
Uso
explore: explore_name {
join: view_name { ... }
}
|
Hierarquia
join |
Valor padrão
Nenhum
Aceita
O nome de uma visualização
Regras especiais
|
Definição
join permite definir a relação de mesclagem entre uma análise e uma visualização para combinar dados de várias visualizações. Você pode mesclar quantas visualizações quiser para qualquer análise.
Cada visualização está associada a uma tabela no banco de dados ou a uma tabela derivada definida no Looker. Da mesma forma, como uma análise está associada a uma visualização, ela também está conectada a uma tabela de algum tipo.
A tabela associada à análise é colocada na cláusula FROM do SQL gerado pelo Looker. As tabelas associadas a visualizações mescladas são colocadas na cláusula JOIN do SQL gerado pelo Looker.
Principais parâmetros de mesclagem
Para definir a relação de mesclagem (a cláusula ON do SQL) entre uma análise e uma visualização, use join em combinação com outros parâmetros.
É necessário usar o parâmetro sql_on ou foreign_key para estabelecer a cláusula ON do SQL.
Você também precisa usar tipos e relações de mesclagem adequados, embora os parâmetros type e relationship nem sempre sejam explicitamente obrigatórios. Se os valores padrão de type: left_outer e relationship: many_to_one forem adequados para seu caso de uso, esses parâmetros poderão ser excluídos.
Esses parâmetros principais e a relação deles com o SQL gerado pelo Looker podem ser resumidos da seguinte maneira:
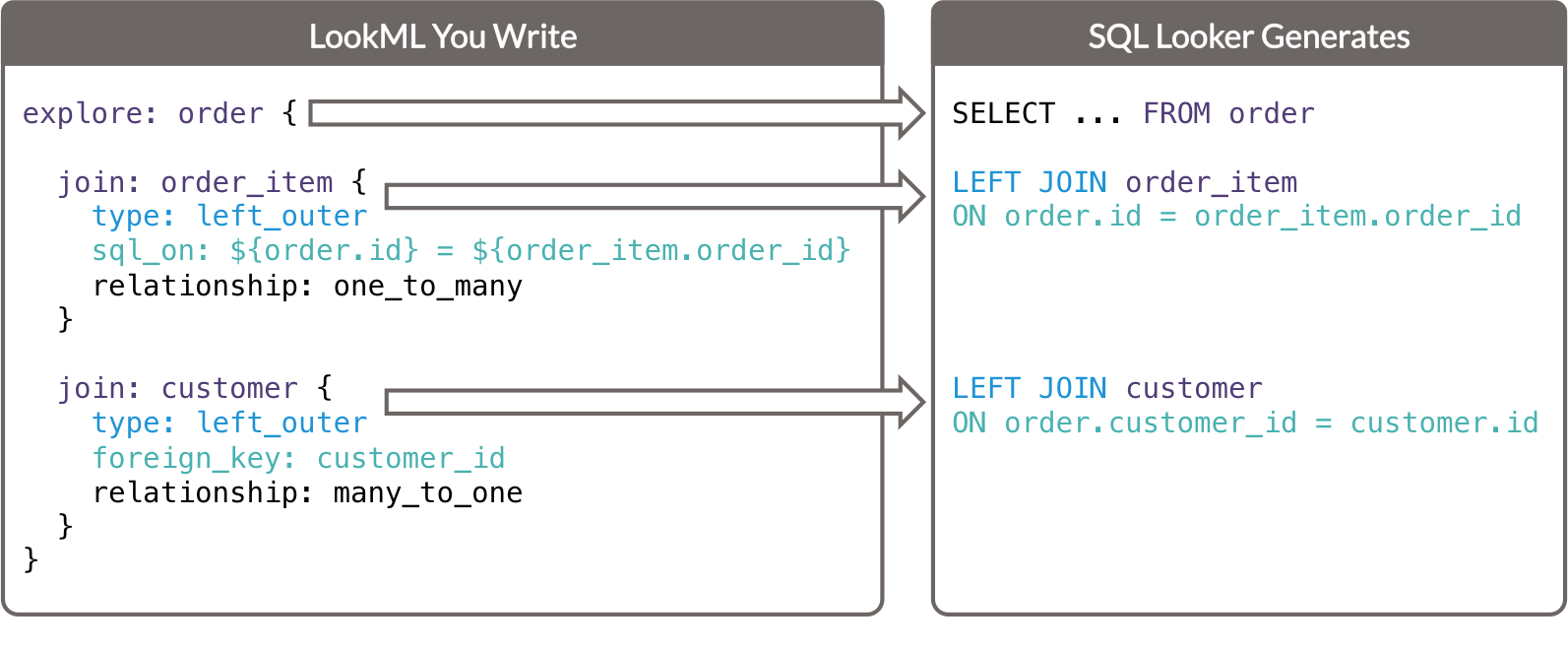
- O parâmetro
exploredetermina a tabela na cláusulaFROMda consulta SQL gerada. - Cada parâmetro
joindetermina uma cláusulaJOINda consulta SQL gerada.- O parâmetro
typedetermina o tipo de mesclagem SQL. - Os parâmetros
sql_oneforeign_keydeterminam a cláusulaONda consulta SQL gerada.
- O parâmetro
sql_on
sql_on permite estabelecer uma relação de mesclagem escrevendo a cláusula ON do SQL diretamente. Ele pode realizar as mesmas mesclagens que foreign_key pode, mas é mais fácil de ler e entender.
Consulte a página de documentação do parâmetro sql_on para mais informações.
foreign_key
foreign_key permite estabelecer uma relação de mesclagem usando a chave primária da visualização mesclada e conectando-a a uma dimensão na análise. Esse padrão é muito comum no design de banco de dados, e foreign_key é uma maneira elegante de expressar a mesclagem nesses casos.
Para entender tudo, consulte a página de documentação do parâmetro foreign_key.
type
A maioria das mesclagens no Looker são LEFT JOIN pelos motivos discutidos na seção Não aplicar lógica de negócios em mesclagens, se possível nesta página. Portanto, se você não adicionar um type explicitamente, o Looker vai presumir que você quer um LEFT JOIN. No entanto, se você precisar de outro tipo de mesclagem por algum motivo, poderá fazer isso com type.
Para uma explicação completa, consulte a página de documentação do parâmetro type.
relationship
relationship não tem um impacto direto no SQL gerado pelo Looker, mas é fundamental para o funcionamento adequado do Looker. Se você não adicionar um relationship explicitamente, o Looker vai interpretar a relação como many-to-one, o que significa que muitas linhas na análise podem ter uma linha na visualização mesclada. Nem todas as mesclagens têm esse tipo de relação, e as mesclagens com outras relações precisam ser declaradas corretamente.
Para entender tudo, consulte a página de documentação do parâmetro relationship.
Exemplos
Mesclar a visualização chamada customer à análise chamada order em que a relação de mesclagem é
FROM order LEFT JOIN customer ON order.customer_id = customer.id:
explore: order {
join: customer {
foreign_key: customer_id
relationship: many_to_one # Could be excluded since many_to_one is the default
type: left_outer # Could be excluded since left_outer is the default
}
}
Mesclar a visualização chamada address à análise chamada person em que a relação de mesclagem é
FROM person LEFT JOIN address ON person.id = address.person_id
AND address.type = 'permanent':
explore: person {
join: address {
sql_on: ${person.id} = ${address.person_id} AND ${address.type} = 'permanent' ;;
relationship: one_to_many
type: left_outer # Could be excluded since left_outer is the default
}
}
Mesclar a visualização chamada member à análise chamada event em que a relação de mesclagem é
FROM event INNER JOIN member ON member.id = event.member_id:
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
relationship: many_to_one # Could be excluded since many_to_one is the default
type: inner
}
}
Desafios comuns
join precisa usar nomes de visualização e não nomes de tabelas subjacentes
O parâmetro join só aceita um nome de visualização, não o nome da tabela associada a essa visualização. Muitas vezes, o nome da visualização e o nome da tabela são idênticos, o que pode levar à conclusão falsa de que os nomes das tabelas podem ser usados.
Alguns tipos de medições exigem conjuntos simétricos
Se você não estiver usando conjuntos simétricos, a maioria dos tipos de medição será excluída das visualizações mescladas. Para que o Looker ofereça suporte a conjuntos simétricos no seu projeto, o dialeto do banco de dados também precisa oferecer suporte a eles. A tabela a seguir mostra quais dialetos oferecem suporte a conjuntos simétricos na versão mais recente do Looker:
| Dialeto | Compatível? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
Sem conjuntos simétricos, as relações de mesclagem que não são um para um podem criar resultados imprecisos em funções agregadas. Como as medições do Looker são funções agregadas, apenas as medições de type: count (como COUNT DISTINCT) são extraídas de visualizações mescladas para a análise. Se você tiver uma relação de mesclagem um para um, poderá usar o relationship parâmetro para forçar a inclusão dos outros tipos de medição, como este:
explore: person {
join: dna {
sql_on: ${person.dna_id} = ${dna.id} ;;
relationship: one_to_one
}
}
Os motivos pelos quais o Looker funciona dessa maneira (para dialetos que não oferecem suporte a conjuntos simétricos) são discutidos com mais detalhes na postagem da comunidade O problema das divergências de SQL.
Informações importantes
É possível mesclar a mesma tabela mais de uma vez usando from
Nos casos em que uma única tabela contém diferentes tipos de entidades, é possível mesclar uma visualização a uma Descoberta avançada mais de uma vez. Para fazer isso, use o parâmetro from. Suponha que você tenha uma análise order e precise mesclar uma visualização person a ela duas vezes: uma para o cliente e outra para o representante de atendimento ao cliente. Você pode fazer algo como:
explore: order {
join: customer {
from: person
sql_on: ${order.customer_id} = ${customer.id} ;;
}
join: representative {
from: person
sql_on: ${order.representative_id} = ${representative.id} ;;
}
}
Não aplicar lógica de negócios em mesclagens, se possível
A abordagem padrão do Looker para mesclagem é usar um LEFT JOIN sempre que possível. Considere uma abordagem diferente se você estiver fazendo algo parecido com isso:
explore: member_event {
from: event
always_join: [member]
join: member {
sql_on: ${member_event.member_id} = ${member.id} ;;
type: inner
}
}
Neste exemplo, criamos uma análise que examina apenas eventos associados a membros conhecidos. No entanto, a maneira preferida de executar isso no Looker seria usar um LEFT JOIN para reunir dados de eventos e dados de membros, como este:
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
}
}
Em seguida, você criaria uma dimensão que poderia ser definida como yes ou no, se quisesse analisar apenas eventos de membros, como este:
dimension: is_member_event {
type: yesno
sql: ${member.id} IS NOT NULL ;;
}
Essa abordagem é preferível porque oferece aos usuários a flexibilidade de analisar todos os eventos ou apenas eventos de membros, conforme desejado. Você não os forçou a analisar apenas eventos de membros pela mesclagem.
Se não estiver usando conjuntos simétricos, evite junções que causem divergências
Esta seção se aplica apenas a dialetos de banco de dados que não oferecem suporte a conjuntos simétricos. Consulte a discussão sobre conjuntos simétricos na seção Desafios comuns desta página para determinar se o dialeto oferece suporte a conjuntos simétricos.
Se o dialeto do banco de dados não oferecer suporte a conjuntos simétricos, evite mesclagens que resultem em uma divergência. Em outras palavras, as mesclagens que têm uma relação um para muitos entre a análise e a visualização geralmente devem ser evitadas. Em vez disso, agregue os dados da visualização em uma tabela derivada para estabelecer uma relação um para um com a análise e, em seguida, mescle essa tabela derivada na análise.
Esse conceito importante é explicado com mais detalhes na postagem da comunidade O problema das divergências de SQL (link em inglês).