
Nutzung
explore: explore_name {
join: view_name { ... }
}
|
Hierarchie
join |
Standardwert
Keine
Akzeptiert
Der Name einer vorhandenen Ansicht
Sonderregeln
|
Definition
join ermöglicht es Ihnen, die Join-Beziehung zwischen einem Explore und einer Ansicht zu definieren, sodass Sie Daten aus mehreren Ansichten kombinieren können. Sie können beliebig viele Ansichten für ein bestimmtes Explore verknüpfen.
Jede Ansicht ist mit einer Tabelle in Ihrer Datenbank oder einer abgeleiteten Tabelle verknüpft, die Sie in Looker definiert haben. Da ein Explore mit einer Ansicht verknüpft ist, ist es auch mit einer Tabelle verbunden.
Die mit dem Explore verknüpfte Tabelle wird in die FROM-Klausel des von Looker generierten SQL-Codes eingefügt. Tabellen, die mit verbundenen Ansichten verknüpft sind, werden in die JOIN-Klausel des von Looker generierten SQL-Codes eingefügt.
Wichtige Join-Parameter
Um die Join-Beziehung (die SQL-ON-Klausel) zwischen einem Explore und einer Ansicht zu definieren, müssen Sie join in Kombination mit anderen Parametern verwenden.
Sie müssen entweder den Parameter sql_on oder den Parameter foreign_key verwenden, um die SQL-ON-Klausel zu erstellen.
Außerdem müssen Sie darauf achten, dass Sie die richtigen Join-Typen und -Beziehungen verwenden. Die Parameter type und relationship sind jedoch nicht immer explizit erforderlich. Wenn die Standardwerte type: left_outer und relationship: many_to_one für Ihren Anwendungsfall geeignet sind, können diese Parameter ausgeschlossen werden.
Diese Schlüsselparameter und ihre Beziehung zum von Looker generierten SQL-Code lassen sich so zusammenfassen:
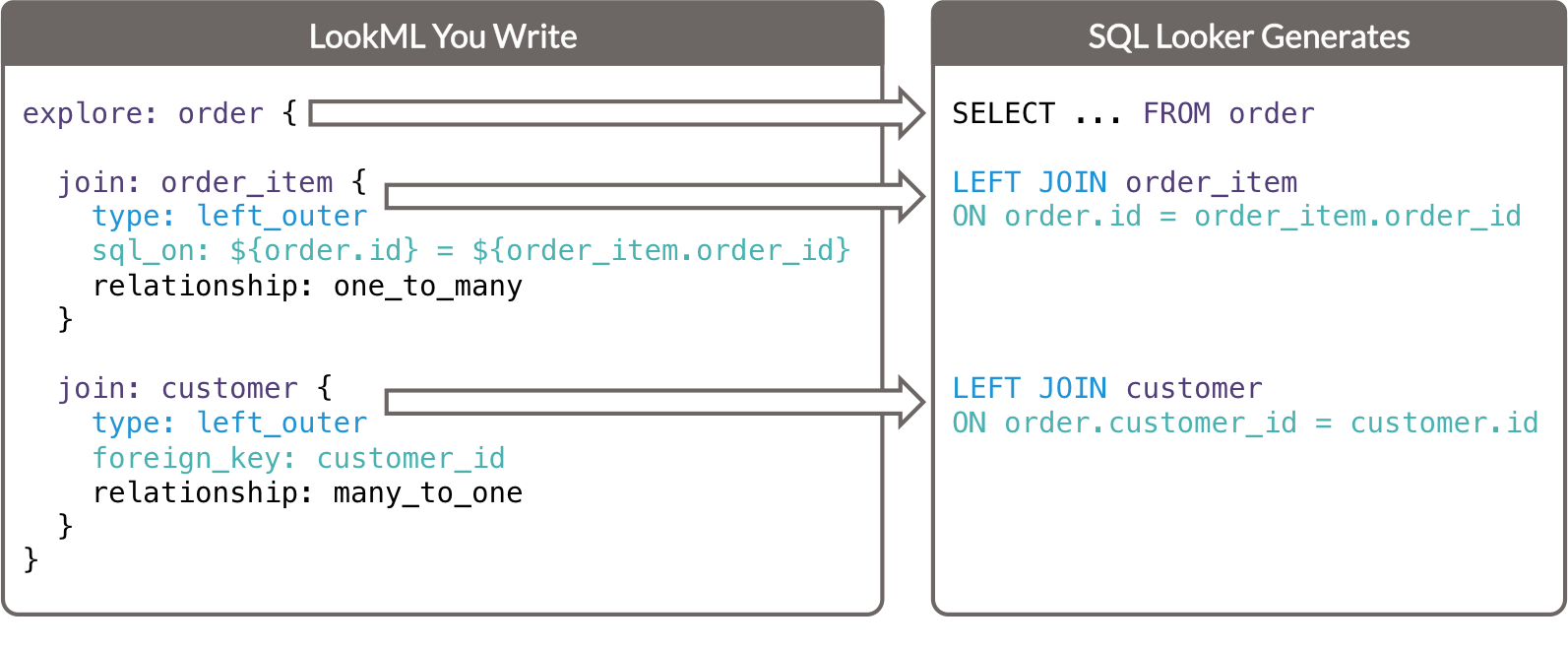
- Der Parameter
explorebestimmt die Tabelle in derFROM-Klausel der generierten SQL-Abfrage. - Jeder
join-Parameter bestimmt eineJOIN-Klausel der generierten SQL-Abfrage.- Der Parameter
typebestimmt den Typ des SQL-Joins. - Die Parameter
sql_onundforeign_keybestimmen dieON-Klausel der generierten SQL-Abfrage.
- Der Parameter
sql_on
sql_on können Sie eine Join-Beziehung herstellen, indem Sie die SQL-ON-Klausel direkt schreiben. Damit lassen sich dieselben Joins wie mit foreign_key erstellen, aber sie sind leichter zu lesen und zu verstehen.
Weitere Informationen finden Sie auf der Dokumentationsseite zum sql_on Parameter.
foreign_key
foreign_key ermöglicht Ihnen, eine Join-Beziehung herzustellen, indem Sie den Primärschlüssel der verbundenen Ansicht verwenden und ihn mit einer Dimension im Explore verknüpfen. Dieses Muster ist im Datenbankdesign sehr verbreitet und foreign_key ist in diesen Fällen eine elegante Möglichkeit, den Join auszudrücken.
Ausführliche Informationen finden Sie auf der Dokumentationsseite zum foreign_key Parameter.
type
Die meisten Joins in Looker sind LEFT JOIN. Die Gründe dafür werden im Abschnitt Geschäftslogik nach Möglichkeit nicht in Joins anwenden auf dieser Seite erläutert. Wenn Sie also nicht explizit einen type hinzufügen, geht Looker davon aus, dass Sie einen LEFT JOIN wünschen. Wenn Sie jedoch aus irgendeinem Grund einen anderen Join-Typ benötigen, können Sie das mit type tun.
Eine vollständige Erläuterung finden Sie auf der type Dokumentationsseite zum Parameter.
relationship
relationship hat keine direkte Auswirkung auf den von Looker generierten SQL-Code, ist aber entscheidend für die ordnungsgemäße Funktion von Looker. Wenn Sie nicht explizit ein relationship hinzufügen, interpretiert Looker die Beziehung als many-to-one. Das bedeutet, dass viele Zeilen im Explore eine Zeile in der verbundenen Ansicht haben können. Nicht alle Joins haben diese Art von Beziehung und Joins mit anderen Beziehungen müssen ordnungsgemäß deklariert werden.
Ausführliche Informationen finden Sie auf der Dokumentationsseite zum relationship Parameter.
Beispiele
Verknüpfen Sie die Ansicht customer mit dem Explore order, wobei die Join-Beziehung
FROM order LEFT JOIN customer ON order.customer_id = customer.id lautet:
explore: order {
join: customer {
foreign_key: customer_id
relationship: many_to_one # Could be excluded since many_to_one is the default
type: left_outer # Could be excluded since left_outer is the default
}
}
Verknüpfen Sie die Ansicht address mit dem Explore person, wobei die Join-Beziehung
FROM person LEFT JOIN address ON person.id = address.person_id
AND address.type = 'permanent' lautet:
explore: person {
join: address {
sql_on: ${person.id} = ${address.person_id} AND ${address.type} = 'permanent' ;;
relationship: one_to_many
type: left_outer # Could be excluded since left_outer is the default
}
}
Verknüpfen Sie die Ansicht member mit dem Explore event, wobei die Join-Beziehung
FROM event INNER JOIN member ON member.id = event.member_id lautet:
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
relationship: many_to_one # Could be excluded since many_to_one is the default
type: inner
}
}
Häufige Herausforderungen
join muss Ansichtsnamen und nicht zugrunde liegende Tabellennamen verwenden
Der Parameter join akzeptiert nur einen Ansichtsnamen, nicht den Tabellennamen, der mit dieser Ansicht verknüpft ist. Oft sind Ansichtsname und Tabellenname identisch, was zu der falschen Schlussfolgerung führen kann, dass Tabellennamen verwendet werden können.
Für einige Arten von Measures sind symmetrische Aggregate erforderlich
Wenn Sie keine symmetrischen Aggregate verwenden, werden die meisten Messwerttypen aus verbundenen Ansichten ausgeschlossen. Damit Looker symmetrische Summen in Ihrem Looker-Projekt unterstützen kann, müssen diese auch von Ihrem Datenbankdialekt unterstützt werden. In der folgenden Tabelle ist zu sehen, welche Dialekte symmetrische Aggregate in der aktuellen Version von Looker unterstützen:
| Dialekt | Unterstützt? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud AlloyDB for PostgreSQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
Ohne symmetrische Aggregate können Join-Beziehungen, die keine 1:1-Beziehungen sind, zu ungenauen Ergebnissen in Aggregatfunktionen führen. Da Looker-Messwerte Aggregatfunktionen sind, werden nur Messwerte vom Typ type: count (als COUNT DISTINCT) aus verbundenen Ansichten in das Explore übernommen. Wenn Sie eine 1:1-Join-Beziehung haben, können Sie mit dem relationship Parameter erzwingen, dass die anderen Messwerttypen einbezogen werden. Beispiel:
explore: person {
join: dna {
sql_on: ${person.dna_id} = ${dna.id} ;;
relationship: one_to_one
}
}
Die Gründe dafür, dass Looker so funktioniert (für Dialekte, die keine symmetrischen Aggregate unterstützen), werden im The problem of SQL fanouts Community-Beitrag ausführlicher erläutert.
Wichtige Punkte
Sie können dieselbe Tabelle mit from mehrmals verknüpfen.
In Fällen, in denen eine einzelne Tabelle verschiedene Arten von Entitäten enthält, ist es möglich, eine Ansicht mehrmals mit einem Explore zu verknüpfen. Dazu müssen Sie den from Parameter verwenden. Angenommen, Sie haben ein order-Explore und müssen eine person-Ansicht zweimal damit verknüpfen: einmal für den Kunden und einmal für den Kundenservicemitarbeiter. Das könnte dann folgendermaßen aussehen:
explore: order {
join: customer {
from: person
sql_on: ${order.customer_id} = ${customer.id} ;;
}
join: representative {
from: person
sql_on: ${order.representative_id} = ${representative.id} ;;
}
}
Geschäftslogik nach Möglichkeit nicht in Joins anwenden
Der Standardansatz für Joins in Looker ist, nach Möglichkeit einen LEFT JOIN zu verwenden. Erwägen Sie einen anderen Ansatz, wenn Sie etwas in dieser Art tun:
explore: member_event {
from: event
always_join: [member]
join: member {
sql_on: ${member_event.member_id} = ${member.id} ;;
type: inner
}
}
In diesem Beispiel haben wir ein Explore erstellt, das nur Ereignisse berücksichtigt, die mit bekannten Mitgliedern verknüpft sind. Die bevorzugte Methode, dies in Looker auszuführen, wäre jedoch, einen LEFT JOIN zu verwenden, um Ereignisdaten und Mitgliedsdaten zusammenzufügen. Beispiel:
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
}
}
Anschließend würden Sie eine Dimension erstellen, die Sie auf yes oder no setzen könnten, wenn Sie nur Ereignisse von Mitgliedern sehen möchten. Beispiel:
dimension: is_member_event {
type: yesno
sql: ${member.id} IS NOT NULL ;;
}
Dieser Ansatz ist vorzuziehen, da er Nutzern die Flexibilität gibt, entweder alle Ereignisse oder nur Ereignisse von Mitgliedern anzusehen. Sie haben sie nicht gezwungen, über den Join nur Ereignisse von Mitgliedern anzusehen.
Wenn Sie keine symmetrischen Aggregate verwenden, vermeiden Sie Joins, die Fanouts verursachen
Dieser Abschnitt gilt nur für Datenbankdialekte, die keine symmetrischen Aggregate unterstützen. Im Abschnitt Häufige Herausforderungen auf dieser Seite finden Sie Informationen dazu, ob Ihr Dialekt symmetrische Aggregate unterstützt.
Wenn Ihr Datenbankdialekt keine symmetrischen Summen unterstützt, sollten Sie Joins vermeiden, die zu einem Fanout führen. Mit anderen Worten: Joins mit einer 1:n-Beziehung zwischen dem Explore und der Ansicht sollten im Allgemeinen vermieden werden. Aggregieren Sie stattdessen die Daten aus der Ansicht in einer abgeleiteten Tabelle, um eine 1:1-Beziehung mit dem Explore herzustellen, und verknüpfen Sie diese abgeleitete Tabelle dann mit dem Explore.
Dieses wichtige Konzept wird im Community-Beitrag The problem of SQL fanouts näher erläutert.