
|
Definizione
join ti consente di definire la relazione di join tra un'Esplora e una vista, in modo da poter combinare i dati di più viste. Puoi unire tutte le viste che vuoi per una determinata esplorazione.
Ricorda che ogni vista è associata a una tabella nel database o a una tabella derivata che hai definito in Looker. Allo stesso modo, poiché un'esplorazione è associata a una vista, è anche connessa a una tabella di qualche tipo.
La tabella associata all'esplorazione viene inserita nella clausola FROM dell'SQL generato da Looker. Le tabelle associate alle viste unite vengono inserite nella clausola JOIN dell'SQL generato da Looker.
Parametri di join principali
Per definire la relazione di join (la clausola SQL ON) tra un'esplorazione e una vista, devi utilizzare join in combinazione con altri parametri.
Per stabilire la clausola SQL ON, devi utilizzare o il parametro sql_on o il parametro foreign_key.
Dovrai anche assicurarti di utilizzare tipi e relazioni di join appropriati, anche se i type e relationship parametri non sono sempre richiesti in modo esplicito. Se i valori predefiniti di type: left_outer e relationship: many_to_one sono appropriati per il tuo caso d'uso, questi parametri possono essere esclusi.
Questi parametri chiave e la loro relazione con l'SQL generato da Looker possono essere riassunti come segue:
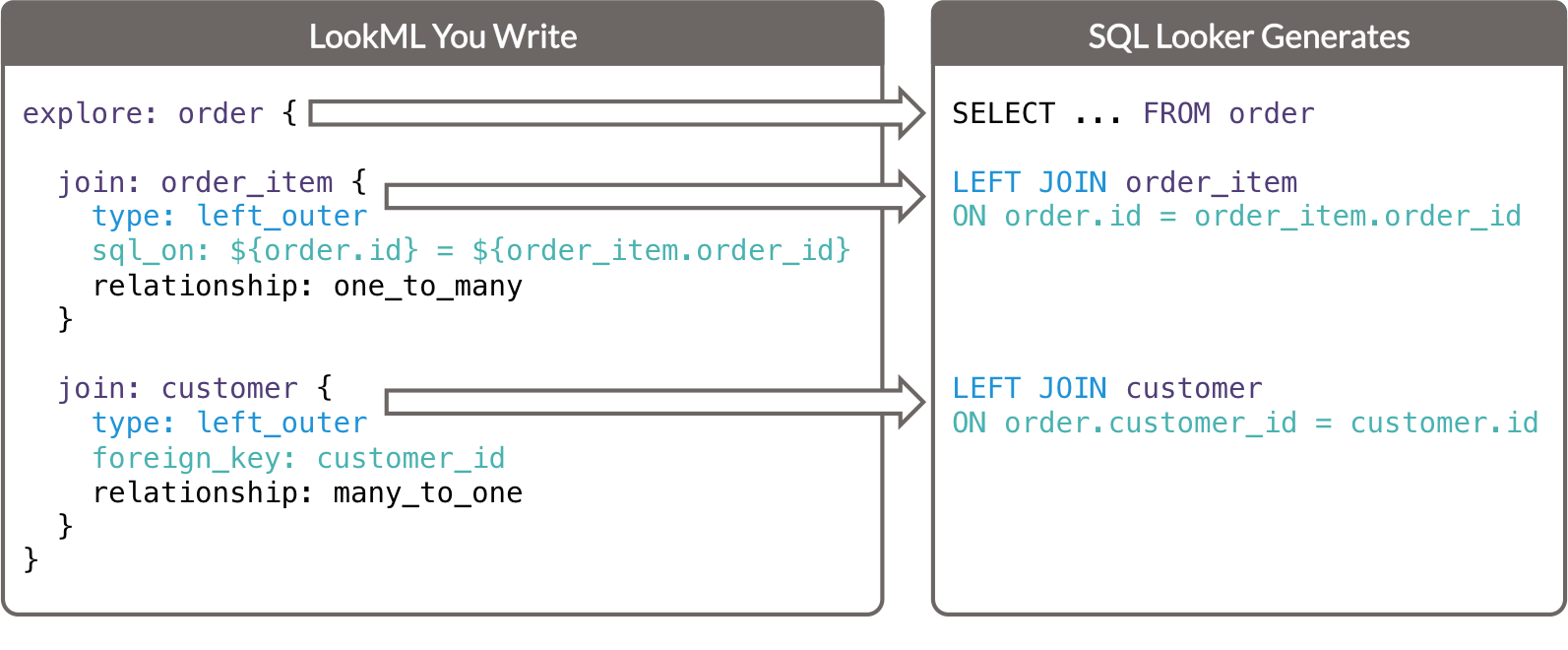
- Il parametro
exploredetermina la tabella nella clausolaFROMdella query SQL generata. - Ogni parametro
joindetermina una clausolaJOINdella query SQL generata.- Il parametro
typedetermina il tipo di join SQL. - Il parametro
sql_one il parametroforeign_keydeterminano la clausolaONdella query SQL generata.
- Il parametro
sql_on
sql_on ti consente di stabilire una relazione di join scrivendo direttamente la clausola SQL ON. Può eseguire gli stessi join di foreign_key, ma è più facile da leggere e comprendere.
Per ulteriori informazioni, consulta la pagina della documentazione del parametro sql_on.
foreign_key
foreign_key ti consente di stabilire una relazione di join utilizzando la chiave primaria della vista unita e collegandola a una dimensione nell'esplorazione. Questo pattern è molto comune nella progettazione di database e foreign_key è un modo elegante per esprimere il join in questi casi.
Per una comprensione completa, consulta la pagina della documentazione del parametro foreign_key.
type
La maggior parte dei join in Looker sono LEFT JOIN per i motivi descritti nella sezione Non applicare la logica di business nei join, se possibile in questa pagina. Pertanto, se non aggiungi esplicitamente un type, Looker presupporrà che tu voglia un LEFT JOIN. Tuttavia, se per qualche motivo hai bisogno di un altro tipo di join, puoi farlo con type.
Per una spiegazione completa, consulta la pagina della documentazione del parametro type.
relationship
relationship non ha un impatto diretto sull'SQL generato da Looker, ma è fondamentale per il corretto funzionamento di Looker. Se non aggiungi esplicitamente un relationship, Looker interpreterà la relazione come many-to-one, il che significa che molte righe nell'esplorazione possono avere una riga nella vista unita. Non tutti i join hanno questo tipo di relazione e i join con altre relazioni devono essere dichiarati correttamente.
Per una comprensione completa, consulta la pagina della documentazione del parametro relationship.
Esempi
Unisci la vista denominata customer all'esplorazione denominata order dove la relazione di join è
FROM order LEFT JOIN customer ON order.customer_id = customer.id:
explore: order {
join: customer {
foreign_key: customer_id
relationship: many_to_one # Could be excluded since many_to_one is the default
type: left_outer # Could be excluded since left_outer is the default
}
}
Unisci la vista denominata address all'esplorazione denominata person dove la relazione di join è
FROM person LEFT JOIN address ON person.id = address.person_id
AND address.type = 'permanent':
explore: person {
join: address {
sql_on: ${person.id} = ${address.person_id} AND ${address.type} = 'permanent' ;;
relationship: one_to_many
type: left_outer # Could be excluded since left_outer is the default
}
}
Unisci la vista denominata member all'esplorazione denominata event dove la relazione di join è
FROM event INNER JOIN member ON member.id = event.member_id:
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
relationship: many_to_one # Could be excluded since many_to_one is the default
type: inner
}
}
Sfide comuni
join deve utilizzare i nomi delle viste e non i nomi delle tabelle sottostanti
Il parametro join accetta solo il nome di una vista, non il nome della tabella associata a quella vista. Spesso il nome della vista e il nome della tabella sono identici, il che può portare alla falsa conclusione che è possibile utilizzare i nomi delle tabelle.
Alcuni tipi di misure richiedono aggregazioni simmetriche
Se non utilizzi aggregazioni simmetriche, la maggior parte dei tipi di misure viene esclusa dalle viste unite. Affinché Looker supporti le aggregazioni simmetriche nel tuo progetto Looker, anche il dialetto del database deve supportarle. La tabella seguente mostra quali dialetti supportano le aggregazioni simmetriche nell'ultima release di Looker:
| Dialetto | Supportata? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13.x - 0.17.x | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud AlloyDB for PostgreSQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
Senza aggregazioni simmetriche, le relazioni di join che non sono uno-a-uno possono creare risultati imprecisi nelle funzioni di aggregazione. Poiché le misure di Looker sono funzioni di aggregazione, solo le misure di type: count (come COUNT DISTINCT) vengono importate dalle viste unite nell'esplorazione. Se hai una relazione di join uno-a-uno, puoi utilizzare il parametro relationship per forzare l'inclusione degli altri tipi di misure, come segue:
explore: person {
join: dna {
sql_on: ${person.dna_id} = ${dna.id} ;;
relationship: one_to_one
}
}
I motivi per cui Looker funziona in questo modo (per i dialetti che non supportano le aggregazioni simmetriche) sono descritti in dettaglio nel post della community Il problema dei fanout SQL.
Cose da sapere
Puoi unire la stessa tabella più di una volta utilizzando from
Nei casi in cui una singola tabella contiene diversi tipi di entità, è possibile unire una vista a un'esplorazione più di una volta. Per farlo, devi utilizzare il from parametro. Supponiamo che tu abbia un'esplorazione order e che tu debba unirvi una vista person due volte: una volta per il cliente e una volta per l'addetto all'assistenza clienti. Potresti fare qualcosa di simile:
explore: order {
join: customer {
from: person
sql_on: ${order.customer_id} = ${customer.id} ;;
}
join: representative {
from: person
sql_on: ${order.representative_id} = ${representative.id} ;;
}
}
Non applicare la logica di business nei join, se possibile
L'approccio standard di Looker per i join è utilizzare un LEFT JOIN quando possibile. Valuta un approccio diverso se ti ritrovi a fare qualcosa di simile:
explore: member_event {
from: event
always_join: [member]
join: member {
sql_on: ${member_event.member_id} = ${member.id} ;;
type: inner
}
}
In questo esempio abbiamo creato un'esplorazione che esamina solo gli eventi associati a membri noti. Tuttavia, il modo preferito per eseguire questa operazione in Looker è utilizzare un LEFT JOIN per unire i dati degli eventi e i dati dei membri, come segue:
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
}
}
Poi creeresti una dimensione che potresti impostare su yes o no, se volessi esaminare solo gli eventi dei membri, come segue:
dimension: is_member_event {
type: yesno
sql: ${member.id} IS NOT NULL ;;
}
Questo approccio è preferibile perché offre agli utenti la flessibilità di esaminare tutti gli eventi o solo gli eventi dei membri, a seconda delle loro esigenze. Non li hai costretti a esaminare solo gli eventi dei membri tramite il join.
Se non utilizzi aggregazioni simmetriche, evita i join che causano fanout
Questa sezione si applica solo ai dialetti di database che non supportano gli aggregati simmetrici. Consulta la discussione sulle aggregazioni simmetriche nella sezione Sfide comuni in questa pagina per determinare se il tuo dialetto supporta le aggregazioni simmetriche.
Se il dialetto del database non supporta gli aggregati simmetrici, devi evitare i join che generano un fanout. In altre parole, in genere è consigliabile evitare i join che hanno una relazione uno-a-molti tra l'esplorazione e la vista. Invece, aggrega i dati della vista in una tabella derivata per stabilire una relazione uno-a-uno con l'esplorazione, quindi unisci la tabella derivata all'esplorazione.
Questo concetto importante è spiegato ulteriormente nel post della community Il problema dei fanout SQL.