
Utilisation
explore: explore_name {
join: view_name { ... }
}
|
Hiérarchie
join |
Valeur par défaut
Aucun
Acceptation
Nom d'une vue existante
Règles spéciales
|
Définition
join vous permet de définir la relation de jointure entre une exploration et une vue, afin de pouvoir combiner des données provenant de plusieurs vues. Vous pouvez joindre autant de vues que vous le souhaitez pour une exploration donnée.
Rappelons que chaque vue est associée à une table de votre base de données ou à une table dérivée que vous avez définie dans Looker. De même, puisqu'une exploration est associée à une vue, elle est également connectée à une table d'un type ou d'un autre.
La table associée à l'exploration est placée dans la clause FROM du code SQL généré par Looker. Les tables associées aux vues jointes sont placées dans la clause JOIN du code SQL généré par Looker.
Principaux paramètres de jointure
Pour définir la relation de jointure (clause SQL ON) entre une exploration et une vue, vous devez utiliser join en combinaison avec d'autres paramètres.
Vous devez utiliser soit le paramètre sql_on, soit le paramètre foreign_key pour établir la clause SQL ON.
Vous devez également vous assurer que vous utilisez des types et des relations de jointure appropriés, bien que les type et relationship paramètres ne soient pas toujours explicitement requis. Si leurs valeurs par défaut type: left_outer et relationship: many_to_one conviennent à votre cas d'utilisation, ces paramètres peuvent être exclus.
Ces paramètres clés et leur relation avec le code SQL généré par Looker peuvent être résumés comme suit :
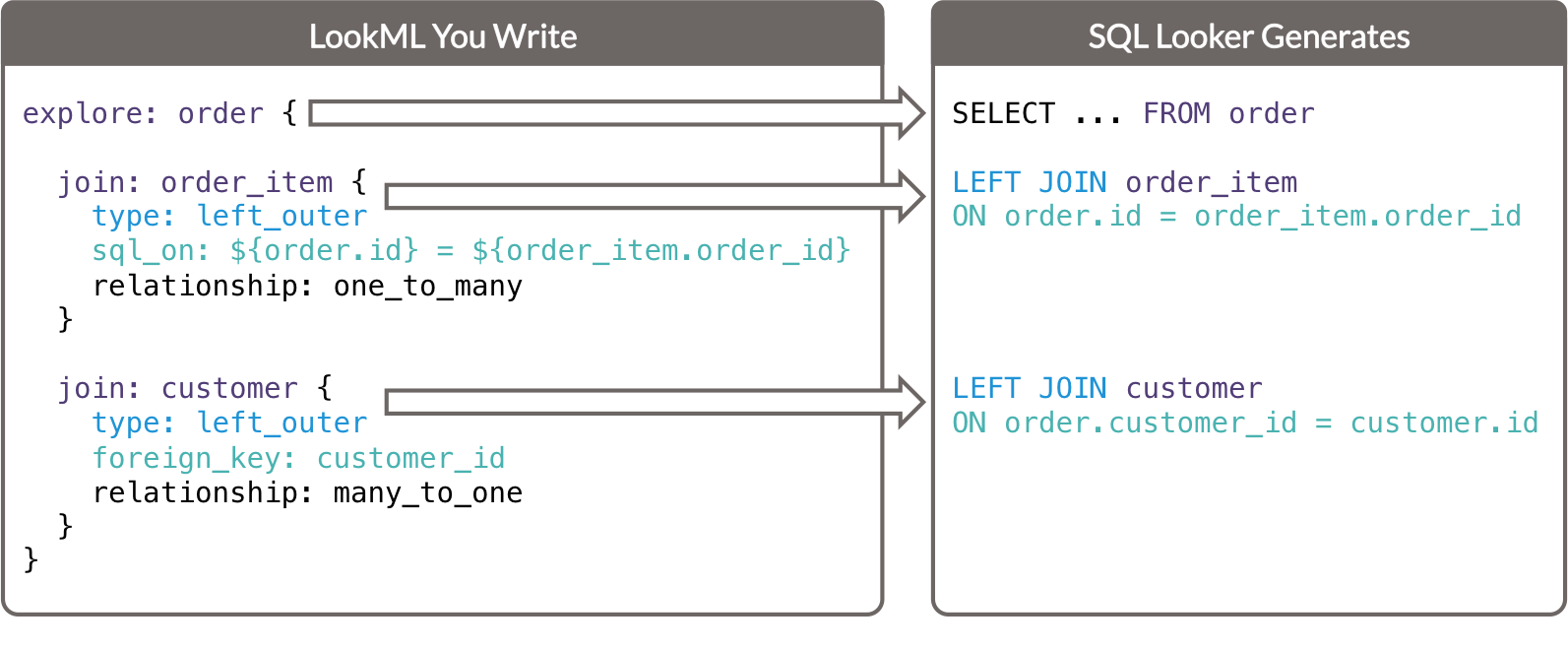
- Le paramètre
exploredétermine la table dans la clauseFROMde la requête SQL générée. - Chaque paramètre
joindétermine une clauseJOINde la requête SQL générée.- Le paramètre
typedétermine le type de jointure SQL. - Les paramètres
sql_onetforeign_keydéterminent la clauseONde la requête SQL générée.
- Le paramètre
sql_on
sql_on vous permet d'établir une relation de jointure en écrivant directement la clause SQL ON. Il peut effectuer les mêmes jointures que foreign_key peut, mais il est plus facile à lire et à comprendre.
Pour en savoir plus, consultez la page de documentation du paramètre sql_on.
foreign_key
foreign_key vous permet d'établir une relation de jointure à l'aide de la clé primaire de la vue jointe et de la connecter à une dimension de l'exploration. Ce modèle est très courant dans la conception de bases de données, et foreign_key est un moyen élégant d'exprimer la jointure dans ces cas.
Pour une compréhension complète, consultez la page de documentation du paramètre foreign_key.
type
La plupart des jointures dans Looker sont LEFT JOIN pour les raisons abordées dans la section Ne pas appliquer de logique métier dans les jointures si possible de cette page. Par conséquent, si vous n'ajoutez pas explicitement de type, Looker suppose que vous souhaitez une LEFT JOIN. Toutefois, si vous avez besoin d'un autre type de jointure pour une raison quelconque, vous pouvez le faire avec type.
Pour une explication complète, consultez la page de documentation du paramètre type.
relationship
relationship n'a pas d'impact direct sur le code SQL généré par Looker, mais il est essentiel au bon fonctionnement de Looker. Si vous n'ajoutez pas explicitement de relationship, Looker interprète la relation comme many-to-one, ce qui signifie que de nombreuses lignes de l'exploration peuvent avoir une ligne dans la vue jointe. Toutes les jointures n'ont pas ce type de relation, et les jointures avec d'autres relations doivent être déclarées correctement.
Pour une compréhension complète, consultez la page de documentation du paramètre relationship.
Exemples
Joindre la vue nommée customer à l'exploration nommée order où la relation de jointure est
FROM order LEFT JOIN customer ON order.customer_id = customer.id:
explore: order {
join: customer {
foreign_key: customer_id
relationship: many_to_one # Could be excluded since many_to_one is the default
type: left_outer # Could be excluded since left_outer is the default
}
}
Joindre la vue nommée address à l'exploration nommée person où la relation de jointure est
FROM person LEFT JOIN address ON person.id = address.person_id
AND address.type = 'permanent'
explore: person {
join: address {
sql_on: ${person.id} = ${address.person_id} AND ${address.type} = 'permanent' ;;
relationship: one_to_many
type: left_outer # Could be excluded since left_outer is the default
}
}
Joindre la vue nommée member à l'exploration nommée event où la relation de jointure est
FROM event INNER JOIN member ON member.id = event.member_id:
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
relationship: many_to_one # Could be excluded since many_to_one is the default
type: inner
}
}
Difficultés courantes
join doit utiliser des noms de vues et non des noms de tables sous-jacentes
Le paramètre join ne prend qu'un nom de vue, et non le nom de la table associée à cette vue. Souvent, le nom de la vue et le nom de la table sont identiques, ce qui peut conduire à la fausse conclusion que les noms de tables peuvent être utilisés.
Certains types de mesures nécessitent des agrégations symétriques
Si vous n'utilisez pas d'agrégations symétriques, la plupart des types de mesures sont exclus des vues jointes. Pour que Looker prenne en charge les agrégations symétriques dans votre projet, votre dialecte de base de données doit également les prendre en charge. Le tableau suivant répertorie les dialectes prenant en charge les agrégations symétriques dans la dernière version de Looker :
| Dialecte | Compatibilité |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
Sans agrégations symétriques, les relations de jointure qui ne sont pas de type un-à-un peuvent générer des résultats inexacts dans les fonctions d'agrégation. Étant donné que les mesures Looker sont des fonctions d'agrégation, seules les mesures de type: count (comme COUNT DISTINCT) sont extraites des vues jointes dans l'exploration. Si vous avez une relation de jointure de type un-à-un, vous pouvez utiliser le relationship paramètre pour forcer l'inclusion des autres types de mesures, comme suit :
explore: person {
join: dna {
sql_on: ${person.dna_id} = ${dna.id} ;;
relationship: one_to_one
}
}
Les raisons pour lesquelles Looker fonctionne de cette manière (pour les dialectes qui ne prennent pas en charge les agrégations symétriques) sont abordées plus en détail dans l'article de la communauté Le problème des sortances SQL.
Bon à savoir
Vous pouvez joindre la même table plusieurs fois à l'aide de from
Dans les cas où une seule table contient différents types d'entités, il est possible de joindre une vue à une exploration plusieurs fois. Pour ce faire, vous devez utiliser le from paramètre. Supposons que vous ayez une exploration order et que vous deviez y joindre une vue person deux fois : une fois pour le client et une fois pour le représentant du service client. L'instruction pourrait se présenter comme suit :
explore: order {
join: customer {
from: person
sql_on: ${order.customer_id} = ${customer.id} ;;
}
join: representative {
from: person
sql_on: ${order.representative_id} = ${representative.id} ;;
}
}
Ne pas appliquer de logique métier dans les jointures si possible
L'approche standard de Looker pour les jointures consiste à utiliser une LEFT JOIN chaque fois que cela est possible. Envisagez une autre approche si vous vous retrouvez à faire quelque chose comme ceci :
explore: member_event {
from: event
always_join: [member]
join: member {
sql_on: ${member_event.member_id} = ${member.id} ;;
type: inner
}
}
Dans cet exemple, nous avons créé une exploration qui ne concerne que les événements associés à des membres connus. Toutefois, la méthode préférée pour exécuter cette opération dans Looker consiste à utiliser une LEFT JOIN pour regrouper les données d'événement et les données de membre, comme suit :
explore: event {
join: member {
sql_on: ${event.member_id} = ${member.id} ;;
}
}
Vous pouvez ensuite créer une dimension que vous pouvez définir sur yes ou no si vous ne souhaitez examiner que les événements des membres, comme suit :
dimension: is_member_event {
type: yesno
sql: ${member.id} IS NOT NULL ;;
}
Cette approche est préférable, car elle permet aux utilisateurs d'examiner tous les événements ou uniquement les événements des membres, selon leurs besoins. Vous ne les avez pas obligés à n'examiner que les événements des membres via la jointure.
Si vous n'utilisez pas d'agrégations symétriques, évitez les jointures qui provoquent des sortances
Cette section ne s'applique qu'aux dialectes de base de données qui ne prennent pas en charge les agrégations symétriques. Consultez la discussion sur les agrégations symétriques dans la section Difficultés courantes de cette page pour déterminer si votre dialecte prend en charge les agrégations symétriques.
Si votre dialecte de base de données ne prend pas en charge les agrégations symétriques, vous devez éviter les jointures qui entraînent une sortance. En d'autres termes, les jointures qui ont une relation de type un-à-plusieurs entre l'exploration et la vue doivent généralement être évitées. À la place, agrégez les données de la vue dans une table dérivée afin d'établir une relation de type un-à-un avec l'exploration, puis joignez cette table dérivée à l'exploration.
Ce concept important est expliqué plus en détail dans l'article de la communauté Le problème des sortances SQL.